{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于汉字聚类特征的中文字符串相似度计算研究
引用本文
王静婷. 基于汉字聚类特征的中文字符串相似度计算研究. 现代图书情报技术, 2011, 27(2): 48-53
Wang Jingting. Research Towards Chinese String Similarity Based on the Clustering Feature of Chinese Characters. 现代图书情报技术, 2011, 27(2): 48-53
Permissions
Wang Jingting. Research Towards Chinese String Similarity Based on the Clustering Feature of Chinese Characters. 现代图书情报技术, 2011, 27(2): 48-53
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于汉字聚类特征的中文字符串相似度计算研究
摘要
采用聚类分析的方法,对汉字的特征进行研究和分析,找出其内在规律,根据汉字具有“成簇性”的特点,对中文字符串进行精细化匹配,给出基于改进编辑距离的相似度计算模型。实验结果表明,该模型对中文字符串的相似度具有更为精细的体现。
关键词:
中文字符串匹配; 汉字成簇性; 相似度
中图分类号:TP391
Research Towards Chinese String Similarity Based on the Clustering Feature of Chinese Characters
Abstract
This paper adopts cluster analysis method to discuss and analyze the features of Chinese characters,in order to discover the internal rules. Based on the clustering feature of Chinese characters,it refines the matching result of string matching,and advances a 2-level similarity model. The experiment result shows that this model can reflect the similarity better.
Keyword:
Chinese string matching; Clustering of Chinese character; Similarity
1 引 言
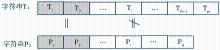
作为字符串近似匹配的一种度量方法,中文字符串相似度的计算在中文信息检索、中文信息过滤、中文OCR识别、中文文本校对等领域中都有广泛的应用。现有的计算字符串相似度的方法按照计算所依据的特征的不同,可以划分为三种:基于字面相似的方法、基于统计关联的方法、基于语义相似的方法。文献[1]将三种方法融合后提出了一种基于多层特征的计算模型;文献[2]和文献[3]专门针对中文信息过滤中存在的网页中恶意夹杂关键词、变形关键词等情况,在匹配算法上进行了改进。然而,根据已有资料的分析,目前在这些计算字符串相似度的算法、近似匹配的算法中,都存在一个假设:中文字符串匹配的最小单元为单个汉字,换句话说,目前大多数方法并没有考虑汉字自身特征的差异对中文字符串相似度的影响。从形式化角度分析,若以T、P代表中文字符串,Ti、Pj 表示单个中文字符,1≤i≤m,1≤j≤n,那么两个中文字符串的近似匹配如图1所示。
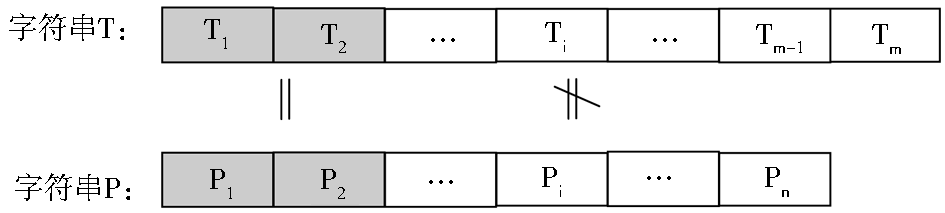 | 图1 中文字符串近似匹配机制 |
由图1可以看出,中文字符串的近似匹配建立在单个中文字符即汉字比较的基础上。然而,汉字间的比较结果通常只有匹配与不匹配两种情况,以0、1或False、True的形式表示。例如,比较“公园”、“公元”与“公务”三个词,用传统的编辑距离方法,它们之间的相似度都是0.5。然而根据直观感受,显然“公园”与“公元”的相似程度要远远大于“公园”与“公务”的相似度,其原因在于,“园”与“元”的相似度大于“园”与“务”之间的相似度。
当前,研究者已经提出了利用汉字可以分解的特征[ 4, 5, 6, 7, 8]来解决这个问题,其中文献[4]中提出的基于拼音索引的中文模糊匹配算法采用了汉字、拼音和拼音改良的编辑距离,文献[5]给出了一种相似匹配算法并应用于拼音相似度的计算,文献[6]提出了利用汉字机内编码进行相似度计算,文献[7]和文献[8]则针对字形特征对汉字进行了相似度计算,但大多数研究仅限于汉字的单一特征分析,忽略了汉字的全特征分析。虽然文献[9]专门针对因编辑行为引起的字符串相似重复的情况,给出了一种基于拼音编码和五笔编码的编辑距离与基于字符的编辑距离融合的计算方法,但没有给出具体的依据以及汉字特征分析的系统证明与描述。
基于这些考虑,本文将从汉字的基本特征入手,对其进行聚类分析,给出“相似”的合理证明,在此基础上,对已有的算法进行改进,试图给出一个不限应用领域的计算中文字符串相似度的普适方法。
2 汉字聚类特征分析
2.1 Soundex算法的启示
英文中已有根据语音的相似性来计算字符串相似度的语音匹配算法,最广为人知的语音算法是Soundex算法,它首先提出了按照发音而不是按照字母表的方式对单词进行分组。Soundex算法的运作方式[ 10]是把某个字母表中的每个字母映射成代表它的语音组的一个数字代码。在这个方案里,像d和t这样的字母在同一个组中,因为它们发音相近,而元音则一概忽略。通过对整体单词应用这种映射,就产生了单词的语音“键”(Key)。发音相近的单词通常会有相同的键。如Smith和Smyth的Soundex都是S530。相似的对象组织到一起构成的类可以称之为簇。簇内对象相似度大,簇间对象相似度小。因此,可以把一个键看作一个类簇,即存在一个键对应的所有单词属于同一个类簇,它们之间语音非常相似,因此,英文单词可以根据语音的相近而具有“成簇性”。
2.2 汉字的聚类分析
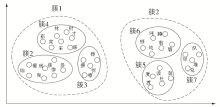
根据Soundex算法的启示,可以直观地推测:同样具有语音特征的中文也具有“成簇性”。同音字、近音字就是自然存在的语音类簇,如图2所示:
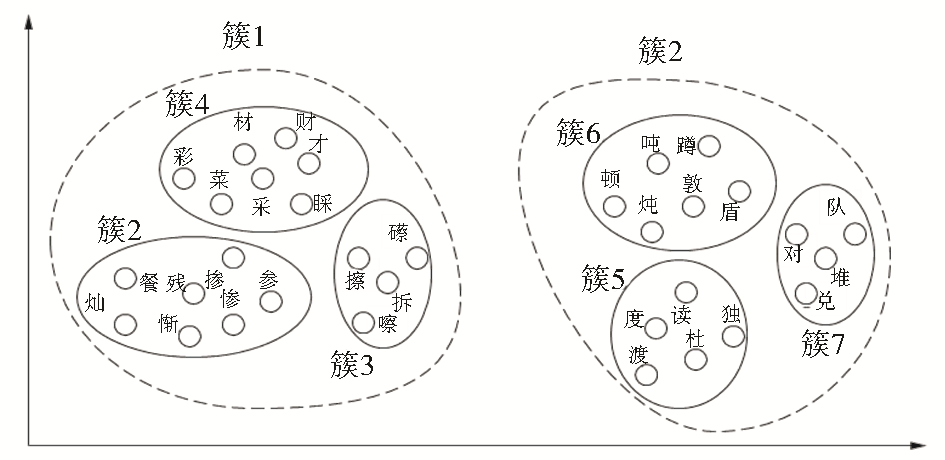 | 图2 同音字类簇 |
图2中包含6组同音字,根据“cai”、“can”、“ca”、“dun”、“du”、“dui”的发音聚成6个类簇。进一步分析,可以观察到不仅同音字具有“成簇性”,发音相近的汉字也具有语音“成簇性”,比如“cai”、“ca”、“can”三个发音之间本身就很相近,所以簇2、簇3、簇4也可以聚类为更大的簇1。同理,簇5、簇6、簇7可聚类为簇2。依此类推,其他发音相似的汉字也具有聚簇性。
音、形、义被归纳为汉字的三大特征。汉字之间可以因其“音”的相同或相似而相似,也可以因为“形”的相近而相似,也可因“义”的相近而相似。为更好地证明此结论的正确性,分别以语音特征和字形特征作为基础,对汉字进行聚类分析。由于目前对“义”还没有一个明确的度量标准,这里暂不考虑这种情况。具体实现则分别以“表音”的拼音编码和“表形”的五笔字型编码为聚类对象,以编码之间的编辑距离作为聚类依据,通过计算编码之间的编辑距离确定汉字的相似度,根据相似度的大小实现聚类。
(1)拼音聚类分析
针对408个拼音编码,分别以50-200个类簇为指标进行聚类分析,在得到的实验结果中,以聚类特征明显为原则,根据实际情况选择合适的类簇数量,可以找出当聚类为52个簇时,结果较为自然。选取其中的5组聚类结果,如下所示:
① [ miao, jiao, diao, biao, tiao, qiao, xiao, piao, liao, niao]
② [gai, wai, bai, lai, mai, ai, tai, sai, nai, dai, cai, kai, pai, zai]
③ [hui, gui, rui, sui, cui, dui, kui, tui]
④ [xiu, niu, diu, liu, miu]
⑤ [chong, cheng, chang]
从聚簇结果可以清楚地看出,拼音相似的编码基本分布在相同的簇中,这说明拼音编码具有语音“成簇性”特征。
(2)五笔聚类分析
对于五笔编码,同样以上述方式进行聚类分析,以50-500个类簇为指标,分别计算,较为自然的聚类结果是聚为360个类簇,从中抽取5组数据作为代表,如下所示:
① [lfou(黑), lfoj(黯), klfo(嘿)]
② [vldy(姻), oldy(烟), kldn(嗯), kldy(咽)]
③ [jans(蝶), ians(渫), dans(碟)]
④ [ptfq(宪), pfqb(完), pfqc(寇), pfqf(冠), pfq(完)]
⑤ [fnrt(场), rnrt(扬), enrt(肠), fnr(声), snrt(杨), qnrc(饭), inro(烫), inrt(汤)]
从实验结果可以看出,形近字分布在同一个类簇中,几组数据均基本符合“成簇”的特征。因此,说明“形”似的汉字也具有聚类特征。
从上述两个实验可以看出,正是由于汉字“成簇性”的存在,在组成字符串的过程中,不可避免组合错误的产生。比如音的“成簇”会导致同音字、近音字替换,形的“成簇”会引起形似字替换,义的成簇则会导致近义词混淆的情况。明确汉字的“成簇性”特征,是中文字符串精细化匹配的前提。
3 基于改进编辑距离的相似度计算模型
3.1 符号及算法说明
字符串之间相似度的计算方法已经有几十种,本文采用其中最常用、最简单的基于编辑距离的计算方法[ 11],以及在英文姓名匹配中广泛使用的Jaro-Winkler距离模型[ 12]。这两种计算方法的结合可以覆盖字符的插入、删除、替换以及交换等基本错误。通过在大量实验数据的基础上对权值进行修正,以获得对字符串间相似度更为精确的结果。
本文使用以下符号描述中文字符串匹配算法:
S、T:给定的两个中文字符串,其中:
S={S1,S2,…,Si,…,Sm},i∈[1,m],S中含有m个汉字(包括重复字符),Si为单个汉字;
T={T1,T2,…,Tj,…,Tn},j∈[1,n],T中含有n个汉字(包括重复字符),Tj为单个汉字。
edit(S,T):S和T之间的编辑距离。
Jaro-Winkler(S,T):S和T之间的Jaro-Winkler距离。
3.2 基于改进编辑距离的二阶相似度模型
根据分析知汉字具有“成簇性”,若要更加精细化地反映中文字符串的相似度,需要将其考虑在内。因此,在计算中文字符串的相似度时,需要将汉字的相似度体现出来。首先需要计算汉字的相似度,在此基础上计算汉字组成的中文字符串的相似度。由此,提出中文字符串的二阶相似度计算模型。
定义1:给定中文字符串S、T,二阶相似度为融入汉字Si∈S、Tj∈T相似度后得出的S与T之间的相似程度。汉字Si和Tj之间的相似度为一阶相似度,记为Sim(Si,Tj),S和T的相似度为二阶相似度,记为 Similar(S,T)。
二阶相似度是一般字符串相似度的扩展。
(1)一阶相似度计算
一阶相似度即汉字相似度。汉字的相似度建立在其特征相似的基础上。概括地说,汉字具有音、形、义特征,汉字进入计算机,这些特征最直接地反映在各种编码方案上。目前专家学者们提出的汉字编码方案有近千个,已被采用的编码方案达数十种之多,这些汉字编码方案大致可以分为4种[ 13]:
①形码:根据汉字的字形来进行编码,如笔形编码法和五笔字型编码法;
②音码:根据汉字的读音来进行编码,一般以汉语拼音方案为根据;
③形音码:这种方法立足于字形分解,把字分解为部件或笔画,部件和笔画统称为字元,各个字元又通过它们的读音来帮助记忆;
④音形码:以音为主,以形为辅的编码,利用字形来区分同音字。
定义2:反映汉字某一方面的特征的编码方案称为汉字的特征项。
例如,五笔编码规则反映汉字字形的特征,可以作为特征项;拼音规则反映汉字读音特征,也是特征项。
定义3:描述汉字c的特征项的字符串,称为c对应的一个Key。记为Keyfeature(c),其中feature表示特征项。
设拼音编码方案用py表示,五笔编码方案用wb表示,则Keypy(c)可表示c的拼音编码,Keywb(c)可表示c对应的五笔编码。
于是,汉字c1和汉字c2的相似度可用Sim(Keyfeature(c1),Keyfeature(c2))表示。即:
Sim(c1,c2)=Sim(Keyfeature(c1),Keyfeature(c2)) (1)
目前应用较为普遍的汉字编码方案都是以英文字符或数字的形式表示的,因此Keyfeature(c)代表的字符串只包含英文字母和数字,并且为短模式字符串。所以,Sim(Keyfeature(c1),Keyfeature(c2))也就是两个短模式英文字符串的相似度。
因此,Sim(c1,c2)可转换为英文字符串匹配问题。英文字符串相似度计算的方法有很多,可采用简单的编辑距离或Jaro-Winkler距离进行计算。
(2)二阶相似度计算
二阶相似度的计算采用加权编辑距离,这种模型适用于编辑操作具有不同代价的字符串匹配,在计算Mi,j时,每次增加编辑操作相应的代价,而不是简单地加1。这也符合本文所讨论的情况。在考虑汉字“成簇性”的前提下,汉字之间具有相似度,所以在中文字符串匹配中,替换操作的代价不能仅凭0、1表示。为了体现原始字符与替换字符之间的相似度,令替换操作的代价为两个汉字的相似度。设x与y为中文字符串中的单个汉字,则各编辑操作的代价为:
δ(x,ε)=1,δ(ε,y)=1,δ(x,y)=Sim(x,y) (2)
其中:δ(x,ε)为删除操作的代价;δ(ε,y)为插入操作的代价;δ(x,y)为替换操作的代价;Sim(x,y)为汉字x与y的相似度。
由此,改进后的编辑距离矩阵M′计算过程为:
M'0,0=0M'i,j=M'i-1,j-1,如果Si=Tj M'i,j=min(M'i-1,j-1+Sim(Si,Tj),M'i-1,j+1, M'i,j-1+1),如果Si≠Tj (3)
将式(3)与式(1)合并为:
M'0,0=0M'i,j=M'i-1,j-1,如果Si=Tj M'i,j=min(M'i-1,j-1+Sim(Keyfeature(Si),Keyfeature(Tj)), M'i-1,j+1,M'i,j-1+1), 如果Si≠Tj (4)
设Edit′(S,T)为改进后的编辑距离,则当i=m,j=n时,Edit′(S,T)=M′i,j。
由此得出,中文字符串的二阶相似度为:
Similar(S,T)=1-Edit'(S,T)max(m,n) (5)
4 实验与分析
4.1 实验方案
选取200对中文字符串作为源数据进行实验,涵盖音似、形似等情况。分别以传统的字符串相似度计算方法和本文提出的方法为模型,输入数据进行计算,对计算结果进行分析比较。
具体采用方法如下:
(1)传统方法:
① ED:基于编辑距离模型;
② JW:基于Jaro-Winkler距离模型。
(2)改进后的方法:
① EE+PY:以拼音编码方案为特征项,基于EE的中文字符串二阶相似度计算模型。其中,EE表示一阶相似度与二阶相似度采用编辑距离计算。
② EE+WB:以五笔编码方案为特征项,基于EE的中文字符串二阶相似度计算模型。
③ JE+PY:以拼音编码方案为特征项,基于JE的中文字符串二阶相似度计算模型。其中,JE表示一阶相似度采用Jaro-Winkler距离计算,二阶相似度采用编辑距离计算。
④ JE+WB:以五笔编码方案为特征项,基于JE的中文字符串二阶相似度计算模型。
4.2 评判标准
由于对相似度计算方法的优劣评判还没有一个较为通用的标准,因此本文采用了人工判别的方法对相似度计算的几种模型进行评价。具体方法为:当相似度小于阈值0.6时,为不相似;0.6-0.7为基本相似;0.7-0.8为比较相似;0.8-0.9为相似;0.9-1.0为非常相似。
4.3 结果分析
选取20组数据为样本显示,相似度计算结果如表1所示:
| 表1 相似度计算结果比较 |
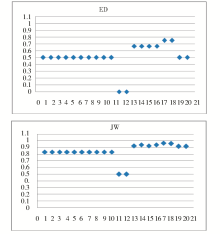
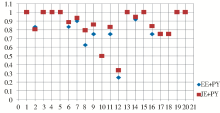
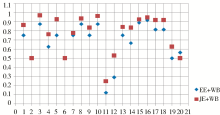
将以上结果以散点图的形式表示,横轴表示实验数据组序号,纵轴表示相似度,如图3、图4、图5所示:
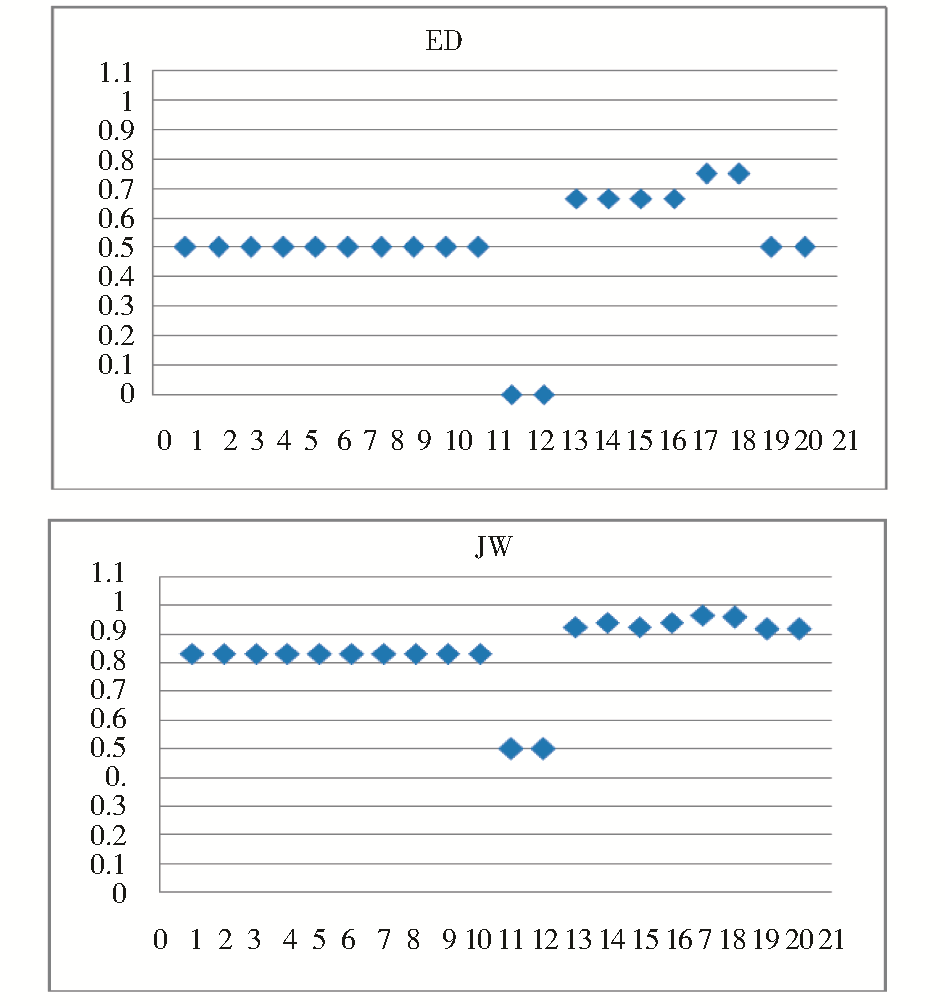 | 图3 ED与JW模型计算结果 |
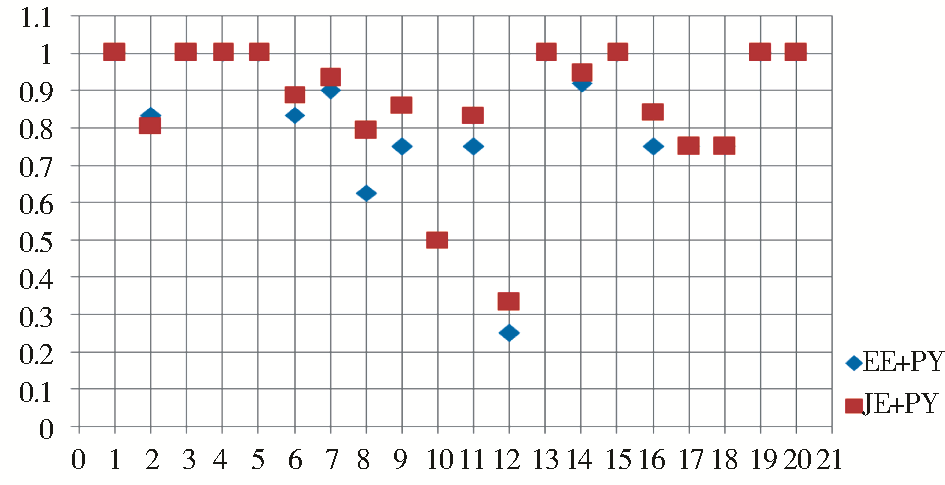 | 图4 EE+PY与JE+PY计算结果对比 |
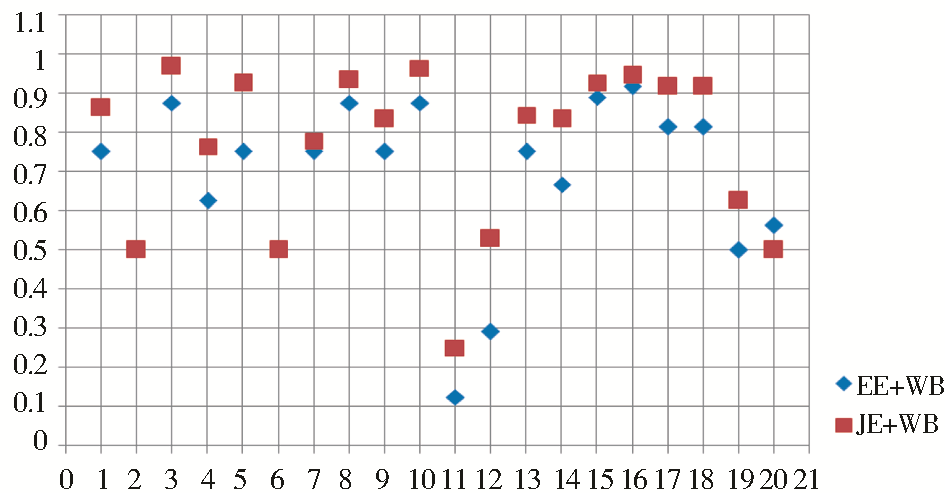 | 图5 EE+WB与JE+WB计算结果对比 |
对实验结果的具体分析如下:
(1)基于二阶相似度模型的中文字符串比较结果明显优于传统的一阶相似度模型。从图 3中可以看出,ED计算结果值偏低,不能充分反映出字符串间的相似程度,JW则偏高,过度强调了相似性,而对差异度表示不明显。而且 ED和JW中的值相对固定,不能充分表现每一组字符串的具体差异,究其原因,是由于忽略了汉字成簇性的特征。
(2)对音而言,从图4对比结果中可以看出,EE+PY的效果优于JE+PY的效果。尤其是对近音字的处理上,EE+PY所反映的相似程度效果相对较好,更加贴近人的自然判断,这可以归因为拼音中几乎不存在交换字符的现象,所以JE的修正作用难以体现。
(3)对形而言,从图5可以分析得出,JE+WB的效果优于EE+WB的效果,反映结果较为自然。即JE+WB用于形近词的相似度计算时,优势较为明显。这也与JE的换位字符修正作用有关。
(4)对于上述样本中唯一一组音、形均不相关的字符串“虚心”与“步履”,各二阶相似度模型的结果值均小于0.6,为不相似。由此可以推断出,改进后的模型更加侧重于体现字符串之间的相似程度,对不相关字符串的反映无明显差异。
(5)根据表中数据分析,二阶相似度模型中一阶相似度计算方法的选择与特征项的选择有直接关系。
综合分析,EE+PY在音方面表现较好,而JE+WB在形上表现较好,这可以归结为样本空间和一阶相似度模型的原因。拼音的样本空间较小,仅有400多个,且很少存在字符位置交换的情况,JE的修正作用不容易体现出来,而五笔编码的样本空间为20 000多个,字符换位的情况经常出现,JE的优势才可以显现出来。因此,对于样本空间小、不存在换位字符的特征项,可以采用EE模型,反之则可采用JE模型。
5 结 语
本文提供了一种更加精细化的中文字符串匹配思路,在汉字“成簇性”和相似度计算上进行了探讨,但面对丰富的汉语言文化和精深的字符串近似匹配理论,所展开的讨论还非常有限,对汉字“义”的成簇性的证明及利用、一阶、二阶相似度计算模型的选择还需要进一步深入研究。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|