搜索引擎日志挖掘领域的论文合著网络分析*
引用本文
王继民, 李雷明子, 张鹏. 搜索引擎日志挖掘领域的论文合著网络分析* . 现代图书情报技术, 2011, 27(4): 58-63
Wang Jimin, Lilei Mingzi, Zhang Peng. Co-authorship Network Analysis in the Research Field of Search Engine’s Log Mining. 现代图书情报技术, 2011, 27(4): 58-63
Permissions
Wang Jimin, Lilei Mingzi, Zhang Peng. Co-authorship Network Analysis in the Research Field of Search Engine’s Log Mining. 现代图书情报技术, 2011, 27(4): 58-63
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
搜索引擎日志挖掘领域的论文合著网络分析*
摘要
基于Web of SCI和EI数据库中所收录的有关搜索引擎日志挖掘领域的研究论文,构建作者合著网络,利用社会网络分析方法研究合著网络的中心性、小世界特性、连通性等基本特征,发现该领域中最核心的科研合作团队、研究人员及其研究内容等。
关键词:
搜索引擎; 日志挖掘; 社会网络分析; 合著网络
中图分类号:TP393
Co-authorship Network Analysis in the Research Field of Search Engine’s Log Mining
Abstract
Based on the papers indexed by Web of SCI and EI on the theme of search engine’s log mining, this paper constructs a co-author network of this field, and analyses the centrality, small world features, connectivity and other basic characteristics of this network. Furthermore, it also explores the core cooperative research teams, the team members and their research contents.
Keyword:
Search engine; Log mining; Social network analysis; Co-authorship network
1 引 言
搜索引擎系统的日志文件记录了用户与系统交互的所有信息。分析与挖掘系统的用户日志可以发现用户进行Web查询的特征与规律,进而改善搜索引擎的系统性能[ 1]。近10余年来有关搜索引擎日志挖掘的论文呈逐年增长的趋势,目前已成为Web使用挖掘的重要研究分支之一。
科研合作最显著的表现形式是科研人员之间合作发表论文,而对论文合著情况的研究是分析科研合作的一个重要切入点。合著论文总数是评价作者、地区或机构之间科研合作与学术交流水平的一个重要指标。一定时期内某领域作者合著论文的数量及合作状况,在一定程度上反映了这个领域科研合作与学术交流的发展速度和质量[ 2]。
以论文作者为节点,以两个作者共同发表论文为边,可以构建一个作者合著关系网络。利用社会网络分析方法对合著网络进行研究和分析,已成为国内外对此类网络进行研究的主流方法,目前已取得了许多研究成果[ 2, 3, 4, 5, 6, 7, 8, 9],如Newman曾对物理学、生物医学和计算机科学等自然科学领域的合著网络进行分析与对比,指出了不同学科之间合作的差异[ 3];Liu等对数字图书馆领域的合著网络进行了分析和研究,并借鉴网页排序的PageRank算法提出了作者排序的Author Rank方法[ 4];Erman等借助论文合著网络分析了电子政务研究领域里最活跃的作者[ 5];李亮等从中心性、凝聚子群和核心-边缘结构等三个角度,对我国情报学领域的合著现象进行分析[ 6]等。
为对搜索引擎日志挖掘这一新的研究领域的科研合作情况有一个较为概括和清晰的认识,进而了解该领域的主要科研团队、主要研究内容及其研究现状,本文利用社会网络分析方法对该领域的作者合著关系网络特征进行了研究和分析。
2 数据准备
2.1 数据来源
为确保所分析论文的权威性和代表性,本文选取Web of Science(包括SCI、SSCI、A&HC)和EI(The Engineering Index)作为论文检索数据库,检索范围为:主题(标题、摘要或者关键词)中同时包含“Search Engine”和“Log”的论文,并选择“所有年份”作为时间段进行检索,共获得1 036篇论文的题录信息,包括论文的题目、作者、作者单位、关键词、发表时间及类型(期刊论文、会议论文)等信息。本文认为:就“搜索引擎日志挖掘”这一特定研究领域而言,检索式的主题中同时包含“Search Engine”和“Log”的论文,基本可以确定是与该研究主题相关的论文。
2.2 数据预处理方法
进行有效的数据预处理可以提高挖掘模式的质量,降低挖掘所需要的时间。由Web of Science和EI这两个数据库所导出的题录信息存在数据格式的不一致性,而且部分数据不完整甚至存在噪音数据。在数据分析与模式挖掘之前,先进行了数据的预处理工作,主要包括:剔除不相关的论文、去除重复的论文、拆分同一篇论文中的多个关键词和多个作者、归并同一作者的不同表示等,具体如下:
(1)主题去重。由于大规模搜索引擎的使用和普及是在1995年之后才开始的,所以在此时间点之前发表的论文予以剔除。通过人工筛查,删除了几十篇与主题内容完全无关的论文。
(2)论文去重。选取“作者”、“期刊来源”、“文章标题”、“发表时间”、“关键词”作为分析数据项,着重检查了相同文献在不同数据库中出现的问题,包括标题大小写字母的不同、标点和空格间断的不同等问题,避免了同一论文的重复出现问题。
(3)作者归并。论文在被收录时,经常会出现同一作者的不同表示形式问题,如本文第一作者“王继民”在此数据集中就同时存在Wang Ji-min和Wang Jimin 两种形式,将来还有可能出现Wang J M等。笔者对论文中所出现的作者进行了简单的归并处理,具体过程是:由论文作者数据构建一个作者合著网络,计算各节点的度值,然后按降序进行排列,去掉度值较小的节点(如删除度值小于3的节点),再按字母序进行作者排序,人工判断连续的两个或多个作者是否为同一作者,构造映射规则库(如Wang Ji-min映射为Wang Jimin),在原数据集上进行作者姓名替换,即用一个统一的名称去表示同一个作者,然后重新构造作者合著网络。在处理数据时,笔者构建了近百条映射规则,很显然,这种做法并未合并度值较小的节点,这将对计算结果有微弱的影响。
在经过上述数据预处理后,得到符合“搜索引擎日志挖掘”研究的论文887篇,不同作者1 969个。以下将基于这一数据集进行研究。
2.3 基本统计结果
按时间顺序统计各年发表的论文总数,结果显示:论文数量呈逐年递增的趋势,近4年年均发文量150篇左右。887篇论文中会议论文和期刊论文的大致比例是2:1,其中,会议论文主要来自International World Wide Web Conferences (WWW)、ACM-SIGIR Conference、International Conference on Information and Knowledge Management、Conferences for IEEE Computer等。期刊论文则主要刊载于Lecture Notes in Computer Science、Journal of the American Society for Information Science and Technology、Information Processing and Management、Journal of Computational Information Systems等。这些会议和期刊主要是计算机、信息检索、人工智能和信息系统领域的核心会议和期刊。
总体来看,这些论文所涉及的内容既有关于搜索引擎日志挖掘的理论、技术、方法的研究,也有具体的实证研究。其中,已被分析的搜索引擎日志约有10余个,包括美国的Excite和AltaVista、智利的TodoCL、德国的Fireball、西班牙的BWIE、韩国的NAVER、中国的天网和搜狗、中国台湾地区的GAIS等。这些论文所使用的日志挖掘技术和方法主要包括:统计分析方法、建模分析与预测、序列模式发现、关联规则挖掘、聚类分析等;挖掘的具体内容包括:词项级、查询级和会话级的数据分析、用户结果页面的查看和点击URL的特征、用户查询行为的演化趋势、不同地域用户查询行为的比较,以及如何利用日志分析改进搜索引擎系统的性能等。
统计每一位作者的发文数量并进行排序,居前10位的作者如表1第2列所示。该领域的一些出色的研究人员都位列其中,包括:美国匹兹堡大学的Amada Spink和宾夕法尼亚州立大学的Bernard J. Jansen、微软亚洲研究院的Chen Zheng(陈正)和Ma Weiying(马维英)、智利大学的Ricardo Baeza-Yates、以及清华大学的Ma Shaoping(马少平)和Zhang Min(张敏)等。
| 表1 合著关系网络的中心性排序 |
3 合著网络的特征
一个具体的网络可抽象为一个加权图G=(V, E, W),其中V表示图中节点的集合、E表示图中边的集合且E中的每一条边都有V中的一对节点与之对应,W表示图中各边所对应的权值的集合。据此,可以使用图论和社会网络分析的理论、技术和方法对此网络进行定量的描述,主要有两个层面内容:
(1)网络中单个节点或边的性质,具体的量化指标包括节点的中心性、声望值等。
(2)网络的整体性质,具体的量化指标包括网络的密度、直径、连通集团的规模及其分布、核心边缘结构等。
目前,对社会网络进行自动分析的软件有很多,如Ucinet、Pajek等[ 10, 11]。本文主要使用Pajek计算作者合著关系网络的基本特征指标。
3.1 合著网络的构建
在经过数据处理后的887篇论文中,合著论文为775篇,占论文总数的87%,即该领域的作者合著率为87%,与一般工程技术领域的作者合著率接近,远高于国内数字图书馆领域的作者合著率(49.6%)[ 12]。
以论文中出现的1 969个不同作者为节点,以两个作者之间共同发表的论文为边,以两个作者合著论文的篇数为边的权值,构建一个加权的合著关系网络,该网络共有3 322条边。统计显示:该网络中度值为0的节点有67个,即该数据集中有67位作者的论文是由个人独立完成的。边的权值大于1的有352条,即有352对作者合作发表2篇及其以上的论文。网络密度为0.0017,这是一个较为稀疏的关系网络。借助Pajek分析显示:该网络存在很多切点(Cut Point)[ 10],即去除某点后,网络就划分为互不连通的两个部分。
3.2 合著网络的基本特征
对所构建的合著关系网络,主要从节点的中心性、小世界特性、连通分支的规模等方面研究该网络的基本特征。
(1)节点的中心性
在社会网络分析中,有三个主要的指标描述一个节点的中心性,即:点度中心度(Degree Centrality)、介数中心度(Between Centrality)和接近中心度(Closeness Centrality)。尽管这三个指标所强调的侧重点有所不同,但都是描述一个节点在网络中所处“中心”位置的情况[ 11, 13]。
网络中一个节点V的点度中心度是指与节点V相连接的边的数量;在合著网络中表现为与其合作发表论文的不同作者的数量。显然,节点V的度值越大就意味着这个节点在某种意义上越重要,它反映了节点的局部中心指数。网络中所有节点度的平均值称为网络的平均度。利用Pajek软件计算合著关系网络中各节点的度值[ 10],并按度值大小进行排序,列举度值最大的前10个科研人员,结果如表1的第4列所示。
一个节点V的介数中心度是指网络中所有两对节点之间的最短路径之中,经过V的数量与总的最短路径数量之比;它反映了节点V在多大程度上控制其他节点之间的交往,是一种“控制能力”指数。一个节点V的接近中心度是指V与网络中所有其他节点的最短距离之和,反映的是节点V不受网络中其他节点控制的测度[ 11]。利用Pajek计算合著关系网络中各节点的介数中心度和接近中心度,并按度值大小进行排序,列举度值最大的前10个科研人员,结果如表1的第6和8列所示。
对比分析表1中的三个中心性指标,发现:微软亚洲研究院的Chen Zheng(陈正)和Ma Weiying(马维英)出现在各列中,是上述三个中心性指标前10名排序的交集,也就是说,无论从哪个角度去看这两位研究人员都是整个合作网络的中心人物。就具体取值来看,陈正的局部中心性高于马维英,马维英的介数中心性和接近中心性高于陈正。局部和整体中心性处于第二档位的是智利的Ricardo Baeza-Yates和美国的Amanda Spink。
网络中各节点的点度中心度(或介数中心度、或接近中心度)的分布可用一个分布函数P(k)来描述,P(k)表示一个随机选定的节点的度值恰好为k的概率。大量实证研究表明,许多实际网络存在幂律(Power-law)形式的中心度分布,即P(k)~k-r,此类网络也称为无标度网络(Scale Free Networks)。无标度网络包括Internet网络、电影与电视剧演员合作网络、科学家合作网络、人类性关系网络、蛋白质互作用网络、语言学网络等[ 13]。这类网络的度分布均呈现无标度网络的特征,即大多数人物仅与少量的人相联系,而少数几个度值较大的人物与众多的人相联系。
网络中一个节点的发文量、点度中心度的大小、介数中心度的大小及接近中心度的大小之间可能存在某种相关性。计算两两之间的相关性,结果显示在p=0.01(双侧)上,任何两个变量之间均显著相关,具体数值如表2所示:
| 表2 发文量、三个中心性指标的相关性分析 |
表2显示:作者的发文量与合著人员的数量呈极强的相关关系,即多产作者通常有更多的合作者。而接近中心度与介数中心度的相关性相对较弱,相关系数仅为0.274。
(2)网络的连通分支
连通分支是指网络的一个子网,在这个子网内,任意两个节点之间都至少存在一条路径。一个网络可能存在多个相互独立的连通分支。实证研究表明,对于大量的Scale Free网络,连通分支的规模(即子网的大小)通常符合幂律分布[ 13]。
类似于其他学科的作者合著关系网络,本文所构建的搜索引擎日志挖掘领域的作者合著网络也由多个连通分支构成,其中,最大的连通分支包含398个节点,第二大连通分支仅包含15个节点,随后节点的规模递减较快,约有115个连通分支只含有两个节点;除孤立点外,该网络包含近400个连通分支。
Nascimento等的研究显示,SIGMOD的合著关系网络中有近60%的节点被包含在一个连通分支中[ 7];Liu等所构建的数字图书馆领域的合著网络最大连通分支包含38%的节点[ 4]。而本文构建的作者合著网络的最大连通分支只包含节点20.2%,是一个比较低的数值,这表明在该领域内大规模的科研合作尚未开始,仍处于学科发展的初级阶段。某些小的连通分支结合紧密,如第二大连通分支是由清华大学马少平领导的科研团队,有15名成员,发表论文20余篇,自成一个小的连通分支,不与外界相连。
3.3 小世界网络的特征
在朋友关系网络中,一个人的两个朋友很可能彼此也是朋友,这种属性称为网络的聚类特性[ 13]。用数学化的语言表示为:对于某个节点i,它的聚类系数Ci被定义为与它所有相邻节点之间相连边的数目占可能的最大连边数目的比例。设节点i有ki条边与之相连(即节点i有ki个邻居),显然这ki个节点最多有 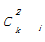
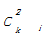
网络中两个节点Vi,Vj之间的最短路径定义为所有连通(Vi,Vj)的通路中, 所经过的其他节点最少的一条或几条路径。两个节点Vi,Vj之间的距离dij定义为Vi,Vj之间最短路径上边的个数。网络的直径(Diameter)定义为网络中任意两个节点之间距离的最大值。网络的平均路径长度定义为网络中任意两个节点之间距离的平均值;这是度量网络特征的一个重要的全局几何量。
对一个连通网络而言,如果它具有大的聚类系数和小的平均路径长度,则称该网络具有小世界网络的特征。笔者将合著关系网络中的最大连通子图(节点398个,边1 155条)取出,使用Pajek计算,结果显示其子网络的聚类系数为0.79,平均最短路径长度为7.9,网络的直径为18。而相同节点数(398个节点)与平均度(网络的平均度为5.8)的随机网络[ 13]的聚类系数为0.013,平均最短路径长度为3.7,这表明:搜索引擎日志挖掘领域的作者合著关系网络具有小世界网络的特征,具体如表3所示:
| 表3 合著关系网络与随机网络的平均路径长度和聚类系数的比较 |
国际数字图书馆领域合著网络[ 4]的聚类系数为0.89,最短平均路径长度为6.58; SIGMOD的合著关系网络[ 8]的聚类系数为0.69,最短平均路径长度为5.65; Newman所构建的不同学科合著关系网络[ 3]中,最大的聚类系数也只有0.72。本文所构建的合著关系网络的聚类系数数值较高可以揭示:在搜索引擎日志挖掘领域,一个科研人员的合作者之间更有可能进行新的科研合作;较大的平均最短路径则揭示:不同的研究小组(或称科研团队)之间的交流并不多。
4 主要凝聚子群
在合著关系网络的最大连通子图中,若删除节点度为1的作者,则该网络迅速划分为若干个子网络,其中有三个聚集性较大的连通分支(凝聚子群,即科研合作团队)较为突出。对这三个科研合作团队进行更为细致的分析如下:
网络中的第一大科研团队是以Chen Zheng(陈正)和Ma Weiying(马维英)为代表的微软亚洲研究院团队;第二大科研团队是以Ricardo Baeza-Yates为领军人物的智利大学研究团队(Baeza-Yates所写的《现代信息检索》一书是信息检索领域的经典教材);第三大科研团队是以美国匹兹堡大学Amada Spink和美国宾夕法尼亚州立大学的Bernard J. Jansen为代表的研究团队。
统计显示:这三个研究团队的发文量分别为152篇、81篇和70篇,占整体论文数量的1/3以上。对每个研究团队所发表论文的高频关键词进行统计,结果显示:排在前几位的高频关键词都是Search Engines、World Wide Web、Information Retrieval、Query Languages,可以称为该领域的标志性关键词。微软亚洲研究院所发表的论文中排序靠前的关键词还有Algorithms、Data Mining、Robot Learning、Mathematical Models、Database Systems等;智利大学的论文中排序靠前的关键词还有Websites、Behavioral Research、Computational Methods、Knowledge Management、Query Processing、Data Structures等;Spink与Jassen研究团队的论文排序靠前的关键词还有Online Searching、User Interfaces、Information Services、Problem Solving、Behavioral Research等。
根据研究团队的发文内容、词间的共现关系以及几个领军人物的网上介绍材料,初步揭示了这三个研究团队的基本特征,如表4所示:
| 表4 三个研究团队的主要特征 |
微软亚洲研究院的研究工作以人工智能、数据挖掘为主要切入点,可完全归结为计算机技术领域;智利大学的研究工作以检索技术为切入点,可归结为信息检索技术领域;而Spink与Jassen可以看作图书馆与情报学中的用户行为研究领域。三个研究团队的论文风格与学科方向密切相关,存在较大的差异。
5 结 语
本文针对搜索引擎日志挖掘这一研究领域,从Web of SCI和EI数据库中抽取相关研究论文的部分题录信息,构造了作者合著网络,研究了网络的基本属性特征,发现该领域中核心的研究人员与研究团队。本文的主要工作及其特点概括如下:
(1)在数据预处理阶段,本文采用的作者合并方法未见其他文献报道。该方法是一种“机器+人工”的处理方法,在总结完善后,将来有可能成为一种比较好的作者归并方法。
(2)搜索引擎日志挖掘领域的作者合著关系网络整体较为稀疏、小连通分支的内部联系紧密、具有小世界网络的特征。微软亚洲研究院的Chen Zheng(陈正)和Ma Weiying(马维英)处于整体网络的中心位置。
(3)该领域的研究论文呈逐年增长的态势,有三个研究团队表现较为突出,所发表的研究论文占论文总量的1/3以上,他们分别从计算机技术、信息检索技术、用户行为研究等三个不同的角度对日志数据进行挖掘,三者的研究方法存在一定的差异。
利用本文所构建的作者合著关系网络,还可以开展更深层次的研究工作,例如计算该网络各节点的Author Rank值,分析该网络的核心-边缘结构、研究该网络的生成机制等。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|