面向查询扩展的特征词频繁项集挖掘算法*
引用本文
黄名选, 马瑞兴, 兰慧红. 面向查询扩展的特征词频繁项集挖掘算法* . 现代图书情报技术, 2011, 27(4): 48-51
Huang Mingxuan, Ma Ruixing, Lan Huihong. Query Expansion Oriented Algorithm of Feature-words Frequent Itemsets Mining. 现代图书情报技术, 2011, 27(4): 48-51
Permissions
Huang Mingxuan, Ma Ruixing, Lan Huihong. Query Expansion Oriented Algorithm of Feature-words Frequent Itemsets Mining. 现代图书情报技术, 2011, 27(4): 48-51
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
面向查询扩展的特征词频繁项集挖掘算法*
摘要
为了获取高质量的扩展词,提出一种面向查询扩展的基于文本数据库的特征词频繁项集挖掘算法。该算法采用支持度衡量特征词频繁项集,给出新的剪枝策略,并结合原始查询,挖掘同时含有查询词项和非查询词项的特征词频繁项集,以提高挖掘效率。实验表明,与传统的挖掘算法相比,本算法更有效、更合理。
关键词:
频繁项集; 挖掘; 支持度; 查询扩展
中图分类号:TP391
Query Expansion Oriented Algorithm of Feature-words Frequent Itemsets Mining
Abstract
In this paper, a novel algorithm is proposed to mine feature-words frequent itemsets in text database, in order to obtain high-quality expansion terms for query expansion. This algorithm uses the support to measure the frequent itemsets, and only to mine those frequent itemsets containing original query terms and non- query terms synchronously. It can tremendously enhance the mining efficiency. The experimental results demonstrate that the algorithm is more efficient and more feasible than traditional ones.
Keyword:
Frequent itemset; Mining; Support; Query expansion
1 引 言
频繁项集挖掘是数据挖掘中一个重要的研究课题,引起众多学者的关注和研究。频繁项集挖掘是关联规则挖掘的核心步骤,主要用来从大量的数据中发现和分析未知的、潜在的数据项集之间的某种本质的联系。其主要难点在于频繁项集的数量是随着项数呈指数增长,致使在理论上需要考虑的项集数目巨大。在频繁项集的挖掘算法中,最有影响力的是1994年Agrawal等提出的Apriori算法[ 1],以及2000年Han等提出的FP-Growth算法[ 2]。近年来,针对频繁项集的挖掘方法,众多专家学者以Apriori算法或者FP-Growth算法为基础,从不同的角度先后提出了多种挖掘算法[ 3, 4, 5, 6],取得了成果。例如,文献[5]对传统的Apriori算法进行了有效的改进,增加了一种新的剪枝策略,使挖掘效率大大提高;文献[6]提出了基于事务数据库标识列表的文档主题词频繁项集产生算法(即TidlistAprior算法),在信息检索领域具有较高的应用价值。
数据挖掘技术广泛应用于各个领域,最典型的应用领域是将数据挖掘技术应用于信息检索查询扩展,取得了较好的研究成果。近年来,不同的学者以各种方式在信息检索查询扩展中应用数据挖掘技术,归纳起来有以下三种:
(1)应用于搜索引擎查询日志挖掘中,即挖掘与原查询相关的规则,实现查询扩展[ 7];
(2)应用于全局分析的词间关联规则挖掘中,即对整个文档集进行词间关联规则挖掘,从规则库提取扩展词,实现查询扩展[ 8, 9];
(3)应用于局部分析的词间关联规则挖掘中,即对初检局部文档集进行词间关联规则挖掘,从中发现与原查询相关的扩展词,实现查询扩展[ 10, 11, 12]。
这些成果均取得了较好的应用效果。
上述这些研究中,其研究焦点都是从关联规则中获取扩展词,而关联规则挖掘要经过两个阶段,即首先挖掘所有的频繁项集,然后再由频繁项集产生关联规则。事实上,频繁项集模式中的各个项集之间会存在某种关联[ 1],表达了项集间的一些本质联系,因此,可以考虑直接将频繁项集作为扩展词的来源,这样会大大提高挖掘效率。为此,本文提出了一种面向查询扩展的基于文本数据库的特征词频繁项集挖掘算法,直接挖掘同时含有查询词项和非查询词项的频繁项集,大大地提高了挖掘效率。实验表明本文提出的挖掘算法有效,更适合信息检索查询扩展的要求。
2 面向查询扩展的特征词频繁项集挖掘算法
2.1 基本概念
设D={d1,d2,…,dn}是一个基于向量空间模型的文本数据库,dj (1≤j≤n)表示文本数据库D中的第j篇文档。每一个文档记录都是一些特征词项目的集合,即dj ={t1,t2,…,tm,…, tp}, tm(m=1, 2,…, p)称为特征词项目(Feature-words Item),简称为特征词项。令I={t1,t2,…,tk}表示D中全体特征词项目集合,则I的任何子集X称为D中的特征词项目集(Feature-words Itemsets),简称为项集X。根据文献[1]的理论知识,给出如下两个基本概念:
(1)特征词项集X的支持度:文本数据库D中包含特征词项集X的文档数称为特征词项集X的支持数,记为fwsupport_count(X),特征词项集X的支持度记为fwsupport(X),即:
fwsupport(X)=
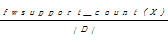 | (1) |
其中,|D|是文本数据库中的文档总数。
(2)特征词频繁项集:对于给定的最小支持度minfwsupport,若特征词项集X的fwsupport(X)≥minfwsupport,则称项集X为特征词频繁项集,它反映了特征词项之间存在某种关联。
2.2 特征词频繁项集挖掘算法的基本思想
面向查询扩展的特征词频繁项集挖掘算法的主要思想是从文本数据库中挖掘潜在的、有效的同时含有查询词项和非查询词项的特征词频繁项集模式,即首先由特征词候选1_项集C1根据给定的最小支持度阈值minfwsupport产生频繁1_项集L1,L1与自己连接生成候选2_项集C2,在C2中提取同时含有查询词项和非查询词项的特征词候选项集,计算其支持度,将支持度不小于最小支持度阈值的特征词候选项集添加到频繁2_项集L2中;由L2与自己连接生成候选3_项集C3,在C3中提取同时含有查询词项和非查询词项的特征词候选项集,再根据其支持度生成频繁3_项集L3,同理,可以生成频繁4_项集L4,频繁5_项集L5,……,频繁k_项集Lk,直到Lk是空集为止。
2.3 算法剪枝策略
面向查询扩展的频繁项集挖掘算法主要目标是从文本数据库中挖掘同时含有查询词项和非查询词项的频繁项集,以便获得与原查询词相关的高质量扩展词。为此,该算法的剪枝策略可以总结如下:
(1)剪去不含查询词项的候选项集;
(2)剪去只含查询词项,但不含非查询词项的候选项集;
(3)对于同时含有查询词项和非查询词项的候选项集,其剪枝按照是否大于等于最小支持度阈值进行。
2.4 面向查询扩展的特征词频繁项集模式挖掘算法
算法: Feature-Words Frequent Itemsets Mining for Query Expansion(即FWFIMforQE算法)
输入:原查询q的初检文本数据库Dq,最小支持度minfwsupport。
输出: 同时含有查询词项和非查询词项的特征词频繁项集(Frequent Itemsets, FI)。
算法描述如下:
Procedure FWFIMforQE (Dq, minfwsupport); //特征词频繁项集挖掘算法
Begin
(1)将FI清空
(2)Let C1=find_candidate_1-itemsets(Dq); //扫描文本数据库Dq,生成候选1-项集,并存入C1
(3)let L1=find_frequent_1-itemsets(C1, minfwsupport); //由C1生成频繁1-项集,并存入L1
(4)for (k=2; Lk-1不为空; k++)
Begin
① Ck=Candidate_Itemsets_Gen(Lk-1, k);//由Lk-1进行Apriori连接[ 1]生成Ck
② PruneIOfNotQItem (Ck, q); //剪去不含查询词项的、或者只含查询词项而不含非查询词项的候选项集
③ CIk =Extract_CandidateItemsetsContainingNon-QAndQ (Ck, q); //提取同时含有查询词项和非查询词项的特征词候选项集(CIk)
④Support =GetCandItemCount(CIk, k); //统计特征词候选项集CIk在Dq中的支持数,并计算其支持度Support
⑤Lk=GenLargeItem(CIk, k, minfwsupport); //生成频繁k_项集,并存入Lk
⑥ FI = FI∪ Lk; // Lk并入FI集合
End;
(5)Frequent_Itemset_Output(FI); //输出同时含有查询词项和非查询词项的频繁项集集合
End;
3 实验设计及其结果分析
3.1 实验设计
从网上下载了720篇有关计算机方面的论文作为特征词频繁项集挖掘的文档测试集。对原始测试文档集经过分词、去掉停用词等文档预处理,构建基于向量空间模型的文本数据库。实验过程中,首先采用基于向量空间模型检索算法对原始查询q在测试文档集中进行初检,对初检文档排降序,然后提取初检前列n篇文档作为针对原始查询q挖掘其频繁项集的局部文档集Dq,构建基于向量空间模型的局部文档数据库和局部文档集的总特征词库,按照特征词在局部文档集中出现的频次对总特征词库中的特征词降序排列,提取其前列50个作为挖掘频繁项集的特征词。实验实例是:原始查询q=知识发现,经过初检得到的局部文档集Dq为32篇。
3.2 实验结果及其分析
编写实验源程序,将本文FWFIMforQE算法与文献[1]的Apriori算法和文献[5]的改进Apriori算法进行比较,验证FWFIMforQE算法的有效性。三种算法分别对初检局部文档集Dq进行面向查询扩展的频繁项集挖掘,统计在给定的支持度下其候选项集、频繁项集的数量、挖掘时间以及从频繁项集中获取扩展词的时间。在最小支持度minfwsupport =0.5的条件下,三种算法挖掘结果如表1所示:
| 表1 三种算法挖掘结果比较(q=知识发现,minfwsupport =0.5) |
在不同的支持度下三种算法挖掘频繁项集的时间比较如表2所示:
| 表2 三种算法挖掘频繁项集的时间比较(单位:毫秒) |
从表1和表2可以看出,在面向查询扩展的频繁项集挖掘中,FWFIMforQE算法产生的候选项集、频繁项集数量以及挖掘时间比传统的Apriori算法明显减少,即候选项集减少了80.96%,频度项集减少了80.85%,而挖掘时间减少的幅度最大,达到了88.24%,本算法的挖掘时间比改进的Apriori算法减少了74.33%。其主要原因是:Apriori算法及其改进算法挖掘了全部的频繁项集,其中大部分的频繁项集对查询扩展没有实际意义,只有那些同时含有查询词项和非查询词项的频繁项集对查询扩展才有用,而FWFIMforQE算法为了避免产生无意义的频繁项集,从候选2_项集起只挖掘同时含有查询词项和非查询词项的频繁项集,因而采用了与Apriori算法及其改进算法不同的剪枝策略,过滤掉对查询扩展没有任何贡献的、无关的、大量的无效项集,即那些不含查询词项的项集,或者只含查询词项、不含非查询词项的项集,因而所挖掘的项集减少了80%以上,使得挖掘时间减少了88%以上,大大提高了挖掘效率。同时,表1还表明,传统的Apriori算法及其改进算法挖掘的候选项集和频繁项集数量一样,只是其改进算法在挖掘时间上比传统的算法减少了54.18%,表2的结果表明了这点,其主要原因是改进算法使用了新的剪枝方法[ 5],使得挖掘效率明显提高。
三种算法从频繁项集中获取扩展词的时间比较如表3所示:
| 表3 三种算法获取扩展词的时间比较(单位:毫秒) |
表3表明,FWFIMforQE算法从频繁项集中获取扩展词的时间比传统的Apriori算法及其改进算法明显少了很多,降低了84.21%,主要原因是本算法挖掘出的频繁项集比传统的Apriori算法及其改进算法挖掘出的少,因而处理的时间就少。
综上所述,FWFIMforQE算法比传统的或改进的挖掘算法的挖掘效率高得多,这使得频繁项集挖掘技术在信息检索查询扩展领域的应用成为可能,因为用户对信息检索的期望是检索速度快而且准。
4 结 语
本文提出的面向查询扩展的基于文本数据库的特征词频繁项集挖掘算法(FWFIMforQE算法)采用支持度衡量特征词频繁项集,只挖掘同时含有查询词项和非查询词项的频繁项集,大大地提高了挖掘效率。与传统Apriori算法及其改进算法比较, FWFIMforQE算法更有效,挖掘效率更高,更适合信息检索查询扩展领域的需要。通过FWFIMforQE算法可以获得与原查询相关的高质量扩展词,该研究成果对信息检索查询扩展领域有着很好的学术价值和应用前景。下一步的工作是将该算法应用于信息检索查询扩展,研究基于频繁项集挖掘的信息检索查询扩展模型,并将所得检索模型应用于现有的Web信息检索系统,如搜索引擎,以提高信息检索性能。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|