



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
新一代数字图书馆应用支撑平台的研究与开发*
引用本文
张勇, 朝乐门, 邢春晓, 张铭, 王文清, 张健. 新一代数字图书馆应用支撑平台的研究与开发* . 现代图书情报技术, 2011, 27(6): 3-13
Zhang Yong, Chao Lemen, Xing Chunxiao, Zhang Ming, Wang Wenqing, Zhang Jian. R&D on the Supporting Platform for New Generation Digital Library Applications. 现代图书情报技术, 2011, 27(6): 3-13
Permissions
Zhang Yong, Chao Lemen, Xing Chunxiao, Zhang Ming, Wang Wenqing, Zhang Jian. R&D on the Supporting Platform for New Generation Digital Library Applications. 现代图书情报技术, 2011, 27(6): 3-13
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
新一代数字图书馆应用支撑平台的研究与开发*
摘要
采用文献研究、案例调研和需求分析方法,提炼出新一代数字图书馆应用支撑平台的主要特点。在此基础上,通过软件工程方法,借鉴相关领域的理论研究、最佳实践和标准规范,设计出新一代数字图书馆应用支撑平台的体系结构及其数据模型。利用课题组自己的专利、软件著作权和学术论文等成果,实现应用支撑平台——“爱迪智搜平台”。最后,介绍该平台在中国高等教育数字图书馆中的部署和应用情况,探讨平台设计的科学性和下一步工作重点。
关键词:
数字图书馆; 数据驱动; 跨域共享; 按需服务; 爱迪智搜
中图分类号:TP311
R&D on the Supporting Platform for New Generation Digital Library Applications
Abstract
The fundamental characteristics of the supporting platform for new generation digital libraries are proposed by conducting literary review, case study and requirement analysis. Then a novel framework for the supporting platform and its data model are designed in terms of theoretical studies, best practices and relevant standards. And the supporting platform named iDLib is implemented by employing several intellectual property rights owned by the authors. Finally, the new platform is deployed and tested on China Academic Library & Information System (CALIS) and its good performance proves the efficiency of the novel platform.
Keyword:
Digital library; Data driven; Cross domain sharing; On-demand services iDLib
1 引 言
当前数字图书馆系统模式存在复制传统图书馆功能、束缚信息资源系统和以图书馆为中心的局限,为其发展带来了危机[ 1]。数字图书馆应用创新是突破数字图书馆局限性的重要途径之一。但是,数字图书馆应用需要底层支撑平台为上层应用提供基础设施和通用服务。相对于数字图书馆应用,作为底层的支撑平台具有一定的通用性和稳定性,从根本上决定了数字图书馆应用的效果和效率。可见,数字图书馆应用的创新需要其底层支撑平台的创新。
本文介绍了863目标导向项目 “支持数据驱动型应用的跨域共享与服务支撑平台研发”的主要成果之一——“爱迪智搜平台”,汇聚了该课题组(简称“课题组”)全体成员的辛勤劳动。平台的设计和实现充分体现了新一代数字图书馆应用的发展趋势,在体系结构、数据模型、核心技术上均有较大突破,较好地支撑了数字图书馆应用的数据驱动、跨域共享、按需服务和大规模并发需求。在平台实现中,课题组还突破了7项核心技术,即基于中国数字对象标识器(China Digital Object Identifier,CDOI)的分布式唯一标识的目录交换技术、语义Web与Web2.0集成的知识处理模式、基于Chu空间的服务组合形式化建模与验证技术、基于社会化标签的协作过滤算法、多文档摘要和科技查新技术、基于图的个性化推荐算法、基于企业服务总线(Enterprise Service Bus, ESB)的大规模并发控制技术。目前,平台已经投入试用,并得到了图书馆用户的较高评价。
2 相关工作
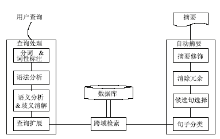
数字图书馆应用支撑平台能够提供数字图书馆建设所需的数字化专业平台和一系列功能模块,以实现数字图书馆的各项平台[ 2]。在国内,比较典型的数字图书馆应用支撑平台有同方TPI、拓尔思TRS、方正Apabi、麦达MDL等[ 3]。在国外,比较常用的数字图书馆平台有IBM数字图书馆平台[ 4]。此外,开源软件可以视为应用开发支撑平台的一种。文献[5]比较系统地研究了DSpace、Fedora、EPrints及Greenstone等数字图书馆开源软件。文献[6]总结归纳了数字图书馆平台的基本功能,认为数字图书馆应用支撑平台应具有创建、获取、存储和管理数字资源,管理用户权限和资源查访,以及信息发布与服务等功能。文献[7]比较系统地调研了数字图书馆的可用性问题,并提出一些改进建议。从目前的数字图书馆应用及其支撑平台的发展现状和趋势看,相对于传统数字图书馆,新一代数字图书馆应用应具备如下特点:
(1)结构化数据与非结构化数据的统一管理
数字图书馆应用系统应支持多种异质文档及其元数据的管理,需要支持多媒体文档的存储、保管、检索和管理[ 8]。目前,数字图书馆应用对结构化数据的管理比较成熟,非结构化数据的管理主要通过上层应用实现,缺乏对非结构化数据与结构化数据的统一管理。结构化数据与非结构化数据的统一管理必须依赖于底层支撑平台和数据模型两个方面的创新,而不能仅仅停留在应用层改进。
(2)支持数据驱动型应用服务
目前,数字图书馆应用类型已逐渐从计算密集型向数据密集型转变,数据密集型应用已经成为主导数字图书馆信息化建设的重要应用。数据密集型应用的特点表现在应用系统的设计以数据为中心,密切结合综合数据管理,包括关系数据库、XML数据、数字仓储和服务技术,如获取、分析、挖掘和决策、展示等,从体系架构、参考模型和基础设施等多层次、多方位综合规划,为用户最终做出决策或制订方案提供一个有效的综合数据管理和服务支持平台。同时,如何建立跨域、异构、动态、海量数据的共享、交换和集成平台,为数据驱动的协同服务提供支撑平台已经成为新一代数字图书馆研究的热点之一。
(3)从数据服务向知识服务的过渡
知识服务是新一代数字图书馆的重要特征之一。以知识为源泉的知识服务能力是图书情报行业走向未来的根本驱动,决定着知识服务机构的资源转化和服务绩效[ 9]。知识服务的提供需要信息组织技术和知识发现技术的创新。从目前来看,基于语义Web的知识组织技术和基于海量数据的知识发现技术是新一代数字图书馆知识服务的支撑技术。
(4)数字图书馆资源的跨域访问
图书馆联盟不断发展, 尤其是20世纪90年代以来, 信息技术为图书馆联盟带来了新的契机[ 10],OCLC、OhioLINK、JISC、Questel-Orbit、CALIS、NSTL、CASHL等已经成为资源共建共享的成功典范。文献[11]比较系统地研究了异构分布式环境下的数字图书馆互操作技术。在数字图书馆联盟的建设过程中,需要解决的最主要的问题之一是成员图书馆往往位于不同的网络域中。因此,互操作性成为数字图书馆的研究热点之一,例如ACM的最新数字图书馆[ 12]中特别强调了互操性。因此,如何有效共享跨域分布、异构、动态和海量数据,为用户提供高效的数据服务支持,成为新一代数字图书馆的主要发展动力。
(5)泛在知识环境下的数字图书馆服务
自2003年6月“后数字图书馆的未来”研讨会提出数字图书馆“泛在知识环境(Ubiquitous Knowledge Environment)”的建设目标[ 13]以来,“泛在知识环境”成为该领域研究和开发的热点问题之一。数字图书馆泛在知识环境的建设不仅带来了新的技术问题,而且还为新一代数字图书馆建设带来了新的机遇。泛在知识环境下的数字图书馆服务的技术难点是大规模并发处理及其负载均衡问题。同时,泛在知识环境对数字图书馆建设带来的重要机遇是Web2.0应用。Web2.0强调基于数据管理和服务的核心竞争能力而不是基于软件产品的核心竞争力、强调草根网民的集体智慧和参与而不仅仅是领军人物的垄断知识和共享、强调个性化的交互式用户体验而不是大众化无差别信息发布[ 14]。Web2.0的成功应用不仅可以解决目前数字资源建设中存在的数据结构化程度与数据规模之间的矛盾[ 15],而且还可以通过对图书馆长尾用户的浏览、标注、转载、评论操作以及行为分析方法实现新一代数字图书馆资源的增值。
(6)数字化处理向数据长期保存的转移
数字图书馆的建设初期,多数项目侧重于数字化工作,而忽视了长期保存的重要性。为此,美国国会图书馆、英国JISC、澳大利亚国家图书馆、荷兰国家图书馆等先后启动了数字图书馆长期保存项目。从技术角度看,数字资源长期保存涉及多重备份与适时迁移、开放描述与注册、模拟环境与环境封装、数据恢复与数据考古、通用虚拟计算机、技术框架与整体解决方案等[ 16]。目前,常用的数字资源长期保存系统有Cedars的分布式数字档案系统、NEDLIB的DSEP、e-Depot的DIAS等。
3 平台设计
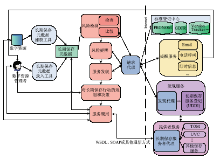
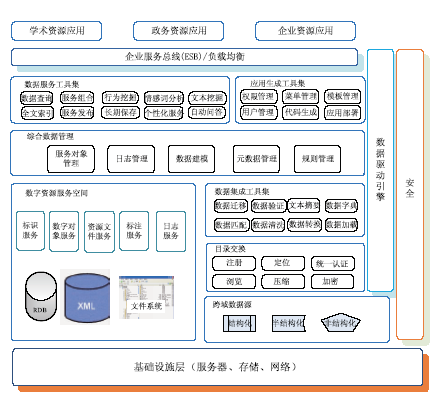
根据上述需求以及国内外数字图书馆的最佳实践、标准规范,课题组设计出了新一代数字图书馆应用支撑平台,如图1所示。
 | 图1 新一代数字图书馆应用支撑平台 |
平台主要组成部分如下:
(1)跨域数字资源:平台所管理的数字资源有三种,即结构化数据、半结构化数据、非结构化数据,这些数据可以分布在不同的网络域。
(2)目录交换:负责跨域数据源的注册、定位和浏览,并提供统一认证、数据压缩和加密功能。
(3)数据集成工具集:对目录交换模块获取的数据进行数据验证、数据清洗、数据转换,并通过综合数据管理模块加载到数字资源服务空间。此外,还提供文本摘要、建立数据字典和数据迁移等辅助功能。
(4)综合数据管理层:接收数据集成后的数据,通过本文提出的数据模型,将数据封装成为数字资源的服务构件模型(Digital Resource Service Component, DRSC)数字对象,并对这些对象进行管理,包括元数据管理、服务对象管理、日志管理和规则管理。
(5)数字资源服务空间:提供DRSC数字对象的存取功能,包括标识服务、数字对象服务、资源文件服务、标注服务和日志服务。其中,标识服务、标注服务、日志服务数据将存储在关系数据库中,数字对象服务和资源文件服务分别存储于XML数据库和文件系统。
(6)应用生成工具集:管理不同的应用模板,支持代码的生成以及应用部署,包括用户管理、权限管理和菜单管理。用户可以通过该工具集快速搭建一个应用系统原型,然后在该原型的基础上开发实际的应用系统。
(7)数据服务工具集:提供了多种工具集,这些工具可以通过库的方式或者Web服务的方式被集成到应用系统中。
在整个平台中,ESB贯穿于各个模块或者系统之间,起到了非常重要的联系作用,包括数据格式的转换,以及为了支持大规模的并发所采取的多个注册服务器的负载均衡。ESB可以防止应用被突发的大规模交易访问造成的崩溃,通过一定的控制能够保证一些重要的交易能够正常进行,保证企业内的重要的系统能够正常运行;其中的流控框架还有一个作用,就是保证下游的系统不会被交易压垮,可以在流控系统中为每个系统设定一个阈值,而且可以为系统配置多个实例,流控系统会根据阈值和交易响应情况对系统中的交易进行流控,从而在一定程度上保护下游系统。
3.1 数据模型
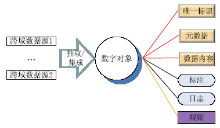
针对新一代数字图书馆应用支撑平台所管理的数字资源的跨域、异构、动态和海量特征,结合Fedora 数字对象(Fedora Digital Object)[ 17]和服务构件架构(Service Component Architecture,SCA)[ 18]提出了数字资源的服务构件模型。该模型将数字对象的管理封装成能够部署在网络上的构件,操作不同域内的数据源,采用数字对象唯一标识技术较好地解决了跨域中资源重复的问题。模型将不同的异构数据进行封装,封装成为DRSC数字对象,并提供统一的访问接口模型。与Fedora数字对象不同的是,DRSC数字对象除了描述唯一标识、元数据和数据内容之外,还支持对标注和日志数据的管理。另外,为了适应数据动态变化特征,DRSC数字对象中还加入了规则数据,如图2所示:
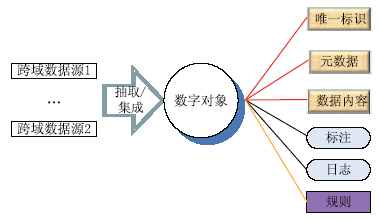 | 图2 对Fedora数字对象模型扩展 |
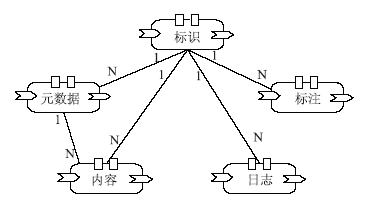
在新平台中,DRSC数字对象定义为5个原子构件的组合,即唯一标识、元数据、数据内容、标注和日志。在每一个原子构件内,都包含了相应的规则属性。值得一提的是,这些服务构件不一定存在于一台计算机上,而是可以分布在不同的网络域中。DRSC数字对象的行为是由其属性配置的,例如链接到相应的子构件。DRSC数字对象支持同一个实现的多个不同接口,可以用不同的语言来实现,例如Java、 C++和COBOL等,从而保证其灵活性。
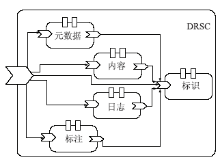
在DRSC数字对象中,元数据、内容、标注和日志构件都是基于标识构件的。当上述4个构件中存储信息发生变化时,它们将通知标识构件更新注册信息,如图3所示:
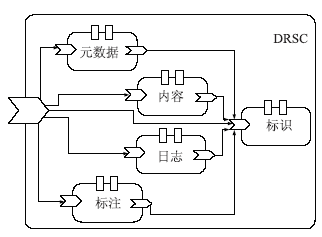 | 图3 DRSC数字对象 |
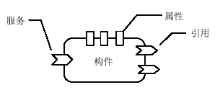
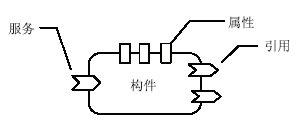
DRSC数字对象高度的灵活性使得它能够自动与其他传输协议进行集成,这些协议包括Web服务、MQ、HTML和REST等。新平台基于SCA提出了数字资源服务组合方法,有效支持服务组合。SCA最初由IBM和BEA开发,目前是由开放面向服务架构(Open Service Oriented Architecture,OSOA)合作组织和OASIS开放组合服务架构(Open SCA)维护的一组规范。一个SCA构件由服务(Services)、引用(References)和属性(Properties)组成,如图4所示:
 | 图4 SCA构件的结构 |
一个构件给其他构件提供服务,同时引用其他构件的服务,服务则通过业务接口来定义。
在数字图书馆应用中,创建一个DRSC数字对象需要两步:
(1)将属性细化和归类为5个构件。元数据包括都柏林核心元数据以及从数字资源中抽取的其他元数据。对于内容,还需要增加一些附加的信息,例如格式类型、文件大小、创建日期、版本等。除了原始的格式,还需要了解将来可能支持的格式。如果自动转换的模块不存在,那么格式转换功能可以被手工添加进去。数字资源的标注可能并不对应元数据构件中的一条记录,如图5所示:
 | 图5 DRSC数字对象之间的关系 |
标识构件和其他4个构件之间的关系是1:N,元数据构件和内容构件之间的关系是1:N。为了提高效率,应用可以通过访问标识构件而直接被检索。
(2)创建相应的管理系统。在数字图书馆应用中,可以采取几种不同方式来创建该系统。
①使用辅助工具来创建源代码和分发包,然后开发一个独立的系统来管理数字资源;
②使用在Internet上提供的原子构件,减少建设和运营成本;
③直接在Web上创建DRSC数字对象,用户输入数字资源的特定信息,提供一个软件即服务(Software as a Service,SaaS)界面对数字资源进行管理,可以进一步降低建设和运营成本。
3.2 数据驱动
与传统数字图书馆的“应用驱动”不同,该平台提供了“数据驱动引擎”,实现了数字资源的动态变化可以驱动上层数据管理工具和应用系统,进而为数字图书馆用户提供自动服务。平台的数据驱动体现在三个不同层面:
(1)数据模型层次。在数字资源的服务构件模型中引入规则数据,能够设定规则,当数据变化的时候,能够触发相应的数据管理和操作功能。
(2)数据管理层次。在平台体系结构的功能设计,尤其是数据集成工具、综合数据管理模块、数据服务工具集、应用生成工具集中采用了数据驱动引擎。
(3)应用系统层次。在平台与上层应用系统之间的企业服务总线中采用数据驱动引擎技术实现负载均衡和数据推送的功能。
3.3 跨域共享
随着数字图书馆的建设,数据总量呈几何级数增长,数据的存储方式、组织结构以及时效性也呈现出了多样性。如何从跨域、异构、动态、海量的数据资源中提取用户所需的知识,是新一代数字图书馆建设面临的一个新课题。本平台对跨域共享的支持体现在以下三个方面:
(1)在平台数据模型的设计中,采用ETL(Extract,Transform,Load)技术、本体技术等将各种跨域、异构、动态的数据以及数据操作的方法整合在同一个模型中,为跨域共享提供了新的数据模型。
(2)目录体系和交换体系的引入,在元数据层次上解决了跨域共享问题。平台采用基于元数据的目录体系和交换体系为跨域资源的统一注册、定位、访问、认证、压缩和加密功能,以及跨域数字图书馆资源的共享提供了保障。
(3)语义相似度计算、资源搜索、多文档摘要、科技查新和热点发现等技术的采用在内容层次上实现了跨域共享。平台采用基于语义的文本相似度计算提高了聚合的效率;采用语义Web与Web2.0集成的知识处理新模式;通过多文档摘要、查新技术和热点发现技术实现了跨域数字资源的内容聚合。
3.4 按需服务
在新一代数字图书馆应用中,用户需求可以是多种多样的,同样向用户提供数据的Web服务功能也各不相同。因此,如何将这些服务按照需要组合起来,满足用户的个性化需求是平台设计的主要目的之一。本平台按需服务功能主要采用了三种技术:
(1)协作过滤技术。面对海量的数据,为了帮助用户及时找到所需要的数据,本平台采用了基于社会化标签的协作过滤算法和基于图的个性化推荐算法。
(2)海量知识挖掘技术。为了提高数据挖掘的速度,本平台借鉴Hadoop分布式文件系统(Hadoop Distributed File System)提出了基于Map-Reduce的海量知识挖掘技术[ 19]。
(3)服务形式化建模与验证技术。新一代数字图书馆应用需要调用分布在不同网络域的Web服务。为此,平台提供了Web服务组合的形式化建模与验证技术。
3.5 大规模并发处理
在新一代数字图书馆环境下,大规模并发主要包括两个方面,即接入问题和加快单个服务器的内部处理问题。在平台设计中,主要采用以下技术解决大规模并发带来的问题:
(1)对于接入问题,本平台主要通过ESB中的负载均衡机制解决了大规模并发问题,通过配置方式实现同一个接入点由多个服务来完成时采用负载均衡的方式来接受大规模的请求。
(2)对于服务器的内部,平台设计中主要采用缓存和内存数据库技术实现了对单个服务器的高效运用。
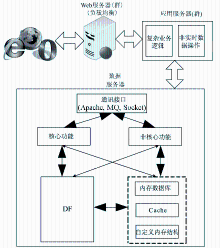
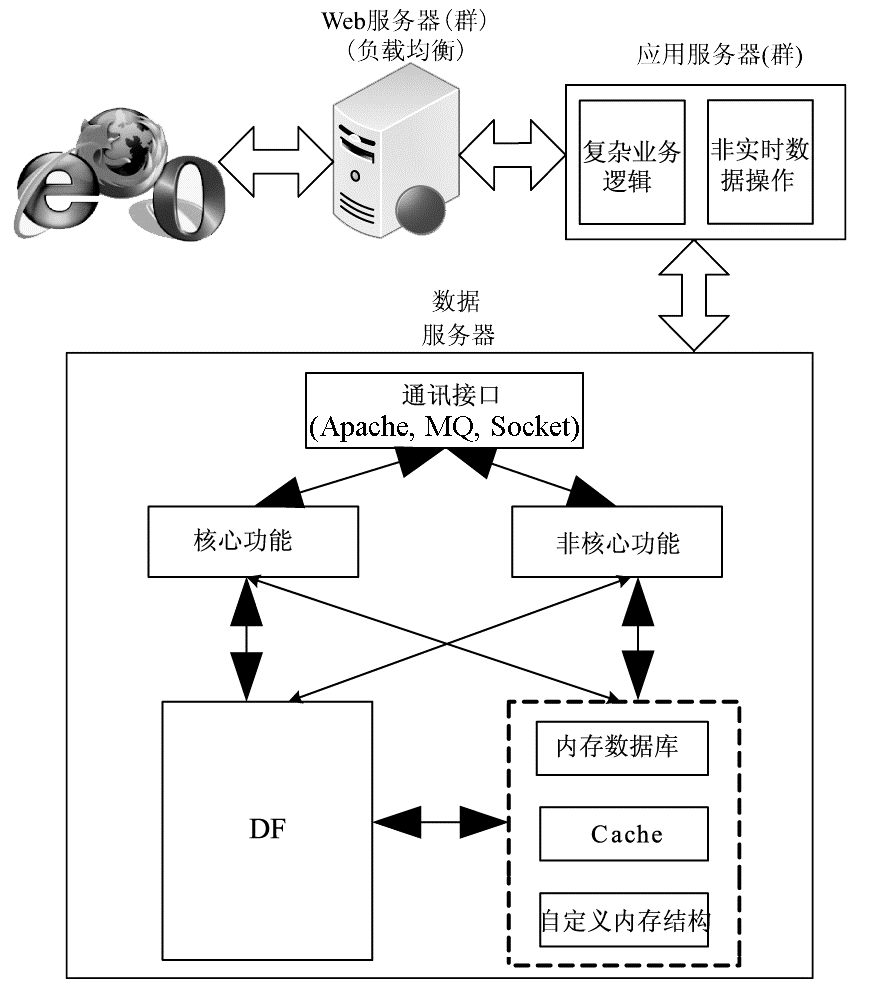
(3)支持大规模并发交易的参考模型。针对基于Web的应用,考察了多种在大规模并发交易下的体系结构,提出了一个支持大规模并发交易的参考模型,在Web服务器和应用服务器层通过负载均衡来应对大规模访问,如图6所示:
 | 图6 支持大规模并发交易的参考模型 |
(4)数字资源服务的分类处理。该模型将新一代数字图书馆服务分为两类:核心服务和非核心服务,并分别采用了不同的技术方案。对于核心服务采用基于键值的DF方法,而对于非核心服务采用内存数据库、Cache和自定义的内存结构提高大规模并发处理的效果和效率。
4 实现技术
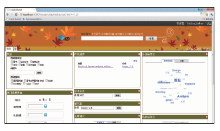
在平台设计的基础上,综合运用J2EE、MySQL、Apache Ant、ApacheDS、Berkeley DB XML、JBoss、JRules、Memcache、OSWorkflow、Mule、ActiveMQ等开发技术,实现了原型平台,并获得了一项软件著作权(软件著作权名称为“支持数据驱动型应用的跨域共享与服务支撑系统”),如图8所示:
 | 图8 新一代数字图书馆应用支撑平台示范界面 |
在平台实现中采用的关键技术如下:
4.1 基于CDOI的分布式唯一标识的目录交换技术
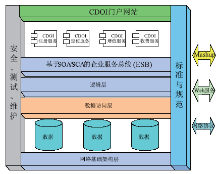
为了支持统一数据参考模型,在前期参与制订国家目录体系与交换体系的基础上,课题组研究了多个数字对象标识管理和服务系统,例如DOI,然后提出了CDOI系统[ 21]。该系统采用通用唯一识别码 (Universally Unique IDentifier,UUID)进行编码,提供了CDOI注册、定位、收费以及增值服务,能够满足分布式、海量数字资源标识的需要。CDOI系统的功能架构如图9所示:
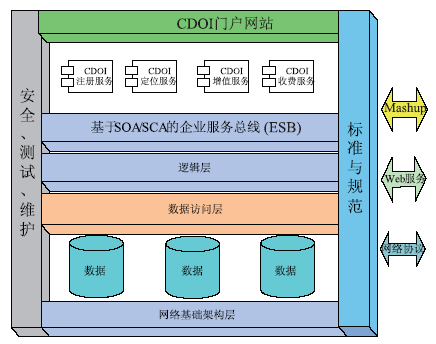 | 图9 CDOI系统功能架构 |
CDOI系统的实现流程如图10所示:
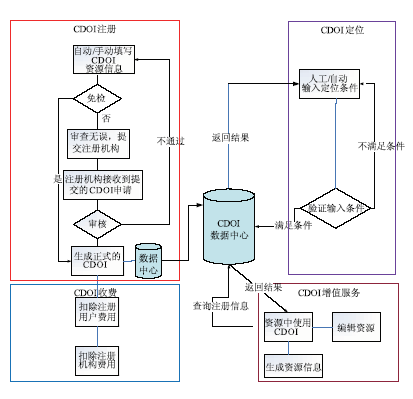 | 图10 CDOI系统实现流程图 |
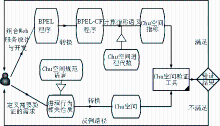
4.2 基于Chu空间的服务组合形式化建模与验证技术
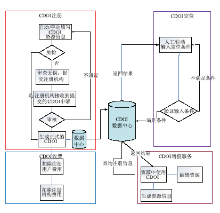
平台研发中提出了一种基于Chu 空间的对WS-BPEL(Web Services Business Process Execution Language)程序进行自动建模和验证的新方法[ 22, 23]。该方法可自动计算WS-BPEL程序的Chu 空间语义,允许用户使用界面定义待验的Chu空间规范语言(Chu spaces Specification Language, CSL)性质,然后对性质进行自动验证,如果验证不成功,可以提供一条反例路径以及程序和性质之间的相似度,如图11所示:
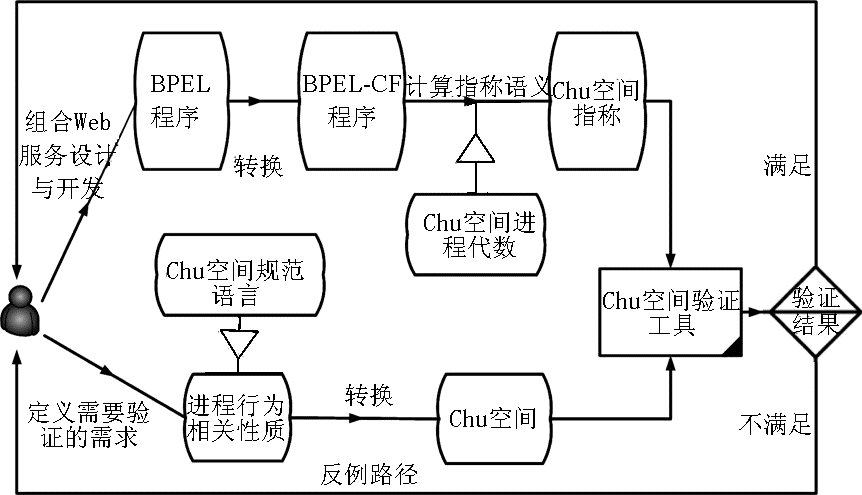 | 图11 服务组合建模和验证的工作流程 |
Web服务组合建模和验证的工作流程如下:
(1)将用户提交的 BPEL 程序转换为其控制流框架BPEL-CF程序,然后通过Chu空间进程代数计算其指称语义,得到该程序的Chu空间指称,作为Chu空间验证工具的一个输入;
(2)根据用户需求,定义需要验证的性质,使用Chu空间规范语言对该性质进行形式化描述,然后转换为Chu空间,作为Chu空间验证工具的另一个输入;
(3)Chu空间验证工具在得到要验证的BPEL程序的Chu空间指称和待验证的性质Chu空间描述之后,进行自动验证。如果性质得到满足,则返回正确;否则,就表明发现了程序的一个错误,返回该程序中的一条错误路径。
4.3 语义Web与Web2.0集成的知识处理技术
平台知识组织采用了语义Web与Web2.0集成的知识处理方式。语义Web技术和Web2.0理论的出现为传统知识处理模式中存在的两大瓶颈(即知识表示的计算机不可理解性和人在知识共享和创新中的自我保护性)提供新的解决方案[ 24]。语义Web技术采用计算机可理解的知识表示方法,实现了知识处理的计算机可理解性,降低了人工智能知识处理的复杂性;Web2.0为知识共享和创新提供了具有草根性、自组织性和集成性的知识生态系统。因此,本平台采用了语义Web与Web2.0集成的知识处理新模式[ 25],实现了语义相似度计算、数据挖掘、知识发现、智能推荐和检索提示等功能。
平台采用语义Web与Web2.0集成的模式,如图12所示:
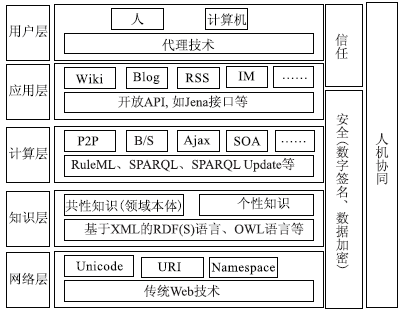 | 图12 语义Web与Web2.0集成的知识处理模式 |
其中,知识层建立在网络层之上,主要为计算层提供计算机可理解的知识资源,是解决知识表示的计算机不可理解性的关键层次。知识层的知识包括两种,即领域知识和非领域知识。前者是个性知识的创建、检索、推理的依据,它的建设一般由领域专家共同完成。而后者可以由领域专家完成,也可以由草根用户完成。基于XML的RDF(S)语法或OWL语言的知识表示技术是常用的知识层技术,用于知识表示和一致性检验。计算层建立在知识层基础之上,主要负责对知识层中的知识进行检索、推理、抽取、挖掘等具体操作,是知识层和应用层之间的桥梁。计算层可选择的计算技术和模式由知识层中采用的知识表示技术和应用层所提供的服务决定。
(1)由于知识层的知识表示采用了语义Web知识表示技术,计算层采用RuleML[ 26]、SPARQL[ 27]、SPARQL Update[ 28]等语义Web技术,分别实现知识层的推理、查询和更新操作;
(2)应用层采用Web2.0式的知识处理模式,计算层一般采用常用于Web2.0的计算模式,如P2P、B/S、Ajax、SOA等。
4.4 基于社会化标签的协作过滤技术
根据平台研发的需要,设计了一种基于社会化标签的协作过滤算法框架IBeST (Item-Based with Social Tags)[ 29]。IBeST是一个将基于条目的协作过滤算法扩展到社会化标签层面的算法框架。不同于在经典协作过滤算法中仅仅使用评分作为条目相似度度量依据,IBeST试图同时使用社会化标签和评分作为度量条目相似度的依据,并将这个新计算出的条目相似度应用在原来的预测公式中,从而提升原有经典算法的预测效果。
IBeST算法框架如图13所示:
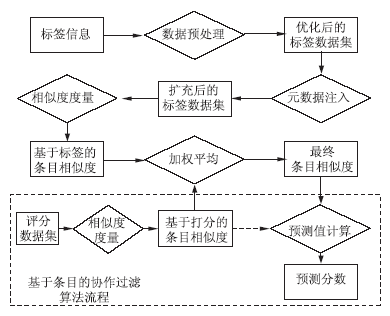 | 图13 基于社会化标签的协作过滤算法框架 |
(1)IBeST针对社会化标签数据进行预处理,优化后的数据能够更好地辅助后面的预测计算;
(2)将条目的元数据作为有权重的标签引入IBeST,从而让标签数据具有更加权威的语义信息;
(3)使用实验中效果最好的相似度度量算法来得到基于标签的条目相似度,通过进一步实验找到合适的相似度权重,并且计算出根据评分和标签得出相似度的加权平均;
(4)使用经典协作过滤算法的预测公式进行计算,并得到预测评分。
4.5 多文档摘要和科技查新技术
平台采用了“多文档自动摘要技术”[ 30],从多个不同文档中自动抽取关键内容,并自动生成摘要报告,从而提高数据驱动型应用的跨域共享与服务能力。在跨域数字资源的科技查新中,使用MMR (Maximal Marginal Relevance)算法计算句子的重要性,选取得分最高的句子作为候选句,使进入文摘的句子与用户查询的相关度较高,且与已选取的候选句子之间的冗余度尽可能小,从而提高了文摘的质量。应用自动摘要技术的新一代数字图书馆自动科技查新的技术架构,如图14所示:
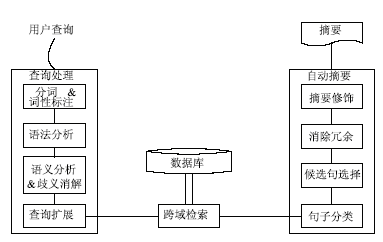 | 图14 多文档自动摘要技术框架 |
4.6 基于图的个性化推荐技术
在平台研发过程中采用了“社会网络下的基于图的个性化推荐算法及其系统”[ 31]。该算法利用用户对资源标注标签这一信息,计算出用户之间的相似度,并将相似度信息加入图中,提高图的密集程度。通过在真实数据集上的实验证明,提出的算法使准确度有一定的提高。算法的思路如下:
(1)对社会网络进行构图:G=(V, E),其中,G是一个带权无向图;V为顶点,代表用户和资源;E为边,表示顶点之间的联系程度,权值越高,表示两个顶点的关系越紧密。
(2)利用用户对资源标注的标签,计算用户之间的相似度,即利用余弦相似度的计算方法和用户的标签向量,进行用户之间相似度的计算。
(3)在图G上进行Random Walk with Restarts算法,结合经典的随机漫步算法,在每一步都有一定的概率重新出发。当算法收敛之后,可以得到到达每个顶点的概率。这个概率可以理解为与当前用户的相关性,把所有资源顶点按概率排序,可以依照排序的结果进行个性化推荐。
4.7 基于ESB的大规模并发控制技术
本平台主要通过负载均衡器、ESB路由规则、Web服务集群三层结构来支持大规模访问。当集群节点负载过大时,能对网络请求进行调度;当服务器发生故障时,能自动检测故障和用户请求,重定向到其他服务器。在用户信息受理过程中,如果其中一个服务器发生故障,其他服务器接管故障服务器的工作。当故障的服务器修复,并准备再次运行时,信息处理工作将从其他服务器转回。当发生故障时,恢复机制利用节点之间的可用资源,动态地进行重路由来代替故障路由,改善了系统的能动性。
如果同时应对多个突发事件或故障时,系统会通过服务器集群共享软件配置数据存储,以数据为中心,来适应不断变化的数据内容。为了容纳多个故障,配置多对多集群系统,由多个活动节点和多个配置为故障转移的节点组成,这些故障节点可为主动,也可为被动,系统将保证故障恢复失败的节点可再次使用,从而确保信息处理过程的安全、可靠。
5 结 语
5.1 应用现状与前景
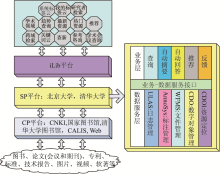
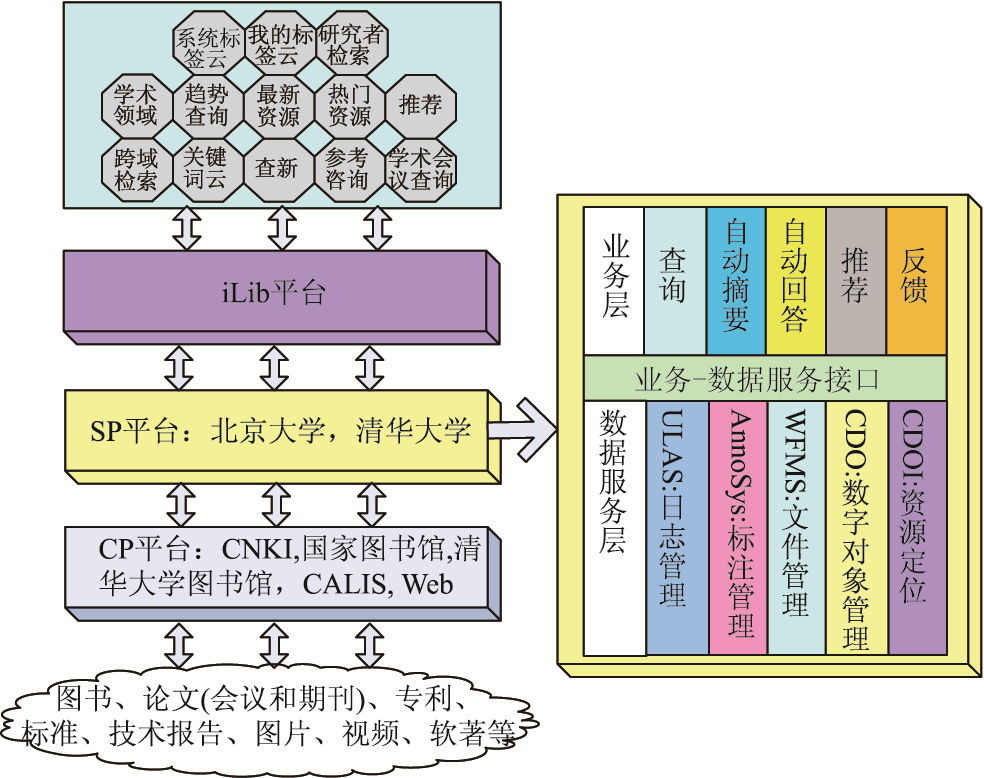
目前,爱迪智搜平台已经在中国高等教育数字图书馆(CALIS)上投入试用,如图15和图16所示:
 | 图15 爱迪智搜的部署图 |
 | 图16 爱迪智搜在CALIS中的应用 |
(1)资源层:平台实现了结构化数据与非结构化数据的统一管理,可支持的数字资源有图书、论文、专利、标准、技术报告、软件著作权、图片、视频及其元数据等。
(2)内容提供者(Content Provider,CP):平台实现了CNKI、国家图书馆、清华大学图书馆、CALIS和互联网的跨域数字资源的按需服务。
(3)服务提供者(Service Provider,SP):服务提供层为北京大学图书馆和清华大学图书馆提供了两个不同层次的服务。业务层提供的服务包括了查询、自动摘要、自动问答、用户反馈;数据服务层提供的服务包括了日志管理、标注管理、文件管理、数字对象管理和资源定位。
(4)应用支撑服务:该平台可以较好地支持以下图书馆应用:按关键字查找用户所需资源;为用户提供科研活动分析功能,如自动查新,形成查新报告;分析用户兴趣偏好主动提供资源推荐和热点跟踪;接收用户反馈信息,获取用户偏好,并根据用户兴趣偏好,实现个性化服务;为用户提供管理科研活动资源的工具,如对资源进行分类,提供标签功能,用户可以使用标签管理资源;用户可以与好友分享自己的科研活动,如标注的资源、查询热点等。
从目前的运行状况看,爱迪智搜平台为新一代数字图书馆建设提供了支持。
(1)从图书馆应用开发角度看,该平台较好地满足了新一代数字图书馆应用的数据驱动、跨域共享、按需服务和大规模并发需求。软件开发商可以直接复用本平台提供的各种服务,从而可以节省研发成本,降低研发风险。
(2)图书馆读者用户在该平台上进行跨学科研究,提高文献检索的查全率。读者用户还可以利用平台的数据驱动和个性化推送功能定制所需内容和服务。
(3)数字图书馆工作人员可以利用本平台的跨域共享特点避免重复建设,降低成本;利用大规模并发处理特征保证泛在知识环境下的服务可用性;利用平台提供的数字资源长期保存技术,识别数字资源中存在的各种风险,降低或避免数字图书馆资源建设中存在的潜在风险;通过平台提供的语义Web和Web2.0集成的知识处理模式,充分发挥图书馆用户的贡献,将长尾用户纳入图书馆建设者范围之内,实现数字图书馆资源的增值,解决目前数字图书馆建设中存在的数据结构化程度与数据规模之间的矛盾。
因此,该平台的适用范围较广,应用价值较大,对数字图书馆、政府和企业信息资源管理平台的研发工作具有重要参考价值。
5.2 总结与展望
本文提炼出了新一代数字图书馆应用支撑平台的主要特点,即结构化数据与非结构化数据的统一管理、支持数据驱动型应用服务、服务内容从数据服务向知识服务过渡、数字图书馆资源的跨域访问、泛在知识环境下的数字图书馆建设、数字图书馆关注点从数字化处理向数据长期保存的转移。在此基础上,重点研究了新一代数字图书馆应用支撑平台的体系结构、数据模型、跨域共享、按需服务、并发访问、长期保存的关键技术,并研制了一套面向新一代数字图书馆应用开发的支撑平台——爱迪智搜平台。该平台由目录交换模块、数据集成工具集、综合数据管理模块、数字资源服务空间、应用生成工具集、数据服务工具集、企业服务总线和数据驱动引擎组成。
爱迪智搜平台的研发工作取得了阶段性的成功,但还需要继续完成以下工作:部分功能需要重新设计或补充开发;需要完成平台的测试和维护工作;总结平台应用的最佳实践,完成平台的推广工作。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|