{kind=link}
Web数据关联创建策略研究*
引用本文
邓兰兰, 李春旺. Web数据关联创建策略研究* . 现代图书情报技术, 2011, 27(5): 1-6
Deng Lanlan, Li Chunwang. Study on Linkage Creation Strategies of Web Data. 现代图书情报技术, 2011, 27(5): 1-6
Permissions
Deng Lanlan, Li Chunwang. Study on Linkage Creation Strategies of Web Data. 现代图书情报技术, 2011, 27(5): 1-6
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
Web数据关联创建策略研究*
摘要
调研关联数据的关联关系创建算法和策略,分析同构模式下属性相似度和图形相似度算法以及相应的组合策略,对比研究异构模式下包含和不包含实例信息的架构映射方法,对可创建丰富语义关联的推导传递的思想进行剖析,并提出关联创建面临的挑战。
关键词:
关联数据; 语义网; 关联创建; 知识融合
中图分类号:TP393
Study on Linkage Creation Strategies of Web Data
Abstract
The linkage creation algorithms and strategies are surveyed. Based on some available work, properties similarity measurements, graph similarity measurements, as well as integrated similarity measurements to objects in homogeneous dataset are analyzed, and different schema mapping methodologies with/without instance information under heterogeneous data environment are compared. Afterwards, inferring and transfering approaches conducive to rich semantic link establishment are highlighted. Finally, challenges of linkage creation are proposed.
Keyword:
Linked data; Semantic Web; Linkage creation; Knowledge mashup
1 引 言
关联数据(Linked Data)最主要的特点是为不同数据集中的同一个实体对象建立关联关系(如owl:sameAs,rdfs:seeAlso),并支持利用这种关系实现对相关信息对象的发现、识别以及融汇服务的提供。因此,关联创建方法成为关联数据发布与应用的关键,相关研究受到关联开放数据(Linking Open Data, LOD)运动中各会议、团体、组织的高度关注。
目前,最简单的关联创建方法是唯一标识符法,即通过识别两个数据对象共用相同的唯一标识符,从而确定两个数据对象之间的同一性关系,如两个图书对象具有相同ISBN号,可判断它们是关于同一本图书的信息,进而建立二者之间的关联关系。但是现实中存在以下问题:共有相同唯一标识符的数据集非常少;而且通过唯一标识符建立的关联也很有限,而自由广泛的关联关系是关联数据得到良好应用的基础。因此,研究在没有唯一标识符的场景下创建关联关系的方法具有重要意义。本文将对同构数据源、异构数据源关联创建方法以及基于推导传递的关联创建方法等进行分析,以便为数字图书馆关联数据发布与应用提供借鉴。
2 同构模式下关联关系创建技术
同构模式是指需要创建关联的两个数据集采用相同的资源描述规范(Schema)。同构资源通过分析数据对象实例的属性值和语境相似度来发现并建立关联关系(以owl:sameAs为主),这种技术在数据库的去重(Duplication Detection)[ 1]和记录链接(Record Linkage)[ 2]等问题方面有应用,具体分单一方法和组合方法两种。
2.1 单一方法
单一方法是指通过计算关键属性或者邻近对象属性(即语境要素)的相似度来判断两个对象实例是否等同。
(1)属性值相似算法
属性相似算法要求选取的属性具有标识性,即选择关键属性作为计算的依据。目前,常用的属性相似度算法包括字符相似度算法、字符串相似度算法和基于字典相似度算法等。
①字符相似度算法:通过字符的插入、删除和替换等操作将字符串A转化为字符串B,然后利用操作的次数确定两个字符串的相似度,常用的方法[ 2]如下:
sim(s1,s2)=1-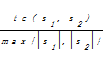
其中,tc(s1,s2)表示将s1变换为s2所需的操作次数,max{ 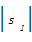
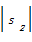
②字符串相似度算法:将字符串切分为词语Token,将两个字符串中共同出现Token占全部Token的比例作为字符串的相似度。该类算法的经典代表是Jaccard,利用字符串中的词语出现频次代表字符串的相似度。计算公式[ 9]如下:
sim(s1,s2)=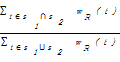
其中,t表示一个Token单元,wR(t)表示在数据集R环境下单元t的权重。如“Tim Berners-Lee”和“Berners-Lee, Tim 1955-”以空格和逗号为分隔符,权重统一为1,则相似度为0.67(2/3)。与字符相似度算法相比,该类方法将字符串拆分为Token,不考虑Token的顺序,克服了字符相似度算法中只能按顺序匹配的不足,但存在切分和权重分配的问题。常用的切分分隔符是空格,但在中文环境下需要专业的分词工具。而权重分配目前采用的主要是词频统计及相应的统计模型,虽然关联数据领域统计全局词频存在困难,但KnoFuss依然将之引入了其方法库,同时在数据集2000 U.S. Census in RDF (http://www.rdfabout.com/demo/census/)与GeoNames创建关联中使用了该方法。
③基于词典相似度算法:借助词典或者词表中的同义词、下义词,将字符串的语义距离作为字符串的相似度。通常是依赖WordNet等词典,计算两个字符串在词表构图中的最短路径。例如比较“New York”与“The Big Apple”借助于词典发现它们是指代美国城市纽约,而不再局限于语法层面的比较。该算法借助于语义词典使对象实例相似度计算更贴近现实,但是词典的选择是难点,词典的覆盖度直接影响该算法的应用范围。
在实际应用中,应结合具体场景调整属性相似度算法。如日期型或数值型属性在计算相似度时,属性完全相等的才是同一对象;而在计算不同属性之间相似度时,了解属性值构建规则十分重要,如RKBPlatform[ 10]采用这种方法实现属性Name与E-mail之间的相似度计算。
(2)图形相似度算法
用关键属性值代表对象实例计算相似度,算法简单,但忽视了邻近对象属性等相关语境信息,具有片面性。为弥补这一缺点,人们提出了对象属性的图形相似度算法,即利用RDF三元组(s,p,o)的图形化概念,限定对象实例s及其属性p构建子图,计算对象属性o的相似度,从而判断s是否等同[ 9]。
如书目数据集1中对象实例“Alexandre Dumas”,它的属性“dc:creator”连结作品“The Count of Monte Cristo”,在另一个数据集2中,可供匹配的对象实例有I1“Alexandre Dumas, père”和I2“Alexandre Dumas, fils”。此时,分析“dc:creator”属性连结的邻近对象的相似性,I1连结“The Count of Monte Cristo”,I2连结“Lady of the Camellias”。从而确定I1与“Alexandre Dumas”是等同关系。
图形相似度算法主要考虑的是对象属性的相似度,对相似度值要求极为严格,如DBTune中两部电影虽然名称相似度高,但其导演不同,则这两部电影必然不同,因此该类算法适用于从候选对象实例中挑出最适合结果。MOMA[ 11]框架通过作者与其他人之间的合著统计判断两个姓名描述的人是否为同一个人。Mi等[ 12]根据开放增长的数据环境对该算法进行改进,将每个对象实例表示为节点和关联语义的集合,通过计算集合的相似度得到对象实例的相似度,该算法思路来自Google的PageRank,通过多次迭代逼近两个对象实例的真实的相似度。
2.2 组合方法
属性值相似度算法与图形相似度算法各具特色,但单独使用时,或只考虑自身,或完全丢失自身信息,组合方法则可克服单一方法的武断和不确定性。组合方法就是综合多个属性和相邻对象的相似度,判断对象实例对是否对等。
(1)基本算法聚合
基本算法即单一方法中介绍的各类算法,聚合是指在计算得到多个相似度值之后,将其综合转化为对象实例间的相似度。
①单一属性,多种算法。该类方法选用多个算法计算关键属性值的相似度,得到的多个值采用平均计算或取众数的简单聚合运算得到最终的相似度。基于字符和基于字符串相似度算法在MOMA等多种方法体系中结合使用。如属性值“Chriz Biser”与“Bizer, Chris”,采用单一方法计算的相似度不超过0.5,则先通过字符串Token操作后,针对每个Token再进行字符“Chriz”与“Chris”和“Biser”与“Bizer”的比较,将得到的相似值平均作为对象实例的相似度。
②多个属性,适宜算法。选择对象实例的多个属性,针对每个属性选取合适算法,然后采用平均或加权平均等聚合算法计算得到相似度。该策略在城市资源融合中得到实现和应用[ 5],例如以城市的名称、在Wikipedia中的主页、人口和经纬度4个属性为代表,选取对应的字符相似度(jaroSimilarity)、集合最大相似度(maxSimilarityInSets)和数值相似度(numSimilarity)三种算法计算,但城市名和经纬度两个属性在聚合运算中权重大于人口属性,通过加权平均聚合运算得到相似度。
③属性值与图形相似度相结合。同时计算实例的对象属性和文本属性值的相似度,然后采用加权平均或优先的聚合算法得到标准化的相似度值。该算法在DBTune、BBC[ 13]等项目中应用,如对象实例“apple”通过名称属性比较得到候选对象实例“Apple Inc.”和“apple(fruit)”,同时采用图形相似度,分析“apple”的对象属性“product”指向“iPhone”,与“Apple Inc.”的相似度高,则优先考虑图形相似度的结果作为“apple”与“Apple Inc.”的相似度。
基本算法聚合可根据不同情况选择不同的聚合策略,除了文中提到的聚合算法,常用的还有取最大值法(Max)、取最小值法(Min)、欧几里德距离法(EUCLID)等。Silk工具在收录大量单一算法基础上提供多种组合策略以满足不同需求。
(2)分类模型
基本算法聚合策略适合较简单的属性、图形计算,且需要人工选择属性、算法并配置参数,但复杂属性下的关联创建则需要借用分类模型,即根据策略自动选择当前对象的值属性或对象属性构建特征模型,利用预先标注的关联对象实例训练并生成分类器模型,据此判断输入的对象实例对是否为等同关系。
在该方法中,作为特征的属性选择是关键。Sleeman等[ 14]在创建FOAF对象实例关联关系时即采用该算法。首先,通过统计等方法确定可以作为特征向量的属性,如foaf:name”、“foaf:mbox”、“foaf:msnChatID”、“foaf:knows”等;再根据提供的训练数据集抽取特征向量,构建分类模型的特征空间;基于该特征空间判定输入的实例对是否创建关联。为支持大数据量、复杂计算,Sleeman等选取支持向量机模型(SVM)并取得比较好的分类效果。
分类模型在信息检索等领域有广泛应用,在关联关系创建中引入该方法,可以在某种程度上解决基于少数属性简单判断而造成的不准确问题,可减少人工干预,提高自动化程度。但这类模型共同的特性是需要大量可靠的训练数据,同时,模型本身也存在各自的局限性,实际应用中要根据具体情况进行选择。
3 异构模式下关联关系创建技术
现实网络环境中,数据源更多采用不同的描述方案。在异构模式下,关联关系创建的基本策略是建立异构数据之间的架构(Schema)映射[ 15, 16, 17, 18, 19],然后运用同构方法创建对象实例间的关联。按照信息类型不同,架构映射分为包含对象实例和不包含对象实例两种。
3.1 不包含对象实例的架构映射
该方法只对架构文件进行分析,包括命名空间、元素定义和结构信息,按照映射的粒度分为元素映射和结构映射。
(1)元素映射
元素映射分析的主要对象是架构内容中的名称、描述和命名空间信息等,其中,实体元素还可考虑关键属性信息,属性元素还可考虑数据类型、取值范围等约束信息。
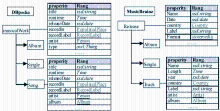
①语言相似度法,即采用文中提到的字符、字符串和基于字典等算法,计算名称、描述、命名空间和关键属性等信息的相似度。如图 1所示,DBpedia与MusicBrainz关于音乐数据的描述都重用了Music Ontology(http://musicontology.com/),“Album”和“Single”两个实体元素可直接映射;“musicalWork”与“Release”两个实体元素则依据WordNet词典建立映射;标题属性元素“Title”与“Name”、发布时间属性元素“ReleaseDate”与“Date”等根据其描述信息形成映射关系。Falcons-AO[ 20]利用该思想构建一个映射匹配器,BLOOMS[ 21]则依据Wikipedia分类表针对实体元素构建语义森林,再通过森林的相似度判断映射关系。
 | 图1 DBpedia与MusicBrainz架构 |
②约束相似度法,通过分析属性数据类型和取值范围等约束信息帮助判断映射关系。如依据W3C推荐的XML Schema数据类型结构(http://www.w3.org/TR/xmlschema-2/),分析“Date”与“gYear”、“gMonth”、“gDay”数据类型之间可能存在的映射关系;依据取值范围相似度分析两个属性元素可能存在的映射关系。由于约束信息设定因人而异,因此约束相似度算法一般不单独使用,仅为其他相似度算法提供候选的映射元素对时使用。
(2)结构映射
元素映射忽略了父类、子类或兄弟邻居等元素及其之间的相互关系,而RDF的架构文件也是一个RDF文件,因此,利用图形相似度算法综合考虑一组实体元素及关系信息,可提高元素映射的准确度,这便是结构映射法。图 1中,DBpedia的“musicalWork”通过“rdfs:subClassOf”链接元素有{Album, Single, Song},而MusicBrainz的“Release”链接元素有{Album, Single, Track}。经过元素映射法已为部分元素建立映射关系,根据图形相似度算法可确定元素“Song”与“Track”的映射关系。结构映射法在Falcons-AO、BLOOMS+[ 22]中得到充分利用。
3.2 包含对象实例架构映射
在分析架构信息同时,增加分析对象实例内容信息,有助于理解架构元素语义,从而提高映射的准确性。按照输入的信息分为对象实例属性值信息分析和对象实例对映射信息分析两种。
(1)对象实例的属性值信息分析
借助自然语言处理和信息检索等技术,统计每一对可能的映射元素对之间的对象实例属性值分布情况以及词频信息等,为元素映射提供语义支持。如“Artist”元素,在DBpedia和MusicBrainz的架构中都得到重用,但是根据二者提供的对象实例统计发现,DBpedia中“Artist”的值域远远大于MusicBrainz,从而否定二者之间的“owl:equivalentClass”关系。该类算法适合作为辅助信息过滤不存在映射的元素对,但对于数据实例较少的数据源判断时,容易出现误差,Autoplex[ 19]工具利用了该方法。
(2)对象实例对映射信息分析
针对两个数据集中对象实例间已有的关联关系,利用机器学习技术提出映射的可能元素对并验证。如DBpedia与MusicBrainz的owl:sameAs关联的对象实例集为“MusicalArtist”与“Artist”实体元素,而第三方BBC中“Artist”对象实例与两者有关联,桥梁作用增加了两个元素描述的对象实例关联数量,假设“MusicalArtist”与“Artist”存在映射,验证则是计算两元素描述的对象实例集合中等同关联的数量比例,计算公式[ 23]如下:
sim(A,B)=overlap(c(A),c(B))
= 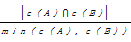
若上述不等式成立,则两个架构元素映射关系成立。该类方法利用已有关联或通过第三方可等价转换的对象实例对信息有助于理解架构,支持从语法和语义两个层面实现架构映射,但要求两个数据源中已存在部分关联的对象实例对,同时阈值的设定是关键。工具KnoFuss[ 24]实现了该方法,Par等[ 25]对地理数据本体建立映射时也采用了该方法。此外,利用神经网络等机器学习模型来实现架构映射,该过程与组合方法中的分类模型相似,这里不再详述。
4 基于推导传递的关联创建技术
同构和异构关联关系创建技术主要计算架构和描述信息重叠部分的相似度,适合创建等同关联,具有一定的局限性。针对缺少相同描述和邻近节点信息的两个对象实例,通过演绎推导或者利用第三方数据关联传递等方式实现关联关系的创建,即推导传递法。利用推导传递法可创建任何在RDF中出现的语义关联。
针对数据集A和B,对象实例I1和I′1已存在owl:sameAs关联,则推导规则[ 26]如下:
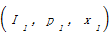
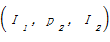
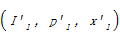
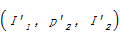
(1)若属性{p1,p′1}对等,则文本属性值x1和x′1相同;
(2)若属性{p2,p′2}对等,则属性对象I2和I′2可建立对等关系。
在知识融合领域,I1与I′2可直接通过p2创建关联。如在伦敦大本钟“Big Ben”与“Great Bell”之间已经存在owl:sameAs关联,其中“Big Ben”存在属性“geo:lat”和“geo:long”表示地理位置,同时通过“dc:creator”指向建筑的设计者“Charles Barry”;“Great Bell”也存在属性“geo:lat”和“geo:long”,通过“dc:contributor”指向建筑的设计者“Sir Charles Barry R.A., F.S.A.”。通过推导得到两个对象属性“geo:lat”和“geo:long”的值应相等,而邻近对象实例“Charles Barry”与“Sir Charles Barry R.A., F.S.A.”可建立“owl:sameAs”关联,“Big Ben”可以通过“dc:contributor”直接与“Sir Charles Barry R.A., F.S.A.”对象关联。
通过推导得到的关联类型可以是多种多样的。KnoFuss集成了推导传递算法,idMesh[ 27]则利用RDF Book Mashup数据集桥梁关系将可信度计算加入到第三方传递过程中。推导传递法的关键是借助对象实例间已经存在的直接或间接关联,目前,在关联数据空间中也出现一些中心数据集(Hub),如DBpedia、DBLP、RKB Explorer、ACM等[ 28],它们不但提供高质量的关联服务,而且为推导传递法提供了较好的第三方关联桥梁。
5 分析与建议
关联数据的快速增长与广泛应用凸显了关联关系创建的重要性,已经存在的关联创建算法和解决方案存在多方面的不足。其中,属性值相似度、图形相似度以及组合算法等主要适用于采取相同描述规范的资源对象;架构映射法虽然可以支持异构资源间的关联建立,但映射关系建立的自动化是难点;推导传递可以支持多类型关联创建, 但同样存在可信度偏低和前提条件(数据集间已有关联)限制等问题。
当前,关联创建算法研究至少面临两方面的挑战:
(1)随着数字图书馆等越来越多的领域都纷纷参加到关联数据发布与应用行列,如何开发适合复杂数据环境下的高效算法是关键;
(2)在快速变化的网络环境下,保证已经创建的关联关系持久有效是另一个亟待解决的问题。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|