





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
混合多层分类和朴素贝叶斯模型的垂直搜索引擎分类器设计*
引用本文
张红斌, 曹义亲. 混合多层分类和朴素贝叶斯模型的垂直搜索引擎分类器设计* . 现代图书情报技术, 2011, 27(3): 73-79
Zhang Hongbin, Cao Yiqin. A New Classifier Design in a Topic Search Engine by Combining Multi-layer Classifier with Naive Bayes Classification Model. 现代图书情报技术, 2011, 27(3): 73-79
Permissions
Zhang Hongbin, Cao Yiqin. A New Classifier Design in a Topic Search Engine by Combining Multi-layer Classifier with Naive Bayes Classification Model. 现代图书情报技术, 2011, 27(3): 73-79
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
混合多层分类和朴素贝叶斯模型的垂直搜索引擎分类器设计*
摘要
研究Web上计算机教育资源的分布特点,融合主题词和文档形式,设计多层分类器来完成主题搜索过程中的正确分类,继而应用朴素贝叶斯模型对主题资源信息进行自动类别划分,完成资源的物理存储。实验中主题分类的平均正确率约78%,主题的平均召回率约61%,而资源解析的平均正确率约81.5%,测试结果能够验证本文设计思想的可行性。
关键词:
多层分类器; 垂直搜索引擎; 计算机教育资源; 朴素贝叶斯
中图分类号:TP393.08
A New Classifier Design in a Topic Search Engine by Combining Multi-layer Classifier with Naive Bayes Classification Model
Abstract
The paper firstly analyzes the distribution characteristics of computer education resources on Web, then it designs a multi-layer classifier to resolve the topic classification problem in topic crawling procedure by combining topic words and resources forms, and introduces how to make the precise classification fusion by Naive Bayes Classifier model and how the resources are stored correctly into the hard disk. Finally, experiment results show that the key design idea is feasible and many performances are acceptable, such as the avarage accuracy of the topic classification algorithm reaches to 78% as well as the avarage recall accuracy reaches to 61% and the avarage resources parsing accuracy reaches to 81.5%.
Keyword:
Multi-layer classifier; Topic search engine; Computer education resources; Naive Bayes
1 引 言
垂直搜索引擎采集专业领域中的网页、文档、资料,再以优良的人机交互界面呈现给用户,满足专业用户在专业领域中对信息搜索的要求。垂直搜索引擎的关键性能指标是搜索的精度和召回率[ 1, 2],要获取较好的搜索精度和召回率,就必须为搜索引擎设计良好的分类器模块,正确地完成主题的归类。本文介绍了一个基于计算机教育资源的垂直搜索引擎分类器的设计思想以及其应用。
2 研究背景
目前,百度网和豆丁网都推出了文库服务,文库服务就是面向Web用户提供文档或资源的下载服务。这些文库服务的运营模式是传统的“共享”方式,即由用户上传文档,并设置下载积分,管理员对上传的文档进行审核,所有通过审核的文档都可提供给其他用户下载。百度和豆丁提供的文档范围很广,但文档的专业深度十分有限,难以满足专业用户的特殊搜索需求,且用户下载文档时还受积分限制,很多文档无法免费获取。目前还没有真正意义上的面向专业资源的垂直搜索引擎系统。本文设计了基于计算机教育资源的垂直搜索引擎系统,使其面向所有Web用户提供开放式的文档搜索服务。
本垂直搜索引擎首先驱动主题爬虫在Web上搜索满足主题分类要求的各种资源[ 2, 3],如不同形式的网页、PPT、PDF、DOC、XSL、TXT等,然后进行预处理,去除不相关的噪声信息,将预处理之后的信息保存为固定形式。应用解析工具把上述类型的计算机教育资源中的文本信息先提取出来,并统一转换为TXT文本,再对其进行中文分词[ 4],计算主题相关度,并保存到计算机外部存储设备,同时创建针对这些信息的索引,为提供搜索服务做好准备。由于Web上的计算机教育资源类型极其丰富,所涉及的主题范围也极广,因此,如何在主题爬虫的搜索过程中对资源进行合理的分类,即设计主题搜索的分类方法是关键内容。本文以此为切入点,深入分析Web上计算机教育资源的分布特点,从而逐步推导出主题搜索的分类方法,最终实现垂直搜索引擎系统原型。
3 主题搜索的分类方法研究
3.1 计算机教育资源分布特点分析
深入分析当前Web上计算机教育资源的分布,发现如下重要特征:
(1)计算机教育资源包含了几个大粒度[ 5]的主题词。这些主题词分别是:软件工程、编程语言、操作系统、计算机网络、信息安全、数据库和人工智能。若文档中包含其中任一个大粒度主题词,则该文档属于计算机教育资源的概率非常高,故包含大粒度主题词的搜索扩展了垂直搜索的宽度。
(2)任一大粒度主题词又可包含若干小粒度[ 5]的主题词条,从而细化大粒度主题词的主题描述内容,如“编程语言”大粒度主题词下包括了如C++、Java、.NET等小粒度主题词,故包含小粒度主题词的搜索可拓宽垂直搜索的深度,提高搜索的精度。
(3) 计算机教育资源在Web上的文档形式包括:网页(如HTML、ASP、JSP、PHP等)、PPT、PDF、DOC和XSL等(参考百度文库和豆丁文库对文档形式的划分[ 6, 7]),故垂直搜索引擎系统的分类器必须能够正确识别和分类不同类型的文档,才能进一步丰富垂直搜索的结果。
(4)计算机教育资源的名称包含了描述资源的关键信息,如某资源“Java编程思想”包含了关键主题词“Java”。因此,对文档描述信息的解析和提取是进行资源聚合的重要方法。
3.2 主题搜索的分类方法的推导
经过上述分析发现:计算机教育资源在进行分类时既要考虑主题词对分类的影响,又要考虑资源文档形式对分类的影响,这样才可以从搜索的广度和搜索的深度等多个角度获取高质量的主题文档资源。
(1)基于主题词的分类方法
定义1:基于主题词的分类层。计算机教育资源包括8个大粒度主题词(在上述7个主题词基础之上增加一个“其他”类,以涵盖所有未被列入到7个主题词范围内的相关资源),所以任一计算机教育资源都可根据这8个大粒度主题词进行合理分类。此外,与每个大粒度主题词相关的小粒度主题词也必须保存起来,并建立与大粒度主题词之间的关联。故基于主题词的分类层由8个大粒度主题词、若干与之相关的小粒度主题词以及它们之间的关联所构成。
大粒度主题词与小粒度主题词间的关联利用文献[2]中的主题词库构建方法。针对所有大粒度主题词采用一张数据库表表示,而与大粒度主题词相关的所有小粒度主题词只用一张数据库表表示。若增加新的大粒度主题词,则只要新建包含与之相关的小粒度主题词数据库表即可,并在大粒度主题词表中增加该大粒度主题词。
(2)基于文档形式的分类方法
定义2:基于文档形式的分类层。计算机教育资源的文档形式可分为6大类:网页、DOC、PDF、XSL、PPT以及其他类型。此分类方法可以丰富搜索结果的文档形式,且对资源管理也非常有利,在索引模块中只要针对不同格式的文件创建索引文件即可,索引之间的耦合低,易于维护。例如,用户搜索PPT格式的资源,搜索引擎系统只需检索PPT文档的索引文件就可获取搜索结果。若用户同时需要多种不同格式的资源文件,则系统会并行搜索多个不同文档形式所对应的索引文件,获取综合的搜索结果。
(3)融合主题词和文档形式的多层分类方法
定义1和定义2分别从不同角度对资源文件进行分类,若孤立定义2方法而仅采纳定义1方法进行分类,则搜索出的资源信息会集中表现为少数几种固定文件格式,显然这不能满足专业用户的搜索需求。相反,如孤立定义1方法而仅用定义2方法进行分类,则搜索系统的召回率会非常差,即得到大量与计算机教育资源主题不相关的文档,这显然违背了本垂直搜索系统设计的初衷。可见,仅用某一种分类方法在理论上都不能获得较好的搜索精度、召回率,且结果单一,必须融合两种分类方法进行综合的多层分类,因此得到如下定义。
定义3:融合主题词和文档形式的多层分类模型。该模型在获取Web资源时既考虑其是否与主题词相关,又对资源的文件格式进行分类。该定义是定义1和定义2融合的结果。例如,第一层分类采用基于主题词的分类,先筛选出主题相关的资源信息。第二层分类采用基于文档形式的分类,将满足主题要求的文档正确归类到对应的资源文件夹中。此方法既可快速决策资源的主题相关性,又非常适合对召回率有较高要求的搜索系统。但若主题词变化很大,而资源文件格式相对变化较小,则可将这两种分类层次对调,以获取较好的搜索精度。
3.3 主题搜索的分类方法的形式化描述
在上述分析的基础之上,笔者提出采用形式化方法来描述本文的主题搜索分类方法。首先,计算机教育资源基于主题词可分为8类(依据大粒度主题词划分),它是一个集合RT,其中每一类资源均用Mi表示:
RT=Mi,i=0,1,2,…,7 (1)
计算机教育资源的文档形式共6类,它也是一个集合RF,其中每一种资源的文档形式均用Nj表示:
RF=Nj,j=0,1,2,…,5 (2)
用式(3)描述融合了两层分类方法的分类决策函数。
P′q=OF{FTLF(Pij),FFLT(Pji)|i∈RT,j∈RF},q=0,1,2,…,N (3)
等式左边P′q是经过文本解析、净化然后输入到分类器中完成多层分类的资源的TXT文本,OF(Objective Function)是目标函数,设计人员可根据垂直搜索关键性能指标的优先顺序,首选某种指标的最优化作为设计和度量系统优劣的目标,如搜索精度最优或召回率最优。先主题后文档形式(First Topic Last Form,FTLF),即分类时先进行基于主题词的划分,再进行基于文档形式的划分。先文档形式后主题(First Form Last Topic,FFLT)则刚好相反。所以,在目标函数最优的指引下,分析人员可灵活定制系统的多层分类模型。本系统考虑主题的查准率[ 9]作为OF函数,故采用FTLE建立多层分类模型。
4 朴素贝叶斯分类模型
上述分类方法指导主题爬虫正确定位计算机教育资源,并完成了资源在外部存储设备中的存储分类架构,但是垂直搜索引擎系统要实现资源的自动分类,还需在主题相关度的计算基础之上融入成熟的自动分类算法,即在主题爬虫中嵌入分类算法,将预处理好的纯文本文档,依据文档内容自动划分到某文档形式的代表某个大粒度主题词的存储目录中,以便统一针对该文档形式建立索引。本文采用朴素贝叶斯分类模型来实现基于文本的自动分类。贝叶斯分类算法是基于贝叶斯全概率的分类算法,其原理是计算待分类文本属于某个类别的概率,将待分类文本划分到概率最大的类别中[ 8]。朴素贝叶斯方法基于朴素假设,即给定类节点后,各属性节点之间被认为相互独立,朴素贝叶斯分类模型如图1所示[ 8]:
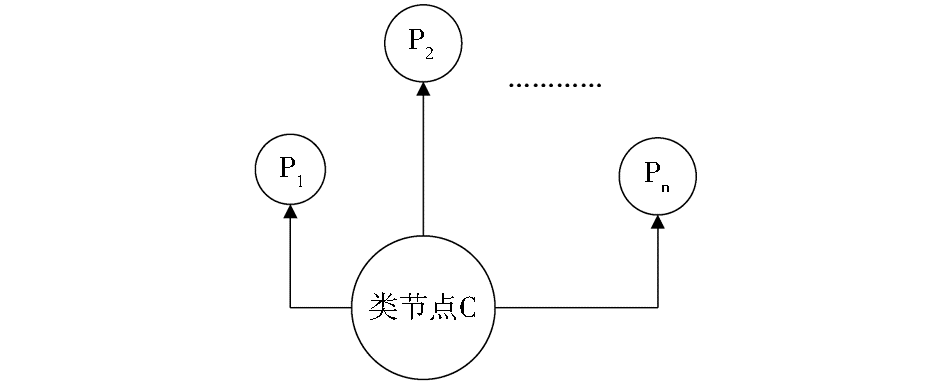 | 图1 朴素贝叶斯分类模型[ 8] |
其中,Pn表示属性节点,C表示类节点,数据样本由n维特征向量表示,分别描述n个属性P1,P2,…,Pn的度量,假定有m个预定义的类别,类别集合是{C1,C2,…,Cm},现给定未知数据样本x,分类器将具有最大后验概率计算结果的类别赋予数据样本x,最大后验概率公式[ 8] 如下:
P(Ci|x)=max{P(C1|x),P(C2|x),…,P(Cj|x)},i∈m,j∈m (4)
将未知数据样本x分配给类别Ci,称Ci为最大后验假设,由贝叶斯定理可得到P(Ci|x)P(x)=P(Ci)P(x|Ci)。样本数据x有n个属性,根据朴素假设得到经过简化后的朴素贝叶斯公式[ 8] 如下:
P(x|Ci)=P(x1x2x3...xn|Ci)= 
朴素假设简化了联合概率P(x1,x2,…xn|Ci)的计算,节省了系统开销,具有高效、错误率低等特点[ 8],这也是本系统采用它进行基于文本的自动分类的重要原因。
贝叶斯分类在实现过程中需要建立训练样本,以提高分类的准确率。本系统建立训练样本的基本思想是:首先通过人工收集的方式采集各种主题的文本信息,形成文本集,如通过百度百科、互动百科、维基等收集计算机教育资源的不同文档类别的文本集,并将这些文本集分成基于8个大粒度主题词的子类别;再收集一个与所有主题均不相关的主题类别,来区分计算机教育资源和其他不相关资源,每个子类别文件夹下包括30个训练集合;使用这些基本的文本集进行分类器训练,再通过计算机自动获取训练文本,添加到相应类别下以不断增加训练集中的样本,提高分类的精度。
5 垂直搜索引擎系统工作流程
垂直搜索引擎系统的工作流程图,如图2所示:
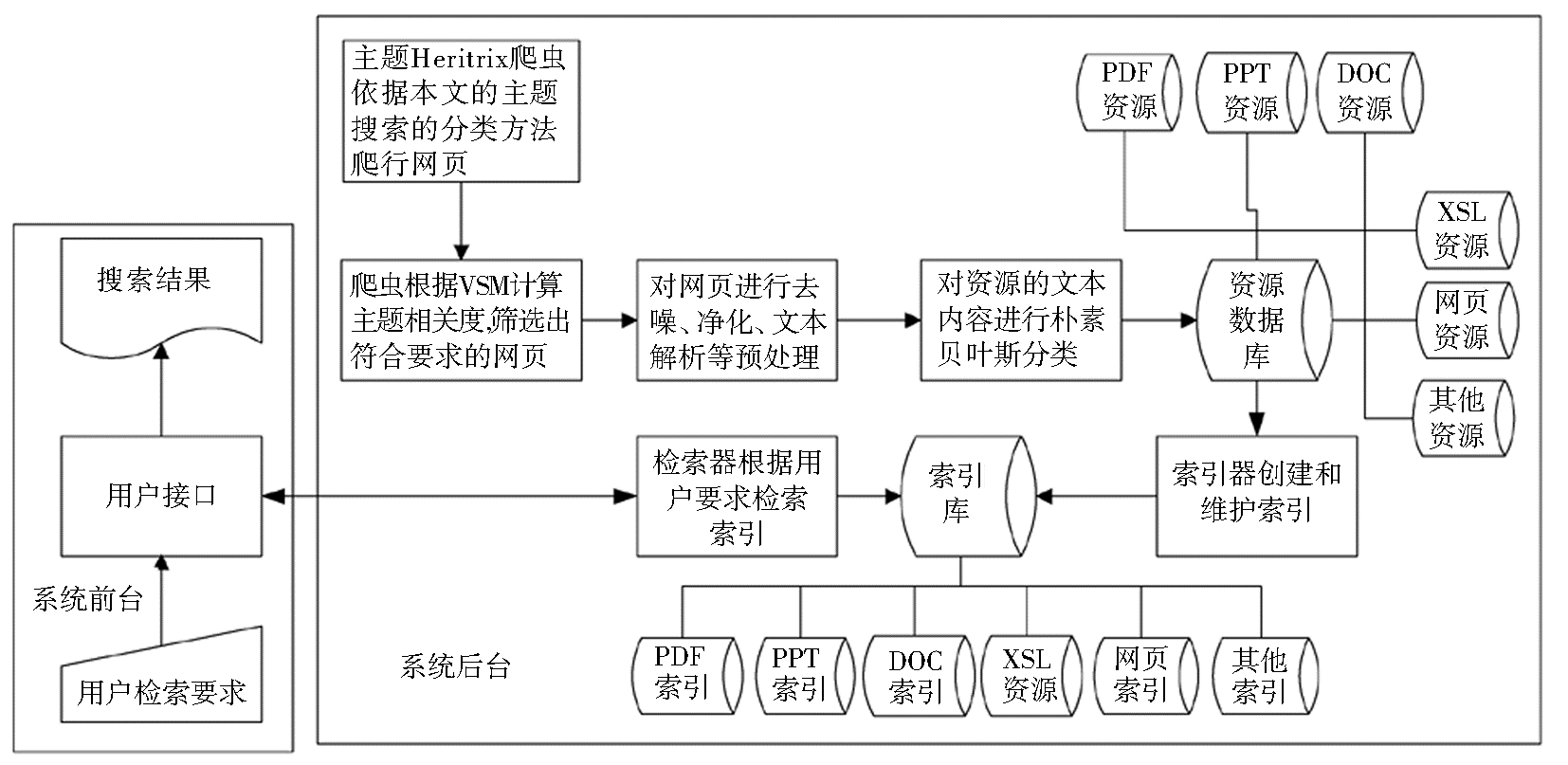 | 图2 垂直搜索引擎系统工作流程图 |
垂直搜索引擎系统采用集中式方式部署到计算机上,并借鉴流水线作业模式进行并行调度。其中主题爬虫基于Heritrix爬虫[ 10]进行功能扩展。Heritrix是一个完全开源的Java爬虫系统,可完成基于多个URL种子的全文搜索,但并不是一个主题爬虫,要实现本文提出的主题爬行,需对其内部功能进行扩展。此外,还需对TXT文件创建索引,并提供检索交互界面。系统的具体设计如下:
(1)扩展Heritrix的Extractor[ 10]处理器,聚焦Heritrix爬行6大计算机教育资源类别的URL。笔者对资源描述信息的主题相关度进行分析,决定当前URL是否为计算机教育资源,计算其相关权值,并运用多线程技术来同时处理多组相关URL的分析。
(2)扩展Heritrix的FrontierScheduler[ 10]处理器,进一步判断URL是否主题聚焦,保证重要的、主题相关的URL首先被调度。每次读取多个URL进行待爬行分析,并对该组URL进行相关度权值的非递增堆排序,优先爬行权值高的URL。
(3)设计TopicRelevanceCalculator组件,在Heritrix中嵌入VSM(Vector Space Model)[ 5]算法来计算网页内容的主题相关度,筛选出满足要求的主题网页。
(4)设计Preprocessor组件,对网页进行预处理,包括基于正则表达式的网页编码问题处理、网页内容的全角转半角、基于VSM计算阈值的网页消重,通过解析工具进行资源的文本解析,最终所有资源均以TXT的形式保存到计算机外部存储设备。
(5)创建并维护索引。基于Lucene技术[ 11]完成索引的创建和更新,从图2可以看出需针对6大资源文档形式分别建立不同的索引文件。
(6) 设计垂直搜索的人机交互界面。参考百度文库的搜索界面[ 6],运用JSP+Servlet+HTML设计了一个简单、大方的搜索人机交互界面。
6 实验及结果分析
6.1 实验环境设置
(1)系统硬件环境:CPU是Intel P4 3.0GHz,内存是金邦1GB DDR2 533,硬盘是希捷SATA 160GB,外部网络是铁通1Mbit/s带宽;
(2)基础软件环境:操作系统是Windows XP SP2,Web服务器选择Tomcat 6.0,页面设计工具选择Dreamweaver 8.0;
(3)系统开发工具:开发平台选择JDK 1.6,爬虫选择Heritrix 1.14.3,文本解析选择POI 3.5[ 12]和PDFBox 0.7.3[ 13],中文分词工具选择庖丁解牛(Paoding) 2.0[ 14],索引创建及更新工具选择Lucene 2.4[ 11]。
6.2 实验步骤
(1)启动Heritrix程序。通过命令行方式运行命令“Heritrix --admin=admin:admin” 命令,启动Heritrix。
(2)设置爬行参数。包括设置合理的虚拟内存空间大小、初始爬行网页的URL地址,并启动Heritrix的各处理器,包括扩展后的Extractor、FrontierScheduler以及默认的Prefetcher、Fetcher、PostProcessor等,完成Heritrix爬行的软件环境设置。
(3)启动Heritrix开始网页爬行。当爬行时间到达或收集了指定数量的网页之后即可人工中断爬行任务。
(4)创建索引文件。索引创建程序是独立于Heritrix的Java桌面程序。采用多线程模式分别为不同文档类型的TXT文件创建索引文件。由于索引了大量文件,故需调节索引创建时的合并因子、最小最大合并文档数等参数提高索引速度。
(5)部署搜索引擎主页程序。将搜索程序压缩包SearchEngine.war放入Tomcat的Webapps目录中,重新启动Tomcat即可在本地测试搜索引擎系统原型。
(6)提交搜索关键词,获取搜索结果,并进行搜索关键性能指标测试。提交检索包含“Java”关键词的PDF文档,系统搜索结果如图3所示:
 | 图3 系统搜索结果 |
6.3 关键性能指标测试
基于计算机教育资源的垂直搜索引擎的核心设计思想是:融合多层分类和朴素贝叶斯分类完成主题信息的分类。多层分类模型采用二级分类方式来指导主题爬虫的主题搜索以及资源管理,而朴素贝叶斯分类则自动地将已经提取出的资源文本信息正确地划分到对应的二级分类架构中。因此,需对该模型进行分类正确率(查准率[ 9])测试,验证本文提出的核心思想的可行性。
分类正确率=基于某个主题词的正确分类的资源数/总的资源数 (6)
为每个大粒度主题词分别采集1 000个网页(Heritrix自动采集,然后进行人工抽样筛选),然后将它们传入分类器进行分类测试,结果如图4所示:
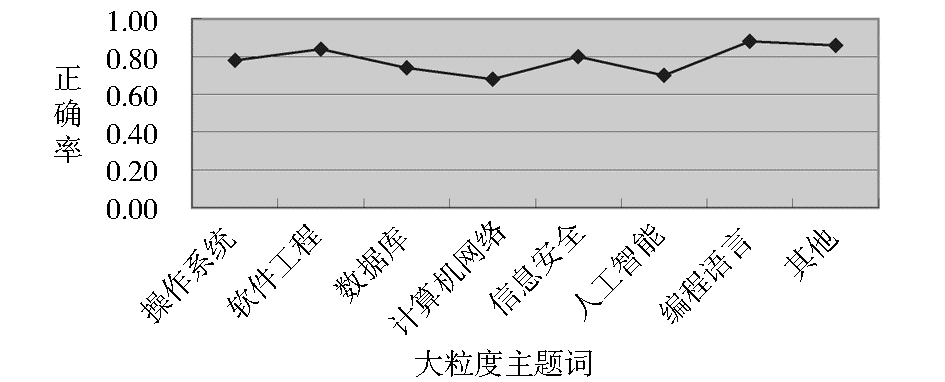 | 图4 分类器正确率测试结果 |
图4中,所有资源分类的正确率均已超过60%,验证了分类设计思想的可行性。分类器的平均正确率达到78%,算法精度较好,可在一定程度上满足专业用户对主题搜索的要求。但是,分类器针对不同主题词的分类正确率还有很大差距,如“编程语言”主题词的分类正确率接近88%,而“计算机网络”主题词的分类正确率只有68%,两者相差20%,分析其原因,这与样本集的大小、样本集的内容、中文分词以及主题相关度计算方法等均有一定关系。
垂直搜索引擎系统的另一个关键性能指标是召回率。召回率也称查全率,是衡量检索结果是否全面的度量标准[ 9]。召回率的高低决定了垂直搜索引擎系统是否已具备应用价值。
召回率=搜索到的满足主题要求的资源/搜索到的所有资源 (7)
人工输入每个关键词,统计搜索结果列表中前100个网页,判别每个网页是否主题相关,计算软件召回率,如图5所示:
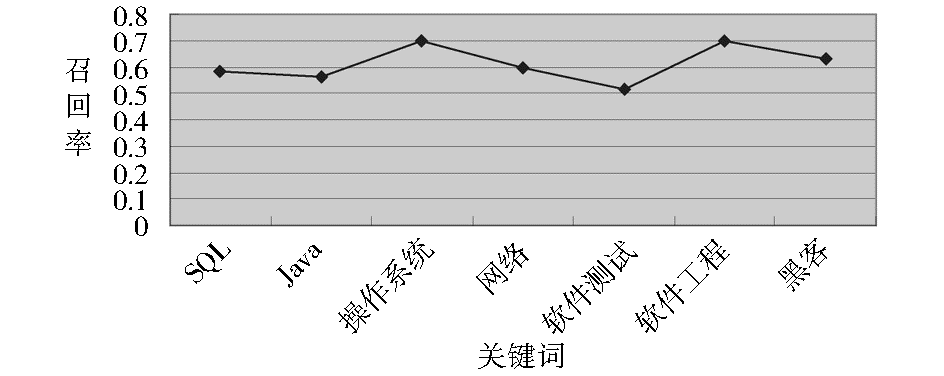 | 图5 软件召回率测试结果 |
图5中,召回率平均值约为61%,能基本满足用户的垂直搜索要求,但有待进一步提高。例如,关键词“软件测试”的召回率偏低,分析其原因,主要是因为软件测试是由软件工程专业细分出来的专业方向,其主题词较新颖,而本垂直搜索引擎系统的中文分词模块未能较好地切分该词,从而降低了系统对于某些关键词的召回率。
由于在多层分类中提出了根据文档形式进行分类,故还对PDF、DOC、PPT、XSL等几类资源文件的解析正确率进行单独测试。每类资源均输入100个文档样本,然后对它们进行解析,人工判断解析之后的TXT文档与解析前文档中的文本内容是否一致。其中,对于Office文档,采用Apache 的工具包POI进行解析,从Office文档中提取出文本信息;选择PDFBox对PDF文档进行解析。得到资源解析的正确率,如图6所示:
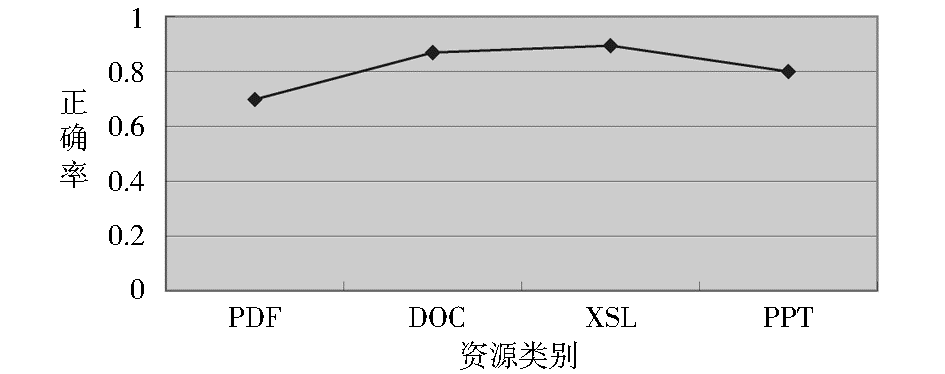 | 图6 资源解析正确率测试结果 |
图6中,DOC、XSL和PPT文档的解析正确率较高,因为这三类文档中的文本信息较多,POI工具可以很好地提取出文本信息。而PDF文档中部分文件的内容是由扫描数字图像所制成且被加密,故解析出的文本的正确率相对较低。总之,平均解析正确率较好,达到81.5%,能够满足后续的基于TXT的朴素贝叶斯自动分类要求。
7 结 语
垂直搜索引擎是未来搜索引擎发展的主流方向。如何更好地细化Web资源的主题词描述,且丰富搜索资源的文档形式,从而向用户提供更优的垂直搜索服务将成为其能否主导搜索引擎领域的关键。本文着重分析并研究了主题搜索的分类方法——融合多层分类和朴素贝叶斯分类的分类方法,实现了一个垂直搜索引擎系统原型。实验表明了设计思想的可行性和正确性。在后续的研究工作中,笔者将会在拓展更多的资源形式、引入其他主题相关度算法、用户定制资源主题搜索、改进PDF文件解析正确率及提高系统召回率等方面继续展开研究,期望能够解决当前系统中存在的某些问题,为相关的研究工作提供较高的参考价值。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|