
{kind=link}
{kind=link}
基于领域中文文本的术语抽取方法研究
引用本文
谷俊, 王昊. 基于领域中文文本的术语抽取方法研究. 现代图书情报技术, 2011, 27(4): 29-34
Gu Jun, Wang Hao. Study on Term Extraction on the Basis of Chinese Domain Texts. 现代图书情报技术, 2011, 27(4): 29-34
Permissions
Gu Jun, Wang Hao. Study on Term Extraction on the Basis of Chinese Domain Texts. 现代图书情报技术, 2011, 27(4): 29-34
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于领域中文文本的术语抽取方法研究
摘要
在ICTCLAS词典分词的基础上,利用串频最大匹配算法从中文专利文本中抽取候选术语,再利用TF-IDF算法得到相关特征项的权重,经过筛选后得到最终概念术语。最后,抽取部分样本数据进行实验,并对结果进行分析。
结果中还出现了诸如“种板带淬火控冷”,“重力除尘器卸灰无”等没有意义的复合词,计算机无法自动剔除,因此在遇到此类不确定的候选术语时,需要标记后转为人工验证,并将验证结果存入过滤模型库中,以提高自动抽取的精度。
关键词:
本体; 概念抽取; 串频最大匹配; TF-IDF; 中文分词
中图分类号:TP391
Study on Term Extraction on the Basis of Chinese Domain Texts
Abstract
Based on the ICTCLAS dictionary segmentation, this paper proposes a method that extracts relevant concept terminology from the Chinese patent texts by maximum matching and frequency statistics, then computes the weights of the items by TF-IDF and gets the final concept terminology. Finally, it analyzes the results with the sample data extraction experiments.
Keyword:
Ontology; Concept extraction; Maximum matching and frequency statistics; TF-IDF; Chinese word segmentation
1 引 言
本体是一种有效的知识组织方式,被纳入语义网体系,因其具有明确性、形式性和共享性三大特征,可以在网络资源上融入计算机可以理解的信息,达到资源的语义理解,是语义层面上网络信息的交换与共享的基础[ 1]。它将Web资源通过语义的方式组织起来,使得互联网的资源获取更加便捷,是在互联网上提供高效服务的先决条件。目前,本体在人工智能、信息检索、知识工程、数据挖掘等学科领域中被广泛研究和应用[ 2]。
本体构建的难点之一就是自动从文本中抽取概念术语,抽取出的术语将直接影响到所建本体的质量。目前国内外很多学者都开展了这方面的研究,Turney提出使用遗传算法和决策树机器学习方法来抽取文本中的术语[ 3];Witte等通过利用朴素贝叶斯技术对短语离散的特征值进行训练, 通过训练结果从文档中抽取实体短语[ 4];姜韶华等则提出了一种基于汉字串频度及串长度递减的中文文本自动切分算法,实现了短语的自动切分和识别[ 5];刘桃等提出了一种基于信息熵的领域术语抽取方法[ 6];何婷婷等提出通过术语在专业语料与背景语料中出现概率的对比,采用LLR公式对术语进行评分,实现概念的抽取[ 7];王昊等提出基于HMM词角色标注和基于CRFs字角色标注的人名实体抽取模型,并进行了比较[ 8];刘豹等提出了一种使用条件随机场模型进行标注识别,并结合规则对错误识别结果进行后处理的科技术语识别方法[ 9];岑咏华等提出一种基于双层隐马尔科夫模型的中文泛术语识别和提取的思路和系统框架,并予以实现[ 10];温春等提出了通过领域相关度和领域主题一致度抽取出最终领域术语的方法[ 11];高文利利用命名实体识别技术实现了武器对象的判定[ 12];周浪等使用子串归并、搭配检验和领域相关度计算技术来提高低频术语和基础术语的抽取效果[ 13]。
在现有的中文术语抽取方法中,有的依赖于文法规则的制定,语言依赖性强,无法应用到所有的领域,且召回率不高;有的依赖于大规模的手工标注和语料训练,并且需要不断调整以逐步提高抽取的精度。而本文则是在上述研究的基础上,提出先进行词典切分,再结合串频最大匹配切分算法和TF-IDF特征项计算的方法,实现中文专利文献中术语的自动抽取。这样可以在一定程度上避免规则制定和语料训练所花费的大量人力和物力,并且能够在适当语料规模条件下,最大限度地抽取出候选术语,从而在不降低准确率的前提下,提高抽取结果的召回率。
2 实验数据
中国国家知识产权局专利检索平台(http://www.sipo.gov.cn)涵盖了1985年以来所有在中国申请和公开的发明、实用新型和外观设计专利。根据统计,截至2010年12月,在华发明、实用新型和外观设计专利总量约为703万件,其中发明专利将近200万件[ 14]。下载截至2010年12月国际专利分类号(IPC)为C21(铁的冶金)的专利数据作为实验对象,共计6 435件专利。从下载的表结构上看,包括申请号、申请日、名称、公开(公告)号、主分类号、分案原申请号、分类号、颁证日、申请(专利权)人、地址、发明(设计)人、国际申请、国际公布、进入国家日期、专利代理机构、代理人、摘要、公开日、优先权等字段。由于本文主要研究从文本中抽取概念术语的方法,而且专利名称相对于其他字段更能反映主题,因此,抽取专利名称和摘要作为本文的实验数据。
3 方法描述
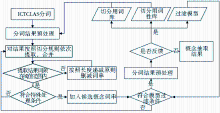
使用中国科学院计算技术研究所开发的ICTCLAS分词系统对文本进行初步切分,得到初步分词结果,再利用串频最大匹配算法进行短语的合并和未登录词的识别,得到术语实体预处理集合,利用TF-IDF特征项计算的方法进行过滤和筛选得到最终的识别概念术语,算法流程如图1所示:
 | 图1 中文概念术语抽取流程 |
3.1 ICTCLAS初步分词
ICTCLAS是一种基于层叠隐马尔科夫模型的词典分词方法,它将汉语词法分析的所有环节都统一到一个完整的理论框架中,分词速度为500KB/s,分词精度达到了98.45%。ICTCLAS能够很好地实现汉语分词、切分排歧、未登录词识别、词性标注等词法分析任务,是目前最好的汉语词法分析器之一[ 15],其分词效果如表1所示:
| 表1 ICTCLAS分词示例 |
由表1可以看出,虽然ICTCLAS能够较好地对汉语句子进行切分,并且可以给出每个切分词的词性,但是有些未登录词依然无法准确识别,例如“不锈”、“结构钢”、“钢带”、“条钢”等,这对于一些能够反映专利主旨的新词(如“结构钢”)的识别较为不利,需要进一步完善才能达到术语抽取的目的。
3.2 串频最大匹配算法
定义1: 分词结果集合T,是由ICTCLAS系统进行分词处理后的结果集,其中不仅包含待处理的词串,还包含一些没有意义的词;
定义2: 切分词库S和切分词性库S1,S包括没有意义的词集合,既包括中文词,也包括部分英文词,S1用于对分词结果进行切分的词性集合,由人工整理;
定义3: 截断符∧,对分词结果T进行切分处理后,结果中的切分词和具有切分词性的词会被替换成统一的截断符号∧;
定义4: 初步切分后的结果集合T1,经过S和S1的初步切分后产生的带有∧的分词结果集合;
定义5: 候选词串集合DT和候选词集合ST,DT为T1中包含的可能成为最终概念术语的词串集合,ST为经过DT组装后的候选字符串集合;
定义6: 过滤模型集合FM,用于对候选词ST词性串进行过滤的模型集合。
由此,得到串频最大匹配算法的过程如下:
(1)分词结果预处理。通过ICTCLAS进行分词得到的结果T需要经过切分词库S(s1…sn)、切分词性库S1(s11…s1n)的过滤才能提供给后续部分使用。切分词库S中存储的是一些常见的虚词,以及对于专利文献来说没有意义的实词,包括“发明”、“方法”、“进行”、“实用新型”,“采用”等;切分用词性库S1中存储的是术语识别中不需要的一些干扰词性,例如“\w”、“\m” 、“\c” 、“\d” 、“\p”等。在进行术语抽取之前,需要将初步分词的结果中相关的切分用词si和切分词性s1i替换成统一的截断符∧,便于对词串T进行再次切分。
(2)初步处理。经过上述预处理之后,词串T就会被自然分割成带有截断符∧的集合T1,T1中包含了所有可能成为候选术语的词串集合DT。由于冶金行业中很多专有名词字数较多,例如“无紊流气体冷却”,分别由“无”、“紊”、“流”、“气体”、“冷却”组成,因此设置可抽取词串长度的最大值为5。遍历DT,如果截取的词串集合DTi(0
(3)阈值筛选。将得到的ST进行阈值筛选,设置阈值的最小值为2,即该ST除了本身出现过一次,还需要在词串集合DT中至少再出现一次。经过观察,笔者发现在专利摘要里描述的词串如果频次大于5的话,该词串基本上不具有实际意义,因此本文设置了阈值的最大值为5。当ST在DT中的出现频率在阈值范围内,则保存为进一步处理的候选词串ST1,否则,根据长度递减的原则,对ST所对应的DTi进行从后到前删减相应位置的dtj,并将缩减后的D 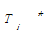
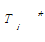

(4)特殊处理。当一个词由单个字组成,且词性不为名词,则该词基本上不能认定为概念术语。因此,对于抽取出的D 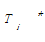
(5)模型过滤。得到候选词串D 
(6)反馈。系统运行过程中支持学习反馈机制,可以根据得到的D 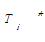
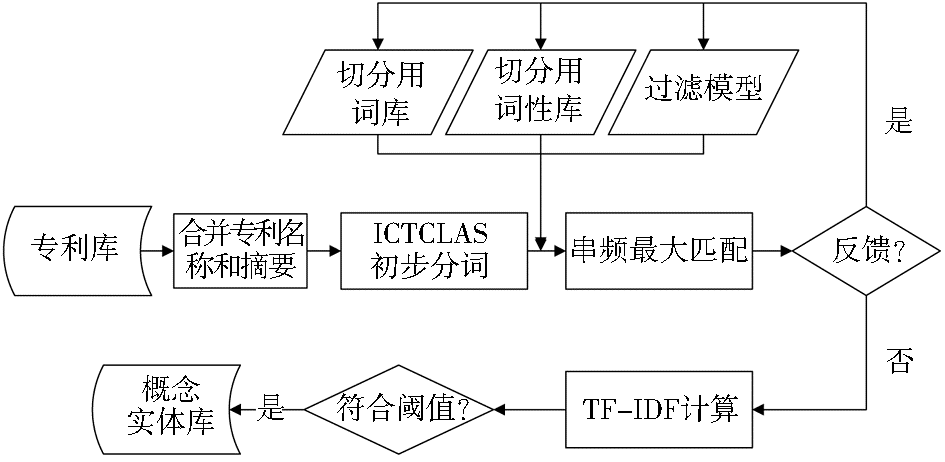
根据上述思想,本文利用C#实现了一个原型系统,其流程如图2所示:
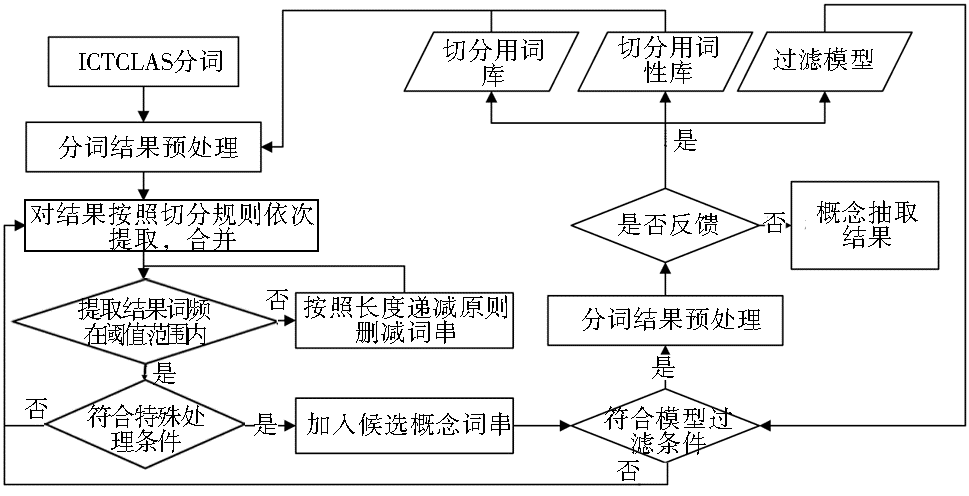 | 图2 串频最大匹配原型系统流程图 |
伪码如下:
(1)利用ICTCLAS进行分词,得到分词结果T,长度为k;
(2)for(int i= 0; i< k; i++)
(3)初始化候选词串、候选词性串;
(4)for(int j= i; j< 定义的最大字符长度+i; j++)
(5)If(当前提取的词为非切分词 && 当前提取的词性不是切分用词性)
(6)加入候选词串和候选词性串;
(7)If(提取出的词串计算在当前SP中的频度在阈值范围内 && 符合特殊处理的条件)
(8)加入候选术语词串;
(9)Else
(10)根据长度递减和最长匹配原则加入候选术语词串;
3.3 基于TF-IDF的特征项权重计算
经过上述处理后,一般来说可以通过计算累计词频的方式来确定文档集合的最终术语集。但是笔者发现,仅依靠单纯的词频统计并不能真实反映出这批语料的概念术语抽取情况,结果集中诸如“钢”、“制备”、“材料”、“炉”、“装置”、“温度”、“气体”等不能代表该专业实际意义的词累计词频排名非常靠前,而“铸造成型”、“装箱退火”等具有实际意义的词排名却非常靠后,这样的结果显然是不符合要求的,如表2所示:
| 表2 累计频次候选术语片段 |
需要利用相应的算法对候选术语集进一步筛选,其思路是:
(1)确定候选术语对特定领域重要程度的衡量公式Weight;
(2)规定一个阈值w;
(3)对于每个候选术语t,如果Weight(t)>w,则候选术语被保留,如果Weight(t)< w,则予以剔除。
本文引入了基于TF-IDF的特征项权重计算方法,运用TF-IDF指数来衡量每个候选术语相对于文档集合的重要程度,可以过滤掉相对不重要的术语,从而筛选出更加具有意义且能够反映文档集主题的最终的术语集合。TF-IDF的特征项权重计算方法如下:
wij=tfij×idfj (1)
其中,tfij表示tj 在文档Di 中的频数,idfj表示tj 的反比文档频数。TF-IDF计算公式有很多种,其中典型的计算公式如下:
wij=tfij×log(N/nj) (2)
其中,tfij表示特征项tfj在文档中的频数,N表示总文档数,nj表示出现特征项tfj的文档数。
式(1)和式(2)的方法可以简单表述为:若某个项在某一文档中出现的频率越高,其贡献越大,但若该项在整个文档集中出现的文档数较多时, 它的贡献将会被减弱。
整个计算过程可以表述为:
(1)计算候选术语在文档Di中的词频;
(2)构建文档×候选术语的二元关联矩阵,以候选术语在文档Di中出现的频次作为矩阵值;
(3)把二元关联矩阵中的数值代入式(2)中进行计算,从而得到每个候选术语的权重。
表3展示了部分候选术语经过计算后得到的结果。
| 表3 基于TF-IDF特征项权重计算结果片段 |
从表3可以看出,经过了TF-IDF特征项权重的计算,如“投球”、“床芯”、“马弗炉”等具有实际意义的词被赋予了较高的权重,而“装置”、“发送”、“温度”等术语,虽然在单个文档中出现的频次很高,但由于涵盖这些术语的文档数量也较多,因此最后只得到了较低的权重。
观察TF-IDF权重计算后的结果,本文给出了一个筛选的阈值为0.08,即权重值高于0.08的术语予以保留,而权重低于0.08的术语则做剔除处理,从而得到最终的术语集。
4 实验结果及分析
此次实验的文档共计6 435篇,经过抽取处理后,共计得到25 497个术语。为了验证本方法的准确性和实际应用价值,笔者从中随机抽取20篇文档,手工提取出相关术语共计154个,再利用本文的方法自动抽取,共得到113个术语,以准确率(准确率=系统识别正确的术语总数/系统能够识别出来的术语总数)和召回率(召回率=系统识别正确的术语总数/随机文档中出现的正确的术语总数)作为测试指标,对术语的抽取结果进行测试,结果如表4所示。由于专门针对钢铁冶金领域的中文专利术语抽取研究相对较少,因此本文没有就实验结果与其他相似的研究进行对比。
| 表4 随机测试结果 |
由表4可以看出,本文所采用的术语抽取方法具有较高的准确率,主要是因为:
(1)基于ICTCLAS初步分词后,被词典收录的一些有意义的词已经被切分出来,而在此基础上使用串频最大匹配的方法进行抽取效果更好;
(2)经过TF-IDF权重计算及筛选,保留了具有实际意义的词,而剔除了那些在文档集中不具有代表性的词。
但是系统的召回率却在一个较低的水平,主要有以下几个方面的原因:
(1)单篇文档信息量较少。由于实验数据只抽取了专利文献中的名称和摘要,包含的信息量相对较少,有些具有实际意义的词在文中可能只出现了1次,那么使用本文的方法则无法将其正确抽取出来。
(2)文档规模不够大。本文只使用了国际专利分类号为C21的专利数据作为实验数据,实际上关于铁的冶金相关专利还应包括“C22”、“C23”、“B21”、“B22”等其他分类的内容,而这些专利文献的概念是相互交叉的,在C21类中出现较少的概念可能在其他类中出现较多。如果实验数据中增加了上述其他分类的内容,再利用TF-IDF算法进行过滤,可以使抽取结果更加准确。
(3)TF-IDF算法有待改进。由于数据集中类间分布具有偏差[ 11]现象,实验数据中的文档类别分布并不均匀,有些子类文档数量庞大,而有些子类数量却比较少,而IDF通常是将文档集作为一个整体去考虑。如果某一类别中的一些特有概念在所在类中计算,可能会得到很高的权重,但如果纳入整个文档集中进行计算,当前的TF-IDF算法赋予这个概念的权重将可能大大降低,而经过阈值筛选后,有可能会被剔除。因此需要将文档集中子类的相关属性考虑到算法中进一步计算。
结果中还出现了诸如“种板带淬火控冷”,“重力除尘器卸灰无”等没有意义的复合词,计算机无法自动剔除,因此在遇到此类不确定的候选术语时,需要标记后转为人工验证,并将验证结果存入过滤模型库中,以提高自动抽取的精度。
5 结 语
中文概念的自动抽取是本体自动构建的基础,其质量将直接影响到本体构建的成败。本文在词典分词的基础上,结合最大串频匹配算法和TF-IDF特征项权重计算方法,实现了中文文本概念术语的自动抽取和新词的发现,这对于以后的本体自动构建工作具有重要意义。
在未来的研究中,将通过加入 “权利要求项”或者专利文献的全文内容来增加单篇文档的信息量;通过增加“C22”、“C23”、“B21”、“B22”等其他分类的专利文献来扩充实验数据的规模;在TF-IDF算法中通过子类拆分并增加参数控制来调整权重计算结果,从而进一步提高本方法的抽取精度。此外还将利用同义词词表,结合聚类、模式匹配以及关联规则挖掘等算法,实现钢铁冶金行业领域本体的半自动构建。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|