





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种断点续传的多线程新闻组抓取方法及存储结构*
引用本文
杨代庆, 王志苹, 王星, 刘敏健, 常迎春. 一种断点续传的多线程新闻组抓取方法及存储结构* . 现代图书情报技术, 2011, 27(2): 29-33
Yang Daiqing, Wang Zhiping, Wang Xing, Liu Minjian, Chang Yingchun. Usenet-snatcher Based on Multithread and Mass-data Storage Supporting Breakpoint Transmission. 现代图书情报技术, 2011, 27(2): 29-33
Permissions
Yang Daiqing, Wang Zhiping, Wang Xing, Liu Minjian, Chang Yingchun. Usenet-snatcher Based on Multithread and Mass-data Storage Supporting Breakpoint Transmission. 现代图书情报技术, 2011, 27(2): 29-33
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
一种断点续传的多线程新闻组抓取方法及存储结构*
摘要
针对新闻组的海量性及相关编码特点设计新闻帖抓取流程,采用多线程方式加快新闻帖的抓取及解析速度,同时设计一种便于海量数据断点续传的数据存储结构,通过实验采集验证该方法能有效达到信息检测的数据采集要求,抓取及解析新闻帖的速度比普通单线程抓取解析方式有显著提高。
关键词:
新闻组; 多线程; 海量数据; 网络新闻传输协议
中图分类号:P393
Usenet-snatcher Based on Multithread and Mass-data Storage Supporting Breakpoint Transmission
Abstract
A usenet-snatcher is designed based on multithread to improve the download-speed and MIME-parsing-speed and a storage schema supporting breakpoint transmission is also proposed. Experiment shows that the usenet-snatcher can gather articles effectively and gathering-speed under multithread is faster than single thread.
Keyword:
Usenet; Multithread; Mass-data NNTP
1 引 言
新闻组(Usenet)作为互联网上最早出现的一种信息共享及信息交换形式,由于其简单、自由的特点,拥有众多使用者。新闻组帖子数量众多,由于其具有论坛的性质,以及比Web论坛更具言论的开放性(大部分不需要经过审查)及个性化,新闻组中的信息可能比WWW页面所携带的信息更具前瞻性或萌芽性。例如:根据NewsAdmin网站的统计数据[ 1],其统计的前100个新闻组中每小时的新闻帖更新量可以达到1 800条,每日达到25 000条;而且新闻组讨论的常常是当前的热点问题,例如:微软网络新闻组就是面向大众建立的免费技术交流平台,具有链接速度快等诸多优点。微软新闻组于2002年开放中文版,至今依然活跃着大量微软技术爱好者以及微软最有价值专家。
上述特点决定了新闻组在网络信息监测中应占有一席之地。目前有很多客户端阅读器都支持对新闻组的访问,例如:微软的Outlook Express、Agent、BinaryBoy[ 2]等,但这些阅读器在使用时通常需要人进行干预和值守,且不便于对大批量新闻组及新闻帖的保存、检索。在采用Outlook Express采集时,是以文件的方式保存新闻帖,而不能保存在数据库中,附件也是以未解析的MIME编码方式存放。若直接使用这些软件,不能满足新闻组作为信息源进行批量自动抓取及存储的要求。此外,有采用C#对新闻组进行基本访问的程序应用[ 3],但不支持对MIME(Multipurpose Internet Mail Extensions)类型的解码;HKcow提供了.Net平台下的NNTP访问库及MIME解码支持[ 4],但在实验过程中,对大批量数据进行采集时,会遇到不能持续进行数据抓取的问题。此外,目前存在一些Usenet的搜索引擎,但这些搜索引擎工具或是需要付费,如News Rover[ 5];或只能以Web方式返回搜索信息,如:BinSearch.info[ 6]。
在信息监测中,对作为新闻组的采集有如下要求:尽可能提高采集速度,以保证有足够的基础数据作为检测对象;能够将采集到的数据存储到数据库中,以便后续检测工作的开展;能够对新闻组附件进行处理;能够实现断点续传。
在调研的范围内没有现成工具完全满足网络信息监测的采集要求,通过对一些开源软件进行实验分析,本文在Java的基础上,基于开源软件包Apache Commons和Sun的MIME,利用多线程方式提高新闻组抓取速度,同时制定了能将抓取到的数据快速保存并支持断点续抓的策略及存储结构。
2 断点续传的多线程抓取及文章解析
新闻组中的文章存放在新闻服务器的新闻组中。通常一个新闻服务器中有几十到上千个新闻组不等。而每个新闻组中存放的新闻帖则从几十条到百万条。对于大多数新闻服务器而言,只保存最近一段时间内的新闻帖。
访问新闻帖的步骤是:连接新闻服务器;获取新闻服务器上的新闻组列表;选择特定的新闻组;获取特定新闻组上的新闻帖标题信息;通过获取的标题信息中的Message-ID获取该Message-ID对应的新闻帖全部内容。
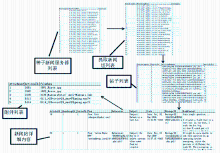
其中,新闻组列表及新闻帖标题信息列表的获取是批量的,而在对完整新闻帖的请求时,每篇新闻帖的获取都需要客户端与服务器端进行一次交互。由于新闻帖数量大,每篇新闻帖完整内容的获取时与服务器端的连接及传输将成为影响抓取速度的瓶颈。为此,设计多线程抓取流程来获取并解析文章完整信息,如图1所示:
 | 图1 多线程抓取新闻流程 |
图1中的流程用两个类来实现,分别是负责新闻组信息获取和支持新闻组级别的断点续传流程控制的NewsReader类和多线程新闻帖抓取及解析的CrawTask类,类中的主要方法及说明如图2所示:
 | 图2 抓取类及方法 |
2.1 带断点续传的抓取
抓取时,根据新闻种子服务器地址获取该服务器上的新闻组列表,根据每个新闻组获取该新闻组的新闻标题列表(简要信息),将新闻标题列表的ID(MessageID)发送给多线程完成新闻帖的完整信息抓取及解码工作。
为了保证每个新闻组服务器的内容都能抓取完成,并且在意外情况发生时,能够不再对已经抓取完成的新闻服务器重新抓取新闻帖,笔者设计了服务器级别的断点继抓过程。具体方法为:
(1)采用getNewsGroupFromServer方法从CurrentServer表中获取当前正在处理的新闻服务器,若CurrentServer中的处理标志为1,表示当前新闻服务器已经处理完成,则从ServerName表中获取下一个新闻服务器;若标识为0,表示当前新闻组服务器的内容并未处理完成,则根据服务器ID清空未完成抓取的新闻帖及新闻组,再重新从该新闻组服务器获取新闻组信息,并保存到NewsGroup表及TempNewsGroup表中。
(2)用getArticleListFromNewsGroup从每个新闻组中获取每个新闻组中的新闻帖列表,存放在TempArticleList和ArticleList表中。
(3)getArticleFromServer根据TempArticleList表中的内容利用多线程从对应的服务器中抓取新闻帖详细内容,并对抓取的新闻帖详细内容进行解析,将解析后的内容保存到Article中,将解析得到的附件保存到Attachment中。
在抓取过程中,各个抓取流程的方法之间相互调用的方式为:getNewsGroupFromServer()→getArticleListFromNewsGroup()→getArticleFromServer(),采用了深度优先采集策略,即采集完当前新闻组中的文章后再采集另一个新闻组中的文章,当所有同一个新闻服务的新闻组采集完成后,再采集另一个新闻组服务器上的内容。
2.2 解 码
扩展的MIME类型新闻帖包含新闻头和新闻体两部分,新闻头包括发帖人、回帖人、 主题、 日期、 新闻帖唯一标识、帖子行数等重要信息。
在解码时,首先判断新闻帖若为纯文本,可按照标准分割新闻头和新闻体的方法,提取帖子各个字段的内容。若帖子不是纯文本,则根据MIME规范中的Multipart类型将内容分隔成不同的段,各段之间的边界标识由对应 Multipart类型的Boundary属性定义,并利用Content-Type给出的边界标识提取出邮件中的分段信息,从而获得所需要的内容,抓取到的新闻帖示例如图3所示:
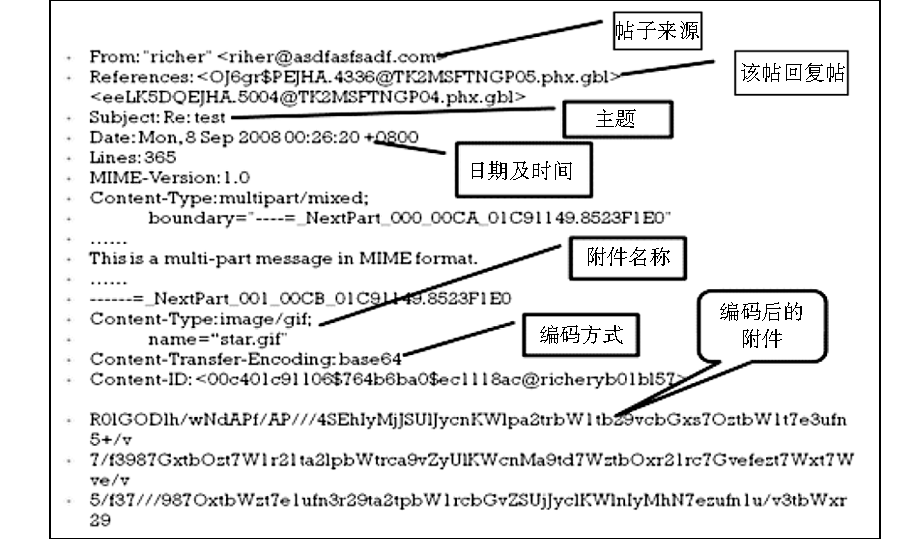 | 图3 MIME类型新闻帖内容示例 |
本文中采用了Sun的MIME开源软件包[ 7]对采集到的新闻帖进行解析,解析后产生:发帖人标识、回帖人标识、发帖主题、发帖日期、新闻帖唯一标识、新闻帖内容、附件名称、附件文件,具体如图4所示:
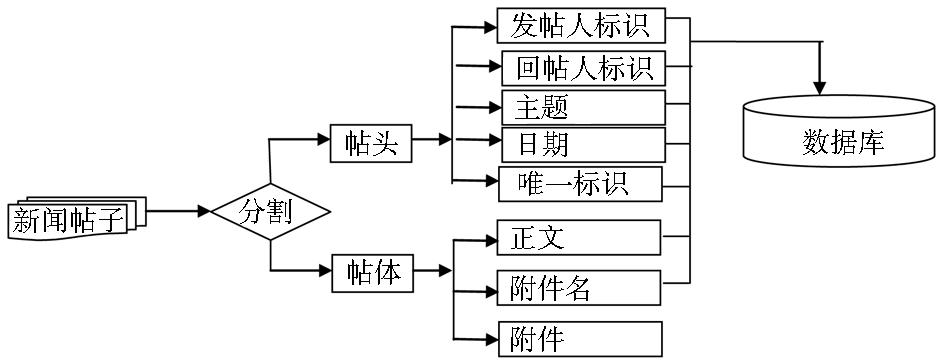 | 图4 MIME解码流程 |
3 数据存储结构
存储海量数据时,为提高效率,需避免对数据库进行反复的修改操作,同时为了保证在数据抓取过程中服务器级的断点都能实现续传,制定了以下存储策略及数据结构。实践中,共建立了11个表作为存储及实现断点续抓的结构,分别为ServerName、NewsGroup、ArticleList、Article、Attachment、CurrentServer、TempNewsGroup、TempArticleList、ArticleErrorLog、NewsGroupErrorLog、ServerErrogLog。各个表的作用及关键字段如表1和表2所示。
| 表1 主要表名及说明 |
| 表2 主要表中的关键字段及说明 |
在抓取过程中,对新闻帖的续抓控制是新闻服务器级别的,同时由于存放新闻组的NewsGroup和Arti⁃cleList表存储所有抓取到的新闻组及新闻帖列表,会变得很大。为了保证查询及更新速度,对这两个表采取的策略是只做写操作。采用对应的两个临时表TempNewsGroup和TempArticleList存储当前服务器的新闻组和当前新闻组的新闻列表,每次处理完当前新闻组和当前服务器后分别清空TempArticleList和TempNewsGroup。
4 实际抓取效果
在实际采集过程中,收集了与计算机专业相关的约340个新闻组服务器作为种子,通过一台服务器在Windows平台进行24小时不间断采集,约7天时间共采集到新闻组约8万个,新闻帖子约300万条,并将抓取到的除附件外数据全部存储到SQL Server数据库中,附件以文件形式存储到服务器硬盘中。采集界面及各个表中抓取的实际新闻数据如图5和图6 所示:
 | 图5 抓取器界面 |
 | 图6 实际抓取结果 |
抓取过程中经测试,同一批数据,在采用单线程的情况下,采集速度量约为1.5条/秒,在20个线程的情况下,采集速度约为11条/秒,因此多线程情况下,采集速度有明显提高,如图7所示:
 | 图7 单线程与20线程抓取速度对比 |
在断点续传抓取测试时,在数据量较小的情况下,能够比较好地实现服务器级别的断点续传,当已经抓取到较多数据时,清空未完成数据会出现耗时较长的情况。为此,在本文最终采集过程中,采用了不清空未完成数据的策略,直接从服务器的断点重复抓取。
5 结 语
尽管本文采用的方法对新闻组的采集速度有了明显提高,但相对于新闻组的更新速度来说仍需进行较大提升,同时对于海量数据的保存也还需考虑采用分布式的保存方式,下一步的探索工作是将目前的抓取工作移植到Hadoop的MapReduce框架下,实现多机的并行抓取及分布式存储,并将断点续传粒度进一步缩小到新闻组级别。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|