





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
网络学术信息空间依赖性研究
引用本文
苏金燕. 网络学术信息空间依赖性研究. 现代图书情报技术, 2011, 27(2): 62-68
Su Jinyan. Study on Spatial Dependence of Academic Information on Internet. 现代图书情报技术, 2011, 27(2): 62-68
Permissions
Su Jinyan. Study on Spatial Dependence of Academic Information on Internet. 现代图书情报技术, 2011, 27(2): 62-68
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
网络学术信息空间依赖性研究
摘要
采用空间计量学理论,以定量的方法对网络学术信息的空间依赖性进行分析。研究发现,地理距离影响着网络学术信息的地理空间分布情况,当两个空间单元的地理位置越接近时,网络学术信息在这两个空间单元的分布情况越相似,网络学术信息分布的空间依赖性的确存在,但空间依赖性大小并不相同,中国网络学术信息分布的空间依赖性比美国要大。
关键词:
网络学术信息; 地理空间; 空间依赖性
中图分类号:G250
Study on Spatial Dependence of Academic Information on Internet
Abstract
It is true that the spatial distribution of academic information on Internet can be influenced by spatial proximity. That is,spatial dependence is really exist when Internet is discussed. The closer of two spaces are the stronger of spatial dependence. And spatial dependence is stronger in China than in America.
Keyword:
Academic information on Internet; Spatial space; Spatial dependence
1 引 言
地理学第一定律认为“任何事物之间均相关,而离得较近的事物总比离得较远的事物相关性要高”[ 1],也就是说地区之间的各种行为在一般情况下会存在一定程度的空间交互(Spatial Interaction),这种空间交互被称为空间依赖性(Spatial Dependence)或空间效应(Spatial Effects)。有学者认为,远程通信技术和计算机网络的关键意义是使地理空间邻近变得不太重要[ 2],“网络使距离消失”[ 3]、“世界变成平的”[ 4],但也有学者认为网络并没有使距离消失,信息鸿沟仍然存在[ 5]。网络学术信息的空间分布情况是否受地理位置的影响呢,也就是说网络学术信息的地理空间分布是否存在空间依赖性呢?如果网络信息分布的空间依赖性确实存在,那么再讨论网络信息的空间分布问题时就不宜再做各地区统计样本独立的假设,而样本独立是传统统计学的基础。本文将以中、美两国网络学术信息的空间依赖性检验为例对网络学术信息的空间依赖性进行分析。
2 文献综述
空间依赖性研究原本是空间计量经济学(Spatial Econometrics)的一个重要研究内容。20世纪70年代,Klaassen和Paelinck首次明确提出空间计量经济学概念,主要对空间依赖性、空间异质性和空间计量模型等进行研究[ 6]。Anselin在1988年撰写了《空间计量经济学:方法和模型》(Spatial Econometrics: Methods and Models)一书,对空间经济计量学进行了系统的研究,并将空间计量经济学定义为“在区域科学模型的统计分析中,研究由空间引起的各种特性的一系列方法”[ 7]。
空间依赖性研究逐渐渗透到其他学科领域。吴玉明等对2000-2002年中国大陆31个省域的创新集群及其影响因素进行了空间计量经济分析,结果发现我国省域创新在空间分布上存在异质性和依赖性,表现为比较明显的区域创新集群现象[ 8]。顾佳峰发现,在不同层级基础教育财政资源配置过程中存在比较显著的空间依赖性,即邻近地区教育财政资源配置情形会互相影响,加剧了教育财政资源配置的收敛性[ 9]。
2009年,Raper、Skupin等学者将地理学中的“空间”概念引入信息计量学领域[ 10, 11],Frenken等则在2009年提出“空间科学计量学”(Spatial Scientometrics)概念[ 12]。在此之前,图书情报领域学者已注意到地理空间邻近对网络信息分布的影响,如Holmberg等对芬兰政府网站信息分布情况进行研究时发现地理位置对信息分布存在重大影响[ 13],Kawamur等利用网络链接分析方法对日本公共图书馆之间的信息分布情况进行分析,同样发现地理位置对信息分布的影响[ 14],但这些研究未从空间计量角度对此进行揭示。
本文从空间计量分析的角度,将空间计量经济学引入信息计量学领域,采用空间计量分析工具定量研究网络学术信息的空间依赖性,即地理距离对网络学术信息地理空间分布的影响,并以Windows Live和Yahoo两个搜索引擎为数据采集工具,搜索中、美两国在物理学纳米材料主题、医学艾滋病主题和图书馆学数字图书馆主题三个研究领域的网络学术信息,对网络学术信息的空间依赖性进行检验。
3 空间依赖性检验方法
处理空间数据主要有两种方法,数据驱动法和模型驱动法。本文采用的是数据驱动法,就是“数据代表自己说话”,常见的数据分析方法有Moran′s I、Moran散点图、LISA检验、G统计量等。这些方法的有效性已经在区域经济学领域、科学学领域得到检验[ 15]。
3.1 空间权重矩阵
空间依赖性判断是以空间权重矩阵为基础,本研究用空间权重矩阵来表达中美两国各省份(各州)之间网络学术信息的空间依赖性[ 16]。空间权重矩阵通常用W表示,是一个n×n维的矩阵,包含关于区域i和区域j之间空间相连性与否的数据。基于空间邻近概念的空间权重矩阵为:
Wij=1 当区域i和区域j相邻0 当区域i和区域j不相邻(1)
其中,i=1,2,…,n;j=1,2,…,m。当两个邻近地区i和j有共同的地理边界时用1表示,否则用0表示。
3.2 空间依赖性判断指标
(1)全局空间相关性指标。空间依赖性可以通过全局空间相关指标和局域空间相关指标来验证,Moran′s I指数是全局空间相关性分析指标[ 17]。
Moran′s I=(2)
其中,S2=1n(Yi-Y-),Y-=1nYi,Yi表示第i地区的观测值,n为地区总数,Wij为空间权重矩阵中的元素。Moran′s I的取值范围是-1到1之间,如果各地区间网络学术信息的地理空间分布行为是正相关的,则Moran′s I的值较大;反之,如果是负相关,则Moran′s I值较小。
通过绘制Moran′s I散点图可了解网络学术信息分布的全局空间相关性。Moran′s I散点图可将各地区的相关行为分为4个象限的集聚模式,分别识别一个地区与其邻近地区的关系。第一象限,表示高高相邻(HH),第二象限表示低高相邻(LH),第三象限表示低低相邻(LL);第四象限高低相邻(HL)[ 18]。第一、第三象限表示观测值正的空间自相关关系,第二、第四象限表示观测值负的空间自相关关系,如果观测值均匀地分布在4个象限,则表明地区之间不存在空间自相关性。
(2)局域空间相关性指标。空间依赖性判断的局域空间相关指标是LISA指标[ 7]:
LISA=ZiwijZj(3)
其中,Zi=xi-x-,Zj=xj-x-,为观测值与均值的差值,xi为局域单元i的观测值。Wij是使用行标准化形式的空间权重矩阵,wii=0,所以LISA是Zi与局域空间单元i的邻近观测单元观测值加权平均的乘积。
3.3 空间依赖性分析工具
常用的统计分析软件是以样本独立为基础的,由于空间依赖性考虑了空间邻近的影响,也就是说样本之间不再具有独立性,所以本研究不能再使用SAS、SPSS等软件进行分析。ArcGIS、GeoDa、MATLAB等是可以对空间依赖性进行分析的统计软件,本研究采用的主要是GeoDa和ArcGIS软件。GeoDa是一款免费获取软件,由美国伊利诺伊大学(University of Illinois)Anselin教授研发,可用于空间统计分析(Spatial Analysis)、多元探索性空间数据分析(Multivariate Exploratory DataAnalysis)以及全局、局域空间相关性分析(Globaland Local Spatial Autocorrelation)等[ 19]。本文使用GeoDa建立空间权重矩阵、做Moran′s I散点图、获得I指数值以及求得LISA值和LISA图对网络学术信息的空间依赖性进行分析。GeoDa采用的Shape图则主要由ArcGIS软件生成。
4 空间依赖性实证分析
4.1 实证统计样本
本文的研究对象是网络学术信息,即网络中可见的学术性信息,包括研究性论文、学术消息等,以文本格式、音视频格式等多种存储形式存在于网络中。
(1) 数据来源
以下两种方式保证采集到网络信息的学术性:
①从检索词上进行限定。本研究选取的检索词应属于学术研究范畴并具有代表性和广泛性,避免有的国家(地区)不从事该领域研究的问题出现,从而增加国家(地区)之间统计结果的可比性。
②从文件格式上进行限定。鉴于PDF文件及微软办公软件应用的广泛性,虽然网络学术信息可以文字、图片、音视频等多种形式存在,但本研究仅以PDF、DOC、XLS、PPT、TXT类型的文件作为采集对象。
由于学科差异的存在,以物理学的纳米材料主题、医学的艾滋病主题和图书馆学的数字图书馆主题三个学科的94个关键词作为检索词。
(2)数据采集
由于本研究要进行94次检索,而每次的检索结果都会比较大(取每个检索结果前1 000条左右),所以最终选用带有应用程序接口(API)可以自动收集检索结果的Windows Live和Yahoo作为研究用搜索引擎。这些搜索引擎虽然是为一般的网络信息搜索设计的,但其检索结果比一般的网络爬行软件甚至一些专门的信息搜集组织搜集的数据要好[ 20],在网络信息计量学领域得到了广泛使用,比如估算某一网站的访问次数、根据检索式获取一系列的URL地址等[ 21]。另外,笔者先期进行的实验性测试结果显示,这两个搜索引擎的覆盖率、检索结果排序等均满足本研究需求。虽然Google有API接口,但是自2006年12月5日开始就不再发放API密匙,故未采用。未采用学术搜索引擎进行数据采集,因为学术搜索引擎如Google Scholar的检索结果有很大一部分为正式发表的学术论文,与从商业数据库中检索的结果具有较大相似性,不能很好地反映纯网络中学术信息的情况。本文数据采集时间是2010年1月21日,为截面数据。
(3)数据整理
①对每个关键词分别用两个搜索引擎进行检索,并将得出的检索结果进行汇总。
②对汇总数据进行清洗,删除重复数据(因为采用了两个搜索引擎,所以检索结果会有一定重复),如果两个URL完全相同则判定为重复数据。
③使用IPNetInfo等工具进行URL到具体省份的批量转换,辅以人工判断,最终确定各省份的统计样本,如表1所示:
| 表1 基于搜索引擎的网络学术信息空间依赖性研究的样本容量表 |
在得到统计样本后,抽取中美两国各100条数据进行人工判断,其中美国抽取数据合格率为89%,中国数据合格率为84%。为消除学科差异带来的影响,进行空间依赖性分析时笔者将每个学科的数据进行了归一标准化处理。
4.2 空间权重矩阵计算
采用ROCK算法计算我国33个省市自治区(包括香港和台湾,但不包括澳门)空间邻近矩阵如表2所示。
在表2中,“1”代表两个省份存在邻接关系,否则代表无邻接关系,比如黑龙江省(1号)有2个邻接省份,分别是内蒙古自治区(2号)和吉林省(4号)。在33个省份中内蒙古自治区(2号)和陕西省(11号)的邻接省份最多,分别有8个;海南省(31号)和台湾省(30号)的邻接省份为0,也就是说这两个省份在地理空间上是孤立的,不与其他省份搭界。美国的空间权重矩阵计算方法与中国相似,计算结果不再详细列出。
| 表2 中国空间依赖性分析的空间权重矩 |
4.3 全局相关性检验
从中国、美国两个角度对网络学术信息的空间相关性进行检验,首先检验中国网络学术信息的全局空间相关性。
(1)中国网络学术信息空间全局相关性检验。中国网络学术信息空间依赖性检验Moran′s I散点图,如图 1所示。
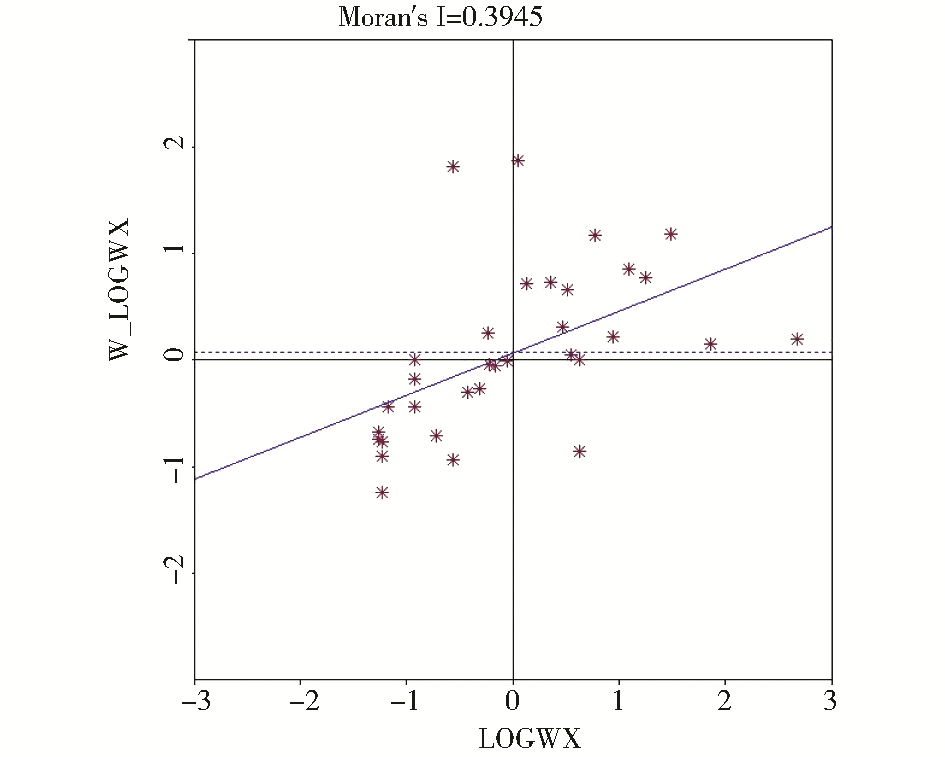 | 图1 中国网络学术信息空间依赖性检验Moran′s I散点图 |
从图 1可以看出,中国的Moran′s I=0.3945,其正态统计量Z值大于正态分布函数在0.01水平下的临界值(1.96),这说明从中国网络学术信息地理空间分布的全局存在明显的正的空间自相关性。通过Moran散点图可以判别发现HL类型和LH类型的省份为偏离全国正的空间自相关总体分布趋势的省份。位于第一象限的省份是山东、河南、江苏、安徽、湖北、上海、浙江、江西、福建、台湾、广东、香港、河北和北京14个省份,是“高高”的正自相关关系的集群(HH),网络学术信息分布数量多的省份被网络学术信息分布数量多的省份包围;湖南、天津两个省份位于第二象限,为“低高”的空间自相关关系的集群(LH),网络学术信息分布数量少的省份被网络学术信息分布数量多的省份包围;黑龙江、陕西、宁夏、青海、西藏、内蒙古、云南、重庆、广西、贵州、新疆、吉林、辽宁、甘肃共14个省份位于第三象限,是“低低”的空间自相关关系的集群(LL),网络学术信息分布数量少的省份被网络学术信息分布数量少的省份包围;四川位于第四象限,是“高低”的空间自相关关系的集群(HL),网络学术信息分布数量多的省份被网络学术信息分布数量少的省份包围。海南、山西两省同时跨越了第二、第三象限。
(2)美国网络学术信息空间全局相关性检验。美国网络学术信息空间依赖性检验Moran′s I散点图,如图 2所示:
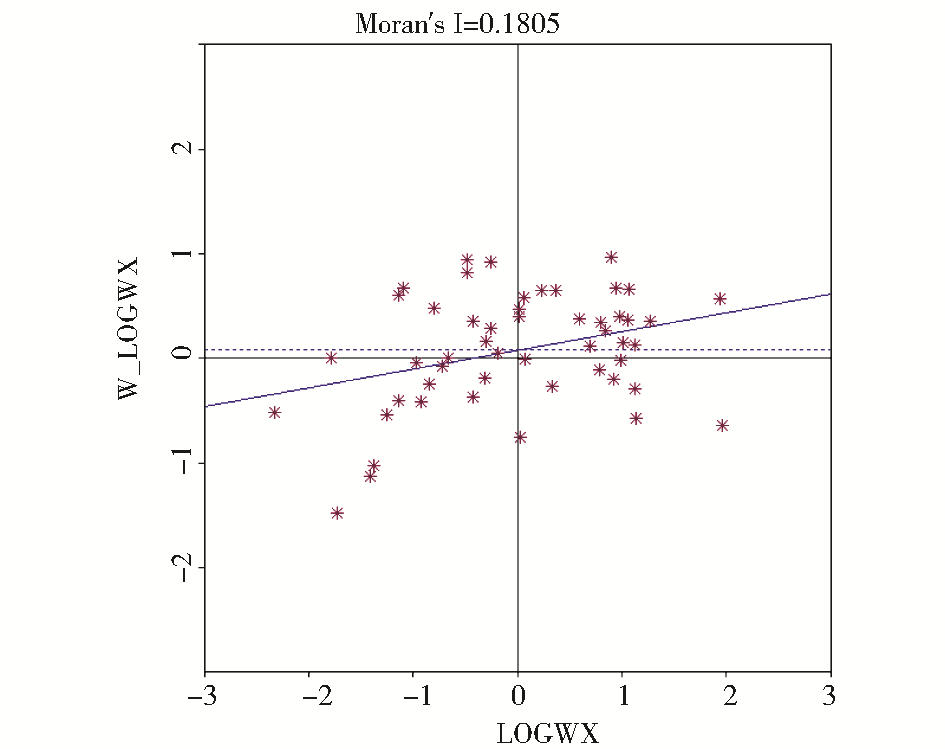 | 图2 美国网络学术信息空间依赖性检验Moran′s I散点图 |
从图2可以看出,Moran′s I=0.1805,Z值大于正态分布函数在0.01水平下的临界值。美国网络学术信息空间分布同样存在正的全局自相关性,只是相关性与中国相比略微小一些(0.1805<0.3945),且在4个象限的分布比较均匀。
4.4 局域相关性检验
由于Moran′s I散点图没有给出网络学术信息空间分布显著性水平的具体数值,因此有必要通过进一步测算局域空间自相关LISA显著性水平和局域统计值,深入探索网络学术信息地理空间分布的格局及地理空间上的可能成因。
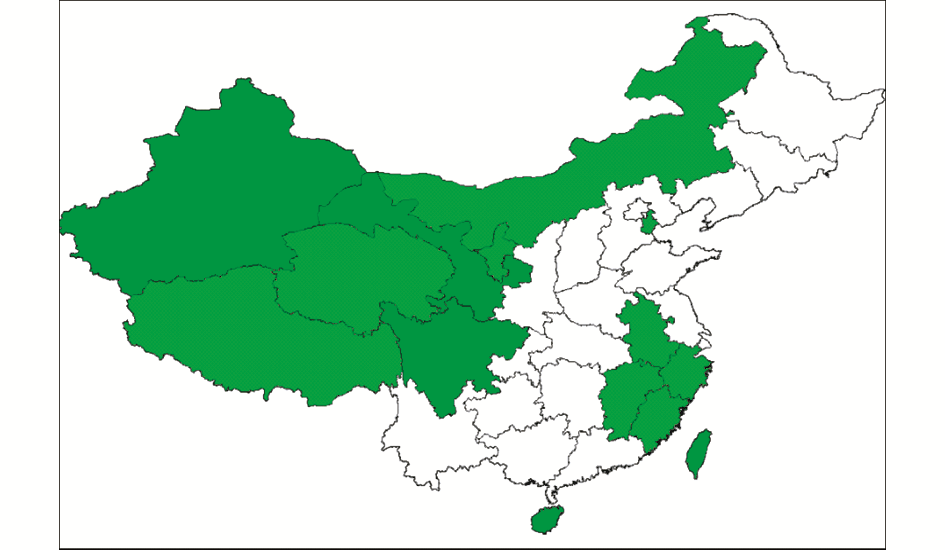
(1)中国网络学术信息局域空间相关性检验。我国网络学术信息局域空间自相关LISA显著性水平和LISA集群如图 3和图 4所示:
 | 图3 中国网络学术信息局域空间自相关LISA显著性水平图 |
 | 图4 中国网络学术信息局域空间自相关LISA集群图 |
图3显示了我国网络学术信息局域空间自相关LISA显著性水平。在LISA显著性水平图中,空间自相关检验表现为显著性的LISA省份是用不同的颜色标识出来的对应于Moran′s I散点图不同象限的省份。结果发现,内蒙古、北京、浙江、福建、安徽、江西、青海、西藏8个省份的网络学术信息空间分布通过5%水平的显著性检验,而新疆、甘肃、陕西、海南和台湾通过1%水平的显著性检验。由LISA显著性水平图可以看出,我国网络学术信息空间依赖性显著的省份分布在沿海和西部地区。
图4显示了我国网络学术信息局域空间自相关LISA集群。在LISA集群图中,红色省份(HH)代表网络学术信息分布数量多的省份被网络学术信息分布数量多的省份包围,为网络学术信息空间分布数量多的省份;蓝色省份(LL)代表网络学术信息分布数量少的省份被网络学术信息分布数量少的省份包围,为网络学术信息空间分布数量少的省份;淡蓝色省份(LH)显示了网络学术信息分布数量少的省份被网络学术信息分布数量多的省份包围;浅红色省份(HL)显示了代表网络学术信息分布数量多的省份被网络学术信息分布数量少的省份包围。图 4的LISA集群图显示以上海为中心的长江三角地区的各个省份、以北京为中心的环渤海省份倾向于分布在第一象限,其显著特点是网络学术信息在这些省份分布的数量很多,与其邻近省份存在正相关的关系。
(2)美国网络学术信息局域空间相关性检验。美国网络学术信息局域空间自相关LISA显著性水平和LISA集群如图 5和图 6所示:
 | 图5 美国网络学术信息局域空间自相关LISA显著性水平图 |
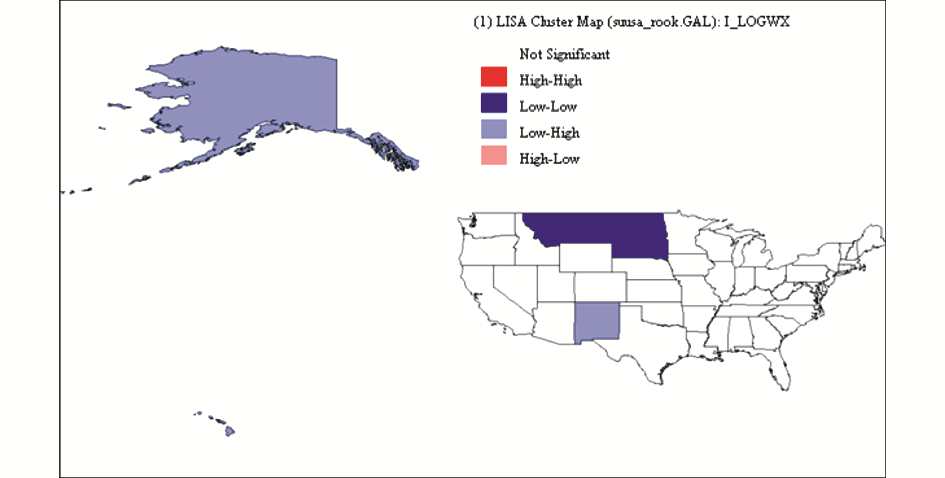 | 图6 美国网络学术信息局域空间自相关LISA集群图 |
图5显示了美国网络学术信息局域空间自相关LISA显著性水平。结果发现,仅北达科他州、新墨西哥州、夏威夷三个州的网络学术信息空间分布通过5%水平的显著性检验,阿拉斯加、蒙大拿和南达科他州通过1%水平的显著性检验。图6显示了美国网络学术信息局域空间自相关LISA集群,从中可以看出美国没有HH地区和HL地区,仅有少数几个LL和LH地区。美国网络学术信息地理空间分布的自相关性与中国相比要弱,也就是说网络学术信息在美国一个州的空间分布情况受其邻近州网络学术信息分布情况的影响比较小。
5 结 论
(1)网络学术信息的地理空间分布存在空间依赖性。对网络是否消减空间邻近作用的疑问,从网络学术信息地理空间分布空间依赖性检验的结果看,网络学术信息的地理空间分布仍然存在很强的空间依赖性,网络学术信息的地理空间分布情况并没有因为存在于虚拟网络而不存在地理空间自相关性。可以说,两个空间单元的地理空间情况,特别是地理距离影响着网络学术信息的空间分布情况。当两个空间单元的地理位置越接近时,网络学术信息在这两个空间单元的分布情况越相似。
(2)网络学术信息地理空间分布空间依赖性大小并不相同。根据检验可知,中国网络学术信息的全局空间相关性检验Moran′s I=0.3945。美国的检验结果是Moran′s I=0.1805,与中国相比要小很多,也就是说网络学术信息在美国各州之间的空间分布情况受地理空间的影响要小很多。因此,可以说网络学术信息地理空间分布的空间依赖性确实存在,但空间自相关性对各国家影响的大小存在一定差异。
通过检验,网络学术信息空间分布的空间依赖性确实存在,那么今后在对网络信息空间分布问题进行研究时是否需要重新考虑统计样本的独立性以保证统计结果的可靠性;考虑空间依赖性与不考虑空间依赖性对研究网络信息的空间分布情况是否有影响,影响有多大;在对期刊的空间分布、网站的空间分布等问题进行研究时,是否也需考虑空间依赖性的影响;这些都有待进一步研究。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|