
{kind=link}
{kind=link}
{kind=link}
基于LOD的关联参考服务构建研究*
引用本文
刘媛媛, 李春旺, 黄永文. 基于LOD的关联参考服务构建研究* . 现代图书情报技术, 2011, 27(6): 66-71
Liu Yuanyuan, Li Chunwang, Huang Yongwen. Study on Building the Service of Relevance Reference Based on LOD. 现代图书情报技术, 2011, 27(6): 66-71
Permissions
Liu Yuanyuan, Li Chunwang, Huang Yongwen. Study on Building the Service of Relevance Reference Based on LOD. 现代图书情报技术, 2011, 27(6): 66-71
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于LOD的关联参考服务构建研究*
关键词:
LOD; 关联服务; 关联数据
中图分类号:G250
Study on Building the Service of Relevance Reference Based on LOD
Abstract
The key technologies and methods to build the service of relevance reference based on LOD are analyzed and summarized, including relevance model, linked data access, entities data consolidation. Typical applications related to the service are introduced and the key problems in building the service are presented.
Keyword:
LOD; Relevance service; Linked data
1 关联参考服务的演变
用户在阅读科技文献时,经常会遇到专业术语、研究项目等各种实体对象,围绕这些实体对象提供语义关联信息,将有助于读者理解文献内容以及扩展获取相关知识,这便是关联参考服务。
数字图书馆早期的关联参考服务主要是基于引文的参考链接(Reference Linking)[ 1],即通过人工或自动化方式对引文元数据进行分析,建立引文和被引文之间的参考链接,支持用户在阅读某篇文献时方便快捷地获取、阅读相关主题的文献。除了引文关系之外,科技文献之间还存在众多基于内容的关联关系。美国国家数字图书馆(NSDL)为用户提供了一个基于名词术语的关联参考服务(SCALE)[ 2],它自动从用户当前阅读文献中抽取跨学科名词术语,并建立这些名词术语与指定百科全书、词典等资源之间的关联链接,支持用户通过点击这些链接以获得相关术语的解释信息。如何为各种各样的主题对象发现准确、可靠的关联信息成为参考服务建设的关键,SCALE采取的策略是预先建立相关学科领域的权威资源列表,支持从文献中抽取出名词术语的查询匹配。该方法的优点是关联信息可靠,缺点是需要预先建立内容庞大的资源库。
关联数据的发布与应用给关联参考服务建设带来了发展契机。W3C于2007年启动了关联数据项目LOD,截至2010年9月,LOD云图中已有200多个数据集合,提供大约250亿个RDF三元组以及大约3.95亿个RDF内部链接[ 3]。在这种情况下,基于LOD的信息扩展服务成为人们关注的热点,例如:Sonntag等[ 4]利用LOD中DrugBank、Diseasome和DBpedia三个数据集中的信息为医学图像提供注释功能,支持利用扩展信息推断可能的疾病并根据病症给出相关的药物信息;Haslhofer等[ 5]利用关联数据为视频注释信息做扩展,当用户添加注释信息后,系统自动显示注释信息的相关信息,帮助用户理解视频内容;Passant等[ 6]则利用关联数据构建一个推荐服务系统,当用户浏览一个音乐家的信息时,通过计算语义距离推荐相关的其他音乐家信息。关联数据不但预先建立了数据对象之间的可靠关系,而且迅速发展的关联数据空间为构建高效的关联参考服务提供了强大的资源支持。本文将重点讨论基于关联数据的关联参考服务构建技术和方法,以便为相关研究提供借鉴。
2 关键技术分析
2.1 关联模型构建技术
关联模型是对数字文献中实体对象的相关属性及关联关系的描述,以指导关联信息发现、融合与可视化呈现等操作。
(1)综合关联模型
综合关联模型描述多个实体属性及实体间关联关系,典型的综合关联模型是DBpedia本体。DBpedia本体是一个跨领域的本体,基于Wikipedia的信息框(Infoboxes)手工创建,包括272个类和1 300个属性,DBpedia3.5版本允许用户自定义信息框与本体之间的映射,扩展本体中已有的类和属性。目前,DBpedia描述了350多万个事物,其中167万个用统一本体进行分类[ 7]。DBpedia本体描述了多种实体对象,其中,与关联参考服务相关的包括科研人员(Scientist)、教育机构(Educational Institution)、研究项目(Research Project)、期刊杂志(Magazine)、会议(Convention)等。实体对象间具有清晰的类层级关系,其中,owl:Thing是所有类的父类,按照事物的类型不同分为33个子类,并可以进一步细分。例如组织类(Organization)按照组织的性质不同分为非盈利组织、公司、教育机构等,教育机构又分为College、Library、School、University子类,子类在父类的基础上添加自己独有的属性描述。DBpedia本体是一个涵盖多个领域、多种实体对象、每个实体对象具有丰富属性描述的综合关联模型,为数字文献中实体对象的关联模型设计提供了重要参考。
(2)单一实体关联模型
单一实体关联模型对某一种实体对象的相关属性及属性间的关联关系进行描述,例如FOAF本体描述人物信息,DOAP本体描述项目信息等。为支持应用对不同人物类型相关信息的有效集成融汇,Latif等设计了CAF-SIAL概念集成框架[ 8]。
CAF-SIAL框架包括三层结构:
①集成知识层,使用DBpedia、Yago和Umbel本体进行资源的识别和分类。首先,选择18种典型的人物类型,例如运动员、艺术家、科学家等,借助DBpedia的SPARQL浏览器SNORQL Query Explorer查询获取18种不同类型人物各自的所有描述属性,经过专家挑选后构建属性知识库。再通过SPARQL查询Yago中Person类的子类信息,构建分类知识库。根据不同属性被使用的次数决定哪些属性最终呈现给用户,排名越高,属性呈现给用户的可能性越大,例如Athlete的属性Position使用70 939次,Clubs使用46 101次。
②属性集成层,使用DBpedia属性知识库识别资源类型(RDF Type),如果没有属性映射到该知识库,框架将映射检索的属性到Yago分类知识库。例如被检索的属性是“AustrianComputerScientist”,在属性知识库列表中没有相应的资源类型,则将其映射到Yago的分层结构中,“AustrianComputerScientist”是“Scientist”的一个子类,可以推理出这个人的职业是科学家。确定人物类型后,手工从属性知识库中提取出最相关的描述属性并对属性进行分类,如出版信息、家庭信息、个人信息等。
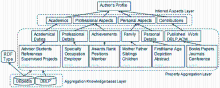
③推理面层,受Google搜索结果的启发,将人物信息分为不同的信息面。数字期刊作者的CAF-SIAL概念集成框架[ 8]如图1所示:
 | 图1 数字期刊作者CAF-SIAL概念集成框架[ 8] |
构建关联模型既要考虑实体间的关联关系,也要考虑实体属性的分类关系。每个实体不是孤立存在的,例如一篇文献的作者属于某个科研机构,其论文发表在某个学术会议上,作者、科研机构、学术会议三个实体就建立了关联关系。对实体属性进行分类与分面,能使关联模型结构更清晰、直观。
2.2 关联数据发现获取
(1)关联数据源选择
选择数字文献中实体对象相关的关联数据源,为关联数据发现获取做准备。已有相关研究对LOD中数据集的归类和互连情况进行统计分析[ 9, 10, 11]。大部分的关联数据应用通过人工方式选择数据源。基本策略是首先选择综合的、被广泛使用的关联数据源,例如DBpedia,然后根据具体的主题选择相关的数据源。典型的应用是Linked Movie Data Base(LinkedMDB), LinkedMDB[ 12]是一个关联电影资料库,选择DBpedia中的电影资源建立owl:sameAs连接,从FlickerWrapper中获取电影相关的图片,以MusicBrainz连接电影的主题曲,从Revyu.com中获得电影的评论信息等。
关联数据集的元数据信息为数据源选择提供了参考,描述这些元数据的词表包括数据集互联词汇表(voiD)和Semantic Sitemaps。voiD[ 13]是一个新兴的本体,用来描述关联数据资源的内容和组成。voiD文件用RDF语言描述数据集的主题信息、版权信息、可用的SPARQL端点地址、资源URIs类型、使用的词汇表、三元组统计信息、内部连接及与其他数据集的外部连接情况等。通过多种方式可以获得数据集的voiD,voiD服务[ 14]收集了大量的voiD文件,客户端或应用能通过SPARQL端点或REST API创建查询,找到特定主题的数据集;关联数据研究中心(LiDRC)开发的Linked Datasets Explorer能查询相关主题的关联数据集,浏览数据集的voiD文件。Semantic Sitemaps[ 15]对Sitempas XML格式进行扩展,方便应用选择合适的方式获取关联数据集。数据集的描述信息在
| 表1 LOD中数据集提供voiD和Sitempas的统计情况[ 16] |
(2)关联数据发现获取
基于关联模型的描述信息,从多个数据源发现并获取相关的关联数据资源。传统的关联数据发现获取方式主要有三种:下载RDF Dump文件,语义网搜索引擎和SPARQL联合查询。目前,LOD中有34.78%的数据集提供Dump文件,66.18%数据集提供SPARQL端点[ 16]。Dump方式,关联数据被保存到本地,通过大量、高效的RDF存储能预先索引和统计数据,查询响应时间快、准确率高,但由于数据获取和更新方面的限制,这种方式不适合规模较大且经常更新的关联数据集。语义网搜索引擎的方式发现获取关联数据被大量的关联数据应用采用,Sindice、Falcons、Watson等都提供API支持应用搜索关键词或URI。这种方式可选择的服务较多,但发现的资源格式多种多样,数据质量参差不齐。SPARQL端点方式不需要下载数据到本地且搜索准确率高。目前,W3C的SPARQL1.1标准还不支持多数据源的联合查询,联合查询引擎解决了这个问题。SPARQL联合引擎支持查询获取多个SPARQL服务,使用户感觉查询多个分散的SPARQL端点就像查询单个RDF图一样。该方法通过联合查询器(Query Federator)分析并分解用户的查询为多个子查询,这些子查询被分散到单个已知的数据源中执行SPARQL查询,结果经过集成后返回给用户。由于要分解查询和处理中间结果,联合查询执行较慢,需要数据缓存技术和优化算法提高查询执行速度。典型的联合查询引擎有DARQ、SemaPlorer等。
传统的关联数据发现获取方法需要应用开发者事先选择潜在的数据源,应用的数据来自被选定的资源,阻碍了发现和使用未知数据源的相关资源。主动发现的联合查询方法和链接遍历的方法能主动发现获取未知的相关关联数据资源。主动发现的联合查询,为了预先主动发现可能的SPARQL端点,将发现过程与查询执行过程分开。利用搜索引擎或RDF链接跟踪等方法发现附加的SPARQL端点元数据描述,通过这些信息判断SPARQL端点的相关性。集成相关SPARQL端点到初始的查询计划中,使用自适应的方法调整查询计划。受关联数据浏览器Tabulator的启发,Hartig等[ 17]提出一种自动链接遍历的方法发现获取关联数据。遵循关联数据原则发布的数据源即可使用该方法,不需要预先已知数据源的信息。该方法从一个种子URI开始,在查询执行过程中基于查询的部分结果跟踪资源间的RDF链接,发现相关的数据,使用基于迭代器的管道技术(Iterator⁃Pipeline)实现了该方法。由于关联数据空间的开放性,遍历链接的方法存在很多问题,例如遍历的深度和广度设置、关联服务器的请求限制等。
除以上方法外,一些应用使用爬虫发现获取关联数据,一个开源的关联数据爬虫是LDSpider[ 18],它支持宽度优先和负载平衡的抓取策略,提供API支持应用配置和控制抓取进程的细节。爬虫的方式适合建立在新资源随着爬虫的抓取不断增长的应用之上,缺点是抓取的数据可能存在重复。综上所述,关联数据有多种获取方式,不同获取方式有各自的优缺点。在实际应用中要考虑获取单一数据源还是多数据源,对应的数据获取方式可能是单一方式或集成方式。
2.3 实体数据融汇
(1)数据过滤
从分散的数据源获取到关联数据后,为保证数据融汇的质量首先要对获取的数据进行过滤,选择关联模型中的相关信息。数据过滤要排除发现获取中的数据质量问题,包括以下三个方面:非结构化数据,例如语义网服务搜索结果中显示为RDF格式数据,但实际可能包含非结构化数据;无效链接,即因数据更新或服务器完善等因素无法正常链接相关的数据;数据冗余,多数据源、多种获取方式获取的数据可能存在重复。通过数据有效性验证可以解决以上问题。
数据过滤的另一个重要任务是选择关联模型中描述的、最相关的资源为实体融汇做准备。Garcia等[ 19]提出一种迭代加深的深度优先算法(Iterative Deepening Depth-First Algorithm)选择相关的关联数据为教育资源添加注释。该方法通过语法分析、相似度分析和词频分析,从XML格式的数字图书中提取文档上下文信息,得到需要语义扩展的关键词及其与上下文的相关度。利用DBpedia的Lookup服务检索关键词的相关语义信息。以关键词Pharaoh为例,算法从根节点Pharaoh(http://dbpedia.org/resource/Pharaoh URI)开始,设置遍历深度为4,检索结果如图2所示[ 19]。
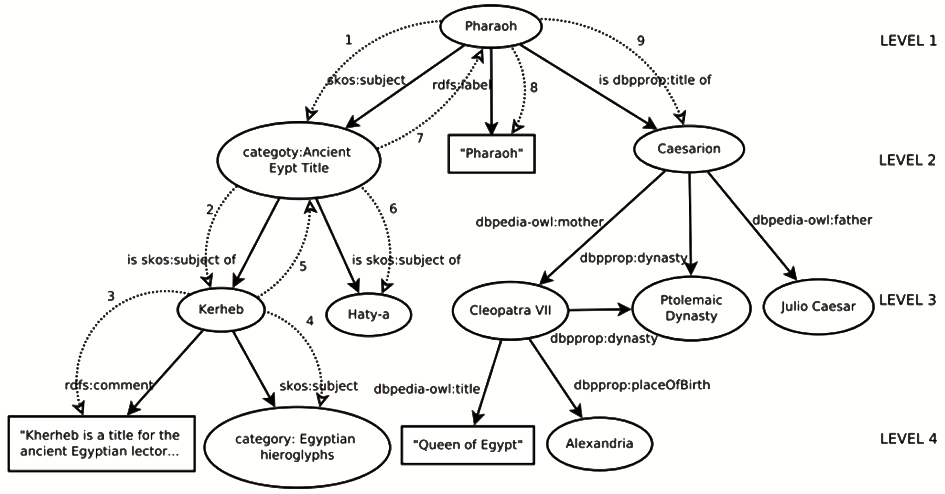 | 图2 应用迭代加深的深度优先算法在 |
图2中,椭圆形是DBpedia资源,长方形是文字,箭头表示节点间的语义关系,弧上的数字表示发现顺序。如果宾语是文字,则分析文字与上下文的关系,例DBpedia中检索Pharaoh[ 19]
如关系dbpedia-owl:title在节点CleopatraⅦ和Queen of Egypt之间,Egypt在文档的上下文中,则根据Egypt的相关度,使用阈值决定这个关系是否被考虑。如果宾语是URI,将URI分为两种:
①描述概念,如Caesarion,继续遍历URI直到深度限制,通过文字与上下文的匹配判断相关性;
②URI定义一个分类,例如http://dbpedia.org/resource/Category:Ancient Egypt titles定义分类Ancient Egypt Titles,如果检索的资源与发现的分类共享同一个分类,则认为分类是相关的,该分类被扩展,否则被过滤。
该研究通过文本与上下文信息的匹配和URIs遍历选择了最合适的子图注释教育资源中的相关概念。关联参考服务可以借鉴这种方法,用关联模型中的属性和层级关系过滤检索到的关联数据。
(2)实体数据融汇
实体数据融汇的主要任务是将过滤后的实体属性描述映射为关联模型中相应的属性描述,可能存在属性名不同、取值范围不同等问题。例如不同来源的人物主页信息可能有不同的属性名,如“page”,“Weblog”,“Website”,“public home page”等,关联模型中相应的属性名是“Web Page”。本体匹配技术为异构的实体数据融汇提供了解决方案。本体匹配能发现两个不同本体之间语义映射关系或相似度,自动或半自动的匹配方法在Euzenat等的书中有详细的总结[ 20]。除了本体匹配的实体融汇方法外,还有一些方法在应用中可以借鉴:语义网数据聚合器Sig.ma基于实体Profile创建对关联数据进行融汇[ 15];Falcons和SWSE等语义网搜索引擎基于对可逆功能属性(Inverse Functional Property)和属性值的分析,找到等价的实例信息并进行实体合并[ 21];Hogan等[ 22]基于对谓词的统计分析设计了关联数据实体合并算法;受Yahoo Pipes的启发Morbidoni等开发了Semantic Web Pipes(SWP)[ 23],SWP能够从不同的关联数据源抓取数据,并进行语义数据融汇。
除关联模型构建、关联数据发现获取、实体数据融汇外,关联参考服务还包括从文献内容中抽取名词术语技术以及关联服务可视化呈现技术等。
3 典型应用
奥地利格拉茨科技大学的研究人员利用关联数据资源融汇计算机科学期刊(J.UCS)作者的个人信息[ 24]。该系统能够识别、检索、过滤数字期刊作者相关的关联数据资源,结构化组织获取的信息并可视化呈现出相关的语义资源。该应用有助于读者搜索合作者,找到相关领域专家,使期刊吸引更多的用户。
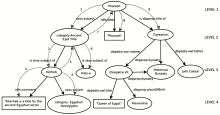
除本地数据源中数字期刊作者的信息外,应用选择DBpedia的Persondata和Links to DBLP两个子数据集,分别获取作者信息及其出版信息。Persondata数据集使用FOAF词汇表描述,包含从Wikipedia中提取的大量人物信息。Links to DBLP数据集包含DBpedia中计算机领域专家到DBLP数据集中他们出版物的链接。通过RDF Dump方式将两个数据集下载到本地,使用ARC2存储工具构建本地三元组存储库。对本地数据源中作者名进行预处理,包括大小写转换、缩写转换为全名等。对每位作者,利用ARC2提供的SPARQL查询在本地三元组存储库中搜索作者的相关信息,如果没有对应的URIs,再使用Sindice提供的API在语义网中搜索相关信息,搜索到的结果过滤后保存到本地三元组存储库中。数据过滤面向本地和网络搜索,主要解决两个问题:无效链接和作者重名问题。通过验证查询结果的链接地址中必须包含RDF数据,解决无效链接问题;利用某些特殊属性区分作者重名问题,例如dbpedia:Abstract,dbpedia:Comment和SKOS分类等,用这些属性信息判断作者的研究领域,将重名但属于另一个领域的作者过滤掉。最后,将获取到的相关关联数据信息与CAF-SIAL概念集成框架中的属性描述进行映射,融汇作者不同分面的信息,以可视化的方式呈现给用户。利用关联数据资源构建数字期刊作者个人信息的应用效果如图3所示:
 | 图3 数字期刊作者个人信息应用效果[ 24] |
RKBExplorer项目[ 25]通过Web抓取或Dump等方式从多个数据源获取科研项目、 组织机构、科研人员、出版物等语义信息,使用一致引用服务(Consistent Reference Service)融汇不同来源的实体对象。Yotube[ 26]利用WordNet和DBpedia使标签具有更多语义关联。对于匹配标签和WordNet模块,如果只有一个同义词集与标签匹配,则选择DBpedia中相应的WordNet URI;多于一个匹配,则通过余弦相似度计算进行选择;不在WordNet中的标签,使用Sindice查询相关资源,用户可以通过手工的方式选择查询结果中的URIs,创建语义链接。
4 结 语
随着LOD中数据集的快速增长,利用关联数据进行类似的信息扩展服务会成为一种趋势。但作为新技术,关联数据在实际应用中还有很多不足之处,其中最主要的是数据质量问题。在应用中不作任何处理直接使用LOD中的数据会产生很多问题,包括:数据不完整,不能检索到相关的数据;获取到的数据是不相关的;不同数据源的数据不一致;数据劫持(Hijack)等[ 27]。另一个关键问题是URIs识别、集成中面临的共指(Co-reference)[ 28]问题,共指是指多个不同的实体共享同一个URI或者用不同的URIs描述同一个实体,给关联数据重用带来很大挑战。笔者将继续对关联参考服务相关环节的技术方法进行研究,同时基于已有的方法尝试搭建基于LOD的关联参考服务应用,在实践中借鉴已有工具和方法解决相关问题。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|