{kind=link}
{kind=link}
基于锚与链接文本扩展的KBES算法隧道策略
引用本文
乔建忠. 基于锚与链接文本扩展的KBES算法隧道策略. 现代图书情报技术, 2011, 27(3): 45-50
Qiao Jianzhong.Anchor and Link Text Expansion Based KBES Algorithm Tunneling Strategy.现代图书情报技术, 2011, 27(3): 45-50
Permissions
Qiao Jianzhong.Anchor and Link Text Expansion Based KBES Algorithm Tunneling Strategy.现代图书情报技术, 2011, 27(3): 45-50
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于锚与链接文本扩展的KBES算法隧道策略
关键词:
主题搜索; 隧道技术; 搜索算法; 主题爬行器
中图分类号:G250.73
Anchor and Link Text Expansion Based KBES Algorithm Tunneling Strategy
Abstract
On the basis of summary of “true or false tunnel” strategy on focused crawler, this paper proposes a new KBES algorithm to solute the “false tunnel” problem. The experiments prove that KBES algorithm can improve the efficiency to predict the relevance of new links by anchor and link text in the heuristic strategies to some extent.
Keyword:
Focused crawling; Tunneling; Search algorithm; Focused crawler
1 引 言
隧道被认为是Internet中两个相关主题群落间的未知区域,如图1所示。如何穿过隧道进入高相关度主题区域是主题搜索技术需要解决的一个重要问题。
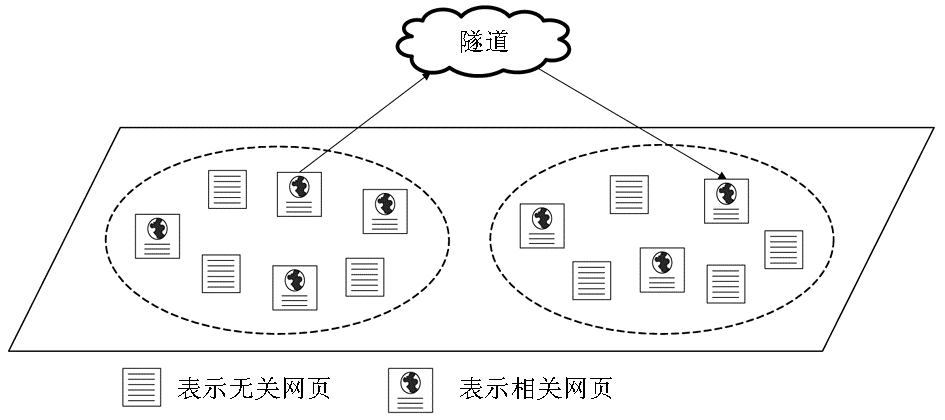 | 图1 主题群落间隧道示意图 |
传统的“最好优先算法+分类器”式的主题爬行器存在隧道瓶颈问题,如:Chakrabarti等[ 1]提出软焦距爬行,网页按概率进行主题分类,但面对隧道效应,无法从无关网页再到相关网页爬行。搜索算法中遇到的较大问题就是相关主题群落之间的这条未知的隧道瓶颈。它的产生原因可能来自以下几个方面:
(1)客观存在着一条不相关的隧道
本文将这类隧道称为“真隧道”。例如对两个具有竞争关系的商业网站互相之间不直接相连,可借助提供多个种子地址的手段来实现穿越隧道的目的。
(2)搜索算法中的特征因子不能真实、全面地反映当前链接与主题的相关性
本文将这类隧道称为“假隧道”。例如,如果采用锚文本或链接文本预测链接的相关性,那么通常会因为锚文本或链接文本中传递的信息量较少,不足以命中查询关键词而造成相关性判断上的一定程度的迷失。此时就需要采取相应的措施来合理丰富特征因子的信息量,从而实现穿过隧道的目的。
实施隧道策略首先需要区分隧道的不同种类,再按不同情况的最佳方案处理。针对不同隧道采用何种隧道技术是问题的关键。目前已有较多文献涉足该领域。
2 相关研究
针对“真隧道”策略的研究,Ester等[ 2]指出具有竞争关系的网站之间联系不紧密,借助Hubs(中心页)比通过判断主题相关性更有效。通常Hubs的获取方法通过API自动检索Google或Yahoo!等通用搜索引擎,在返回排名前列的结果中进行筛选得到。Shchekotykhin等[ 3]则认为利用通用搜索引擎将受到诸如检索失败或客户端检索次数超限等问题,因此在其“xCrawl”爬行技术研究中利用HITS+Topic-Sensitive PageRank搜索算法去主动发现Hubs,并基于“网页间距离增大则相关度减小”的假设采取“重启”策略来避免爬行器陷井问题。
针对“假隧道”策略的研究,可归纳为两类技术:调节特征因子的相关度权重法和变换主题法。
(1)调节特征因子的相关度权重法的基本原理是通过调节影响链接优先级的特征因子的权重,将不相关的链接调整为相关链接并作为“跳板”来达到穿过隧道找到目标网页的目的。在不转换主题的情况下,调节特征权重的方法需要解决调节的度量和链路距离问题,为此Diligenti等[ 4]设计的“Context-Graph-Based Crawler”学习一个到目标主题的链接语境图(链接层次关系)来估计当前页与目标页的距离并优先爬行距目标最短距离的链接。其缺点是需借助通用搜索引擎和Backlinks建立语境图。McCallum等[ 5]和Rennie等[ 6]在其“Cora’s Focused Crawler”中通过强化学习算法决定爬行策略,从一个特定链接开始在锚附近文本中寻找未来回报并通过分类器学习通往目标的链接路径,但对预期建模的能力限制在4层链接距离以内。为扩大预测的链接距离,傅向华等[ 7]、黄莉等[ 8]和谭骏珊等[ 9]均基于改进的强化学习爬行算法,将回报沿链接链路反馈,更新链路上所有链接的Q值,并选择相应的特征文本作为训练样本,增量地改善网页分类评估器和Q值预测器。
(2)变换主题法的基本原理是借助其他相关主题达到扩大搜索范围穿过隧道的目的。主要利用概念上的相关性解决字面上的相似性匹配带来的问题。常用的方法是构建领域本体,利用本体对用户的查询关键词按实体间关系进行扩展。例如Ehrig[ 10]、Ester等[ 11]和杨贞[ 12]研究通过上位类或语义关系找到目标网页。该方法有利于迅速提高查全率,但具有本体建设成本较高、领域局限性和权重设定的主观性等不足。Mouton等[ 13]则认为避免歧义最好从多个角度表示主题,于是提出主题表示的4种方法,即ODP、Wikipedia、Keywords和WordNet。
本文所提出的KBES算法适用于“假隧道”问题,但有别于现有的调节特征因子的相关度权重法和变换主题法。
3 KBES算法
3.1 算法原理
用户输入的查询关键词往往不能较完整地表达用户对主题的需求,这就需要通过一定的手段来弥补。查询关键词扩展法即变换主题法,通常借助本体的语义关系来扩展查询的表达空间,达到全面表示主题的目的。常用的实体间关系包括同义、反义关系、分类或等级关系以及非分类关系等被称为“语义网络”。但在实践中发现本体领域依赖性较强,本体的建造成本较高,常常用词典替代,如WordNet[ 14]、HowNet[ 15]等。因此笔者没有采用这一方案,而是采用对目标进行扩展的方法。这里的目标是指锚文本或链接文本等需要与查询关键词进行匹配的特征文本。该方法与前者的不同之处在于针对目标进行扩展而不是针对查询。依据的原理是如果目标关键词与查询关键词都属于相同的类目则二者相关。相关的程度则由命中的关键词在知识库(Knowledge Base,KB)中的权重决定。因此笔者将这种隧道技术称为知识库扩展搜索算法(Knowledge Base Expand Search Algorithm,KBES)。
本文采用KBES算法基于4点考虑:
(1)本文采用的主题表示方法是一种基于分类体系的关联方法。自动推荐或自定义的查询词虽然很有限,但可利用分类体系或知识库进一步丰富查询词的内涵。
(2)锚和链接文本都较容易获取。
(3)相关网页中的锚或链接文本是用来在线构建知识库的重要素材,具有更新快、不过时和人工干预少等特点。
(4)不存在领域局限性问题。
锚与链接文本是笔者用于计算陌生链接优先级的重要特征,由于链接与锚点本身的文本较短,能被用户定义的关键词所命中的机率较低,因此通过KBES算法来发挥知识库在链接相关性预测上的作用。本文中锚与链接文本也是被选作扩展的目标特征。
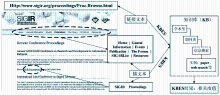
为过滤噪声提取其中的关键词,需要对目标文本进行预处理。笔者采用中英文分别处理的方法,对英文特征文本,过滤其中的名称短语后用于扩展搜索;对中文特征文本,需要经过分词和停用词过滤后保留其中的关键词用于扩展搜索。利用这些关键词在知识库中相应类目下的关键词库进行匹配,同时取得命中关键词的权重,作为扩展搜索的相关度值,参与到新链接优先级预测的算法当中。KBES算法的基本思路,如图2所示:
 | 图2 KBES算法思路(注:图中网页来自http://www.sigir.org/proceedings/Proc-Browse.html) |
KBES算法中的知识库是由类目和实例组成的分类体系。底层类目下的实例主要是用于KBES算法中扩展匹配的关键词。这些实例由主题爬行器在抓取网页过程中自动构建,知识库的基本结构如表1所示:
| 表1 知识库基本结构 |
知识库构建的基本步骤如下:
(1)建立分类体系,共4个一级类目,13个二级类目,二级类目下面再按学科领域或习惯分类。建立方式为手工建立。建立依据有两个:根据主题爬行需求的类型或根据互联网资源的种类和分布特征。
(2)为每个底层类目建立关键词集合。关键词集合分两类:反映学科领域特征的内容关键词和反映网络文档类型特征的类型关键词;关键词的属性还包括:语种、权重等,建立方式为自动建立。
关键词来源于判断为相关的网络文档中的标题、关键词、描述、摘要、链接文本、文件格式标准(MIME Type)以及用户查询7个元数据。提取出的关键词的属性在KB中的表示如表2所示:
| 表2 关键词属性示例表 |
表2中的内容特征是指该关键词是用于描述网页内容的学科领域的关键词,而类型特征是指该关键词是用于描述网页类型(如:新闻、博客、会议或讲义等)或形式的关键词。
3.2 算法伪码
在分别计算锚文本相关度和链接文本相关度均为0的情况下,才触发KBES算法,该算法包括锚文本和链接文本扩展搜索两个过程:
(1)锚文本扩展搜索
利用锚文本中的关键词或短语在知识库相应类目下的关键词库中进行匹配操作。
(2)链接文本扩展搜索
利用链接文本中的关键词或短语在知识库相应类目下的关键词库中进行匹配操作。
最后选取命中关键词的权重值作为扩展搜索相关度值。
具体算法伪码如下:
Algorithm:ExpandTextRelevance(Input)
Input: text, page, anchor_or_urltext
//输入锚或链接文本、网页、锚或链接的识别码
Output: SpecialRelevance
//输出扩展相关度值
{
Begin
LET SpecialRelevance、weight、keyword、wordcount
//初始化变量:扩展相关度、权重、关键词、命中关键词数量
language = page.languageType;
//取得网页语种
class = page.getCategory();
//取得网页所属类目
text = StringTools.SpecialTextFilter(text);
//不管中文还是英文,锚还是URL都统一过滤特殊字符
if (language ∈chinese) {//如果是中文网页
keywordset = IKSegmentation(text);
//对分词后的关键词集合进行词长和词性的过滤,保留cjk_normal,过滤掉单字符
while (keyword∈keywordset)
{
KBBCheck(keyword, class);
//在知识库的相应类目下匹配关键词
SpecialRelevance = weight / wordcount;
//计算命中关键词的平均权重
}
} else {//如果是英文网页
if (language∈english)
{
HiddenMarkovModel_pos_PhraseChunker(text);
//进行英文短语识别、POS,保留名词或名词短语,过滤单个字符等
while (keyword∈keywordset) {
KBBCheck(keyword, class);
//在知识库的相应类目下匹配关键词
SpecialRelevance = weight / wordcount;
//计算命中关键词的平均权重
}
}
}
return SpecialRelevance;
//返回扩展相关度值
End
}
KBES算法是一个可复用模块,锚、链接等文本均可利用其进行扩展搜索。算法中的KBBCheck(keyword, class)方法包含两个步骤:与KB中的关键词实例匹配;命中的关键词与查询所属的类目匹配。
如果锚与链接文本中包含多个关键词实例,则其权重累计后除以命中关键词总数得到的平均权重作为该锚或链接文本的相关度值。其公式如下:
SpecialRelevance=
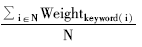 | (1) |
Weightkeyword(i)表示某命中关键词的权重,N表示锚或链接文本中的命中关键词总数。
4 实验与评价
4.1 实验环境
实验在笔者改进的一款开源爬行器上进行,其中直接相关的组件用到了改进的最好优先搜索算法模块、知识库模块、统计分析模块、网页解析模块、语种识别API、中文分词API以及英文POS和短语识别API等。
其中最好优先搜索算法模块、知识库模块和统计分析模块是由笔者独立开发,其他第三方API如表3所示:
| 表3 实验中的第三方API |
4.2 实验数据与评价
笔者采用KBES贡献率来衡量KBES算法对链接优先级所起作用的大小,并与无扩展搜索情况下的锚与链接预测贡献率进行比较。
(1)KBES贡献率(KBBExpandSearchRatio)
KBES贡献率用来评价锚和链接进行KB扩展搜索的效果,表示相对于无扩展情况下的锚和链接预测链接优先级的贡献率而言其贡献的大小。具体公式如下:
KBBExpandSearchRatio=
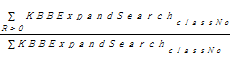 | (2) |
KBES贡献率是按类统计的,等于某类爬行任务中返回KB扩展搜索相关度大于0的次数与该类任务中全部KB扩展搜索次数的比。
实验中针对知识库的全部13个类中的部分类进行了此项实验和统计。其各自KBES贡献率与平均KBES贡献率统计结果如表4所示:
| 表4 部分类KBES贡献率与平均值 |
(2)锚与链接预测贡献率(AnchorUrlPrioRatio)
锚与链接预测贡献率用来评价锚与链接未进行KB扩展搜索时的链接优先级预测效果,计算公式如下:
AnchorUrlPrioRatio=
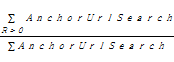 | (3) |
AnchorUrlPrioRatio也是按类来统计的,所采用的查询词和种子地址与统计KBBExpandSearchRatio一致。锚与链接预测贡献率等于锚和链接文本预测相关度大于0的次数与总次数的比。锚与链接预测贡献率统计结果如表5所示:
| 表5 锚与链接预测贡献率 |
实验发现:单纯依赖锚与链接文本进行链接相关性预测时,各类主题下的平均贡献率只有0.2093,而利用KBES算法改进后的平均贡献率提高到0.5785。贡献率的提高将使无扩展情况下的不相关链接识别为相关链接加入到优先级队列中的数量增加,从而有可能带动爬行器收割率的提高。
从实验结果可知,在锚与链接文本中的关键词较少的情况下,单纯依赖其进行陌生链接的相关性预测效果一般,大部分情况下无法与查询关键词直接匹配。通过对锚与链接文本中的关键词进行KB扩展,去发现与查询之间的其他共同特性,能较有效地穿越盲区(隧道)抓取更多相关网页。而对于评论类和教育类的AnchorUrlPrioRatio实验结果均高于KBBExpandSearchRatio是受查询词较短的影响,评论类抓取主题是有关Java的博客日志,锚点中出现Java的情况较多。而教育类抓取的网页锚点中包含查询词Syllabus、Lecture和Course的情况也较多。如果使用较复杂的查询词如2至3个词以上,则AnchorUrlPrioRatio的结果并不乐观。同时实验数据也表明不同类目的KBES贡献率是不同的,原因可能有4点:
(1)知识库中的各类目下的实例库建设的完善程度不同;
(2)各类目进行的爬行任务量不同,导致锚与链接的数量不同,因此扩展搜索的次数也不同;
(3)抓取的目标区域内与各类主题实际相关的网页分布有可能是不均匀的;
(4)受文本分词和短语识别算法的影响。
5 结 语
与利用词典或本体对查询关键词进行适当扩展后的主题搜索相比,本文利用自动构建的知识库对目标文本进行扩展查询穿过隧道的策略具有成本较低、领域局限性较小等特点。主题爬行器在预测链接优先级时所采用的启发策略中锚与链接文本仅是内容特征的一部分,链接的入度、出度等Web结构特征以及网页类型特征等都起到重要作用。爬行器将综合利用各种特征来预测链接的相关性。因此各种特征在解决“真、假”隧道问题上的有效性以及综合利用是笔者需要进一步研究的问题。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|