{kind=link}
{kind=link}
基于CRFs自动构建维吾尔语情感词语料库*
引用本文
冯冠军, 禹龙, 田生伟. 基于CRFs自动构建维吾尔语情感词语料库* . 现代图书情报技术, 2011, 27(3): 17-21
Feng Guanjun, Yu Long, Tian Shengwei. Auto Construction of Uyghur Emotional Words Corpus Based on CRFs. 现代图书情报技术, 2011, 27(3): 17-21
Permissions
Feng Guanjun, Yu Long, Tian Shengwei. Auto Construction of Uyghur Emotional Words Corpus Based on CRFs. 现代图书情报技术, 2011, 27(3): 17-21
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于CRFs自动构建维吾尔语情感词语料库*
摘要
提出维吾尔语情感语料库的构建规范,设计和实现维吾尔语情感语料库辅助整理系统。该系统结合维吾尔语情感语料的具体特点,多方面分析维吾尔语情感词汇的特征,利用条件随机场(CRFs)模型进行维吾尔语情感词汇的自动识别。测试结果验证该系统能够大幅度降低人工劳动,高效快速地标注维吾尔语情感词语料。
关键词:
维吾尔语; 情感语料; 语料库构建
中图分类号:TP391
Auto Construction of Uyghur Emotional Words Corpus Based on CRFs
Abstract
This paper proposes uyghur emotional corpus construction specifications and develops uyghur emotional corpus processing system.Combined with the specific characteristics of uyghur emotional words,this paper proposes the full analysis of characteristics of uyghur emotional words in the text,achieves the uyghur emotional words automatic identification method with CRFs model.Experimental results show that the system can effectively process emotional words corpus, and reduce the manual workload.
Keyword:
Uyghur; Emotional corpus; Corpus construction
1 引 言
倾向性分析(也称情感分类),近年来受到了广泛关注[ 1, 2, 3, 4]。倾向性分析的目的是判断给定的文本片段(词汇、短语或文档)中所体现的说话者的情感倾向[ 5],如褒、贬等。该技术能够帮助企事业部门对文本进行快速有效的情感分析,在情报搜集、产品推荐、民意调查、舆情分析[ 6, 7]、商业智能、报刊编辑等工作中起到重要作用。
情感语料库的构建是情感分类的基础,全面、大量和高质量的情感语料能够为文本情感分类研究提供充分的数据保障。
本文依据维吾尔语的特点,制定了情感语料库构建规范和质量保证方法。笔者结合维吾尔语情感表达的语言特点,利用统计方法,设计了情感词汇的自动标注模型,并开发和实现了维吾尔语情感语料辅助整理系统。
2 需求及技术思路
2.1 研究现状
国内外针对情感计算方法的研究较多,而情感语料库的构建研究相对较少[ 3]。国内汉语情感语料库有厦门大学的全宋词情感语料库[ 4],大连理工大学的平衡语料库[ 5]。国外较著名的英语情感语料库有Pang语料库[ 2]和电影评论语料库[ 8]。国外英语的情感分析技术已经拥有较完备的体系[ 2, 8],汉语相关研究起步不久[ 5],查阅近年国内外重要文献,尚无关于维吾尔语情感分析及语料库建设的研究。
英语和汉语的情感语料库构建,一般采用基于统计和规则的方法。无论何种语言,都需要分析语言的具体特征,设计自动或半自动的情感词汇识别模型,用于提高语料整理的效率。维吾尔语不同于英语和汉语,属于阿尔泰语系突厥语族,书写方式是从右至左的顺序,语法结构通常为主+宾+谓结构。同时,维吾尔语属黏着型语言,是一种有形态变化的语言类型,其形态结构远比英语和汉语复杂。而且,相对于英语和汉语,维吾尔语没有WordNet和HowNet等已经建立好的语义关系,因此自动获取维吾尔语情感词汇较中英文更加困难。
2.2 需求分析
情感语料库构建是一项繁琐、人工劳动量巨大且质量要求很高的工作。单纯凭借人工,不仅需要极高的人力成本而且建设周期过长,同时,语料的质量也无法得到有效保障。因此,制定适合于维吾尔语特点的情感语料收集和标注规范、开发具有自动或半自动化的辅助情感语料整理系统,对快速收集、标注语料、有效实施质量监控、减轻人工劳动起着重要作用。
2.3 技术思路
一篇未加工的情感原始语料(文本文件)需要经过篇章级别、句子级别和词汇、短语级别的属性和情感类别标注,最后存入数据库,形成情感语料。具体的思路如图1所示。
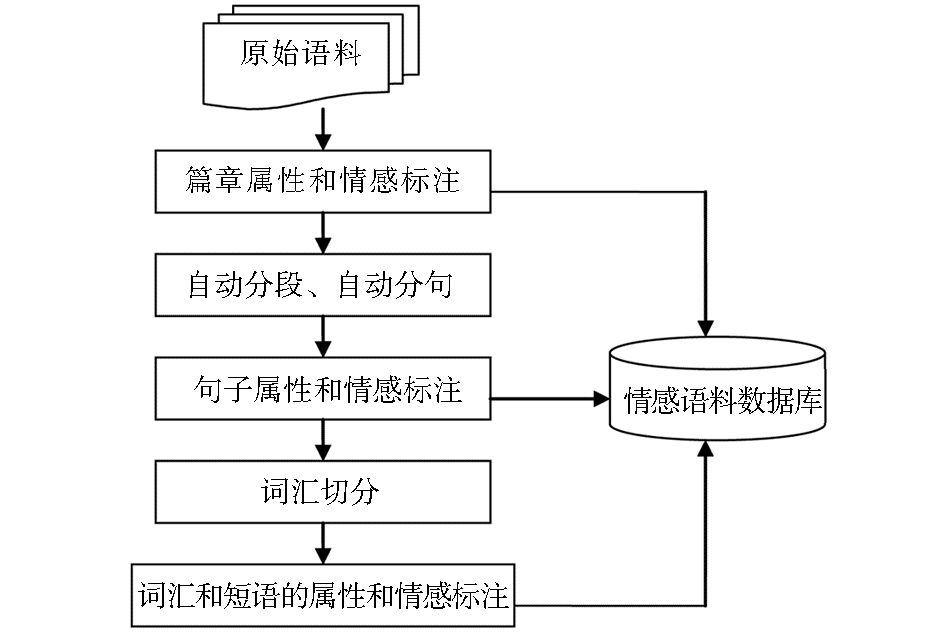 | 图1 情感语料整理思路 |
(1)将搜集的篇章级别的原始语料(文本文件)导入系统,标注篇章级别的属性和情感类别。
(2)依据回车符号,将篇章语料自动分段,再按照维吾尔语句子结束的标点符号对每段进行自动分句,对得到的句子标注句子属性和情感类别。
(3)依据空格符号,将句子自动切分成单词,对得到的单词标注词汇属性和情感类别,同时标注由单词组合短语的属性和情感类别。
3 实现方案
3.1 语料收集和标注规范
(1)语料收集
为了降低成本,语料主要从专业媒体部门和网络中的Web页面获取。同时,收集的语料包含了新闻、童话、小说、网评、自传、纪实、笑话、戏剧、诗歌、散文等多种体裁,充分保证了语料的多样性。
(2)标注规范
新浪网站将网民浏览新闻时的心情分为8类,搜狐网站分为6类,文献[9]分为6类,心理学家林传鼎将情绪划分为18类[ 10],许小颖等分为24类[ 11]。为了减少过细划分情感类别带来的混乱,降低对研究带来的干扰,同时考虑褒、贬两种情感的巨大应用市场,将情感类别划分为7类:褒、贬、乐、哀、怒、恐、惊。
①篇章级文本的情感标注属性:作者、文章来源、作品时代、发表时间、风格、态度、立场和情感类别。其中态度分为积极、消极和中性;立场分为正面、负面和中性。
②句子级别的情感标注属性:态度、立场、句型结构、修辞方法、病句特征和情感类别。
③词汇和短语级情感标注属性:词汇和短语的词性、词干和情感类别。
(3)质量保证方案
①约束规则
分析发现,在句子级别的标注时,“褒”和“贬”,“乐”和“哀”类别的标注往往是互斥的,而“贬”和“怒”伴随发生的概率比较高;“积极”和“负面”,“消极”和“正面”互斥的概率较高。因此,在程序设计中采用伴随发生和互斥约束规则,对人工标注的结果进行检验,一旦出现违反约束规则的结果,就提示标注人员进行校对。
②管理技术
由于不同个体对同一文本的情感判断存在差异,导致标注结果不一致。为了减少不一致现象,可以采用人工双重标注方法,即对同一语料采用双人分别标注,若标注结果一致,则通过,否则采用第三人校对加以更正。
3.2 维吾尔语情感词汇自动识别
情感词汇的情感类别标注,是情感倾向研究的基础性工作,也是语料整理过程中工作量最大的部分,全人工标注成本极高。情感词汇自动识别技术是情感语料构建技术的基础核心,高效的情感词汇自动识别技术,能够有效降低人工标注劳动强度,对快速扩大情感词汇库有重要意义。
(1) 条件随机场(CRFs)[ 12]
给定数据序列随机变量X,标注结果序列随机变量Y的条件概率分布P(Y|X),要求条件概率P(Y|X)最大。CRFs是无向图模型,线性CRFs模型中各个节点之间构成线性结构。设x=(x1,x2,…,xn)表示待标注的观察序列,y=(y1,y2,…,yn)表示标注的输出序列,则CRFs定义为:
P(y|x)= 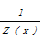


其中,fk是观察序列x中位置为i和i-1的输出节点的特征,gk是位置为i的输入节点和输出节点的特征,λ和μ是特征函数的权重,Z是归一化因子。
CRFs能够充分利用上下文信息作为特征,可以任意添加外部特征,使得模型能够获取的信息非常丰富。同时, CRFs克服了隐马尔科夫(HMM)独立性假设和最大熵马尔科夫(MEMM)模型的偏置问题,因此可有效应用于情感词汇的自动识别。
(2) 基于CRFs的维吾尔语情感词汇的语言规律分析
CRFs特征模板的设计来源于语言规律,语言规律总结是否合理能够决定特征模板的优劣。在维吾尔语语言学专家的帮助下,笔者分析了维吾尔语的语言现象,总结了维吾尔语情感词汇的5类语言规律。
①词性规律
维吾尔语情感词汇多分布在形容词、名词、动词中,在其他词性词汇中分布较少,这种特征使得词汇的词性规律可以用于情感词汇的识别。
②词和词性规律
情感词汇本身和其附近词汇、词性也存在一定规律,因此,也可作为识别特征。
③副词修饰规律
副词修饰的中心词往往是具有主观用意的情感词汇,如:

湖在蓝天的烘托下显得更加美丽
因此副词与形容词等词性的词汇修饰搭配的规律能够作为情感词汇发现的特征。
④否定词搭配结构规律
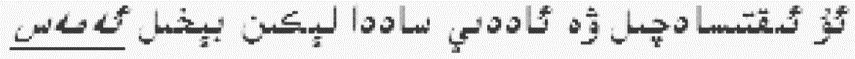
人家是朴素,可并不是贫气
单词 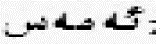
⑤特定规律
特定规律包含两大类,第一类主要是连词、非连续的固定搭配结构等,如:
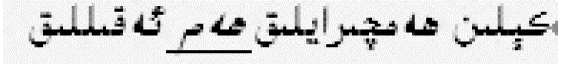
新娘既美丽又聪明
单词 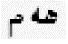
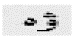
第二类主要是形态否定式,如:
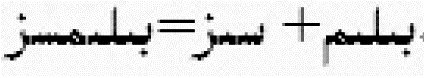
无知的 = 无(否定词缀) + 知识(名词)
词缀 
(3)特征模板
依据情感词汇的语言规律,相应地设计了CRFs的5类特征模板,具体参数设计如表1所示。
①词性搭配特征模板
情感词和前后一个词的词性高度相关,可得到特征模板%x[-1,1],%x[1,1],%x[-1,1] %x[0,1] %x[1,1];情感词与前面的第1、2个词词性搭配,与后面的第1、2个词词性搭配具有较高的精度约束关系,可以得到特征模板%x[0,1] %x[1,1] %x[2,1],%x[-2,1] %x[-1,1] %x[0,1]。
| 表1 特征模板 |
②词和词性特征模板
以情感词为中心,抽取与其相关的上下文语境:情感词与前面1个词、前面第2个词、后面1个词、后面第2个词,与前1个词词性,后面1个词词性,得到特征模板%x[-1,0]、 %x[-2,1]、%x[1,0]、%x[1,0]、%x[2,0]、%x[-1,0] %x[0,1]、%x[1,0] %x[0,1]。
③副词修饰特征模板
情感词汇经常受副词修饰,且副词出现在情感词汇前第1个词的位置,因此得到特征模板%x[-1,2]、%x[0,1]%x[-1,2]。
④否定结构特征模板
考察情感词汇和一般否定式的搭配现象:情感词后面1个词是否是否定词、情感词词性和后面第2个词是否是否定词,可得到特征模板%x[0,1]%x[1,3]、 %x[0,1]%x[2,3]。
⑤特定特征模板
特定特征是一些维吾尔语具体的语法特征,得出的特征模板数量较多,限于篇幅此处略。
3.3 系统实现
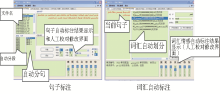
利用C#开发平台,实现维吾尔语情感语料辅助整理系统,如图2所示:
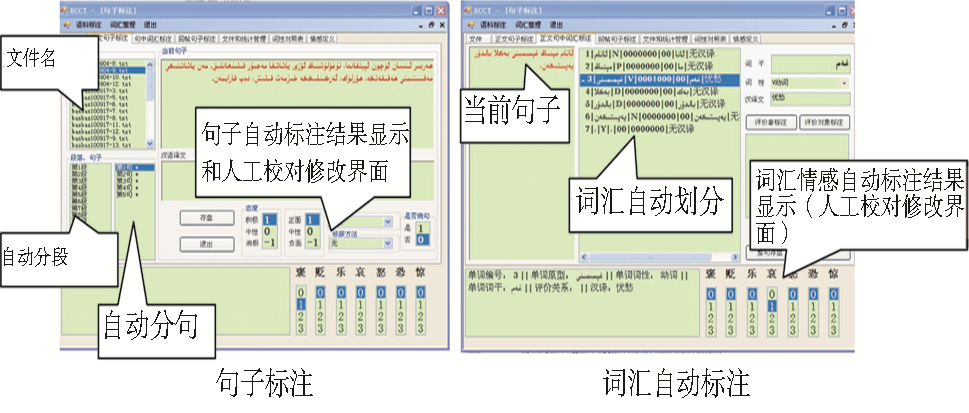 | 图2 情感语料辅助整理系统主要界面 |
系统包含的主要模块有:
(1)原始语料导入模块:读入原始语料文件,去除噪音格式,生成Unicode编码的标准格式文件。
(2)句子标注模块:将标准格式文件自动切分成多个段落,对每个切分的段落自动切分成多个句子,然后对划分的句子进行句子的情感类别和属性标注,用户可以审核校对标注信息。
(3)词汇标注模块:将一个句子自动切分成多个单词,对每个单词进行情感的自动标注。用户可以对自动标注结果进行浏览、校对。
(4)质量约束模块:利用伴随发生和互斥约束规则模块,对句子、词汇和短语的情感标注结果进行检验,对可疑标注结果做警示标记。
4 应用效果评估
4.1 实验数据来源
搜集415篇共计12 528个句子的维吾尔语主观语料,经语言专家审核后,作为实验语料。
4.2 实验方法和效果
实验步骤如下:
(1)对语料进行词性标注、否定词标注;
(2)由语言专家人工标注语料中情感词汇的情感类别;
(3)采用三倍交叉验证法分割语料,即:将语料随机分为数量相等的三部分,其中三分之二作为训练数据,其余三分之一语料作为测试数据;
(4)利用训练数据训练CRFs,然后自动标注测试语料中词汇的情感类别。CRFs的特征模板采用表1中的5类特征模板,并选择增量式引入,即:逐步在上一级特征模板的基础上增加下一级模板。
(5)比对自动标注结果和事先人工标注的结果,计算正确率、召回率和FB1。其中:
正确率P= 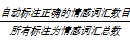
召回率 R= 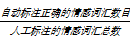
FB1= 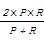
实验结果如表2所示。
| 表2 情感词汇识别结果 |
可以看出,随着特征模板不断加入,情感词汇发现的正确率不断提高,召回率随着特征模板的增加逐步趋于稳定,自动标注的情感词汇达到了64.6%的正确率和55.3%的召回率。该系统经语料整理专业人员应用后验证,语料整理效率比完全人工整理得到了大幅度提高。
5 结 语
本文详细阐述了维吾尔语情感语料库的构建规范和实现技术,并开发了情感语料辅助整理系统。在分析维吾尔语情感词汇的语言特征的基础上,设计和实现了基于CRFs模型的情感词汇自动标注系统。实际应用验证,该系统大幅度降低了人工劳动,提高了语料整理效率,为快速扩大语料提供了有力保障。
目前,已经完成了500余个篇章、15 000多句子、120 000多个单词的维吾尔语情感语料的整理和标注工作。最终目标是构建容量为50 000个句子的情感语料库。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|