
{kind=link}
{kind=link}
{kind=link}
面向VIVO本体的数据摄取工具
引用本文
黄金霞, 景丽. 面向VIVO本体的数据摄取工具. 现代图书情报技术, 2011, 27(2): 16-20
Huang Jinxia, Jing Li. A Data Ingest Tool for VIVO Ontology. 现代图书情报技术, 2011, 27(2): 16-20
Permissions
Huang Jinxia, Jing Li. A Data Ingest Tool for VIVO Ontology. 现代图书情报技术, 2011, 27(2): 16-20
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
面向VIVO本体的数据摄取工具
摘要
介绍基于本体的科学家网络VIVO中的数据摄取工具,分析关系数据模型向RDF数据模型的批量数据摄取并与VIVO本体匹配的原理,阐述工具应用流程,为基于本体构建的信息服务系统或语义网应用中存在的异构数据摄取问题提供解决方法,并讨论该工具的特色和存在的问题。
关键词:
VIVO; 本体; 数据摄取工具; SPARQL查询
中图分类号:TP391
A Data Ingest Tool for VIVO Ontology
Abstract
To provide an effective method to import the heterogeneous data into the information systems based on Ontologies, this paper introduces a data ingest tool developed in VIVO which is a networking of scientists and is also a semantic Web application, including the principles and the working process in the data ingestion from relational data model to RDF data model and the data mapping with VIVO Ontology. The characteristics and some questions in this tool are also discussed.
Keyword:
VIVO; Ontology; Data ingest tool; SPARQL query
当前基于本体的系统越来越多,本体已经按照概念和属性的规则定义了数据、按照三元组模式存储了数据,但在很多系统中,数据仍以不同的格式存在和存储,这使得信息系统之间、数据之间的互操作、共享等成为很大的问题,目前的数据集成研究和工具应用几近成熟[ 1, 2],但还没有专门针对本体的数据导入工具产品。在建设基于本体的信息系统以后,需要把不同格式的数据导入到语义系统的数据库中;如果采用界面录入,将需要较大的人工成本,还不能完全保证数据的正确性。因此,一个强大的、面向本体的数据导入工具在当前语义网应用实施和维护中是很重要的。本文分析一个实用的面向本体的数据导入工具,这是在VIVO——一个面向科学和学术交流的科学家语义网络建设中,开发和应用的数据导入工具。在该项目中,该工具被称为数据摄取工具(Data Ingest Tool)。
1 VIVO项目概况
VIVO最初是康奈尔大学图书馆在2004年启动,以支撑该校农业和生命科学学院的生命科学研究而发展起来的,在2007年利用RDF、OWL、Jena 和SPARQL等技术进行了改造,目前其内容已经覆盖康奈尔大学所有院系的教员、科研人员和学科信息,分为人员、机构、学术活动和科研[ 3]。基于VIVO在康奈尔大学的应用以及科学研究工作发展的需求,2009年9月美国7所大学(包括佛罗里达大学、康奈尔大学、印第安那大学等)联合申请,从美国国立卫生研究院(NIH)的国家研究资源中心(National Center for Research Resources)获得1 220万美元的资助,来建设一个开放的科学家网络的语义应用,这个应用是为了寻求一种解决方法,来促进科研人员的科研网络化和协作[ 4],项目为期两年。目前佛罗里达大学和印第安那大学已搭建了本地VIVO系统。2010年9月VIVO数据被放到关联数据云中[ 5]。
VIVO本体是VIVO建设的核心部分,本体设计策略是核心本体+具有新命名空间的当地本体;不同命名空间的本体将支持对全部或部分的本体实例的查询。VIVO开发了一个本体编辑器Vitro,用于本体创建和修改、类和属性添加、实例添加等,并能直接生成OWL文件。基于本体,VIVO系统还提供了系统显示栏目与底层本体类的灵活关联,提供了基于本体的索引和检索功能,以及RDF数据添加/移除、RDF导出(包括本体、实例,支持多种文件格式,如RDF\XML、N3、N-Triples、Turtle等)、数据摄取工具、SPARQL查询。VIVO建设的软件和工具目前都是开放和开源的[ 6],便于其他有类似需求的系统建设者能够快速有效地建立模式系统,实现VIVO倡导的构建国家的、国际的科学家网络的目标。
2 VIVO数据摄取工具原理和工作流程
为了解决系统中的数据添加以及免除科研人员数据输入的工作量,面向VIVO的本体结构,VIVO开发了数据摄取工具。该工具已经在成员单位康奈尔大学、佛罗里达大学的VIVO平台上应用,并在不断完善中,例如摄取数据类型的增加、实现源数据与系统数据之间的更好匹配等[ 7]。
2.1 数据摄取的概念
数据摄取(Data Ingest)是指装载已有数据到VIVO中的任一过程,而不是直接的内容编辑,包括从一个在线数据库或一个当地记录系统中下载或导出数据[ 7]。这个概念与一般提到的概念“数据导入(Data Import)”类似,但过程的复杂程度超过数据导入,解决本体中不同类之间的对象关联是难点之一。
数据摄取不是全部自动化的,实际上,当前的摄取工具包括从数据源文件整理到在VIVO中新数据显示的一系列工作,流程中需要操作者有一些对语义网数据模型的了解。
2.2 工作原理
使用摄取工具阅读源数据文件,阅读来的数据被存储在VIVO数据库中作为一个“外部模型”,由VIVO底层的Jena语义网文库进行管理;利用Jena模型存储的信息,关联导入的信息和VIVO源数据:利用在SPARQL查询语言中的CONSTRUCT查询,进行源本体和VIVO本体之间的匹配并创建陈述[ 7]。
通过分析,可见VIVO数据摄取工具有三层模型基础架构,如图1所示:
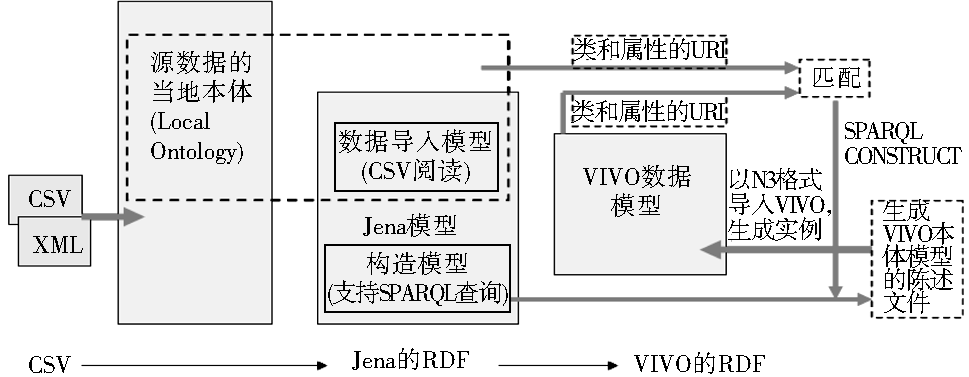 | 图1 VIVO数据摄取工具原理图 |
(1)当地本体-源数据模型
目前,摄取工具能支持导入的源数据类型包括由Excel文件或者数据库记录产生的CSV文件、XML文件。VIVO提供工具阅读CSV文件、也可以阅读和转换XML到RDF。所以,首先要新建一个当地本体,以它的类和属性来存储源数据,以它的命名空间作为所摄取资源的命名空间。
(2)数据导入和构造查询的Jena模型
在摄取工作区需要新建数据导入模型和构造模型。导入模型把从CSV文件中阅读来的数据转变为RDF,被Jena语义网文库管理。在SPARQL CONSTRUCT检索中,利用构造模型对来源数据RDF与VIVO中的RDF进行匹配。
(3)VIVO数据模型
因为VIVO通过“核心本体+当地本体”的组织方式来实现国家网络的资源共享,所以在数据摄取后需要建立当地本体与VIVO本体的匹配。以人员信息的导入为例:从源文件阅读来的作者名字需要关联到VIVO中的人员实例,可能的匹配结果是:或者匹配上已有人员或者创建一个新的人员记录。这种匹配最好是利用标识符,例如电子邮件地址、一个机构或者其他标识符。当一个作者已经存在,新导入的作者能够合并到VIVO中已存在的人员。如果一个作者在VIVO中找不到,那么一个新的人员记录必须在VIVO中产生,利用在RDF的SPARQL检索语言中的检索的CONSTRUCT形式:导入作者的检索,利用导入的本体来表达;CONSTRUCT声明利用VIVO本体的类和属性名。这就完成了源本体和VIVO本体的匹配。源数据也再次从在导入模型中的RDF翻译为在VIVO模型的RDF。
VIVO的系统管理平台提供的摄取工具操作菜单如图2所示:
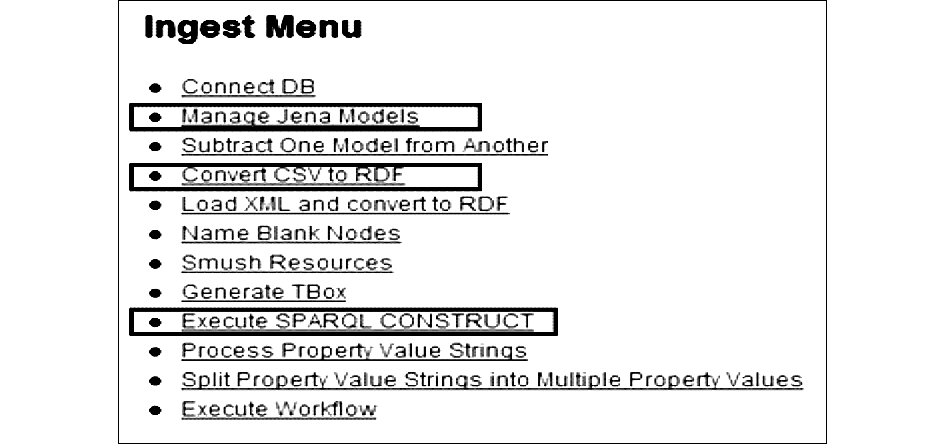 | 图2 VIVO系统中的数据摄取工具菜单[ 7] |
其中,主要使用的是三个功能区:Manage Jena Models(创建一个导入模型)、Convert CSV to RDF(转换CSV文件为RDF)或Load XML and Convert to RDF(转换CSV\XML文件为RDF)、Execute SPARQL CONSTRUCT(执行SPARQL构造)。
2.3 工作流程
主要介绍利用工具的流程化数据摄取过程,具体包括6个步骤(以用户经常使用的CSV文件摄取为例)。在摄取过程开始之前,需要对源数据进行评价,这是一个比较缓慢的过程,需要决定做怎样的数据清理,然后再进行数据摄取的工作流程。
(1)创建一个当地本体
VIVO建议每个机构自己创建一个当地本体来容纳机构数据和数据源的独特需要。利用VIVO提供的本体建设功能(Ontology List),创建一个新本体,并定义命名空间,添加类和属性,如类“人员”的数值属性PersonID、“机构”的数值属性OrganizationID。
(2)创建工作区模型来摄取和构造数据
在数据摄取工作区,选择“Manage Jena Models”来创建两个模型,摄取模型(Ingest Model)和构造模型(Construction Model)。这两个模型还提供模型导出功能,文件为RDF格式。
(3)把外部数据文件转换为RDF
选择“Convert CSV to RDF”,把整理好的、存放在相关位置的CSV文件如people.csv转换为某一命名空间的RDF文件。需要考虑命名空间、类名,以及选择的摄取模型。资源的命名空间将一直跟随着资源,所以最好与所创建的当地本体的命名空间一致,而类和属性的命名空间在这一步都是暂时的,因为在后续的步骤中它们将转换到本体的格式。类名在这一步也是暂时的,也将变更到本体的格式。转换是否成功,可以通过在系统的所有类中查找到新导入的类(包括实例)的方式来检查,或者通过输出摄取模型来检查。
(4)匹配表格数据为本体格式
收集属性、类和其他相关的URI,作为匹配的标准。首先是获取被摄取数据的URI:打开“Manage Jena Models”,在创建的摄取模型中,选择“Output Model RDF”,生成文档的谓词为下一步SPARQL检索所需要的特征,如图3所示,复制这些谓词到一个写字板文件中。
 | 图3 被摄取数据的RDF格式 |
获取VIVO本体中实例的谓词:确定被摄取数据将被放入的VIVO本体中的类,获取类与属性的URI,浏览这个类的一个已有实例或者新建一个实例,进入“Raw Statements with this Resource as Subject”,复制在SPARQL检索中需要的URI或谓词到一个写字板文档中。
(5)构造摄取的实体
在数据摄取工作区,选择“Execute SPARQL CONSTRUCT”,用基本框架在SPARQL中对被摄取数据的谓词和VIVO中实例的谓词进行比较,对于没有匹配上的数据将为VIVO构造新实例。如果被导入的新数据已经存在于VIVO中,而所在的命名空间不同,会出现两个名称相同的实例,具体过程如下:
Construct
{
}
Where
{
}
对于可能出现的变数,可以在变数名称前用?表示。例如:
Construct
{
?person ˂http://www.w3.org/1999/02/22-rdf-syntax-ns#type˃; ˂http://vivoweb.org/ontology/core#FacultyMember˃;.
?person ˂http://www.w3.org/2000/01/rdf-schema#label˃; ?fullname.
}
Where
{?person ˂http://localhost/vivo/ws_ppl_name˃; ?fullname.
}
在工作区,选择数据导入模型和构造模型,在执行构造的过程中,创建实例的陈述(Statement),这些陈述将按照VIVO数据模型创建三元组。
(6)装载数据到当前VIVO模型
为了防止Tomcat更新时数据模型的丢失,需要导出生成的最后模型,把它添加到当前VIVO模型中。在摄取工作菜单,选择“Manage Jena Models”,选择构造模型的数据导出(Output Model),保存结果文件;利用VIVO系统管理页面的“添加/删除 RDF”功能区,选择N3格式导入结果文件(N3是一种三元组的方式,通过枚举RDF模型中的每个陈述来表述RDF模型,与图形、XML相比,它最易于使用,简明易懂[ 8])。这样,摄取数据将显示在VIVO的索引和检索结果中。
3 关键技术分析
3.1 数据阅读和转换
VIVO系统数据导入模块的数据采用RDF格式,是网络上用来描述信息的一种矢量图数据格式,RDF提供了将不同的信息资源整合的方法[ 9]。
VIVO利用一个Supplied XSL或者Extensible Stylesheet Language来直接转换XML为RDF,很好地解决了在异构数据库之间的数据导入导出中的首要解决的问题,即阅读(打开)非SQL Server数据库的问题。这种成功的转换很大程度依赖XML数据的结构和一致性。这里需要在数据阅读之前,做好关系数据表的准备。CSV是一种纯文本格式,但其可以用Excel打开且能呈现类似于表格的形式,基于这个特点,可将现有的一些关系数据库表格存储成CSV格式。
3.2 SPARQL查询原理
在摄取工具中,Jena的特点得到了很好地运用,可以存储数据到硬盘、OWL文件或者关系数据库中。Jena提供了ARQ查询引擎,实现SPARQL查询语言和RDQL,从而支持对模型的查询。另外,查询引擎与关系数据库相关联,这使得查询存储在关系数据库中的本体时能够达到更高的效率。
随着越来越多的数据使用RDF格式保存,需要用一种简单方法查找特定信息。功能强大的新查询语言SPARQL填补了这个空白,使用户可以很容易地在RDF中找到所需要的数据。SPARQL是RDF数据查询语言,它能够查询跨系统的不同数据资源,不管数据本身是RDF格式还是通过中间件可查看其RDF格式。大多数SPARQL查询是一种基本视图格式的三元组格式。该三元组格式,除了主谓宾也许是变量之外,很像RDF格式。当一个子视图中的RDF术语被变量取代且检索出的RDF视图结果等同于该子视图时,即为一个基本视图匹配了RDF文档中的子视图[ 10]。在VIVO摄取工具中,使用到的是SPARQL查询的CONSTRUCT语句,返回结果集为RDF视图。
3.3 本体匹配(映射)
Vitro系统中有自身的本体表述,如人员类对应有若干数值属性和对象数据,但其与关系数据转换的临时三元组格式数据在谓词上不一致,需要对两种谓词表述进行映射。在本体匹配中,人员类的名称词要做映射,两者对应的数值属性词也要一一映射。
做好的映射表可以直接转化成SPARQL的CONSTRUCT查询语句,即将一个RDF格式文档利用SPARQL CONSTRUCT创建的格式生成一个新的RDF格式文档,之前的谓词被CONSTRUCT中的谓词所替换。
如果一个不在VIVO中的对象被发现,一条新记录必须利用CONSTRUCT查询格式在VIVO中被创建。查询浏览导入数据列表,在没有发现可匹配已有实例的任何地方,插入创建一个新实例的陈述。导入数据的查询利用导入本体被表达,而CONSTRUCT陈述使用VIVO本体的类和属性名称,完成源本体和VIVO本体之间的匹配。
3.4 对象属性的关联导入
VIVO摄取工具目前仅实现了关系数据库单表的导入,在本体中均为对应的数值属性。对于多个关联的关系数据库表如何转化为本体中的对象属性还在继续研究中。
4 VIVO数据摄取工具的特色和问题
XML具有自描述功能、结构性强、语义性强、交互性好、能描述不同复杂程度的数据、可以在各种平台上用各种编程语言对XML文件进行处理的特点,故用XML作为数据模型描述来自不同数据源的数据,屏蔽数据源中应用环境和数据结构的异构性。但XML只能从语法结构描述数据信息,而不能表达清晰的语义信息。因此,语义异构的问题仍存在于各种数据集成系统中,解决语义异构成为目前数据集成急需解决的任务。VIVO摄取工具在一定程度上解决了语义异构的问题。
作为一个实际应用的语义网系统中的数据摄取工具,当前的VIVO数据摄取工具还存在一些问题:
(1)能摄取的数据类型有限,主要是CSV文件、XML。当前VIVO还是主要面向结构化数据源,如PubMed系统等;如何面向非结构化数据源(如纯文本)及半结构化数据源(如XML、HTML文件、RDF等格式标注的网页、词典等)尚有待完善。
(2)信息存在操作过程中需要人工与自动并存的操作方式,且步骤较多。
(3)导入数据成为VIVO本体中的实例后,需要人工进行对象属性的关联,例如人员与机构的关联。
但作为一个语义网应用总体系统中的一部分,数据摄取工具对VIVO的应用很实用。
5 结 语
随着本体在信息系统领域应用的深入研究和应用,基于本体的语义网应用也越来越多。如何收集和整理大量科学数据(试验数据、计算数据、分析数据等)到这些语义网中已经成为问题。对于大量非结构化数据源和半结构化数据源的本体学习,目前研究较多[ 11],但是仍没有一个成熟的概念获取方法,多元的外部数据源到本体的匹配仍是研究重点,而在VIVO中数据摄取已经工具化并在实际中应用,以帮助用户方便快捷地导入数据。面向本体的异构数据集成和导入,仍是当前的一个研究方向。
(致谢:感谢康奈尔大学Mann图书馆和印第安纳大学的VIVO团队成员,在黄金霞参与VIVO项目工作时给予的帮助和指导。)
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|