从客户评论中识别命名实体*——基于最大熵模型的实现
引用本文
余传明, 黄建秋, 郭飞. 从客户评论中识别命名实体*——基于最大熵模型的实现 . 现代图书情报技术, 2011, 27(5): 77-82
Yu Chuanming, Huang Jianqiu, Guo Fei. Recognizing Named Entity from Free-text Customer Reviews——A Maximum Entropy Model-based Approach. 现代图书情报技术, 2011, 27(5): 77-82
Permissions
Yu Chuanming, Huang Jianqiu, Guo Fei. Recognizing Named Entity from Free-text Customer Reviews——A Maximum Entropy Model-based Approach. 现代图书情报技术, 2011, 27(5): 77-82
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
从客户评论中识别命名实体*——基于最大熵模型的实现
摘要
介绍命名实体识别的基本概念,分析两种命名实体识别的基本方法:基于规则的命名实体识别方法和基于统计的命名实体识别方法,并以最大熵模型为理论基础,对中文菜名识别进行实证研究。根据中文命名实体的特点,设计6种特征模板。实验结果表明,在简单特征模板的基础上增加标注特征能有效提高命名实体的识别效果。对改进识别效果有用的特征依次为:标注特征、词性组合特征、后向词性依赖特征和词形特征。
关键词:
命名实体识别; 最大熵模型; 客户评论; 文本挖掘
中图分类号:TP391
Recognizing Named Entity from Free-text Customer Reviews——A Maximum Entropy Model-based Approach
Abstract
This paper introduces the concept of Named Entity Recognition (NER), analyzes two basic approaches, the rule-based approach and the statistical approach, and conducts an empirical study on Chinese dish name recognition based on the theory of Maximum Entropy Model (MEM). According to the characteristics of Chinese named entity, 6 feature templates are designed. Experimental results show that adding tagging features to the basic simple feature template can efficiently improve the performance of Named Entity Recognition. The features in order to improve recognition performance are as follow: tagging features, combination of POS features, forward POS dependency features and word form features.
Keyword:
Named entity recognition; Maximum entropy model; User reviews; Text mining
1 引 言
命名实体(Named Entity)这一术语最早出现在第6届消息理解大会(Message Understanding Conference, MUC)[ 1]上,将其简单定义为识别文本中的人名、组织机构名、地名以及时间表达式、数量、金额、百分比等。命名实体在数量上远远超过任何词类的词语数,因此对命名实体的理解是正确理解文本的基础。 命名实体识别(Named Entity Recognition)是指识别文本中的命名实体并判断其所属种类的过程。它通常包括两个过程:实体边界识别和确定实体类别(人名、地名、组织和机构等)。命名实体识别是信息提取(Information Extraction)[ 2]、问答系统(Question Answering)[ 3]、句法分析(Syntax Analysis)[ 4]、机器翻译(Machine Translation)[ 5]、面向语义网的元数据标注[ 6]等应用领域的重要基础工具,是自然语言处理(Natural Language Processing,NLP)[ 7]的基础环节,在自然语言处理技术走向实用化的过程中占据着重要地位。根据MUC会议的提议,命名实体识别的任务包括识别出待处理文本中三大类(实体类、时间类和数字类)和7小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
在英语中,命名实体具有比较明显的形式标志(即实体中的每个词的第一个字母要大写),因此实体边界的识别相对比较容易,命名实体识别的重点就是确定实体的类别。和英语相比,汉语命名实体识别任务更加复杂,因为相对于实体类别标注子任务,实体边界的识别更加困难。中文命名实体识别目前所遇到的困难在于命名实体和普通名词之间经常会出现重叠,从而产生歧义。例如成语“望子成龙”所包含的“成龙”有可能被识别为人名,而在命名实体“巴拿马总督米雷娅·莫斯科索”中所包含的“莫斯科”很可能被识别为地名。如何消除这种重叠所引起的歧义是一个非常有趣又较难解决的问题。由此出发,本文将以中文菜名为例,以验证中文命名实体识别中的歧义消除问题。选择中文菜名作为识别对象的原因在于:
(1)中文菜名种类繁多。中文菜名包括中式菜名和西式菜名,而中式菜名又涵盖各个菜系,每个菜系又包含不同的代表菜。因此该领域命名实体具有一定的规模。
(2)中文复合菜名的构成具有一定复杂度。由单个菜名所构成的复合式菜名往往包含多种形式。
①两种或两种以上单式菜名复合而成,如香菇菜心、章鱼小丸子和菠萝咕老肉;
②由其他名词和单式菜名复合而成,如澳洲大龙虾、非洲鲫鱼、东坡红烧肉和西湖醋鱼;
③由动词和单式菜名复合而成,如清蒸甲鱼、大煮干丝和水煮牛肉。
2 命名实体识别的相关研究
命名实体识别主要有两类方法:基于规则的方法和基于统计的方法。
基于规则的方法是要找到一套规则,根据该规则对文本进行处理,识别出文本中的命名实体,并将其归类。Farmakiotou等[ 8]使用基于规则的方法对金融文本中的命名实体进行识别,以一个人工获取的词典为基础,将命名实体识别分为预处理、实体边界识别和实体分类三步,系统最终识别出来的人名、地名和机构名的准确率分别达到了87.8%、83.6%和85.9%。由于其研究以预先选定的词典为基础,因此通用性较低。李楠等[ 9]以中文文本中化学物质命名为研究对象,建立适用于化学领域文献命名识别的启发式规则,为专业领域的命名实体识别提供一个较新的解决方案,对比实验证明该方法能从一定程度上提升专业命名识别的效率。基于规则的方法准确率较高,且比较接近于人类的思维,直观、自然,便于理解。但是基于规则的方法常常是依赖于具体的语料特征和文本格式而定的规则,普遍适用性较差,且编制过程费时费力,容易出错。
同基于规则的方法相比,基于统计的方法其健壮性和灵活性较强,其中,较具有代表性的方法包括决策树模型(Decision Tree)[ 10, 11]、隐马尔科夫模型(Hidden Markov Model, HMM)[ 12, 13]和最大熵模型(Maximum Entropy Model, MEM)[ 14, 15]等。本文选择其中较具有代表性的最大熵模型作为研究方法。选择最大熵模型的原因在于:
(1)与其他概率评价模型相比,最大熵模型所使用的特征类型更多,种类更齐全,形式更多样,所有对分析预测有用的信息都可以作为模型特征使用;
(2)最大熵模型只取观察到的已存在的事实,不作独立性假设,因此从理论上讲更为客观。
3 基于最大熵模型的命名实体识别
(1)命名实体识别问题
将待识别文本看成一个由输入词构成的序列,对这些输入词进行状态标注,通过状态序列即可识别出句子中的命名实体。为了实现这一点,通常定义以下状态标注集:Ω={B,I,O},其中B表示命名实体起始,I表示命名实体内部词,O表示命名实体外部词。因此,命名实体的识别问题可以转化为对输入文本序列的序列标注问题。
该问题可定义如下:
假定随机变量x = {x1,x2,…,xn}表示一个长度为n的输入词序列,y = {y1,y2,…,yn}(yi∈Ω)表示输入评论词序列x所对应的标注序列。命名实体识别问题,是指在输入序列x给定的情况下确定最有可能的标注序列y的过程。
(2)利用最大熵模型为命名识别问题建模
对输入序列x,从中提取出一些特征。对于每一个特征fi,其权重为wi,目标是为这个输入x选择一个类别。对于给定的观察对象x,每一个特定类别y的概率值可根据式(1)来计算[ 16]:
p(y|x)=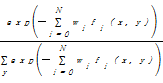 | (1) |
由式(1)可以看出,命名实体识别问题被转化成求解特征函数的权重值,这些权重值可通过数值计算方法求得,其中比较常用的是迭代缩放算法[ 17]。
4 实验设计
4.1 实验数据
本文采用大众点评网(http://www.dianping.com)上的评论语句作为原始语料,由人工标注而成。采用{B,I,O}标注集对语料进行标注,其中,B表示命名实体的开始,I表示命名实体的内部,O表示非命名实体。训练语料中,O并不标注出来,而只标注B和I,且B和I在分词词性后用“< >”加以标注。这样,在识别的时候,只需判断分词中是否含有“< >”即可。
程序输入文本是一个已经完成分词和{B,I,O}标注的句子,这些句子以序号开始,以中文结束标点结尾,即以词性标注“wj”结尾。生成训练语料库的第一步是扫描文件,并将文件中的数据以句子为单位分开处理,对句子的处理主要是将其分割成包含词性及其标注的分词,再将这些分词以特征模板需要的输入形式写入文件,即得到训练语料库。
实验数据的一条样例如下:
[800] 他们/rr 家/n 的/ude1烤/v 香肠/n 蛮/d 好吃/a 的/ude1 ,/wd 老/a 香/a 的/ude1 ,/wd 肉质/n 也/d 紧/a ,/wd 不过/c 也/d 是/vshi 太/d 咸/a 了/ule 点/qt。/wj
其中, “[800]”为序号, “/rr”、“/n”等为词性,标注为和的词构成命名实体。
4.2 构建特征
在最大熵模型中,特征是指从训练语料库中训练得来的语言知识规则。一条规则一般由两个部分组成[ 18],即条件和条件得到满足时所发生的动作。其形式如下:
信息一,信息二,…… —〉动作
若干信息构成条件。比如,在如果“当前词词性是名词,它左边第一个词的词性也是名词”,则“当前词标记为B(即命名实体的开始)”中,规则就由“如果……”和“则……”两部分组成,前者描述“条件”,后者描述“动作”。
例如,在句子“[800] 他们/rr 家/n 的/ude1烤/v 香肠/n 蛮/d 好吃/a 的/ude1 ,/wd 老/a 香/a 的/ude1 ,/wd 肉质/n 也/d 紧/a ,/wd 不过/c 也/d 是/vshi 太/d 咸/a 了/ule 点/qt。/wj”中,可以得到规则:
Pos(0)=v,Pos(-1)=ule,Word(0)=烤 —〉B
在上述规则中,0表示当前词,-1表示当前词左边一个词,Pos(0)表示当前词词性,Word(0)表示当前词词形。
上述规则表示:特征前提是当前词词性为名词(n)、当前词左边一个词的词性为助词(ule)、当前词词形是“烤”,该前提下的动作是“当前词的标注为B”。
4.3 设置特征模板
最大熵模型的特征是通过在语料库中匹配特征模板生成的。特征模板定义要考虑上下文信息,目前学者在进行相关研究时,往往通过设置特征种类和特征窗口来确定特征[ 18]。在设置特征种类时,通常将特征划分为原子特征和复合特征,原子特征往往是词形特征、词性特征和标注特征的混合,这较难从细粒度角度反映三种类型的特征对于改进命名实体识别的效果。在设置特征窗口时,通常是以一定大小的滑动窗口来获取特征,这种方法将前向特征(当前词词前的各种特征)和后向特征(当前词词后的各种特征)混合,因此也较难反映前向特征和后向特征对于改进命名实体识别效果的差异。
为了从细粒度角度研究各种特征对最大熵模型的影响,笔者对原子特征进一步细分为简单特征、词性依赖特征、词形依赖特征、标注依赖特征。在设置特征窗口时,对前向特征和后向特征进行了区分,默认情况为前向特征,对后向特征则加以标明。
使用当前词的词形、词性以及前两个词的词性作为简单特征,简单特征模板定义如表1所示。
| 表1 特征模板1(简单特征模板) |
为了验证当前词后的特征对于命名实体识别的效果影响(后向词性依赖),特征模板2在特征模板1的基础上增加了后向词性依赖特征,即将当前词右边一个词的词性与当前词右边第二个词的词性也作为特征,如表2所示:
| 表2 特征模板2 (简单特征模板+后向词性依赖) |
为了验证当前词的前若干个词的词形特征对于命名实体识别的效果影响(词形依赖),特征模板3在特征模板1的基础上增加了词形依赖特征,即将当前词左边第一个词的词形与当前词左边第二个词的词形也作为特征,如表3所示:
| 表3 特征模板3 (简单特征模板+词形依赖) |
为了验证当前词的前若干个词的标注结果对于命名实体识别的效果影响(标注依赖),特征模板4在特征模板1的基础上增加了标注依赖特征,即将当前词左边第一个词的标签与当前词左边第二个词的标签也作为特征,如表4所示:
| 表4 特征模板4 (简单特征模板+标注依赖) |
为了验证当前词的前若干个词的词性组合对于命名实体识别的效果影响(词性组合依赖),特征模板5在特征模板1的基础上增加了词性组合依赖特征,即将当前词左边两个词的词性与当前词的词性的组合标签也作为特征,如表5所示:
| 表5 特征模板5 (简单特征模板+词性组合依赖) |
为了验证各种特征组合对于命名实体识别的效果影响,特征模板6在特征模板1的基础上增加了标注依赖特征和词性组合依赖特征,即将当前词左边第一个词的标签、当前词左边第二个词的标签以及当前词左边两个词的词性与当前词的词性的组合标签也作为特征,如表6所示:
| 表6 特征模板6 (简单特征模板+标注依赖+词性组合依赖) |
4.4 特征生成
在训练语料库基础上,需要找到每个词的特征,因此对语料中的每个词进行遍历,循环匹配模板库中的每个模板,按照模板要求在所扫描的各个词的上下文取值,并按规定输出,即得到最大熵模型中各个词的特征。特征生成算法如下:
(1) 扫描语料库;
(2) 循环模板:
①利用当前模板开始匹配特征;
②将生成的新特征加入特征库;
(3) 重复步骤(1)和步骤(2),直到语料库扫描完毕。
4.5 训练与测试
笔者从语料库中随机抽出1 000条评论语句,其中800条评论语句作为训练语料,另外200条评论语句作为测试语料。为了检验最大熵模型的各种特征对于中文命名实体识别的效果,实验采用了4.3节所描述的6种特征模板进行6组训练和测试。第一组训练和测试使用词性和词形作为简单特征;第二组在简单特征模板的基础上增加了后向词性依赖特征;第三组在简单特征模板的基础上增加了词形依赖特征;第4组在简单特征模板的基础上增加了标注依赖特征;第5组在简单特征模板的基础上增加了词性组合依赖特征;第6组在简单特征模板的基础上同时增加标注依赖特征和词性组合依赖特征。
4.6 评价指标
为了衡量最大熵模型的识别效果,采用三个评测指标:准确率(P)、召回率(R)和综合指标F值(F)。计算公式分别为:
P= 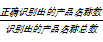
R= 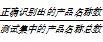
F= 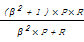
5 实验结果与讨论
利用6种特征模板分别进行命名实体识别测试的效果如表7所示:
| 表7 各种模板的命名实体识别效果比较 |
(1)对比各个模板的识别效果可以看出,模板4(在简单特征模板的基础上增加标注依赖特征)的效果(准确率71.85%、召回率57.74%和F值64.03%)和模板6(在简单特征模板的基础上既增加标注依赖特征又增加词性组合依赖特征)的效果(准确率71.16%、召回率56.55%和F值63.02%)明显好于使用模板1、模板2、模板3和模板5的效果。
(2)对比模板1、2和3的识别效果可以看出,简单特征模板(模板1)的效果好于在简单特征模板的基础上增加后向词性依赖特征(模板2)、词形依赖特征(模板3)。在简单特征的基础上增加后向词性依赖特征后,准确率、召回率和F值均下降了约5个百分点,其中准确率由60.22%降为54.64%,召回率由50%降为45.54%,F值由54.63%降为49.68%;在简单特征的基础上增加词形依赖特征后,准确率、召回率和F值均大幅下降近30个百分点,其中准确率由60.22%降为35.29%,召回率由50%降为21.43%,F值由54.63%为26.67%。这表明,在简单特征模板的基础上增加后向词性依赖特征和词形依赖特征并不能提高命名实体的识别效果,相反,由于词形依赖特征可能存在数据稀疏等问题,识别效果反而大大降低。
(3)对比模板1和5的识别效果可以看出,简单特征模板(模板1)的效果与在简单特征模板的基础上增加词性组合依赖特征(模板5)的效果相当。在简单特征的基础上增加词性组合依赖特征后,准确率、召回率和F值略有变动,其中准确率由60.22%降为59.79%,召回率由50%升为50.89%,F值由54.63%升为54.98%。这表明,在简单特征模板的基础上增加词性组合依赖特征后,对于改进命名实体识别的效果也并不明显。
(4)对比模板1和4的识别效果可以看出,在简单特征模板的基础上增加标注依赖特征(模板4)的效果明显好于简单特征模板(模板1)。在简单特征的基础上增加标注依赖特征后,准确率、召回率和F值均有明显提高,其中准确率由60.22%升为71.85%,召回率由50%升为57.74%,F值由54.63%升为64.03%。这表明,在简单特征模板的基础上增加标注依赖特征能有效提高命名实体的识别效果。
(5)对比模板4和6的识别效果可以看出,在简单特征模板的基础上增加标注依赖特征(模板4)的效果与在简单特征模板的基础上既增加标注依赖特征又增加词性组合依赖特征(模板6)的效果相当。在模板4的基础上增加词性组合依赖特征后,准确率、召回率和F值均略有下降,其中准确率由71.85%降为71.16%,召回率由57.74%降为56.55%,F值由64.03%降为63.02%。这表明,在模板4的基础上增加词性组合依赖特征后,对于改进命名实体识别并无显著效果。这与在简单特征模板(模板1)的基础上增加词性组合依赖特征(模板5)后对于改进命名实体识别的效果相似。
综上可以看出,在简单特征模板的基础上增加标注特征能有效提高命名实体的识别效果,而在简单特征模板的基础上增加其他特征似乎并不能有效提高识别效果,这与通常的看法(即增加特征通常能提高识别效果)并不一致。按照改进识别效果的大小对这些特征进行排序,其顺序依次为:标注特征、词性组合特征、后向词性依赖特征和词形特征。
目前,国内也有学者尝试利用最大熵模型进行命名实体识别。例如,曲晓棠等[ 18]以最大熵模型对于《人民日报》中的人名、地名、组织机构和专有名词进行了识别。由于《人民日报》语料的规范性要好于具有网络语言特征的在线评论,因此其识别效果好于本文中对于中文菜名的识别效果。但在其研究中,只是将特征分为简单特征和复合特征两种情况,因此较难从细粒度角度反映各种特征对于改进命名实体识别的效果。从这一点来看,本文的研究对于从细粒度角度改进命名实体识别的特征选择,具有一定借鉴意义。
6 结 语
本文通过实验,验证了利用最大熵模型使用各种特征模板对于命名实体识别的效果。实验结果表明,在简单特征模板的基础上增加标注特征能有效提高命名实体的识别效果,而在简单特征模板的基础上增加其他特征似乎并不能有效提高识别效果,这与传统的增加特征通常能提高识别效果的想法并不一致。
由于本文所选择的实验测试语料是己经正确分词并进行了词性标注的句库,因此其实验结果并不能完全代表系统实际使用时的性能。在后续研究中,会考虑将中文分词、词性标注和命名实体识别融合到一个系统框架中,避免底层错误向上层传播,从而进一步提高识别效率。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|