{kind=link}
{kind=link}
{kind=link}
DBpedia及其典型应用*
引用本文
朝乐门, 张勇, 邢春晓. DBpedia及其典型应用* . 现代图书情报技术, 2011, 27(3): 80-87
Chao Lemen, Zhang Yong, Xing Chunxiao. DBpedia and Its Typical Applications. 现代图书情报技术, 2011, 27(3): 80-87
Permissions
Chao Lemen, Zhang Yong, Xing Chunxiao. DBpedia and Its Typical Applications. 现代图书情报技术, 2011, 27(3): 80-87
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
DBpedia及其典型应用*
摘要
基于文献研究和案例分析,提炼出DBpedia的6个特征,即大规模人机协同、语义Web知识组织、跨领域知识库、多语言知识库、实时动态知识库和关联数据中枢。在此基础上,探讨DBpedia的4种典型应用(用户界面、语义标注、数据挖掘、跨域共享与服务)与6个基本特征之间的内在联系。
关键词:
DBpedia; 典型应用; 关联数据; 语义Web
中图分类号:TP182
DBpedia and Its Typical Applications
Abstract
Six basic characteristics, namely man-machine mass collaboration, Semantic Web-based knowledge organization, cross domain knowledge base, multi-language dataset, dynamic database are proposed by literary researches and case studies. Then, the relations between these six characteristics and four typical applications of DBpedia, which are UI, semantic tagging, data mining, cross-domain sharing and servicing applications, are further discussed.
Keyword:
DBpedia; Typical applications Linked data; Semantic Web
1 引 言
从文档网到数据网的过渡是当今Web技术的重要发展趋势之一[ 1]。数据网的出现亟须数据发布、互联、共享和服务方法与技术的创新。在这种需求驱动下,涌现出了许多新的理念、方法和技术,比较典型的是关联数据(Linked Data)、语义Web(Semantic Web)、微格(Microformats)、Web 服务(Web Services)、数据空间(Dataspace)等,其中关联数据和语义Web逐渐演化成数据网的主流方法与技术。
DBpedia[ 2]是基于Wikipedia、语义Web和关联数据技术的创新型知识库,是文档网向数据网过渡的标志性成果之一。本文主要介绍了常用关联数据集以及DBpedia区别于其他关联数据集的特殊性,探讨了DBpedia典型应用的类型、含义、所依赖的特征以及代表性应用,并进一步探讨了DBpedia对数据联网建设的启示。
2 DBpedia的特征
近年来,关联数据运动推动了一些新型关联数据集的建设活动,如DBpedia、Freebase、WordNet、DBLP Bibliography、Revyu、Flickr、MusicBranz、GeoNames、DrugBank、 YAGO等, 如表1所示。 相对于其他关联数据集, DBpedia具有6个基本特征。
| 表1 关联数据集 |
2.1 知识库建设与维护特征——大规模人机协同知识处理
人机协同知识处理是指在知识管理,尤其在基于语义Web的知识处理过程中,强调人与计算机的分工与合作,通过人对知识处理前端控制,降低计算机知识处理的难度,在人与计算机之间寻找最佳的协同状态,推动知识的创造、表示、存储、检索、推理、验证、抽取、再现、集成能力上超过人与计算机的“超知识处理系统”的出现。在这种超知识处理系统中,人与计算机共同感知、共同决策、相互学习、相互监督,共同完成知识管理任务[ 12]。人机协同知识处理模式可分为小规模人际协同、小规模机器协同和小规模人机协同,大规模人际协同、大规模机器协同和大规模人机协同模式。大规模知识处理模式与小规模知识处理模式的区别在于协同范围是否在开放环境中进行,是否延伸至知识链的长尾。如果协同知识处理范围仅限于封闭式环境中,或仅限于知识链的头部,那么将其称之为“小规模协同处理”,反之称为“大规模协同知识处理”。二者的主要区别在于“大规模协同知识处理”容易出现“知识涌现”现象,具有开放性、自组织性、不确定性、演化性、涌现性的特征,可以更好地支持知识生态系统[ 13]。DBpedia在知识库建设和维护方面最显著的特征是采用了大规模人机协同知识处理模式。
Web2.0提供了一种不同于目前知识管理中的80/20法则的新方法论,即大规模协同知识管理方法论。DBpedia数据源自Web2.0的典型应用——Wikipedia,即来自知识链长尾的众多草根用户,而不是头部的少数专家用户,充分体现了大规模协同知识处理。Wikipedia的知识处理符合基于Web2.0的大规模知识处理的4个基本原则[ 14]:
(1)Wikipedia知识处理范围不仅限于特定组织内部知识型员工,而是延伸至知识链的“长尾”,鼓励“长尾”用户参与,通过众多草根用户的贡献完成海量数据集的建设与维护工作,而不是由特定专家负责完成;
(2)Wikipedia的核心竞争力来自于其不断积累的数据库,尤其是用户提供的内容和进行评注过的数据,而不是Wikipedia软件本身;
(3)Wikipedia的知识处理采用人机协同的知识处理模式,实现人与计算机的优势互补;
(4)Wikipedia数据内容的创建和维护工作以人工操作为主,而其传递、存储和推理依靠计算机系统完成。
DBpedia继承了Wikipedia的开放式大规模协同处理特征,通过发挥长尾用户的贡献,解决了目前知识库建设中存在的数据规模与其结构化程度之间的矛盾,以较低成本建设和维护结构化程度较高的大规模海量知识库。
在DBpedia知识库建设与维护中,数据的一致性验证、内容抽取、快速查询、统计处理、精确计算等重复性处理工作使用计算机自动处理技术,而知识创新、知识发现、本体建设等创新性工作则由人工处理,较好地发挥了计算机与人在知识处理中各自的优势,体现了人机协同知识处理的思想。DBpedia数据来源于Wikipedia,主要因为人在知识创造中具有不可替代的地位,为了提高DBpedia数据集的语义处理能力,以人工方式建立了DBpedia本体,避免计算机自动创建本体的局限性,支持用户对DBpedia数据进行反馈和修改操作,增强计算机的语义处理能力;DBpedia通过知识抽取框架(DBpedia Knowledge Extraction Framework)自动抽取Wikipedia的标签、摘要、语言链接、图片等数据项,并进行一定的语义处理,以多元组的形式存放到DBpedia知识库中,发挥了计算机对结构化程度较高的数据的重复操作能力。DBpedia支持定时抽取和实时抽取两种抽取模式,前者以一个月为周期,而后者可以动态监测Wikipedia中的数据变化,进而保证DBpedia与Wikipedia的同步性。从目前运行现状看,DBpedia的定时抽取模式的可用性高于实时抽取模式,实时抽取技术需要进一步完善。
在DBpedia知识库中,通过采用大规模协同知识处理模式,较好地解决了目前知识库建设中普遍存在的规模小和数据内容静态性的问题。但是,就目前而言,DBpedia数据中仍然存在结构化程度低、数据不一致以及数据质量低等问题。要克服此类问题,需要进一步研究大规模协同知识处理问题,从Wikipedia和DBpedia两个层面进行技术创新,更好地发挥人与计算机的互补性优势,实现大规模协同知识生态系统,保证DBpedia数据的持续改进。
2.2 知识表示与组织特征——基于语义Web的知识组织
从知识表示与组织的角度看,DBpedia主要采用基于语义Web的知识组织模式,体现在两个方面:
(1)DBpedia采用RDF语法表示和组织知识,并支持基于SPARQL语法的知识查询。目前,DBpedia知识库已包含超过10.3亿的RDF三元组[ 15]。DBpedia中采用不同的属性表示资源的不同信息,表2列出了一些常用的属性URI及其所代表的含义。
| 表2 DBpedia常用属性 |
(2)为了对数据集进行语义分类,提高分类效果,采用OWL语言创建了DBpedia本体,更好地支持基于语义Web的知识组织活动。在Wikipedia中,元数据以信息框(InfoBox)的形式记录和保存,不同的信息框应用频度可能不同。Wikipedia从这些InfoBox中找出一些最常用的数据项,分析相互关系,用手工方式创建DBpedia数据集的本体库。目前,该本体库包括170个类和720个属性。在DBpedia本体中采用元素
2.3 知识内容的涉及范围特征——跨领域
知识库的建设与维护主要依靠处于知识链头部的领域专家。因为这种方式成本过高,所以多数知识库往往仅限于单个特定领域,主要由某个特定领域的专家学者负责建设与维护。单领域知识库建设模式使不同领域知识库的映射和整合成为知识库建设与维护的难点。DBpedia突破了目前的面向单领域的知识库建设模式,将知识库建设者和维护者的范围延长至知识链的长尾部分,利用来自不同领域的众多草根用户的力量,达到了以较低成本建设与维护跨领域大规模知识库的目的。知识分类技术和Web2.0技术是实现DBpedia跨领域的两个关键技术。
DBpedia支持4种知识分类方法[ 16]:Wikipedia分类方法,可支持多达41.5万个类;YAGO分类方法,可支持多达28.6万个类;UMBEL(Upper Mapping and Binding Exchange Layer)分类方法,可支持多达2万个类型;DBpedia本体,支持170个大类和720个属性。具体情况如表3所示:
| 表3 DBpedia的不同分类方案 |
DBpedia支持Web2.0草根知识库建设与维护模式。由于DBpedia数据是从Wikipedia百科全书自动抽取的,DBpedia知识库的建设者来自不同领域的群众,而不是少数领域专家。因此,DBpedia的数据能更好地反映群众的共识,以较低成本建设了较大规模的知识库。从DBpedia的运行情况看,基于群众知识库的优点是成本低、规模大、可以跨领域,缺点是数据的权威性和规范性不够高。
目前,DBpedia知识库含有340万个以上的事物,其中包括31.2万人、 41.3万个地点、9.4万个音乐专辑、4.9万部电影、1.5万个视频游戏、1.4万个组织和 14.6万个物种以及4 600个不同的疾病信息,成为目前最大的跨领域语义数据库之一[ 17]。
2.4 知识内容的语言特征——多语言
Wikipedia有多个语言版本。基于Wikipedia的DBpedia的数据集也具备多语言知识库特性。DBpedia的跨语言性主要体现在其资源标签和摘要两个方面,目前可支持多达92种语言的标记和摘要。表4列出了Wikipedia所支持的主要语言及其摘要个数[ 16]。
| 表4 DBpedia的跨语言摘要[ 16] |
DBpedia采用属性@lang标识知识的语言类型。因此,在跨语言知识库的查询中,通过SPARQL查询语言的Filter语句即可限定检索数据的语言范围。例如,查询标签为英文的资源,其检索语句如下:
PREFIX p:
SELECT ?reference ?x ?t ?l
WHERE
{
?x rdf:type ?t.
?x rdfs:comment ?abstract.
?x p:reference ?reference.
?x rdfs:label ?l.
FILTER (lang(?l) = "en").
}
2.5 知识库内容的更新特征——实时动态
“创建容易,维护和更新难”是多数知识库的共性问题,进而导致知识内容的静止或过时,降低了知识库的应用价值。DBpedia通过继承Wikipedia的动态性较好地解决了这个问题。DBpedia知识库的动态性体现在两个不同层次:
(1)DBpedia数据内容本身的动态性。DBpedia可以通过自己的实时抽取框架(Live Extraction Framework)从Wikipedia中动态抽取数据,实现与Wikipedia动态数据的同步更新。
(2)在DBpedia应用系统中嵌入的DBpedia数据也具备实时动态特征。应用系统可以通过开放数据互联(Linked Open Data,LOD)技术将DBpedia数据嵌入用户界面。当DBpedia的数据发生变化时,应用系统中被嵌入的DBpedia数据也随之发生变化,实现应用系统用户界面中显示的数据与DBpedia数据的实时同步。
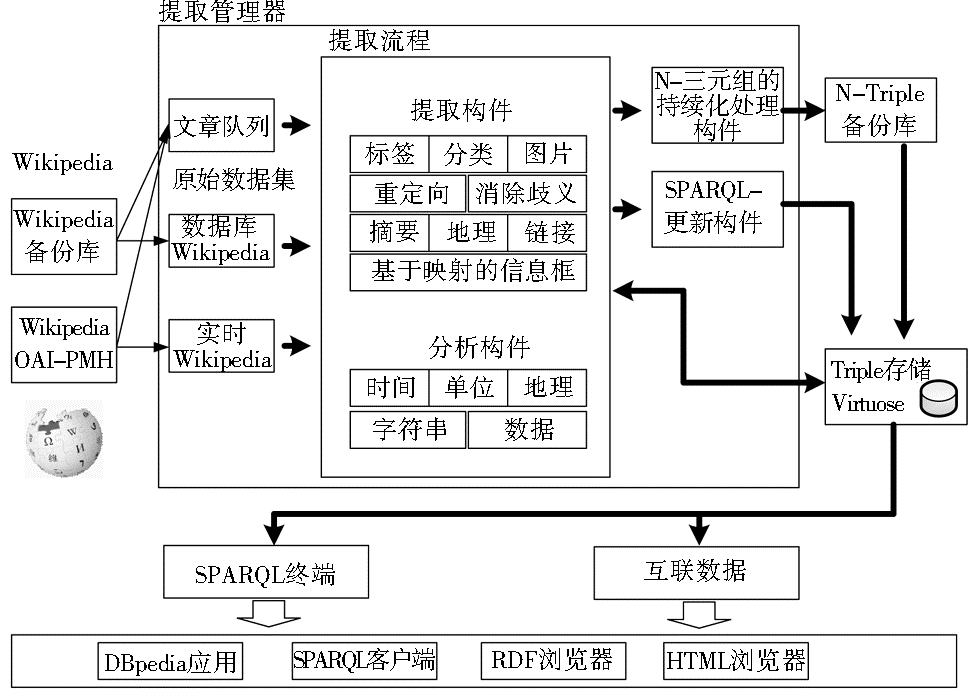 | 图1 DBpedia的实时抽取框架[ 18] |
可以看出,DBpedia实时抽取框架主要由原始数据集、目标数据集、提取构件、分析构件、提取管理器、更新构件等组成,其中SPARQL更新构件负责完成向DBpedia插入或替换新提交的三元组工作。根据文献[18]的研究,在Wikipedia中,数据更新的平均速度为1.4篇文章/秒。因此,DBpedia实时抽取框架至少以0.71秒/篇的速度进行抽取。但是,现有DBpedia实时抽取框架设计很难实现这样的实时处理要求,相关研究者正在从事技术创新工作。
2.6 DBpedia的作用特征——关联数据中枢
DBpedia从Wikipedia抽取和转换数据后,遵循关联数据建设的4项基本原则[ 19],对资源进行了语义描述,并在关联数据网空间中进行发布、互联和共享,方便其他用户的访问和使用。具体表现在如下几个方面:
(1)所有资源配有具有唯一标识作用的URI标识符,并且可以通过URI访问更多的详细信息。Wikipedia URI可以分为两部分,前半部分是资源路径,一般为http://en.Wikipedia.org/wiki;后半部分为资源的名称,一般为一个字符串。以资源“北京大学(Peking University)”为例,其Wikipedia URI为“http://en.Wikipedia.org/wiki/Peking_University”,其中“http://en.Wikipedia.org/wiki/”为资源路径,“Peking_University”为北京大学在Wikipedia中的名称。DBpedia URI对Wikipedia URI的继承主要体现在两个方面:
①从组成部分看,DBpedia URI由两部分组成,前者为DBpedia资源路径,一般为http://DBpedia.org/resource/,后者是该资源在DBpedia中的名称。
②DBpedia中的资源名称直接采用了该资源在Wikipedia中的名称。例如,资源“北京大学(Peking University)”的DBpedia URI为http://DBpedia.org/resource/Peking_University,其中后半部分,即“Peking_University”与该资源在Wikipedia中的名称相同。
DBpedia继承Wikipedia URI机制的优点在于可以覆盖百科全书的更多主题、充分反映用户共识、有助于规范管理以及易于灵活扩展[ 20]。
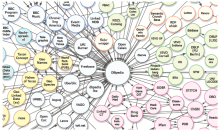
(2)通过DBpedia可连接到其他开放关联数据集。近年来,LOD项目在海量数据和语义本体的连接方面进行了大量的探索性工作。根据Cyganiak等发布的LOD云(见图2)[ 21],DBpedia中含有超过49万个指向外部数据的RDF链接,可以直接或间接连接包括Freebase、Flickr、WordNet、GeoNames、MusicBrainz在内的202个不同的数据集,表5中列出了DBpedia与几个重要的数据集之间的RDF链接情况[ 20]。
 | 图2 DBpedia成为关联数据中枢[ 21] |
| 表5 DBpedia中的RDF链接[ 20] |
3 DBpedia的典型应用案例
从上述特征分析看出,DBpedia具有大规模人机协同知识处理、基于语义Web的知识组织、跨领域、多语言、动态更新和关联数据中枢的特征。在实际应用中,可以利用DBpedia的这些特征开发出不同特色的应用系统。近年来,基于DBpedia的应用系统越来越多,大致可以归为4类,即用户界面(User Interface,UI)应用、语义标注、数据挖掘和跨域共享与服务,如表6所示:
| 表6 DBpedia的典型应用 |
3.1 UI应用
此类应用主要利用了DBpedia的跨领域、多语言和实时动态知识库特征。其技术实现主要分为三个阶段:通过SPARQL语法对DBpedia进行语义检索;对检索返回结果集进行过滤或重组后显示给用户;当DBpedia中的数据发生变化时,同步更新UI应用中的对应数据。
基于DBpedia的UI应用主要有3种:
(1)SPARQL转换器。DBpedia Query Builder[ 23]是一种访问DBpedia数据集的简单UI应用之一。该系统的主要功能是将用户在图形界面中输入的查询请求转换为SPARQL语句,并在DBpedia数据集上进行查询,降低了用户直接写SPARQL语句的复杂性。DBpedia访问客户端系统应用的特征有3个:数据来源比较单一,主要依赖DBpedia数据集;数据处理比较简单,主要实现SPARQL语言的语法功能;查询转换,即用户查询转换为SPARQL语句。
(2)专用于浏览和检索DBpedia的客户端系统。DBpedia Navigator[ 24]是典型的专门用于浏览和检索DBpedia的客户端系统,该系统采用机器学习算法和导航提示法,提高了用户浏览和检索DBpedia数据集的效率。
(3)在用户的UI中嵌入DBpedia数据。用户在自己的应用中可通过Ajax技术和SPARQL语句嵌入DBpedia数据。此类应用的主要特征是:数据来源较多,应用系统的数据并不仅限于DBpedia数据集;嵌入数据的动态性,应用系统中被嵌入的数据可以与DBpedia数据集同步变化;数据集成处理,对不同数据源进行了简单的集成处理。
3.2 语义标注
此类应用主要利用DBpedia的语义Web知识组织、跨领域知识库、实时动态知识库和关联数据中枢的特征。在应用系统的开发过程中可以DBpedia数据为语义标注数据来源对其他数据资源进行语义标注,从而提高数据的语义处理能力和开放互连能力。从实现角度看,基于DBpedia的语义标注主要分为4个阶段:
(1)对DBpedia数据集进行语义检索,并对检索结果进行抽取、转换和加载(Extraction Transformation Loading,ETL)操作;
(2)利用抽取结果对特定数据进行语义标注;
(3)用户可以通过语义标注信息查看DBpedia或其他关联数据集中的更多数据;
(4)当DBpedia数据发生变化时,同步更新语义标注中的相应数据。
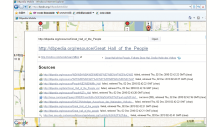
DBpedia Mobile是典型的基于DBpedia的语义标注系统,其最基本的语义标注信息主要来自DBpedia知识库。为了提高DBpedia Mobile的可用性,该系统不仅支持普通浏览器、手机等不同的终端,而且还支持用户发布与特定地理位置相关的语义标注信息。以检索“人民大会堂”为例,用户可以在DBpedia Mobile地图中检索到人民大会堂的具体位置,而且选中地名即可进一步查看该地名在DBpedia中的详细信息以及与其他数据源的RDF链接信息,如图3所示:
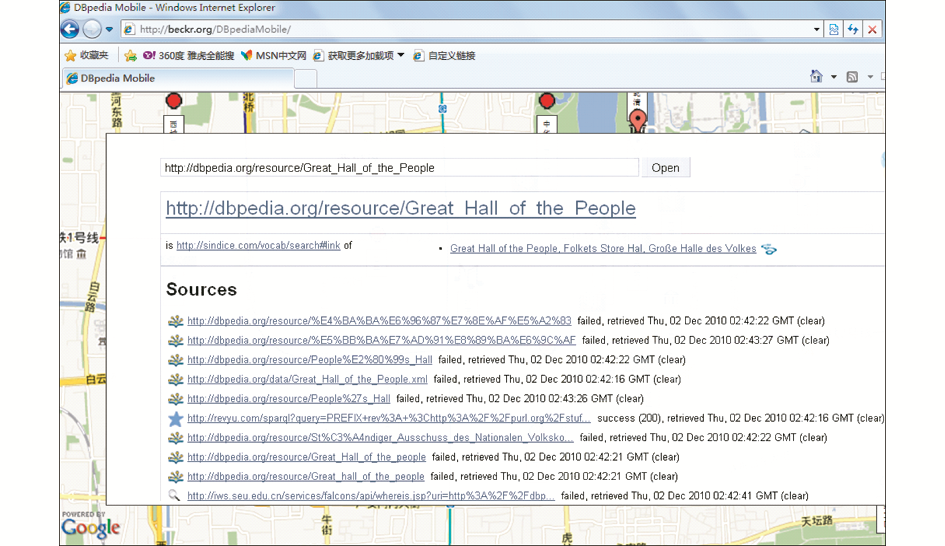 | 图3 DBpedia Mobile |
3.3 数据挖掘
与UI应用不同的是,数据挖掘型应用对DBpedia数据及以DBpedia为中心的开放互联数据进行深入挖掘,发现新的知识,而不是仅停留在简单查询操作上。数据挖掘型应用主要利用了DBpedia的语义Web知识组织、跨领域知识库、多语言知识库、实时动态知识库和关联数据中枢特征。目前,基于DBpedia的数据挖掘主要通过语义相似度计算、语义规则推理、人工智能等辅助方法实现。DBpedia Relationship Finder是一个典型的基于DBpedia的数据挖掘与知识发现系统。通过DBpedia系统可以计算在英文Wikipedia中描述的两个事物之间的语义距离。该系统计算两个事物之间的语义距离算法如下[ 25]:
输入:第一事物O1,第二事物O2,最大距离dmax,最大结果数n,对象和谓词忽略词表
If 查询已保存 then
直接从缓冲区中读取结果;
else
if O1和O2是在同一个子图之中 then
根据元素对照表,计算最小距离dmin和最大距离dmax
计算并显示连接;
设变量d=dmin
设变量m=0;
While d 通过SQL语句获取O1和O2之间的长度为d的连接 (排除忽略词表中的对象和属性之外) If 连接存在 then 显示连接; m=m+发现的连接数; d=d+1; If d=dmax then 输出:在给定的最大语义距离之内未发现连接 else 输出:连接不存在,对象在另外一个子图中 Loop
3.4 跨域共享与服务
DBpedia跨域共享与服务功能的实现有两种:利用DBpedia本身数据内容的跨领域性和利用DBpedia的关联数据中枢特征。其中,基于关联数据中枢特征的跨域共享与服务是DBpedia对关联数据领域做出的最重要的贡献之一。从DBpedia的特征分析可以看出,DBpedia已经成为关联数据中枢,是连接不同开放关联数据集的中心节点(见图2)。因此,可以利用DBpedia特征开发出基于DBpedia的跨域共享与服务系统。在基于DBpedia的跨域共享与服务系统之中,DBpedia扮演着不同数据集的纽带角色。
DBpedia知识集是从Wikipedia自动抽取相关知识而来的,其知识集结构化程度和数据质量往往低于由专家手工创建的知识库。为了提高语义知识处理的效率,可以综合运用DBpedia数据集及其他手工创建的结构化程度较高的本体,例如Open Cyc,SUMO或WordNet等[ 26]。此类应用是跨域共享与服务的另一种类型,即DBpedia与其他数据集的集成,而不是通过DBpedia数据集实现对其他数据集的跨域共享与服务。以Revyu项目为例,在Revyu中可以对DBpedia数据进行评论,关键代码如下[ 27]:
@prefix rev:
@prefix foaf:
@prefix rdfs:
<> a rev:Review;
rdfs:label "Review of Cold Mountain, by Alice";
foaf:primaryTopic
rev:text "This movie sucks. Miss it.";
rev:rating 1;
rev:minRating 1;
rev:maxRating 5;
rev:reviewer
从以上代码可以看出,在应用系统研发中可按照关联数据的原则和DBpedia的数据互联中枢特征,实现对DBpedia及其他相关数据集的跨域共享与服务。因此,DBpedia及关联数据技术的出现为跨域共享与服务提供了更为容易的技术条件和实现环境。
4 结 语
DBpedia主要完成了3项基本工作,即从Wikipedia中抽取结构化数据、描述数据的语义信息、以数据联网形式提供给用户。在完成上述3项基本工作的过程中,DBpedia表现出6个不同的特色,即大规模人机协同、语义Web知识组织、跨领域知识库、多语言知识库、实时动态知识库和关联数据中枢。DBpedia的这些特征支持了4种不同类型的应用,即UI应用、语义标注、数据挖掘、跨域共享与服务。DBpedia在某种程度上克服了目前本体知识库建设中存在的领域限制、数据规模小、结构化程度不够、本体内容不能动态更新、实例数据不够等局限,为数据网建设提供了一种数据规模较大并且结构化程度较高的跨领域动态知识库建设方案,并积累大量的实例数据,是目前最大的跨领域动态语义知识库之一。因此,DBpedia对语义知识库和开放关联数据的建设与维护具有重要的借鉴价值。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|