{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
人才网页自动识别系统研究*
引用本文
徐健, 温浩胜. 人才网页自动识别系统研究* . 现代图书情报技术, 2011, 27(6): 20-26
Xu Jian, Wen Haosheng. Study on Talents Description Web Page Automatic Recognition System. 现代图书情报技术, 2011, 27(6): 20-26
Permissions
Xu Jian, Wen Haosheng. Study on Talents Description Web Page Automatic Recognition System. 现代图书情报技术, 2011, 27(6): 20-26
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
人才网页自动识别系统研究*
摘要
提出人才网页自动识别系统设计,实现对Nutch定向采集系统抓取的高校网站页面进行人才描述网页自动识别。识别过程中使用自动获取的网页的URL特征、网页Title标签特征、链接文字特征以及网页文本内容特征,使用人名词表、正面特征词表、负面特征词表对各项识别特征进行匹配以计算特征值,借助开源软件LibSVM实现基于多特征值的人才网页自动识别。
关键词:
LibSVM; 人才网页; 自动分类; 分类特征提取
中图分类号:G250
Study on Talents Description Web Page Automatic Recognition System
Abstract
The paper brings forward a talents description Web page automatic recognition system, realizes automatic recognition methods of university talents description Web pages which are crawled by Nutch crawl system. During the automatic recognition process, features of Web page URL, title label content, anchor text content and Web page content are used.The value of those features are computed based on matching of name list, positive feature word list and negative feature word list. Based on multiple feature values, the system uses LibSVM to realize talents description Web page automatic recognition.
Keyword:
LibSVM; Talents description; Web page; Automatic classification; Classification feature extraction
1 引 言
随着海外高层次人才引进工作的不断深入,政府或高校在人才引进过程中所面临的一个实际问题迫切需要解决,那就是如何对海外人才质量进行核查和评估。目前海外人才的相关信息通常是由候选人单方面提供的,无论是候选人的确定、个人履历的真实性还是推荐人的权威性,都需要大量的工作来完成。如果能够通过持续对互联网中的各种人才描述信息进行获取并管理起来,形成海外人才数据库,那么对于政府或高校人才引进部门来说,都具有重大的决策信息参考价值。
针对上述问题,本文提出了人才网页自动识别系统设计。该系统是中山大学资讯管理学院网络人才信息发现系统的一个子系统。其作用是从互联网上定向采集知名高校网站页面,对其进行页面URL特征、网页Title标签特征、链接文字特征、网页文本内容特征的提取,并利用这些特征进行自动学习和分类,以获取专门用于描述人才相关信息的网页,为后续的基于自动包装器构造的网页信息抽取工作提供高质量语料。该识别系统在开源软件Nutch的基础上进行二次开发和集成,实现了高校网站定向采集和网页元数据、链接数据的提取,利用人名词表、正面关键词表、负面关键词表对各项识别特征进行计算,以获取更为客观的特征值,并使用开源软件LibSVM基于多种识别特征进行自动分类,达到人才描述网页自动识别的目的。
2 相关研究及技术
在文献调研过程中,笔者还未见到专门针对人才网页识别的报道。但是一些密切相关的研究具有重要借鉴意义。人才网页自动识别系统的核心问题可以看作一个网页自动分类问题。在人才网页多项特征值基础上,通过自动分类技术,将定向抓取的网页集合自动分类为需要保留的人才描述网页集合和需要剔除的其他网页集合,从而完成人才网页识别任务。
相关的代表性研究思路可归纳为:
(1)针对待分类网页本身内容特征的识别研究。从该角度进行的研究由来已久,所提出的特征包括:网页内容的长度、语句的平均长度、词语的平均长度、句法和词语难易度、内容语义、HTML标签特征、HTML结构特征、网页内容媒体类型和数量等。Eickhoff等在儿童适读网页识别任务中,针对儿童网页具有用词、句法结构简单等内容特征,对网页文本内容的长度、语词长度、超出儿童词表的词数比例等特征进行计算,并据此判断是否为儿童适读网页[ 1]。
(2)针对待分类网页环境所反映内容特征的识别研究。近年来也有一些学者认为尽管网页内容是重要的分类依据,但是内容结构复杂、噪音较多,难于实现高效率的自动分类。而一些网页环境信息,例如网页URL和指向网页的链接信息,既能提供简洁、高质量的内容描述,又方便进行获取,是比较理想的分类特征。Large等发现,网页URL和域名信息对于网页是否受到儿童用户的欢迎起到重要作用[ 2]。儿童不愿意记住这些长而复杂的URL,因此可以使用URL的长度和URL中与儿童相关的词语来确定网页是否适合儿童看。Hung等认为链接文字多为目标页面的内容概括或观点描述,因此可以被应用于自动摘要或文档分类任务中[ 3]。
(3)基于多种内容特征项的网页自动分类研究。受到描述片面性以及适用环境的限制,单独利用某种特征进行网页自动分类的方法往往不能取得理想的结果。研究者更多地使用基于多特征项的自动分类方法来克服单一特征的局限性。多特征项的常用集成方法有:线性加权方法、遗传算法以及SVM算法。吴思竹等在科研机构网页重要性排序任务中,将网络资源属性特征、网络资源所在位置特征和网络资源内容结构特征通过线性加权的方法进行集成,获得用于网页重要度排序的综合值[ 4]。Wen等在网页分类过程中使用了网页的Google目录服务分类结果、关键词标签内容以及网页内容特征构造自动分类特征指标,并通过线性加权的方法合并多项特征指标实现分类[ 5]。Ozel从网页的HTML代码中抽取< title >、 < h1 >、 < h2 >、 < h3 >、 < a >等标签中的特征词,使用遗传算法实现了基于多标签内容特征的网页自动分类[ 6]。许世明等使用SVM对网页内容中特征词构成的向量进行自动分类,实现了高校的中文网页分类[ 7]。
与上述相关研究相比,本研究的特色体现在:
(1)该系统充分利用开源软件Nutch对所抓取网页进行自动处理获得的Lucene索引、LinkDB数据库和Segments原文数据库,自动、高效地获得各项识别特征。
(2)将人名字典、正面关键词表、负面关键词表以及人名词表分别应用于各项网页识别指标获取过程,以获得更为客观的特征值。
(3)采用LibSVM高效集成各种识别特征,更加全面、客观地反映网页本质属性,减少网页噪音干扰。
此外,通过自动学习的方法解决了各项特征值在集成时权重难于确定的问题。
3 人才网页自动识别系统设计
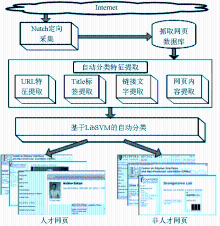
人才网页自动识别系统从互联网上定向采集知名高校网站页面,对其进行页面内容特征提取,并基于这些特征进行自动学习和分类,以识别专门用于描述人才相关信息的网页,为后续的基于自动包装器构造的网页信息抽取工作提供高质量语料。人才网页自动识别系统架构如图1所示。
从图1可以看到,人才网页自动识别系统主要由以下三个核心功能构成:
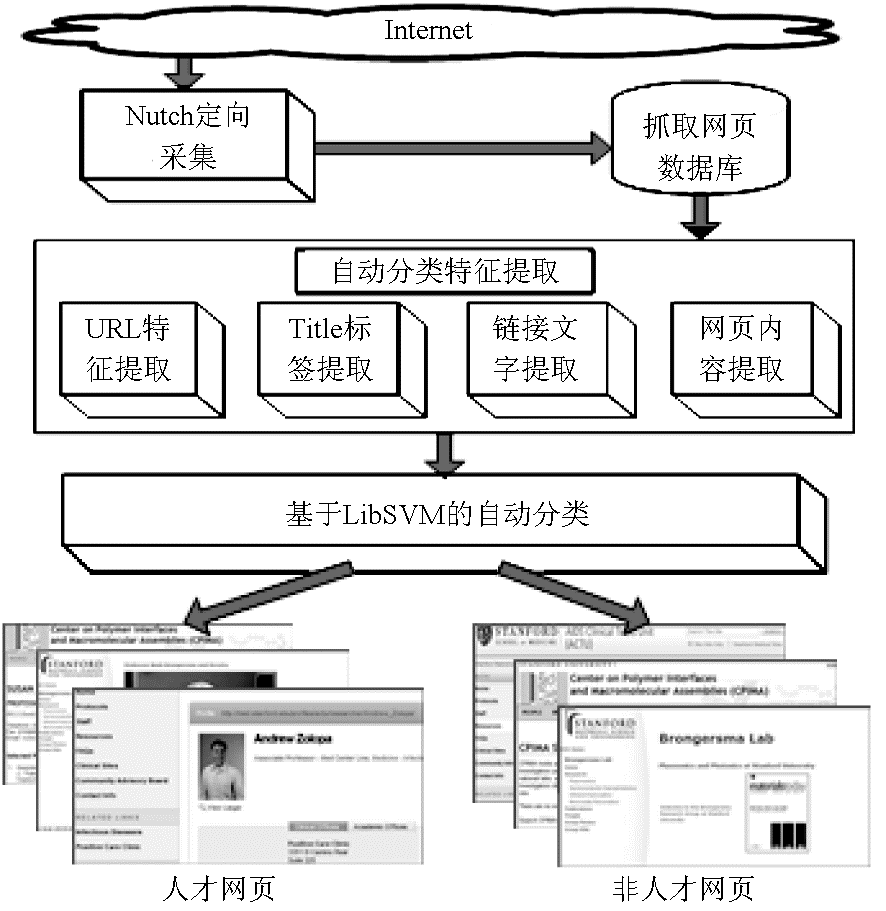 | 图1 人才网页自动识别系统架构 |
(1)基于Nutch的人才网页抓取。在Nutch基础上进行二次开发,对所指定的高校网站进行定向采集和自动分析,获取所抓取页面的源代码、页面链接分析信息以及页面描述元数据。
(2)人才网页特征识别。在获得Nutch抓取网页的URL、Title标签、链接文字以及页面内容后,根据人才网页特征词表计算这些特征项所体现的人才网页特征值。各特征项的特征值越高,则该网页越有可能为所需要的人才描述网页。
(3)基于SVM的人才网页自动分类。在LibSVM基础上进行二次开发,使用人才网页特征项构成的向量作为输入,对各个网页进行自动分类识别,获得高质量分类结果。
4 系统核心功能实现
4.1 基于Nutch的人才网页抓取
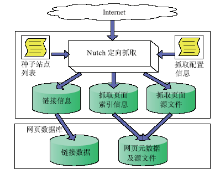
根据人才网页自动识别系统架构设计,需要首先将各目标高校网站上的网页抓取下来,以便为后续的自动分类特征提取提供语料。笔者在对Nutch[ 8]、Heritrix[ 9]、Web-Harvest[ 10]等开源网页抓取工具进行比较后发现,Nutch不仅提供了抓取网页的功能,还具有内容解析、链接解析、网页评分等功能,这为系统框架后续的网页内容分析等工作提供了更多便利。因此,本研究采用Nutch进行目标网站的抓取工作,其系统设计如图2所示。
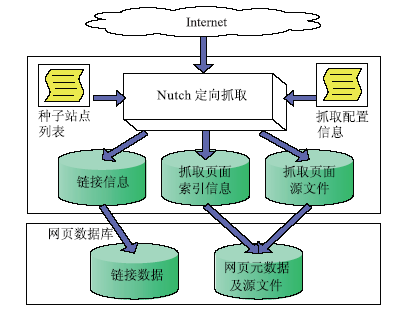 | 图2 基于Nutch的网页抓取子系统 |
在对Nutch定向采集系统的种子站点列表进行配置,并对抓取层数、抓取线程数等参数进行设定后,启动Nutch进行网站定向采集。 经采集和自动分析后获得的信息主要包括三个部分:
(1)链接信息,存储于Nutch的LinkDB中。
(2)抓取页面的索引信息,存储于Nutch的Lucene索引中。
(3)抓取页面源文件,存储于Nutch的Segments文件夹中。
为了更方便地使用这些数据,在对那些重复抓取页面和错误页面进行去重和过滤后,将抓取的信息导入自建的链接数据库和网页元数据及源文件数据库,为后续的自动分类特征提取功能提供输入。
4.2 人才网页识别特征
基于单一特征的人才网页识别指标往往具有片面性,难于对网页真实内容类型进行客观、真实的反映。例如,网页“http://cee.stanford.edu/faculty/faculty_dir.html”是美国斯坦福大学城市与环境工程系的教职工列表网页。仅从网页文本内容特征方面分析,由于其网页上含有类似“Baker, Jack”以及“Professor”这样的人名或头衔特征词,可能会被误分类为人才描述网页。如果能够结合该网页URL特征进行分析,就可以发现URL末段“faculty_dir.html”已经明确表达了该页面为一个人员列表网页而非人才描述网页。本文采用了4种网页特征作为人才网页的识别特征,力图避免基于单一识别特征所带来的局限性,使人才网页识别综合效率能够有所提升。
(1)URL特征
以英文为主的高校网站网页的地址URL对于网页内容具有较强的指示作用。若URL 中存在类似 “faculty”、“staff”的关键词,并且出现位置在网页地址以“/”作为分隔符分隔得到的最后一段URL文字中,则该网页通常为一个系或一个学院的人员列表页面。例如:
http://www.college.columbia.edu/facultyadmin/affairs/staff
当上述关键词不是出现在网页地址以“/”作为分隔符分隔得到的最后一段URL文字中,那么很可能该网页就是符合要求的个人介绍页面。如果URL的后部还包含人名或姓氏字符串,则该URL具有非常明显的人物介绍页面特征。例如:
http://www.college.columbia.edu/facultyadmin/yatrakis.php
URL特征分析过程为:
①对URL中的一些特殊字符进行处理和规范化。采用正则表达式方法,去除URL中多余的空格、“http://”等与操作无关的字符,为后续URL处理做好准备。
②取出URL的最后一段,进行姓名匹配。根据相关分析和网页数据统计结果,如果在当前网页的URL的最后一段出现名字,则当前网页很可能为个人介绍性网页。首先从URL中分离出最后一段字符串,然后将其与数据库中已经保存的名字姓氏表进行匹配,如果匹配成功则在URL特征指标项加入相应的权值。目前通过互联网共收集到16 581个姓名。
③对URL字符串进行关键词和禁用词匹配。将URL中经过分词得到的语词与数据库中的关键词表和禁用词表进行精确匹配,并根据匹配情况进行加权操作。若URL中出现特定关键词,则根据该关键词重要程度,在URL特征指标中加入相应权值。若URL中出现特定禁用词,则应在URL特征指标中减去相应权值。例如,判断URL字符串最后一段是否为“faculty”、“staff”等指示性关键词。若URL的最后一段出现上述关键词,则该网页很有可能为人才介绍页面上一层的列表页面。这类页面并不是本系统所需要的目标页面,因此对其在URL特征指标上应进行减权操作。上述过程中使用到的关键词和禁用词是通过对大量网页进行分析统计获取,共计70个词,部分关键词和禁用词及其权值如表1所示:
| 表1 部分URL特征关键词/禁用词及其权值 |
(2)网页Title标签特征
浏览器通常会把Title标签内容放置在浏览器窗口的标题栏或状态栏上。当用户把网页加入收藏夹时,Title标签内容也将成为该网页链接的默认名称。因此,网页发布者一般会将Title标签内容设置为对网页主要内容的概括性描述。而对于人才网页而言,通常会在其Title标签内容中出现姓名。本研究将网页Title标签内容作为判断人才网页的一项重要指标。处理步骤如下:
①对Title标签文本内容进行分词处理,获得单词集合。
②将获得的单词集合与已建立的姓氏或者姓名表进行匹配;若匹配成功,则在Title标签指标项上加入一定权值。
(3)链接文字特征
在基于Nutch的人才网页抓取系统抓取目标网站时,会对网页之间的链接关系进行自动分析,得到所抓取网页中每个链接的链接文字、链接目标URL等信息,形成Linklist数据库。可通过查询该库,获得指向某个目标URL的链接的文字描述信息。链接文字通常是对链接目标页面内容的概括性描述。在本研究中,那些链接文字中出现姓名等关键词的链接目标页面有可能为所需要的人才描述页面。处理步骤如下:
①在Linklist数据库中进行检索,找到目标页面对应的所有链接文字描述。
②对链接文字进行去重、去噪处理。
③对这些链接文字内容进行分词处理,获得单词集合。
④将获得的单词集合与已经建立的姓氏或者姓名表进行匹配;若匹配成功,则在链接文字指标项上加入一定权值。
(4)网页文本内容特征
尽管上述人才网页识别特征具有易于获取、处理量小等优势,但是在对大量网页进行观察后发现,这些指标有时也会失效。而网页文本内容本身是判断网页内容类型最直接和最根本的依据。通过大量网页观察发现,若在网页文本内容中同时出现类似“name”、“education”、“research interests”等词语,则该网页很有可能为所需要的人才网页。 网页文本内容特征值的获取可通过以下步骤进行:
①进行网页去噪,将网页的源代码中的HTML标签、脚本代码等与主要内容无关的部分过滤掉,并在去噪过程中对网页内出现的特殊格式(例如:加粗、斜体、下划线等)的文本进行标记,作为文本内容的重点处理对象。
②将网页文本内容与关键词表中的关键词进行匹配,如果网页内容中(特别是那些具有加粗、斜体、下划线等特殊格式)出现某个关键词,则加上相应的权值。
网页文本内容分析的关键是建立高质量的特征关键词表。本研究通过观察大量的人才网页,经过统计建立了特征关键词表,部分内容如表2所示:
| 表2 部分网页文本内容特征词及其权值 |
4.3 基于SVM的人才网页自动识别
由于SVM的应用逐渐引起越来越多的重视,以SVM应用为目的的开源软件也在不断涌现。目前比较知名的SVM开源软件有:MySVM[ 11],SVMLight[ 12]以及LibSVM[ 13]。其中尤以LibSVM开源软件最受欢迎。
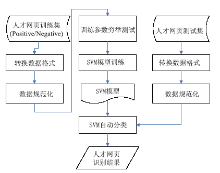
本文实验在LibSVM2.9开源软件的基础上进行了二次开发,实现了基于SVM的人才网页判断指标集成功能。基本流程如图3所示:
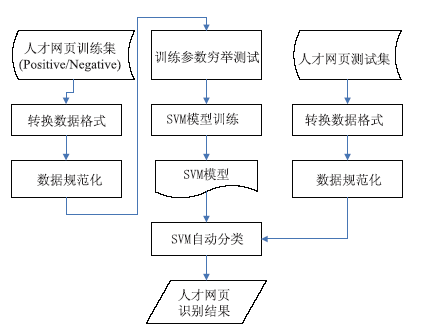 | 图3 基于SVM的人才网页自动识别流程 |
基本流程涉及以下5个步骤:
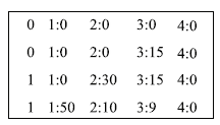
(1)将人才网页训练集转换为LibSVM的数据格式。经过转化后的训练集部分数据样例如图4所示:
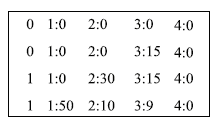 | 图4 训练集部分数据样例 |
在数据样例中,每一行代表一个网页的相应识别指标向量。向量的第1列为人工标引的网页识别结果,0表示该网页不是人才描述页面,1表示该网页为人才描述页面。第1列以后为向量中各分量序号及分量值,两者以冒号相间隔。对于待分类的测试数据,同样也需要进行数据格式转换操作。
(2)进行数据缩放规范化处理。为了尽可能减少部分向量分量变化范围大造成的对分类结果的干扰,使用数值范围[-1,+1]对训练集中所有向量分量进行规范化。
(3)进行训练参数的穷举测试。实验中采用的SVM核函数是RBF,该核函数比较适合维数不高、训练数据量不特别大的情况,因此对人才网页识别任务是适合的。为了训练出更好的SVM模型,还需要为SVM所使用的核函数提供合适的参数。这些参数通过穷举测试获取。本实验中采用LibSVM提供的grid.py工具测试获得最优参数设置。
(4)使用获取的最优参数进行模型训练。输入步骤(3)获得的最优参数,运行LibSVM中的训练工具生成用于人才网页识别的SVM模型文件。
(5)测试预测结果。在对测试集进行数据格式转换以及数据规范化操作后,使用步骤(4)获得的SVM模型对其进行自动分类,获得人才网页识别结果。
5 实验过程与结果
实验中对上述各项人才网页识别特征分别进行基于SVM的人才网页自动识别训练,以验证各项识别特征的有效性,并基于LibSVM对这些识别特征进行集成,验证集成效果与单个识别特征相比在分类效果上是否有显著提升。
实验过程中,借助基于Nutch的人才网页抓取子系统对世界排名前10的高校网站[ 14]进行了抓取,对已抓取网页进行去重和过滤等预处理操作后,共得到149 351个有效网页。在该网页集合基础上随机选取500个页面作为训练集,选取3 071个页面作为测试集,并对这些训练集和测试集页面的类型进行人工标引。测试集人工标引数据将用于验证人才网页自动识别系统的真实效果。实验在主频2.1GHz双核CPU、2.5GB内存、Windows XP操作系统、MyEclipse Java开发环境下进行。
对人才网页自动识别的效果评测采用准确率和召回率两个指标。本实验中的准确率和召回率指标沿用了维基百科中对于统计分类任务中准确率和召回率的定义[ 15]。
准确率计算公式为:
Precision= | (1) |
召回率计算公式为:
Recall=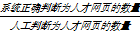 | (2) |
表3列出了基于各项网页识别特征单独进行人才网页自动识别的统计结果和采用多指标进行人才网页自动识别的统计结果,并据此计算出各次实验的准确率和召回率。
| 表3 单指标识别和多指标识别实验的准确率和召回率结果 |
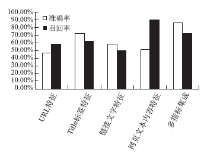
绘制各种单指标人才网页识别和多指标人才网页识别实验的准确率和召回率直方图,如图5所示:
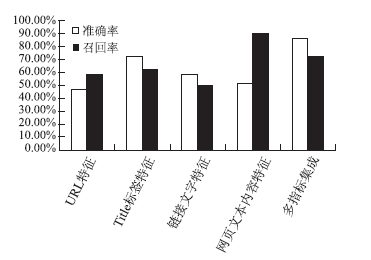 | 图5 单指标识别和多指标识别实验的准确率和召回率直方图 |
从图5可以直观地看到,将URL特征、网页Title标签特征、链接文字特征以及网页文本内容特征应用于人才网页识别任务时,都能达到一定的识别效果,但是距离一个实用系统水平还相差甚远。在这些特征中,网页文本内容特征单独作用时的效果相对较好,特别是其召回率达到了89.98%, 但在准确率方面得分相对较低,只能达到51.86%。这些特征被基于SVM的人才网页自动识别系统集成在一起,使原本只能反映网页局部特征的指标能够共同反映更为全面、综合的网页内容特征,人才网页识别的准确率和召回率都得到了较大提升。在采用多指标集成的人才网页识别实验中,准确率达到了85.94%,召回率也达到了72.18%。相比基于单指标的人才网页识别系统,综合识别系统的整体性能有明显提升。
6 结 语
针对当前基于网络的人才信息抓取和管理需要,本文设计了基于开源软件Nutch和LibSVM的人才网页自动识别系统。在人才网页识别过程中使用了自动获取的网页URL特征、网页Title标签特征、链接文字特征以及网页文本内容特征。通过对这些特征的有机集成,实现了对人才网页的高效自动识别。该系统充分利用开源软件Nutch对所抓取网页进行自动处理获得的Lucene索引、LinkDB数据库和Segments原文数据库,自动、高效地获得各项识别特征。此外,针对各种识别特征,分别构造适用的正面关键词表、负面关键词表以及人名列表,通过这些特征词表比对的方法,获得较为客观的各项特征值。最后,采用LibSVM高效集成各种识别特征,克服了每种识别特征在单独作为人才网页判断依据时的片面性,也通过自动学习的方法解决了各项特征值在集成时权重难于确定的问题。实验结果证明,人才网页自动识别系统是可行的,多指标集成识别结果较各种单项指标表现得更好。
在实现了人才网页自动识别后,下一步工作的重点是根据相似网页的结构来自动构造包装器,并自动提取其中的字段内容。这些字段内容将会被存入数据库以形成人才信息库,为人才引进相关部门提供决策支持。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|