
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
语义网环境下数据溯源表达模型研究综述*
引用本文
沈志宏, 张晓林. 语义网环境下数据溯源表达模型研究综述* . 现代图书情报技术, 2011, 27(4): 1-8
Shen Zhihong, Zhang Xiaolin. Data Provenance Model in Semantic Web Environment: An Overview. 现代图书情报技术, 2011, 27(4): 1-8
Permissions
Shen Zhihong, Zhang Xiaolin. Data Provenance Model in Semantic Web Environment: An Overview. 现代图书情报技术, 2011, 27(4): 1-8
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
语义网环境下数据溯源表达模型研究综述*
摘要
综述语义网环境下数据溯源在表达模型与技术上的研究进展,重点研究Open Provenance Model、Provenir Ontology与Provenance Vocabulary的描述方法和能力,结合科研环境,讨论这些溯源模型在使用和推广上所面临的挑战。
关键词:
数据溯源; 工作流溯源; 溯源模型; 开放溯源模型; 语义网; 关联数据
中图分类号:TP393
Data Provenance Model in Semantic Web Environment: An Overview
Abstract
This paper reviews the progress of research on provenance in the Semantic Web environment, and introduces provenance models including the Open Provenance Model, Provenir Ontology and Provenance Vocabulary, focusing on the description methods and description capabilities of them. Finally, it discusses the difficulties and new challenges when applying these provenance models in the scientific research environment.
Keyword:
Data provenance; Workflow provenance; Provenance model; Open provenance model; Semantic Web; Linked data
1 概 述
在当今开放的网络环境中,人们常会在Web上发现一些有问题的、甚至自相矛盾的信息。判定这些信息的真实性往往需要借助于Data Provenance。Provenance翻译成“溯源”、“起源”,数据溯源也称为“数据族系(Data Lineage)”、“数据系谱(Data Pedigree)”、“数据来源(Data Derivation)”等。通过溯源,人们可以根据艺术品的出处和所有者来鉴别艺术品的真实性,了解食品工业、汽车行业中产品的生产流程,明白科研活动中的数据是如何基于科学工作流计算出来的还是基于传感器、仪器采集而来的。在分布式网络环境(如:e-Science,Web of Linked Data)中,很多数据驱动的应用都会集成和融合一些数据,如果不记录这些原始数据的溯源信息,融合后的数据其真实性和有效
性将会有所降低。
国际上讨论溯源技术的组织和会议很多,比较早的包括Data Provenance/Derivation Workshop[ 1]、Data Provenance and Annotation[ 2]、Provenance Aware Storage Systems(PASS)[ 3]等,较近的包括International Provenance and Annotation Workshop Series(IPAW)[ 4]、Workshop on the Theory and Practice of Provenance(TaPP)[ 5]、Principles of Provenance (PrOPr)[ 6]、Provenance in Practice Workshop(PPW)[ 7]、International Workshop on the Role of Semantic Web in Provenance Management(SWPM)[ 8]、International Workshop on Data and Process Provenance(WDPP)[ 9]等。另外,W3C也于2009年9月专门开设了W3C Provenance Incubator Group[ 10](以下简称PROV-XG)来研究语义网环境下的溯源。
文献[11]对溯源相关的文献做过统计,结果如图 1所示:
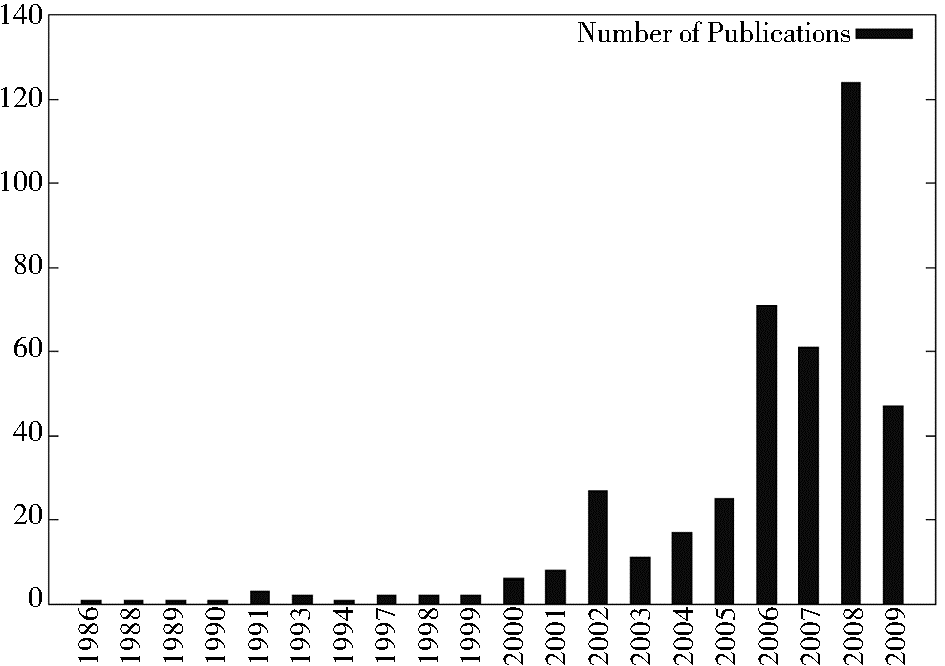 | 图1 溯源技术研究文献统计图[ 11] |
从1986年到2009年,关于溯源的发表物为425篇,最早的文献[12]可以追溯到1986年,它介绍了一项用以帮助分析人员理解和校验数据结果的审计技术。通过图1可以发现,基本上有一半的文献都是2006年以后发表的。另外,不难看出文献发表的几次高峰,这与溯源研究社区的活动也正好一致:2002年,由Foster与Buneman组织了第一次溯源工作组会议;2006年,由Foster和Moreau组织了第一届IPAW会议[ 13];2008年,由Freire和Moreau组织了第二届IPAW会议[ 14]。另外,2010年6月,IPAW2010[ 15]在纽约召开,该次会议发表了各种文章和报告共41篇,关注的主题包括溯源模型、溯源架构与工具、溯源数据的安全保障、Linked Data下溯源信息的发布和消费等。
国内针对溯源的研究不多,戴超凡等[ 16]对数据溯源的发展现状做了综述,并对数据仓库中数据日志跟踪的理论与方法进行研究。李亚子[ 17]对数据溯源标注模式与描述模型做了综述,陈颖[ 18]结合目前的描述模型提出了一种基于DNA双螺旋结构的数据溯源模型。此外,乐鹏等[ 19]结合空间数据研究了基于SOA的空间数据溯源,李秀美等[ 20]则从安全的角度研究了数据溯源的安全模型。
随着语义网的发展和溯源研究的不断深入,人们越来越迫切地需要实现不同溯源系统的信息交换与互操作,这催生了各种形式化、语义化的溯源表达模型的产生,本文就语义网环境下数据溯源在表达模型与技术上的研究进展进行综述。
2 数据溯源的概念与定义
溯源的概念由来已久,但直到2007年Buneman等[ 21]才明确地提出将溯源划分成两类,即粗粒度的工作流溯源(Workflow Provenance)和细粒度的数据溯源(Data Provenance)。
数据溯源指某个转换步骤结果中的片段数据(Single Pieces of Data)是如何衍生的。最传统的例子是针对数据库D通过一个SQL查询得到结果Q(D)。2001年Buneman等[ 22]将数据库领域中的溯源(数据溯源)区分为Why-provenance 和Where-provenance,2007年Green等[ 23]在此基础上引入了How-provenance。2010年Ram等[ 24]提出W7模型,指出数据溯源信息应该包括Who、When、Where、How、Which、What、Why 7个部分。工作流溯源用来记录工作流中产生最终输出的完整过程。文献[25]用工作流模型(时序图) 和构建图对溯源进行描述,该模型由4 个基本的组件组成:工作流引擎、服务、为服务提供功能的应用和在工作流里生产与消费的数据。
可以看出,人们尝试从不同的视角给溯源以不同的定义和理论模型。文献[11]对这些不同的定义给出了全面的综述。PROV-XG给出了数据溯源的工作定义(Working Definition)[ 26],它认为一个资源的溯源指的是对资源的生产、传递等影响中的实体和流程的描述记录,溯源为评估真实性、增加信任、再现过程提供了必要的基础。
数据溯源根据应用领域的不同,其包含的内容也不同。本文结合PROV-XG给出的一些示例与其他文献[ 27, 28],整理如表 1所示:
| 表1 数据溯源包含的内容 |
溯源与元数据之间存在着某种重合的关系,溯源信息实际上是一种上下文的元数据。PROV-XG认为,元数据用以描述对象的属性,而对象属性往往包含着数据溯源信息,因此两者在有些情况下是一致的。图书馆界在考虑数字资源长期保存时,在长期保存元数据中也考虑了溯源。例如,CEDARS(CURL Exemplars in Digital ARchiveS)[ 29]将保护描述信息细分为确认信息、环境信息、固化信息以及溯源信息。另外,根据NSF[ 30]在2008年对元数据的定义“元数据为数据的子集,用以概括数据的内容、环境、结构、相互关系和溯源”也可以看出,数据溯源信息可以认为是元数据的一部分。以一条科学数据为例,它往往会包含创建者和创建时间等元数据项,当从溯源的角度来分析时,每次所做的创建、修改的过程以及涉及到的一些主体(人员或者程序)、时间、空间、生成方法(如:根据影像修复算法),这些元数据项就属于溯源信息。
溯源与信任(Trust)也存在着一定的关系,通常认为,可以从完整的溯源信息中推导出信任。信任是一个基于上下文的主观性判断,而溯源为信任的推导提供客观的记录。当然,在推导的过程中,对主体的身份认证尤显重要。但是身份认证在分布式、异域环境下会显得格外复杂,如:用户的唯一标识、数字签名、访问控制策略等。
3 数据溯源表达模型
得益于语义网的发展,在2006年芝加哥召开的第一届IPAW会议[ 13]中的一个讨论溯源标准化的分会上,溯源研究社区提出了需要更好地理解不同溯源系统的性能和表达,并研究它们的异同与设计动机;同时期望通过溯源信息的交换,建立起系统之间的互操作。2007年8月,继两届溯源竞坛(Provenance Challenge)之后,在盐湖城的一个工作组会议之后,Moreau等[ 31]发布了开放溯源模型(Open Provenance Model,OPM)。此后,关于数据溯源的表达模型竞相开发出来。除了OPM之外,还有Provenir Ontology、Provenance Vocabulary、SWAN Provenance Ontology等。此外还有已经广为接受的词表,如:Proof Markup Language、Dublin Core、PREMIS、WOT Schema、Semantic Web Publishing Vocabulary、Changeset Vocabulary,尽管它们不是专门针对数据溯源而提出的,但是与溯源模型存在着一些交叉和重合。因此,人们常常研究这些模型之间的异同与映射技术。
3.1 开放数据溯源模型OPM
OPM规范1.0版本于2007年8月发布。随着几届溯源竞坛的相继展开,OPM规范推出1.01版本、1.1版本。OPM设计的目标是为不同的系统提供可交换的溯源信息,并允许开发人员创建并共享操作该模型的工具。OPM同时从技术角度定义了溯源,支持对任何事物(不仅仅是针对计算机系统)的溯源,并允许多级描述同时共存。
OPM首先定义了三个核心概念,即Artifact、Process和Agent。Artifact用以指代一个状态,它可以是物理的一个对象,也可以是计算机系统中的一个数字化表达。Process指代由Artifact引起的一个或者一系列的动作。Agent指代Process的催化剂,它用以促进、控制和影响Process的执行。此外,OPM还引入了Role的概念,一个Process可能会产生多个Artifact,这些Artifact就会拥有不同的Role。以某次除法运算为例,Agent为计算器(或者运算程序),Process为除法运算,参与运算的有两个Artifact,它们分别属于除数和被除数这两个角色,运算的结果也包含两个Artifact,它们则分别属于商和余数这两个角色。
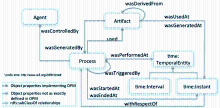
OPM常常采用有向无环图来表示溯源图,Artifact、Process和Agent表示为节点,它们之间的关联表示为边。图 2列出了OPM各节点之间所有可能的关联[ 32]。可以看出,同一类节点之间也会存在关联,如:某个Artifact可能会wasDerivedFrom另一个Artifact,某个Process会wasTriggeredBy另外一个Process。文献[32]为这些关系分别给出了严格的定义,如:P2 wasTriggeredBy P1被定义成“启动P1为完成P2的必要条件”。
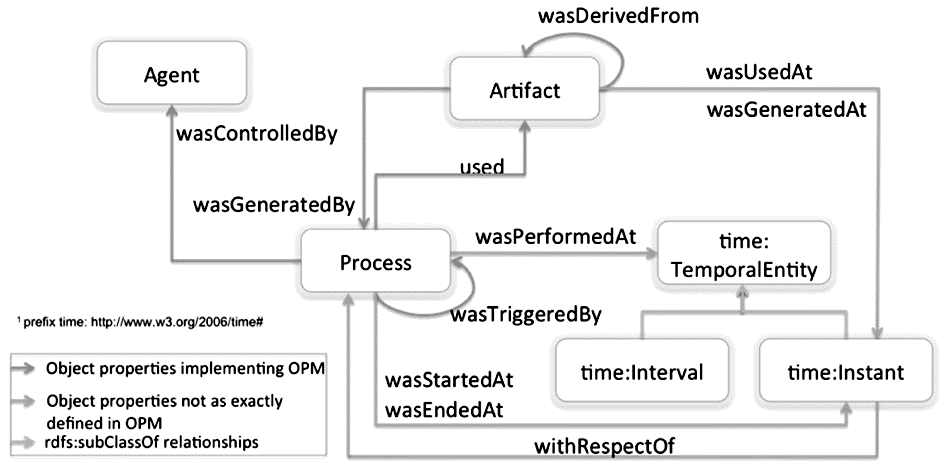 | 图2 OPM溯源模型结构图[ 32] |
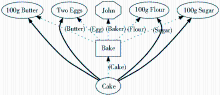
绘制OPM溯源图时,一般使用椭圆表示Artifact,矩形表示Process,八角菱形表示Agent。如:John烤蛋糕的过程溯源可以描述成如图 3所示:
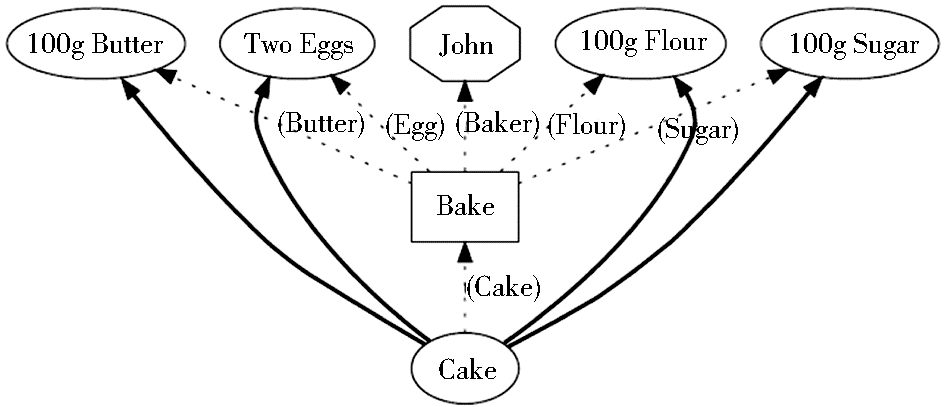 | 图3 John烤蛋糕的过程溯源[ 32] |
3.2 Provenir数据溯源模型
2008年,美国赖特大学Sahoo 等[ 33]在第二届IPAW 会议上提出了Provenir模型,Provenir来自于法语,意思为“to come from”。
Provenir数据溯源模型给出了Provenir Ontology[ 34]。Provenir Ontology定义了三个主要的类作为模型的基本组件,它们是Data、Process、Agent。Data类代表科学实验中的原始材料、中间材料、最终产品以及影响科学流程执行的一些参数。Process和Agent的含义与OPM中的相似。不过Provenir Ontology强调了两个概念,即Occurrent和Continuant,Occurrent指那些随着时间变化而变化的偶然性的特性,Continuant相反,指那些不随时间变化而改变的持续性的特性。Provenir Ontology认为,Process是Occurrent的,Data和Agent是Continuant的。
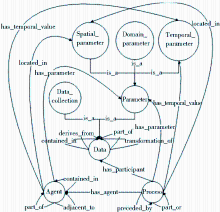
Data类具有两个子类Data_collection和Parameter,Data_collection代表科学过程中参与的数据实体,Parameter为影响科学过程的一些个体,它又可细分为三个子类Temporal_parameter、Spatial_parameter、Domain_parameter,分别代表时间的、空间的、领域相关的参数。Provenir Ontology类的关系如图 4所示[ 33]:
 | 图4 Provenir Ontology模型结构图[ 33] |
文献[33]还对常见的溯源信息查询模式进行了总结,并针对Provenir Ontology给出了查询函数,同时一一给出了形式化定义。笔者整理如表 2所示:
| 表2 溯源信息查询函数定义 |
Provenir Ontology在不同领域中都得到了应用,包括生物医学科学、海洋学、传感器、卫生保健等领域。
3.3 Provenance Vocabulary
在LDOW2009(Linked Data On the Web)工作组会议[ 35]上, Hartig等[ 36]提出了一个面向Web上Linked Data的溯源模型,并给出其OWL本体模型Provenance Vocabulary。Provenance Vocabulary从两个维度描述数据溯源,即数据创建(Data Creation)与数据访问(Data Access)。数据访问在Web上很常见,但是在此之前,人们很少关注描述数据访问过程中的溯源。
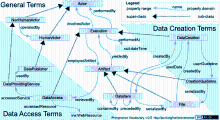
Provenance Vocabulary定义了一个核心的词表(http://purl.org/net/provenance/ns#),并提供了三个扩展模块:Types(http://purl.org/net/provenance/types#)、Files(http://purl.org/net/provenance/files#)和Integrity Verification(http://purl.org/net/provenance/integrity#)。Provenance Vocabulary包括通用词汇、用于数据创建的词汇以及用于数据访问的词汇。与前两个模型类似,通用词汇定义了三个核心概念:Actor、Execution和Artifact。Actor具有两个子类HumanActors和NonHumanActors,HumanActors用以指代人、组织或者公司,NonHumanActors则指代软件、工具、算法等。Artifact又细分为DataItems和Files两个子类。Provenance Vocabulary的结构如图 5所示[ 37]:
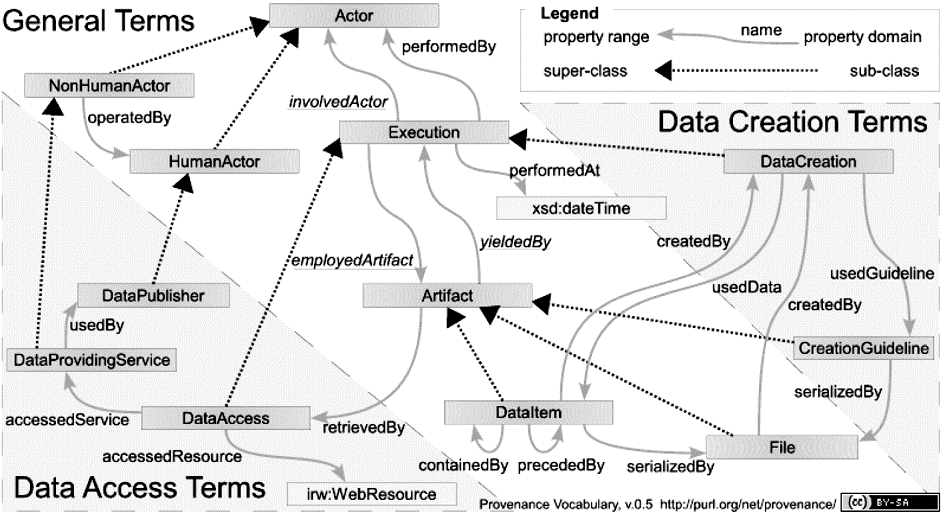 | 图5 Provenance Vocabulary模型结构图[ 37] |
Provenance Vocabulary可以描述数据创建的不同方式,文献[37]中给出两个例子,如:Alice在2009年7月10日手动创建了一个RDF文件,可以描述如下:
<>rdf:type prv:DataItem;
rdf:type
prv:createdBy [rdf:type prv:DataCreation;
prv:performedAt "2009-07-10T12:00:00Z"^^xsd:dateTime;
prv:performedBy
另外一个例子是描述Bob通过传感器Sensor1采集到一条数据,描述如下:
_:a rdf:type prv:DataItem;
prv:createdBy [rdf:type prv:DataCreation, prvTypes:Measurement;
prv:performedAt "2009-07-10T12:00:00Z"^^xsd:dateTime;
prv:performedBy
prv:operatedBy
除了以上介绍的三种溯源模型之外,在其他一些广为接纳的模型中其实也包含溯源描述的能力。如:与OPM相比,Dublin Core元数据词汇[ 38]所包含的dct:Agent、dct:Source、dct:Contributor、dcmitype:Event、dct:ProvenanceStatement等都具有可映射的溯源信息。另外还有一些词汇,如dct:Contributor、dct:Creator、dct:Publisher,以及dct:Created、dct:dateAccepted、dct:dateCopyrighted、dct:dateSubmitted、dct:Modified等属性名,它们与OPM词汇在含义上也存在着某种重合,但不存在直接的映射方法。
PROV-XG对不同的词表做了较为细致的研究,并针对包括Provenir Ontology、Provenance Vocabulary等在内的9个词表,研究了它们与OPM之间的映射方法[ 39]。通过采用SKOS[ 40]的skos:broader、skos:narrower和skos:related,以及OWL2[ 41]的owl:equivalentClass、owl:equivalentProperty,给出了不同的类与属性之间的映射关系。
4 结 语
近年来随着语义网的深入,人们已经不再局限于溯源的理论研究和在单个领域中的应用,而是开始考虑如何将溯源以形式化的方式表达出来,以及如何实现不同溯源系统之间的互操作。通过对比可以看出,这些表达模型基本上都存在着一些值得借鉴的共性。
(1)这些溯源模型都没有给出一套统一的表达,而是鼓励人们针对不同应用领域对其进行继承和扩展。可以看出,无论OPM、Provenir Ontology还是Provenance Vocabulary,它们首先给出的还是三要素(Artifact、Process、Agent),同时允许基于此参考模型进行扩展。以Provenir Ontology为例,很显然它无法给出一个包罗万象的溯源本体,因此它推荐以其为通用参考模型,结合特定领域(如生物学、海洋科学、天文学等)来构造各自的溯源本体模型,如:ProPreO代表蛋白质组学领域特定的本体模型。
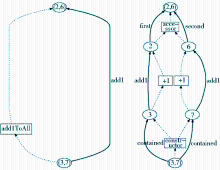
(2)尽管各种模型没有对具体的描述粒度做出严格的限制,但在表达能力上都支持不同描述粒度的细化和合并。图 6是OPM给出的一个例子,左侧展示的列表(3,7)由列表(2,6)执行加1的操作生成,右侧展示的则是更为细节的操作,列表(2,6)首先被分解成元素2和6,它们各自被加1,生成3和7,最后再被组装成列表(3,7)[ 37]。至于应该采取哪一种表达方式,取决于应用的需求。OPM甚至还提供了将左右这两种描述合并在一起的表达能力。
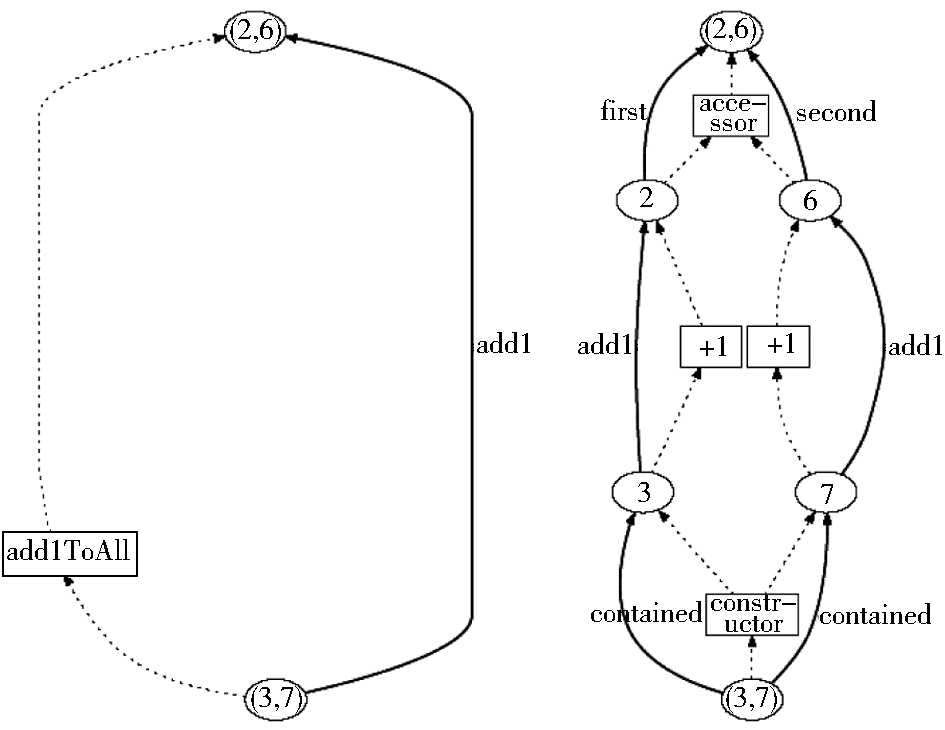 | 图6 溯源图的不同粒度[ 37] |
但是目前,无论是如上这些溯源模型自身的表达能力上,还是针对它们而提出的技术实施框架上,都存在着一些急需改进和深入的地方。在真实的科研环境中,这些溯源模型的使用和推广还面临着较大的挑战。
(1)如何保证科学流程的溯源信息的完全可重算能力。
重算(再现)数据的产生过程是数据溯源的重要目标,但是在实际的科学计算中,往往会包含很大的数据量(大矩阵或者上百兆(M)、上吉(G)的数据文件),参与计算的环境极其复杂,不仅会依赖于特定的自然条件,还会依赖于特定的软件平台和环境,计算的过程也可能会涉及到多个系统之间的切换和配合,在这种情况下,如何来记录足够详尽的溯源信息,仍是一个很难解决的问题。即便有一个足够强大的溯源模型将这些上下文信息描述出来,如何构造一个重算框架,还原这些上下文,也是一个比较重要的问题。
(2)目前在Web上还缺乏一套统一的溯源信息发布与访问机制。
通过Linked Data等技术,人们可以将数据以统一的方式发布出去,但是如何再提供该数据的溯源信息,这些溯源和数据本身又该如何关联,目前还没有成熟的办法。文献[42]就如何在Web上集成数据的溯源信息作了简略的讨论,包括如何在HTTP响应头或者描述内容本身来包含溯源信息,如何以引用的方式(by Reference)或者以值的方式(by Value)来包含这些溯源信息等。溯源信息可以针对一个Web资源、一个Web资源的描述,以及一个Web资源的某个状态。那么如何来发布这些信息,又如何采用必要的策略来保障这些溯源信息自身的安全,目前还缺乏成熟的技术框架。
(3)如何创建这些溯源信息,这也是溯源研究一直关注的一个问题。
数据溯源的创建基本上可以通过两种方式:
①采用查询求逆(或者构造一个逆查询)推算出溯源信息,这种方式称为“查询反演(Query Inversion)”[ 43],又由于它是在需要用到数据溯源时才进行计算分析,因而又称为“Lazy”方式。
②采用标注的方法,即直接在数据上注明其来源。由于这种方式是在一开始就让数据通过标注[ 44]携带一些数据溯源信息,因而又称为“Eager”方式。
面向复杂科学过程的数据溯源,需要提供一种自动化的标注方法。本文认为,溯源模型的发展和标准化会带来另外一个后果,即使得溯源信息标注插件的标准化成为可能。一方面,硬件(如摄像头、传感器)、软件(如文档处理系统、数据加工软件、科学工作流系统)厂商可以结合溯源模型,提供一些可插拔的、可扩展的溯源信息标注插件接口(插槽),并定义插槽与插件之间交换的溯源信息的格式。另一方面,开发人员遵循这些协议和格式,开发出一些通用的、专用的标注插件。最终用户一旦安装了这些插件,即可完成标准化的溯源信息的自动创建。
以上这些困难会在相当长的时间内继续存在,但是不可否认,借助于数据溯源,有利于评估数据质量和可靠性,查询数据来源,再现数据的产生过程,发生错误时能够快速定位产生错误的位置从而分析出错误原因等。数据溯源无论对科研领域还是商业领域,都具有重要的意义。因此,如何提供更完善的溯源表达模型,以及基于这些模型提供更为便捷强大的解决方案,是溯源研究的下一步方向。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|