
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于概念格的异构资源领域本体构建研究*
引用本文
滕广青, 毕强. 基于概念格的异构资源领域本体构建研究*. 现代图书情报技术, 2011, 27(5): 7-12
Teng Guangqing, Bi Qiang. A Study on Domain Ontology Construction from Heterogeneous Resources Based on Concept Lattice. 现代图书情报技术, 2011, 27(5): 7-12
Permissions
Teng Guangqing, Bi Qiang. A Study on Domain Ontology Construction from Heterogeneous Resources Based on Concept Lattice. 现代图书情报技术, 2011, 27(5): 7-12
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于概念格的异构资源领域本体构建研究*
摘要
在对本体构建研究路径进行分析的基础上,阐述以概念格构建异构资源领域本体的内在机理和技术路线。通过概念格的并叠置运算,获得基于主题词表和文本两大异构资源的概念格。进而以异构资源概念格构建异构资源领域本体,并对异构资源领域本体的构建进行讨论。为数字图书馆构建异构资源领域本体做出探索。
关键词:
概念格; 异构资源; 本体构建
中图分类号:G250
A Study on Domain Ontology Construction from Heterogeneous Resources Based on Concept Lattice
Abstract
Based on the analysis of the research paths of Ontology construction, this paper elaborates the internal mechanism and the technical route of domain Ontology construction from heterogeneous resources with the concept lattice. The concept lattice from heterogeneous resources based on thesaurus and text is acquired with apposition-overlap operation. Then the domain Ontology of heterogeneous resources is constructed with concept lattice of heterogeneous resources, and the construction of this domain Ontology is discussed. And the paper makes an exploring for construction of domain Ontology of heterogeneous resources in digital library.
Keyword:
Concept lattice; Heterogeneous resources; Ontology construction
1 引 言
本体(Ontology)作为语义Web的核心和骨干,能够帮助人们实现领域知识的共享以及软件系统与人工代理之间的知识交流和沟通。由于本体能够在语义和知识层面上以概念模型描述知识系统,使其成为下一代数字图书馆建设的主要建模工具。近年来,国际图书馆学界对本体的相关研究在知识组织、知识复用、知识检索等领域已取得了长足的发展。与此同时,由于在图书馆界内部,词表和文本两大知识资源具有显著的异构性,使得集成异构资源的领域本体构建成为当前数字图书馆亟待解决的问题。
本文以概念格理论为基础,对异构资源的领域本体构建进行了探索。在对当前学术界本体构建的研究路径进行分析的基础上,阐释了以概念格构建异构资源领域本体的内在机理和技术路线。并通过概念格并叠置运算构建了以主题词表和文本两种异构资源为基础的领域本体,对异构资源的领域本体构建进行了讨论。
2 领域本体构建研究的路径分析
自从Wille以形式概念分析(Formal Concept Analysis,FCA)重构了格理论(Lattice Theory),概念格(Concept Lattice)[ 1]就逐渐成为数据分析领域的有力工具。随着概念格在处理概念化知识方面的优势逐渐被人们所认识,越来越多的研究人员把概念格理论应用于本体构建的相关研究中。将概念格引入本体构建过程中可以解决早期本体构建方法中识别概念之间的关系困难、手工组织概念到本体费时费力和易受开发者的主观影响等问题。目前,以形式概念分析和基于形式概念分析的概念格相关理论与技术为基础的半自动化的本体构建方法主要包括:Obitko等[ 2]的方法、Haav[ 3]的方法、Cimiano等[ 4]的方法等。其中,Obitko等和Haav采用将概念格中的概念和本体的概念等同起来,由概念格直接构建本体;而Cimiano等则将本体中的概念和形式概念分析中的属性相匹配。随着概念格理论为代表的数据分析方法被引入本体构建,使得本体构建的相关研究产生了两条不同的研究路径:一条是以结构化资源为基础的本体构建研究路径;另一条是以非结构化资源为基础的本体构建研究路径。
在以结构化资源为基础的本体构建研究中,领域本体构建的基础资源主要包括:主题词表(叙词表)、分类法、现有本体、结构化词典、关系数据库等。此类研究中,主要以结构化资源自身的体系结构为研究起点,需要依赖领域专家从资源结构特征出发构建目标本体,其研究方法多属于有指导的本体学习构建方法。由于在本体构建研究中充分借助了现有资源的结构特征,使得本体构建效率得到一定提高,但仍然在很大程度上受到主观因素的制约。在以非结构化资源为基础的本体构建研究中,领域本体构建的基础资源主要包括:文本、网页、非结构化词典等。此类研究中,基础资源多被视为无结构或平面结构,研究人员往往采用形式概念分析等数据分析的手段,以无指导的机器学习方法从文本、网页等基础资源中提取资源特征。由于不同研究者所采用的具体分析方法不同,所构建的目标本体也存在一定差异。但是由计算机辅助的数据分析使得本体构建工程向自动化迈进,本体构建的效率得到很大提高,最重要的是此类研究中极大地降低了人为因素的影响。
近年来,国内外学者也曾试图对两种研究路径进行整合。国内学者的研究主要通过将主题词表用OWL直接转化为本体中的类,对文本资源进行切词分析的基础上构建基于文本资源的概念格,并直接将所得概念格与由主题词表转化而来的本体相结合构建目标本体[ 5]。此方法中,主题词表内在的人为因素仍然存在,且在解决“同构”问题上尚存缺陷。国外学者的研究则分别对结构化词典和文本资源构建概念格,通过概念格并置运算构建目标本体[ 6]。此方法通过概念格并置解决了“同构”问题,且减少了本体构建过程中的人为因素影响。本文将此两种本体构建方法进行整合,以图书馆内部两大主要资源——主题词表(结构化)和文本(非结构化)为主,采用形式概念分析的方法,在对主题词表进行形式化和对文本资源进行切词分析的基础上,通过概念格并叠置诱导出异构资源概念格,并以异构资源概念格构建目标领域本体。
3 基于概念格的异构资源本体构建思想
3.1 概念格构建本体的内在机理
由概念格构建领域本体的科学性和有效性主要源自于形式概念分析和概念格理论的两大支柱:形式背景和形式概念。
(1)由组成概念格的“序”可知,集合M上的二元关系R,对于所有x,y,z∈M都有[ 7]:
①自反性:xRx
②反对称性:xRy和x≠y⇒不是yRx
③传递性:xRy和yRz⇒xRz
如果x称为y的下近邻,即当x (2)传统的主题词表虽然经过领域专家的推敲和提炼,但是单纯以主题词表为基础构建的领域本体语义单薄,难以发现未知概念,在很多既往的基于主题词表的本体构建研究中不得不人为手动添加本体元素。若通过对文本切词获得基于文本资源的形式背景,且基于主题词表的形式背景K1=(G1,M1,I1)与基于文本资源的形式背景K2=(G2,M2,I2)满足G1⊆G,G2⊆G,M1⊆M,M2⊆M,则称K1和K2是同域形式背景,可以通过并叠置运算[ 8]诱导出同域的异构资源概念格,以此概念格构建领域本体可以提高目标本体的语义丰富度。 对于同域形式背景K1=(G1,M1,I1)和K2=(G2,M2,I2): ①当G1=G2时,K1和K2为相同对象域的形式背景。若M1⊆M,M2⊆M,M1≠M2,M1∩M2≠ϕ,则称K1和K2是内涵一致的,K1和K2的并置为(G,M1∪M2,I1∪I2)。 ②当M1=M2时,K1和K2为相同属性域的形式背景。若G1⊆G,G2⊆G,G1≠G2,G1∩G2≠ϕ,则称K1和K2是外延一致的,K1和K2的叠置为(G1∪G2,M,I1∪I2)。 ③当G1≠G2且M1≠M2时,若G1⊆G,G2⊆G,G1∩G2≠ϕ,M1⊆M,M2⊆M,M1∩M2≠ϕ,则形式背景K1=(G1,M1,I1)和K2=(G2,M2,I2)的并叠置为(G1∪G2,M1∪M2,I1∪I2)。
3.2 基于概念格的异构资源本体构建技术路线
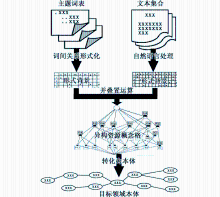
本文基于概念格的异构资源领域本体构建,主要以图书馆内部两大主要资源(主题词表和文本)为基础构建领域本体,从而弥补以单一资源构建领域本体的缺失和不足。由于主题词表和文本两大资源存在典型的异构性,因此,在研究中需要综合使用多种方法与技术互补融合。
(1)选取特定领域现有的传统主题词表,根据主题词表所特有的“属(S)”、“参(C)”、“分(F)”、“代(D)”、“族(Z)”等词间关系,对相关主题词进行形式化处理,构建基于主题词表的形式背景。
(2)选取相关领域的文本集合,并对集合中的文本进行自然语言处理(Natural Language Processing,NLP),提取可以作为形式对象和形式属性的核心词汇,进而构建基于文本的形式背景。
(3)将所获得的基于两种异构资源的形式背景进行并叠置运算,获得异构资源的概念格。
(4)将异构资源概念格转化为目标领域本体。
具体技术路线如图1所示。
 | 图1 基于概念格的异构资源领域本体构建技术路线 |
4 基于概念格的异构资源领域本体构建
4.1 异构资源的选择与形式化处理
本文以《交通汉语主题词表》(人民交通出版社,2007年版)为基础结构化资源,选择“车辆”词族中“汽车”下的“客车”主题词片段为例进行说明。截取的主题词及相关属性如表1所示:
| 表1 “客车”主题词片段 |
依照《交通汉语主题词表》,按照各种客车在主题词表中的词族关系及所属类别和子类进行形式化处理。以具体客车为形式对象,以所属类别为形式属性,得到的基于主题词表的形式背景如表2所示:
| 表2 基于主题词表的形式背景 |
在表2中第3行第3列的“1”表示“省际客车”具有“卧铺客车”的属性。
主题词表作为经过领域专家推敲和提炼后的一种分类工具,具有清晰、简洁、权威等特点,其相关内容的形式化过程也比较简单,容易实施。
研究中结合主题词表中相关主题词,选择了部分相关文本组成文本集合。由于文本自身的非结构化特征,使得针对文本内容进行的形式化首先需要进行自然语言处理。本文利用中国科学院计算技术研究所研制开发的汉语词法分析系统(ICTCLAS)2011版对相关文本进行切词处理。
经过切词后的文本内容还需要过滤停用词等处理,然后将切词结果进行叠加,并针对特定名词提取对象和属性进行形式化处理。研究中,基于文本资源获得的形式背景如表3所示:
| 表3 基于文本资源的形式背景 |
4.2 异构资源概念格的并叠置运算
现实图书馆中,主题词表与文本两大资源在资源的结构属性方面存在着巨大的差异,这正是数字图书馆领域本体构建研究中产生两条不同路径的主要原因。基于两种不同结构特征的资源(主题词表与文本)构建的概念格各有自己的优势和不足,单独以其中任何一种单一结构的知识资源为基础构建领域本体都是不完备的。因此,有必要在数字图书馆领域本体构建过程中对异构资源进行整合,构建基于异构资源的概念格。
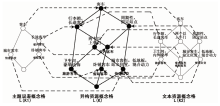
引例中主题词表概念格L(K1=(G1,M1,I1))和文本资源概念格L(K2=(G2,M2,I2))的并叠置为(G1∪G2,M1∪M2,I1∪I2)。由此,对基于主题词表的形式背景和基于文本资源的形式背景进行并叠置运算后获得的异构资源形式背景如表4所示。
由表4并叠置后的异构资源形式背景诱导出的异构资源概念格与主体词表概念格和文本资源概念格是“同构”的,其Hasse图如图2中异构资源概念格L(K)所示。
| 表4 并叠置后的异构资源形式背景 |
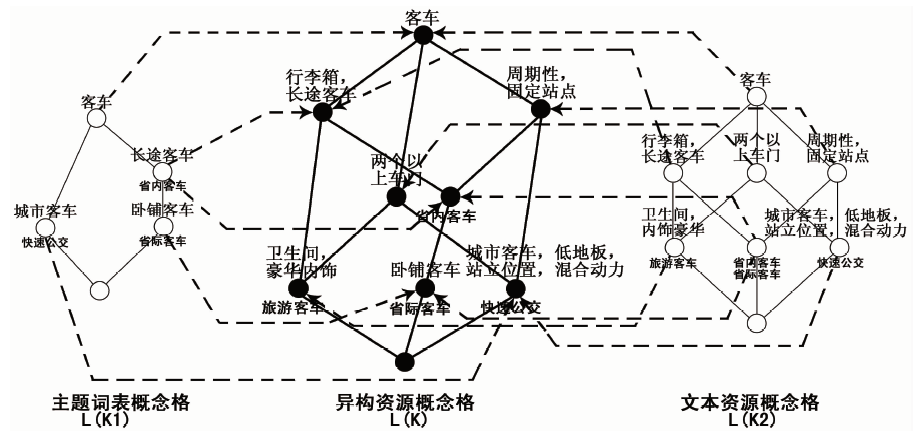 | 图2 并叠置运算获得的异构资源概念格 |
由图2可以看出,通过异构资源概念格的并叠置运算,主题词表概念格L(K1)中“{省内客车}{长途客\车}”概念节点的对象和属性在文本资源概念格L(K2)的作用下,在目标概念格L(K)中被分解在两个概念节点中;同时,文本资源概念格L(K2)中“{省内客车,省际客车}{}”概念节点在主题词表概念格L(K1)的作用下,在目标概念格L(K)中被分解为两个概念节点;此外,在文本资源概念格L(K2)的作用下,目标概念格L(K)比主题词表概念格L(K1)多产生了“{旅游客车}{卫生间,内饰豪华}”等概念节点。
由于作为目标概念格的异构资源概念格在概念节点与节点间关系等方面都得到了增加和强化,使得异构资源概念格比任意单一资源的主题词表概念格或文本资源概念格包含更丰富的语义信息。例如:原主题词表概念格中的概念“{快速公交}{客车,城市客车}”在异构资源概念格中被诠释为“{快速公交}{客车,两个以上车门,周期性,固定站点,城市客车,低地板,站立位置,混合动力}”,概念属性的增加使得概念的内涵被极大丰富。文本资源概念格中原有的概念“{省内客车,省际客车}{客车,行李箱,长途客车,周期性,固定站点}”在异构资源概念格中被诠释为“{省内客车}{客车,行李箱,长途客车,周期性,固定站点}”和“{省际客车}{客车,行李箱,长途客车,周期性,固定站点,卧铺客车}”两个带有偏序关系的概念,概念间隐含的关联关系被揭示出来。
4.3 基于概念格的目标本体构建
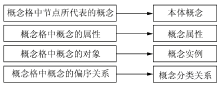
在由概念格向本体的转化过程中,首先删除异构资源概念格的底部节点,概念格中各节点所代表的概念直接等同于领域本体中的概念。需要说明的是,与文献[5]中映射规则的不同之处在于,本文中“概念节点”一词区别于“概念”一词,前者指的是概念格Hasse图中的某一节点,后者指该节点所代表的概念。具体映射规则如图3所示:
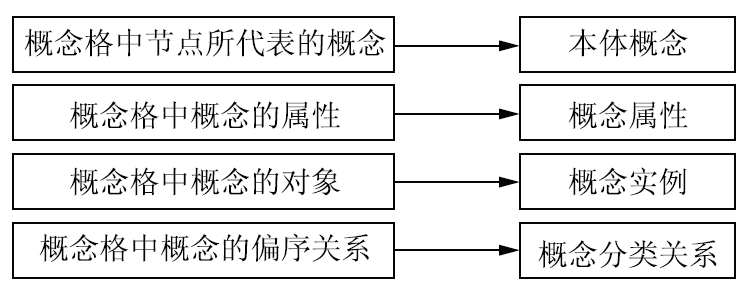 | 图3 概念格到本体的映射规则 |
依据以上规则,由异构资源概念格转化而得到的领域本体比建立在单一资源基础上的领域本体具有更加丰富的内涵,如图4中基于异构资源的领域本体。
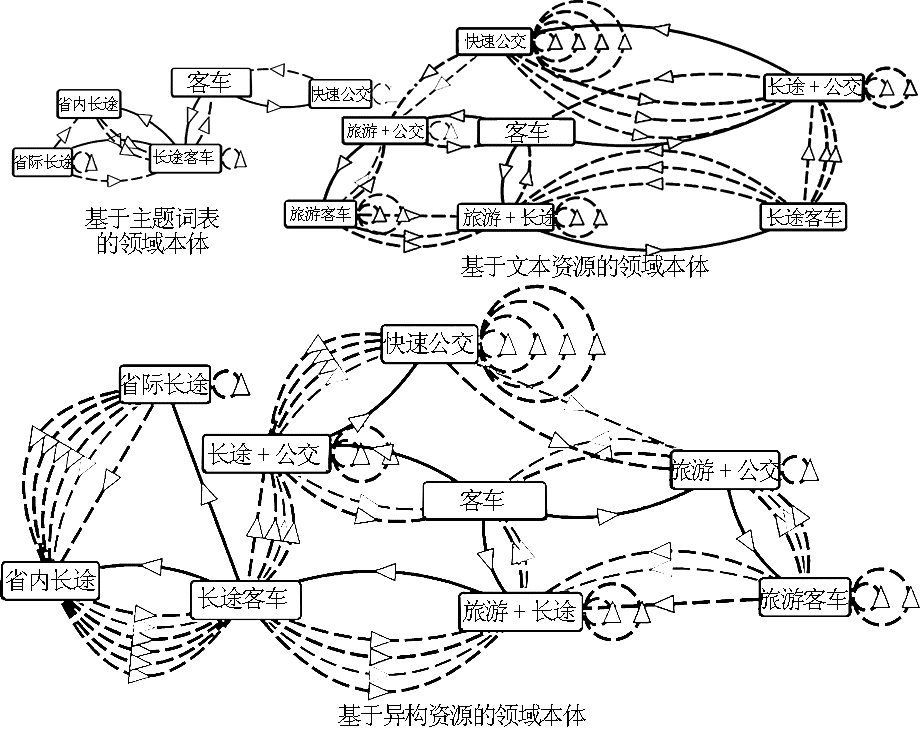 | 图4 单一资源领域本体与异构资源领域本体 |
由图4可以看出,由于在领域本体构建的过程中整合了不同结构的知识资源,使得基于概念格的异构资源领域本体无论在本体中的概念数量上,还是本体中概念间的层次与关联关系上,或者是在本体的语义丰富度等方面都远胜于单一资源的领域本体。
5 关于异构资源领域本体构建的讨论
(1)基于概念格的异构资源领域本体构建符合本体建模的生命周期。本体建模的生命周期一般划分为三个阶段[ 9]:概念化、模型化、实现。由于本体建模的起点是模型中涵盖的概念、实例、关系和公理等实体,因此,在本体的构建过程中需要对领域知识进行概念化描述,概念化是本体建模的第一步。近年来的ICFCA(International Conference on Formal Concept Analysis)国际会议中一直把概念化知识处理作为主要研究议题[ 10],建立在形式概念分析基础上的概念格理论与技术凭借其形式背景和形式概念在知识的概念化描述方面具有的得天独厚的优势,成为学术界公认的概念化知识处理的有力工具。同时,概念格中节点之间的偏序关系,体现了概念间的多重继承关系,在呈现概念间层级关系的同时,也揭示了概念间隐含的关联关系。概念关系的呈现与揭示通过Hasse图表现出来,构成了模型化环节的初始原型。而概念格中经过形式化处理的知识易于被计算机处理和加工,为实现本体建模创造了条件。
(2)基于概念格的异构资源领域本体构建是未来数字图书馆本体构建的必由之路。现实世界中的知识资源是多形式、多结构、多载体的,数字图书馆无论其馆藏资源是综合领域的还是专业领域的,其资源结构都不可能是绝对的单一结构。绝大多数图书馆中,都至少含有主题词表和文本两大异构资源。在这种情况下,单纯以某一单一结构的知识资源构建领域本体,即使借助大量领域专家的人工参与,也难以保证领域本体的科学性与完备性,从而难以实现图书馆知识组织的科学性和知识服务的高效性。综合学术界在单一结构知识资源领域本体构建中取得的经验,整合基于不同结构的知识资源的领域本体的优势,探索异构资源领域本体构建的思路和方法,必然是未来数字图书馆领域本体构建的必由之路。
(3)基于概念格的异构资源领域本体构建易于实现计算机自动化处理。利用现有资源构建领域本体,主要需要在三个环节上实现自动化:原始资源的预处理、概念格构建、本体构建。目前这三个环节都已经有比较成熟的工具软件问世。在资源预处理环节,中国科学院计算技术研究所研制开发的汉语词法分析系统(ICTCLAS)目前已发展到2011版,其主要功能包括中文分词、词性标注、命名实体识别、支持用户词典、支持繁体中文等,分词精度达98.45%。在概念格构建环节,ConExp和Lattice Miner等著名建格工具已经被学术界广为接受[ 11],并在诸多知识组织与管理领域的研究中成为研究概念化知识处理不可或缺的工具。在本体构建环节,Protégé[ 12]与KAON[ 13]等本体构建工具日臻成熟,并常被研究者用于构建实验本体。通过对现有工具软件包进行适当整合,有望实现本体构建过程的自动化。
6 结 语
本文基于概念格的异构资源领域本体构建研究,以概念格理论为基础,对以图书馆内两大主要异构资源(主体词表与文本)为基础的领域本体构建进行了探索。在对当前本体构建的研究中的两条主要路径进行分析的基础上,阐释了以概念格构建异构资源领域本体的内在机理和技术路线。同时,针对主题词表和文本两种异构资源,通过概念格的并叠置运算获得了异构资源的概念格,进而以异构资源概念格构建了异构资源领域本体。最后对异构资源领域本体的构建进行了讨论,为数字图书馆构建异构资源领域本体做出了探索。
现实中,数字图书馆的馆藏资源是千差万别的,通过构建数字图书馆异构资源的领域本体将图书馆资源进行整合,必将是数字图书馆领域本体构建的未来之路,也是数字图书馆知识组织与知识服务的保障。形式概念分析及概念格理论与技术,是当前对异构知识资源进行形式化和概念化处理的有效工具,也是半自动化乃至自动化本体构建的有力支撑。随着相关理论与技术的不断成熟,基于概念格的异构资源领域本体构建研究也将逐渐走向深入,并向具体的实践应用领域拓展。当然,数字图书馆领域本体构建是一个浩大的系统工程,相关的研究工作不可能一蹴而就。本研究中所使用的引例仅仅是在实验状态下的初步结论,未来数字图书馆异构资源领域本体构建的过程中还将面临很多具体问题,这些都有待于在下一步的工作中进行研究。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|