{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于社会化标签网络的细粒度用户兴趣建模*
引用本文
易明, 毛进, 邓卫华. 基于社会化标签网络的细粒度用户兴趣建模* . 现代图书情报技术, 2011, 27(4): 35-41
Yi Ming, Mao Jin, Deng Weihua. Fine-grained User Preference Modeling Based on Tag Networks. 现代图书情报技术, 2011, 27(4): 35-41
Permissions
Yi Ming, Mao Jin, Deng Weihua. Fine-grained User Preference Modeling Based on Tag Networks. 现代图书情报技术, 2011, 27(4): 35-41
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于社会化标签网络的细粒度用户兴趣建模*
摘要
针对目前由社会化标签抽取用户兴趣模型过程中存在的问题,在借鉴社会网络分析的基础上,提出构建网站层次和用户层次的社会化标签网络对用户产生的社会化标签进行序化,进而分别得到反映主题领域的社会化标签使用文档和用户标签网络,通过两者相似度的计算形成细粒度用户兴趣模型。实验结果能够验证该模型的科学性。
关键词:
社会化标签网络; 细粒度兴趣; 兴趣建模
中图分类号:G202
Fine-grained User Preference Modeling Based on Tag Networks
Abstract
Aiming at the existing problems in the process of extracting user preferences, a new approach that to organize user generated tags by constructing site-level and user-level tag networks on the basis of social network analysis is proposed. Then, topic based tag documents and topic based user networks are formed. A fine-grained user preference model is formed by computing the similarity between them. The experimental results show that the model is scientific.
Keyword:
Tag network; Fine-grained preference; Preference modeling
作为由用户产生的元数据,社会化标签能够独特反映用户的需求及其变化,由此基于社会化标签的用户兴趣建模问题吸引了学者们的密切关注,并取得一定进展[ 1, 2, 3]。然而,由于社会化标签的大众性和用户参与性,用户使用的社会化标签可能杂乱无章。如果仅以此为基础构建用户兴趣模型,必然会存在相应的不足。显然,已有的相关研究并未完全意识到这个问题。由此,本文将依据社会化标签之间的共现关系,构建社会化标签网络,来实现社会化标签的序化。这种社会化标签网络不仅能够反映社会化标签之间的共现规律,而且利用社会网络分析的相关指标可以深入揭示社会化标签之间的内在关联,进而实现社会化标签的有序组织。更为重要的是,社会化标签网络能够多维度深入挖掘用户的兴趣主题,从而可以启发新的细粒度用户兴趣建模思路。
1 社会化标签网络模型
社会化标签网络本质是一种共现网络,是通过对社会化标签在特定资源中同时出现的情况来反映社会化标签之间内在关联的一种可视化展示方式,通常用顶点来表示社会化标签,用边来表示社会化标签在特定资源中的共现情况。
定义1:U=(RU,TU,LU)为用户层次社会化标签系统。其中,RU={rU1,rU2,…,rUM}是单个用户标注的资源集合,TU={tU1,tU2,…,tUN}是单个用户使用的社会化标签集合,LU={ 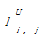
定义2:G=(RG,TG,LG)为网站层次社会化标签系统。其中,RG={rG1,rG2,…,rGm}是所有用户标注的资源集合,TG={tG1,tG2,…,tGn}是所有用户使用的社会化标签集合,LG={ 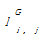
显然,社会化标签网络应当分为两个层次:用户层次社会化标签网络和网站层次社会化标签网络。其中,用户层次社会化标签网络是以单个用户使用的社会化标签为分析对象,而网站层次社会化标签网络是以网站所有用户使用的社会化标签为分析对象。在社会化标签系统中,如果两个社会化标签存在共现的情形,则表明这两个社会化标签之间存在着重要的内在关联,可以建立彼此的连接关系。由此,可以建立用户层次和网站层次社会化标签网络模型,它们从不同层面反映了社会化标签之间的内在关联。需要说明的是,由于用户兴趣的多元性,网站层次和用户层次社会化标签网络模型都应当是一个集合,它包含了若干彼此不连通的社会化标签网络,即任意两个分属于不同社会化标签网络中的节点都没有对同一个资源进行标注。因此,每一个网站层次的社会化标签网络对应网站的一个主题领域,每一个用户层次的社会化标签网络则代表了单个用户的一个兴趣领域。
定义3:TU′={U′1,U′2,…,U′X}为用户层次社会化标签网络模型。其中,U′代表每个彼此分割的用户层次社会化标签网络,X为用户层次社会化标签网络的数目。
定义4:U′=(T′U,L′U,W′U)为用户层次社会化标签网络。其中,T′U={t′U1,t′U2,…,t′UN′}是对应的节点集合,N′≤N,T′U⊆TU,L′U={ 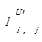

定义5[ 4]:资源节点集合RU中与社会化标签t′∈T′U相连的资源节点集合为RUt′。若RUt′i∩RUt′j≠Φ,则社会化标签t′i和t′j之间可以建立连接关系 
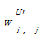
如果将所有用户的社会化标签网络进行整合,便可以得到网站层次社会化标签网络模型TG′={G′1,G′2,…,G′Y},G′表示每个彼此分割的网站层次社会化标签网络(代表网站的一个主题领域),Y为网站层次社会化标签网络的数目。
定义6:G′=(T′G,L′G,W′G)为网站层次社会化标签网络。其中,T′G={t′G1,t′G2,…,t′Gn′}是对应的节点集合,n′≤n,T′G⊆TG,L′G={ 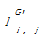
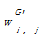
定义7[ 4]:资源节点集合RG中与社会化标签t′∈T′G相连的资源节点集合为RGt′。若RGt′i∩RGt′j≠Φ,则社会化标签t′i和t′j之间可以建立连接关系 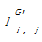

2 基于社会化标签网络的细粒度用户兴趣模型
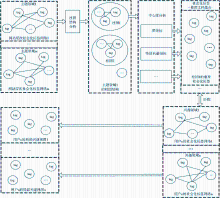
针对社会化标签网络,可以利用社会网络分析的相关指标进行结构分析,以深入揭示社会化标签之间的内在关联,进而实现社会化标签序化,为用户兴趣建模提供高质量的数据基础。由于社会化标签网络分为网站层次和用户层次,所以可以从两种层次建立基于社会化标签网络的用户兴趣模型。然而,如果仅依据用户层次社会化标签网络进行用户兴趣建模,则只能发现用户已有的兴趣,而无法找到用户的未知兴趣。所以,本文提出综合利用两种层次的社会化标签网络进行用户兴趣建模,如图1所示。
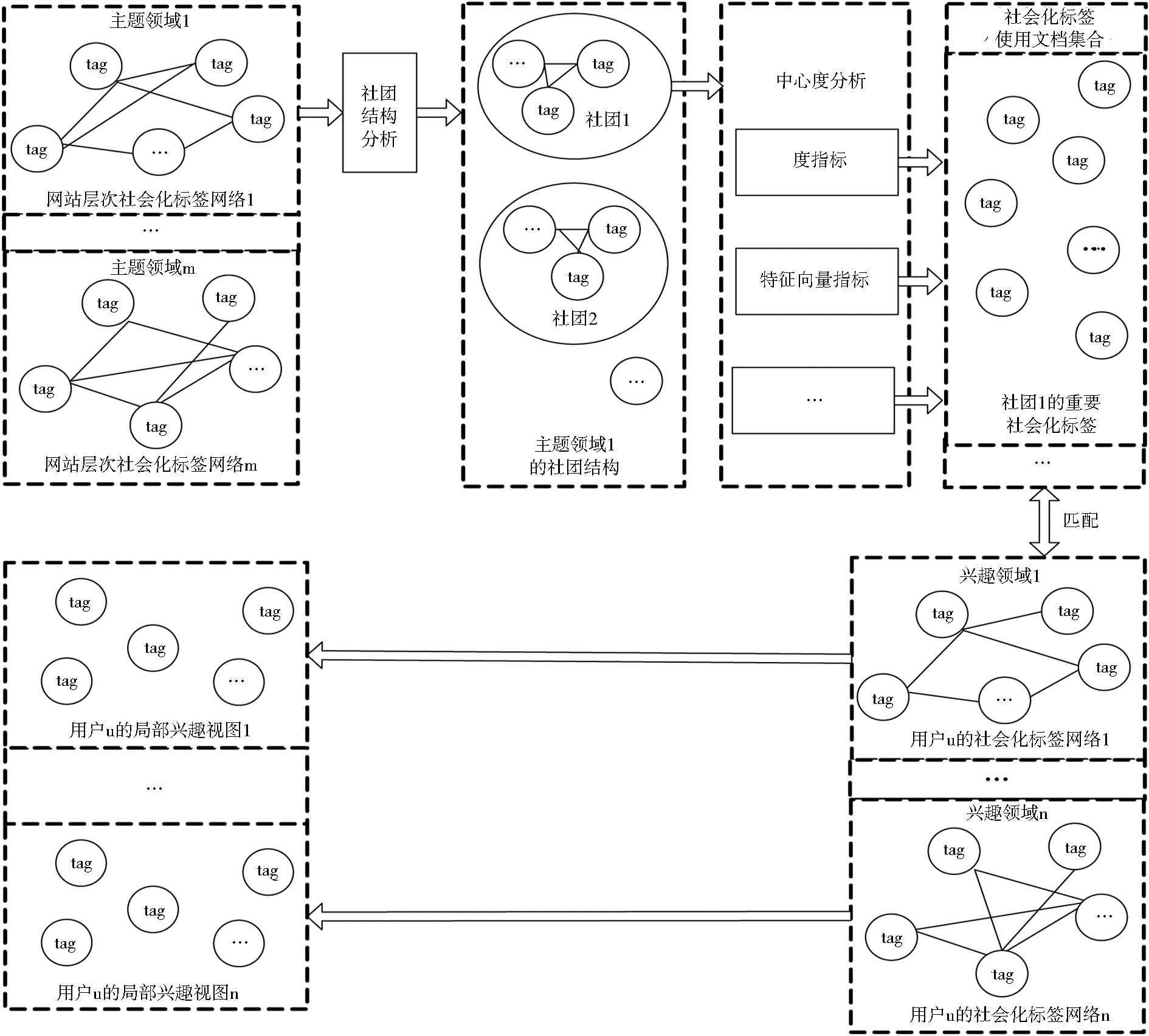 | 图1 基于社会化标签网络的细粒度用户兴趣模型构建过程 |
针对网站层次的每个社会化标签网络进行社团结构分析,将属于同一主题领域的社会化标签进行聚类以形成社团结构,然后运用社会网络分析中的中心度分析方法(如度指标、特征向量指标),找到每个社团中的重要社会化标签以产生社会化标签使用文档,进而将所有社会化标签使用文档与用户u的每个社会化标签网络进行匹配以形成用户u的多个局部兴趣视图,即细粒度用户兴趣模型。
2.1 模型建立的理论依据
社会化标签可以促进用户间的默契与协作,从而“涌现”出对应某个标注资源的、最容易被用户群体所接受的分类[ 5]。由于这种分类是以社会化标签作为类名的,所以在特定领域中比较重要的社会化标签就代表了用户群体对该领域相关资源特征的共同理解。对于网站层次的每个主题领域而言,它们都对应了相关的社会化标签和资源,利用社团结构分析不仅可以对主题领域中的社会化标签进行聚类,同时也能将主题领域进一步细分为若干子领域(资源的集合)。利用中心度分析(如度指标、特征向量指标),便可以发现每个社团中最为重要的社会化标签集合,也就是社会化标签使用文档。每个社会化标签使用文档就代表了大多数用户群体对特定子领域相关资源特征的共同认识,表征着一个细粒度的主题领域。利用社会化标签文档与用户层次社会化标签网络进行匹配,便可以发现在特定子领域中用户u可能感兴趣的相关社会化标签,也就建立了用户局部兴趣视图。这种兴趣视图属于细粒度兴趣表示,它对传统粗粒度兴趣作进一步的划分,可以更为精准地刻画用户兴趣。
2.2 模型涉及的相关方法
(1)社团结构分析
针对网站层次的每个主题领域,需要利用社团结构分析算法进行社团划分。目前,很多社团结构分析算法都只能将社会化标签网络划分为若干个相互独立的社团。显然,由于社会化标签的语义复杂性和资源的跨主题性,仅将一个社会化标签划分至一个社团是不符合实际情形的,而且也不利于提高用户兴趣模型的覆盖度。由此,本文将应用Derenyi等提出的派系过滤算法(Clique Percolation Method,CPM)进行社团结构分析。他们将社团定义为一些互相连通的“小的全耦合网络”的集合,这些“全耦合网络”称为“派系”,而k-派系则表示该全耦合网络的节点数目为k[ 6]。如果两个k-派系有k-1个公共节点,就称这两个k-派系相邻。如果一个k-派系可以通过若干个相邻的k-派系到达另一个k-派系,就称这两个k-派系彼此连通。有些节点可能是多个k-派系的节点,而它们所在的这些k-派系又并不相邻,那么这些节点就是不同k-派系社团之间的重叠节点。
(2)中心度分析
针对每个社团,需要利用社会网络分析中的中心度分析方法(如度指标、特征向量指标)寻找社团中的重要标签以建立社会化标签使用文档。中心度能够描述社会化标签网络中个体节点与周围其他节点之间的关系。虽然可以用于量化中心度的指标很多,但是对于社会化标签网络而言,比较有意义的指标主要有度指标和特征向量指标。假设社团对应的社会化标签网络的节点总数为g,则节点x的度指标值为Cd(x)=d(x)。其中,d(x)表示与节点x相连的节点数。同时,为了根据度指标来比较不同社团中的节点的中心性,可以对度指标进行归一化处理,即Cd(x)=d(x)/(g-1)。特征向量指标与社团对应的社会化标签网络的邻接矩阵密切相关。邻接矩阵能够描述社会化标签网络中各个节点之间的邻接关系,包含了网络的最基本拓扑性质。有g个节点的社会化标签网络的邻接矩阵A是一个g×g矩阵,aij=0表示节点i和节点j之间无连接,aij=1表示节点i和节点j之间相连[ 7]。λ为邻接矩阵A的主特征值,e=(e1,e2,…,eg)T为矩阵A对应于主特征值λ的特征向量。对应特征向量定义λX=AX,得到特征向量指标ei的定义公式如下[ 8]:
λei= 
ei=λ-1 
(3)用户局部兴趣视图生成
每一个用户局部兴趣视图代表了用户的一个细粒度兴趣,它由表示同一主题的社会化标签使用文档和用户层次社会化标签网络匹配而得到。社会化标签使用文档的社会化标签向量TVt=(∂(t1),∂(t2),∂(t3),…,∂(tK))与用户社会化标签网络的社会化标签向量TVu=(∂′(t1),∂′(t2),∂′(t3),…,∂′(tK))的余弦相似度sim(TVt,TVu)记为[ 9]:
sim(TVt,TVu)=
 | (3) |
其中,K为社会化标签向量的长度。需特别指出的是K并不是网站全局的社会化标签向量空间长度,而是社会化标签使用文档与用户层次社会化标签网络的社会化标签并集向量的长度。
若社会化标签ti出现在社会化标签使用文档中,则∂(ti)=1,否则∂(ti)=0;同理,若社会化标签ti出现在用户层次社会化标签网络中,则∂′(ti)=1,否则∂′(ti)=0。设定sim(TVt,TVu)的最小阈值为β,当sim(TVt,TVu)≥β时,可以判定用户层次社会化网络与社会化标签使用文档属于同一主题,那么社会化标签使用文档中不属于用户层次社会化标签网络的社会化标签集合便构成用户局部兴趣视图,即针对用户不同兴趣主题的细粒度用户兴趣模型。
3 实验分析
3.1 实验数据
本实验依托于笔者前期研究开发的“基于Web2.0的虚拟学习社区平台”。该平台构建于Apache应用服务器、MySQL数据库服务器、PHP语言环境之中,内置基于社会化标签网络的用户兴趣建模系统,具有资源标注、社会化标签网络可视化、用户兴趣建模等功能。本次实验过程中共组织了55名本科生作为系统用户,分享了经济与管理、计算机、信息传播、英语、考试、文学与小说6大类的734本图书信息。同时,模拟真实虚拟学习社区环境中的资源标注场景,每人至少对50本图书进行标注,每本图书的社会化标签数量在三个左右,从而共形成6 894条接近真实应用场景的标注数据,存储于MySQL数据库中。
3.2 实验过程
由于实验过程对计算能力的要求并不太高,因此本实验在个人电脑上即能完成。实验过程中借助了多种成熟的第三方软件,将在实验过程中对这些软件所起到的作用进行描述。根据本文所提出的方法,基于社会化标签网络的细粒度用户兴趣模型构建过程共分为以下4个步骤:
(1)网站主题领域和社团结构划分
目的在于划分出多个网站主题领域,对每个主题领域进一步细分得到多个社团,并用标签进行表达。网站层次社会化标签之间的关系建立在标签共现的基础上,即两个社会化标签同时标注了同一资源,则两者之间搭建了关系。利用Navicat数据库客户端管理工具,从实验平台的数据库中查询得到社会化标签共现数据,并导出为Excel文件,分别用格式转换得到社会化标签矩阵关系文件和社会化标签共现关系文件。借助富客户端编程语言Flex的SpringGraph网络拓扑结构可视化组件,将网站层次社会化标签之间的共现关系以可视化方式呈现,得到社会化标签网络。
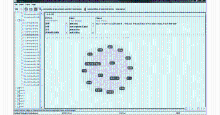
由于虚拟学习社区平台还处于初始运行阶段,参加实验的用户大多为信息管理专业本科生,最终仅形成一个网站层次社会化标签网络,即一个主题领域。利用CFinder 2.0.1工具,对该主题领域进行社团结构分析。该工具能够实现派系过滤算法CPM,从而可以将该主题领域划分为多个社团。在使用该工具时,需要确定社团的成员数k。例如,当k=13时,每个社团应包括13个成员,而社团之间的成员可部分重叠。根据实验需求,本文选定k=16,共得到网站主题领域的22个社团,分别记为C16_1,C16_2,…,C16_22,每个社团中含有16个社会化标签。以社团C16_4为例,社团C16_4={多情剑客无情剑,感人,古龙,光明,豪情,黑暗,剑客,李慕白,李寻欢,淋漓江湖,奇幻,温和,武侠,小说,研究,言情},如图2所示。
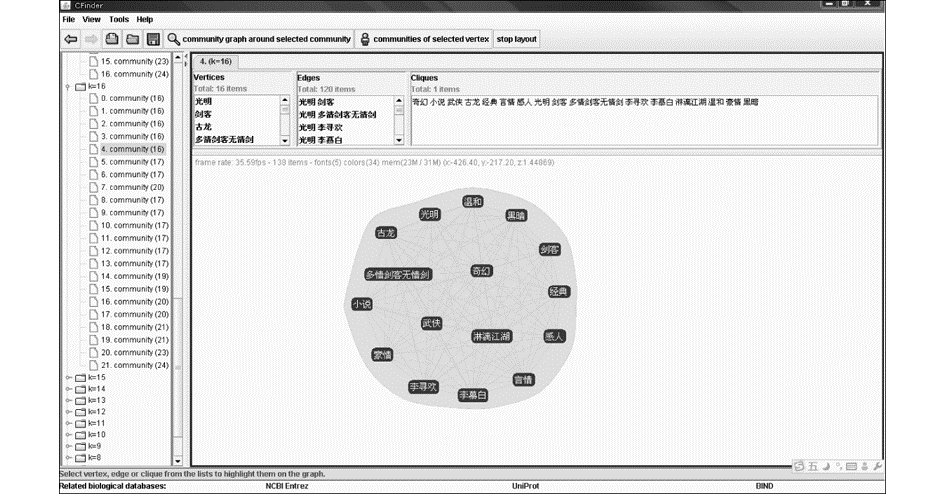 | 图2 主题领域的社团结构划分示例 |
(2)社会化标签使用文档的产生
利用UCINET 6.232社会网络分析软件的度指标和特征向量指标对每个社团结构进一步分析提炼,得到与社团对应的社会化标签使用文档。首先,对选取的社团运用度指标进行分析,挑选出度指标值较高的社会化标签,初步形成社会化标签使用文档。再运用特征向量指标进行分析,甄选出特征向量指标值较高的社会化标签对社会化标签使用文档进行补充,得到最终的社会化标签使用文档。以社团C16_4为例,分别进行度指标和特征向量指标分析后得到与之对应的社会化标签使用文档,记为CP16_4 ={多情剑客无情剑,感人,古龙,光明,豪情,黑暗,剑客,李慕白,李寻欢,淋漓江湖,奇幻,温和,武侠,小说,言情}。采用同样的方法计算其他21个社团的社会化标签使用文档。
(3)用户层次社会化标签网络的生成
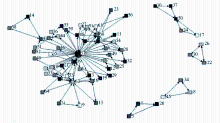
与网站层次标签网络相似,用户层次的社会化标签网络也是基于用户的社会化标签共现情况。同样,使用Navicat软件查询出单个用户的社会化标签共现数据,导出社会化标签矩阵文件。再利用UCINET 6.232社会网络分析软件对用户的社会化标签矩阵文件进行处理后得到用户层次的社会化标签网络。用户“46”的社会化标签网络如图3所示:
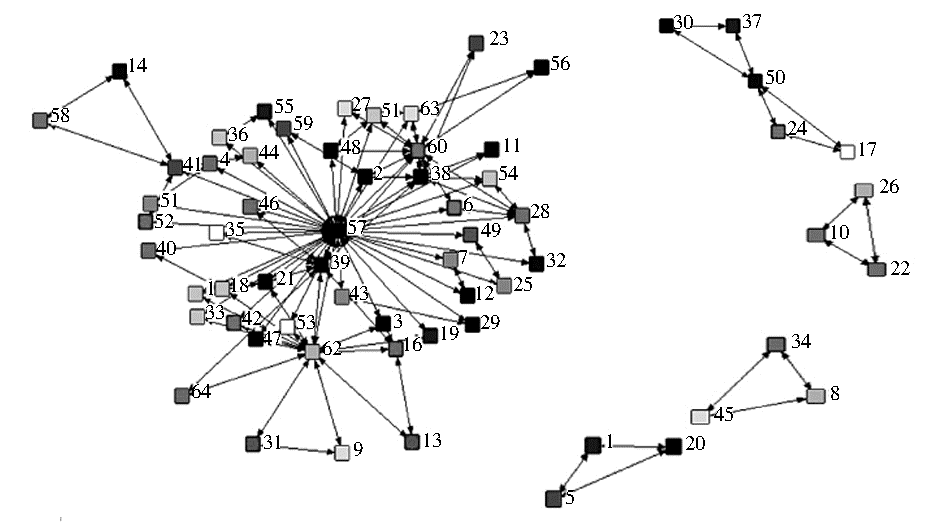 | 图3 用户“46”的社会化标签网络 |
从图3可以看出,用户“46”共有5个互不连通的社会化标签网络,分别标记为:I46_1、I46_2、I46_3、I46_4、I46_5,每个社会化标签网络对应用户“46”的一个细粒度兴趣领域。
(4)用户局部兴趣视图发现
将反映用户细粒度兴趣的用户层次社会化标签网络和反映网站细粒度兴趣领域的社会化标签使用文档进行匹配,提炼得到用户局部兴趣视图。具体计算方法如下:计算网站层次的社会化标签使用文档与用户层次的社会化标签网络的余弦相似度,找到与每一个用户社会化标签网络相似度最高的社会化标签使用文档;计算两者的社会化标签差集,即由社会化标签使用文档中不存在于用户社会化标签网络中的社会化标签所组成的集合,构成了用户局部兴趣视图。对用户“46”实施以上计算过程,最终得到5个用户局部兴趣视图:LI46_1={多情剑客无情剑,古龙,光明,李慕白,李寻欢,淋漓江湖…};LI46_2={GRE,出国,考研,英语,计算机,阅读理解,政治…};LI46_3={信息传播,网络营销,危机管理,突发事件,政府职能,信息采集…};LI46_4={经济改革,经济管理,企业管理,吴敬琏,林毅夫,经济管理出版社,WTO…};LI46_5={EXCEL,程序员,SPSS,MATLAB,ABAQUS,清华大学出版社,…}。
至此,构建完成了用户“46”的细粒度兴趣模型,它是用户局部兴趣视图的集合。从实验结果可以看出,本文所提出的方法能将用户兴趣分为多个主题领域,更为细致地表达了用户兴趣。
3.3 模型评价
由于细粒度用户兴趣模型是以社会化标签的形式表现,为了评价本文模型的优劣,需要首先将细粒度用户兴趣模型转换为对应个性化推荐资源集合,即:将细粒度用户兴趣模型与虚拟学习社区资源进行匹配。对于那些未被用户u标注的资源,如果其他用户标注该资源时选择的社会化标签都是来自于用户u的细粒度兴趣模型,那么就说明该资源与用户u的细粒度兴趣模型的匹配度较高。由此,可以得到细粒度用户兴趣模型与虚拟学习社区资源的匹配方法:细粒度用户兴趣模型的社会化标签向量与其他用户标注该资源的社会化标签集合向量的余弦相似度。通过计算即得到用户的个性化推荐资源列表,利用相应的评价指标对个性化推荐资源列表进行评价,得到对用户细粒度兴趣模型的评价。
在具体的评价环节,本文采用平均绝对误差MAE作为度量标准。MAE通过计算预测的用户评分与实际的用户评分之间的偏差来度量预测的准确性,因此在本文中该指标体现了基于用户细粒度兴趣模型的个性化推荐结果的准确度。假设在测试集中对X个项目预测的兴趣度向量表示为{p1,p2,…,pX},实际的用户评价值集合为{q1,q2,…,qX},则MAE的计算方法为[ 10]:
MAE=
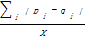 | (4) |
其中,|pi-qi|为pi和qi之间的绝对误差值,MAE值越小说明预测的质量越高。在本文实验过程中,需要分别将推荐资源在推荐列表和用户预测列表中的排序情况转换为系统评分值和用户评分值。系统评分值与用户评分值的评分标度如表1所示:
| 表1 评分标度表 |
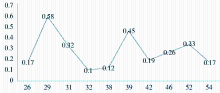
图4描述了随机选择的10位用户对应的MAE值变化。总体来看,本实验中所采用细粒度用户兴趣建模方法的准确度相对较高。除了用户“29”、“39”对应的MAE值超过0.4之外,其余用户对应的MAE值都在0.4以下,而且大部分都小于0.2。
 | 图4 随机选择的10位用户对应的MAE值分布 |
4 结 语
如果社会化标签不能得到序化,以此为基础建立的用户兴趣模型必然存在诸多不足。本文构建的社会化标签网络有利于深入揭示社会化标签之间的内在关联,进而实现社会化标签的有序组织。综合利用社会化标签系统“涌现”的大众分类规则和社会化标签网络分析指标构建特定知识领域的社会化标签使用文档,以此为基础建立细粒度用户兴趣模型,具有一定的创新性。实验结果表明了本模型的科学性。然而,在真实系统中,社会化标签随意性较大、数据量也非常庞大。在应用本模型时,需适当借助文本预处理方法将原始社会化标签加工后作为本方法的输入数据,利用程序算法实现本方法的各个环节,并优化系统性能。同时,本文的研究属于静态研究,如何利用用户层次社会化标签网络的时间属性建立细粒度用户兴趣转移模型则是需要进一步探讨的重要问题。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|