





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于FCA的Folksonomy用户偏好挖掘研究
引用本文
张云中, 杨萌, 徐宝祥. 基于FCA的Folksonomy用户偏好挖掘研究. 现代图书情报技术, 2011, 27(6): 72-78
Zhang Yunzhong, Yang Meng, Xu Baoxiang. Research on FCA-based User Profile Mining for Folksonomy. 现代图书情报技术, 2011, 27(6): 72-78
Permissions
Zhang Yunzhong, Yang Meng, Xu Baoxiang. Research on FCA-based User Profile Mining for Folksonomy. 现代图书情报技术, 2011, 27(6): 72-78
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于FCA的Folksonomy用户偏好挖掘研究
摘要
针对当前Folksonomy用户偏好挖掘方法只能在二元关系基础上挖掘用户偏好、只关注单用户偏好而忽略用户群偏好、只注重静态偏好而忽视时间推移带来的动态变化等问题,提出基于FCA的Folksonomy用户偏好挖掘模型,通过构建Folksonomy多值背景及单值背景,在概念格可视化基础上分析Folksonomy用户行为、用户偏好及其转移。该模型的提出为Folksonomy系统中的用户偏好的获取提供新思路。
关键词:
形式概念分析; 分众分类法; 用户偏好
中图分类号:G254
Research on FCA-based User Profile Mining for Folksonomy
Abstract
Aiming at the major defects of current folksonomy user profile mining methods such as mining user profile on the basis of binary relation, focus on the user profile of single-user rather than user groups, and focus on the static user profile but neglect the dynamic changes over time etc, a new FCA-based user profile mining methods for folksonomy is proposed. By means of constructing folksonomy multi-valued formal context and single-valued formal context, the user behaviors, user preferences and their transfer for folksonomy are analyzed based on the visual concept lattice which converts from formal context. The model provides a new idea for getting the user profile in folksonomy system.
Keyword:
FCA; Folksonomy; User profile
1 引 言
Folksonomy是一个分布式分类系统,由使用者个体与群体将网络资源加上标记,自由地随着社会情境来标记信息所创造出的分类结构[ 1]。Folksonomy 通过邀请用户参与到网络信息组织中,为自己感兴趣的信息添加标注,既摆脱了传统分类法受控词表的约束,保证了标注的时效性及灵活性,又可多维度地揭示信息资源的属性,同时注重“以用户为中心”,方便挖掘用户行为及用户偏好以满足用户个性化的信息需求,Folksonomy因此在Web2.0环境下倍受青睐。
用户偏好是Folksonomy用户或用户群对其所标注内容感兴趣程度的描述和度量,获取用户偏好可帮助Folksonomy系统实现用户导航、促进用户网络资源的组织管理、实现用户个性化检索及个性化等服务。Folksonomy用户偏好挖掘的研究也因其实用性而越来越被重视,文献[2]指出用户偏好模型的构建是个性化信息聚合的基础,是Web3.0环境下Folksonomy研究的重要方向。用户偏好的获取离不开对用户行为的分析,用户行为是捕捉用户偏好的前提和信息来源。
文献[3]将Folksonomy用户偏好挖掘分为单兴趣用户偏好和多兴趣用户偏好两类,后者又分为单系统多兴趣或多系统多兴趣,其中单系统多兴趣是用户偏好挖掘中最常见的情况。本文研究的问题可界定为:以用户行为分析为基础,在单系统内实现用户或用户群的多兴趣偏好挖掘。
本文通过运用FCA理论,构建出Folksonomy的形式背景及相应概念格,以可视化的视角分析用户行为并挖掘用户偏好,克服当前方法获取用户偏好的一些不足。
2 Folksonomy用户偏好挖掘研究现状
文献[4]利用维基法挖掘用户偏好,先将文档映射到描述用户兴趣的维基概念集,然后从这些概念中构建层次偏好。该方法简洁、稳定,顶层概念具有较高的精确度。但维基索引规模太大,且没有考虑用户语境。
文献[5]通过分析某用户的Personomy来识别用户的不同兴趣。该方法以网络分析技术为基础,分析某用户标记的内容,使用社区挖掘算法来获得文档群集,从中构建表示用户偏好的标签群集。
文献[6]提出一种聚类法,通过整合从Agent收集到的基于内容的偏好和用户在Folksonomy中表达的标记行为,利用聚类算法(WebDCC)以及为用户偏好专门设计的结构和程序构建用户偏好。
文献[7]以FCA为基础,先构建个人标签空间来模拟表示某用户的标签和协作资源,并将个人标签空间转换成概念格,对每个生成的描述用户兴趣的概念分别计算出权重及概念相似度等,以此为基础构建层次化的用户偏好。
文献[4]至[7]列举了目前单系统多兴趣用户偏好中几种典型的Folksonomy用户偏好挖掘方法,这些方法有着各自的优势和独特性,且在一定程度上解决了Folksonomy用户偏好的获取,但仍存在两个问题:
(1)均以二元关系(“标签-资源”或“用户-标签”)为基础进行用户偏好挖掘,尚未建立三元关系“用户-标签-资源”基础上的用户偏好挖掘;
(2)只能挖掘单个用户的偏好,尚未解决挖掘用户群偏好的问题。
3 基于FCA的Folksonomy用户偏好挖掘模型
3.1 Folksonomy与FCA的关系
FCA[ 8]是在给定数据集合基础上生成概念结构的一种数据分析方法,它强调用数学手段来表达、分析和构建客观知识,从给定领域的大量数据中抽取和生成概念,并抓取出概念与概念间的“父-子”关系,构建概念层次化结构。该方法已被广泛应用在本体论工程、信息系统开发、信息科学等诸多领域。Folksonomy是协作化标签系统中基于用户标引的数据集合,在该系统中,用户可以自由地选择术语来描述他们喜欢的网络资源(包括网页、图片、食品等)。Folksonomy通常至少由三个数据集组成:用户集、标签集和资源集。
本文认为,可利用FCA来协助进行Folksonomy中的相关数据和知识挖掘,因为两者之间存在如下关系:
(1)两者以自底向上的“聚类”机制为组织模式,为两者的结合奠定了基础;
(2)Folksonomy提供了三类数据集,但缺少有效的数据组织的方法, FCA作为有效的数据分析工具,恰能为之提供支撑;
(3)FCA可协助实现Folksonomy中的隐含知识挖掘和概念层次构建;
(4)利用FCA分析Folksonomy相关数据,须先将Folksonomy形式背景化。
3.2 Folksonomy的形式背景及其内涵
结合文献[9]和[10],本文将Folksonomy的形式化定义如下:
定义1:Folksonomy是一个4元组F:= (U, T, R, Y),其中U,T,R是有限集, Y(Y⊆U×T×R)是U,T,R之间的三元关系;U,T,R分别称作用户集、标签集和资源集,并用(u, t, r)∈Y表示用户u 对资源r标记了一个标签t。
定义2:概念换算(Conceptual Scaling)是按照某些规则,把多值背景转化成为单值背景,导出的这个单值背景的概念可认为是原多值背景的概念。显然这种换算不是唯一的,一个多值背景的概念随着概念换算的不同而不同。
定义3:一个用于多值背景的属性A的概念标尺(Conceptual Scales)是一个单值背景S:=(Oa,Aa,Ia),满足a(O)⊆Oa,标尺中的对象是属性a的各个值,标尺中的属性是单值背景中的属性。每个背景都能够当作标尺使用,形式上标尺与背景之间没有什么不同。然而,只对有着清楚的概念结构且具有实际意义的背景才使用术语“标尺”。
定义4:Folksonomy 的单值背景是一个三元组F:= (O,A,I), 其中O是对象的集合,A是属性的集合,I⊆O×A是O与A间的二元关系,(o, a)∈I表示对象o具有属性a。其中有限集U, T, R中任一项的元素都可视为对象O,剩余两项的积可视为对象的属性A。
定义5:运用概念换算及概念标尺,可以将定义1中的Folksonomy多值形式背景换算成三类单值形式背景:
FU:= (U,T×R, YU) (资源R视为标签T的属性)
FT:= (T,R×U, YT ) (用户U视为资源R的属性)
FR:= (R,U× T, YR) (标签T视为用户U的属性)
其中 (u, (t, r))∈YU⇔(t, (r,u))∈YT⇔ (r, (u, t))∈YR⇔(u, t, r)∈Y。
3.3 基于FCA的Folksonomy用户偏好挖掘模型
为解决本文提出的问题,在定义Folksonomy形式背景的基础上,提出了新的基于FCA的Folksonomy用户偏好挖掘模型,如图1所示:
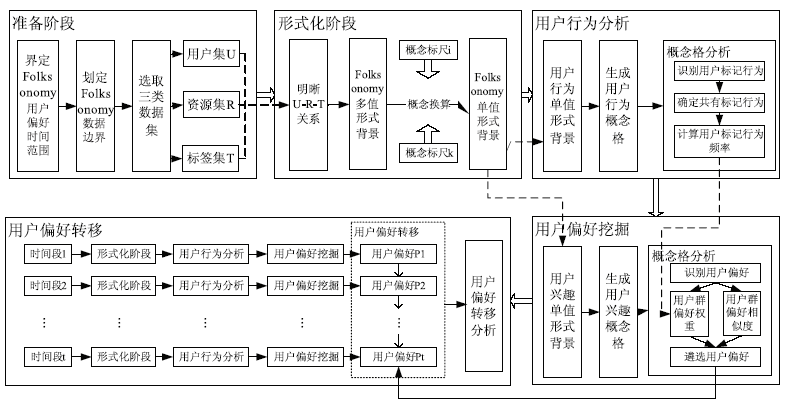 | 图1 基于FCA的Folksonomy用户偏好挖掘模型 |
该模型的基本原理是:首先界定Folksonomy用户偏好的时间范围及Folksonomy数据边界,整理出相应的用户集、标签集和资源集,明晰三类数据集元素之间的关系,进而构建出Folksonomy多值形式背景,通过特定的概念换算过程得出描述用户行为的单值背景,在将该单值背景转换成概念格后,在可视化基础上计算用户标记行为频率,然后通过概念换算从多值背景得出用户偏好单值背景,在对该背景概念格化的基础上,从用户-标签-资源相整合的角度挖掘出用户偏好。转换时间范围,重复上述过程,即可得出用户群在新时间范围内的用户偏好,对比不同时间范围内用户偏好的内涵及外延变化,即可分析出用户偏好的转移。
4 基于FCA的Folksonomy用户偏好挖掘过程
4.1 预处理
预处理是基于FCA的Folksonomy用户偏好挖掘的首要任务,也就是“方法模型”中的准备阶段。众所周知,用户(群)的偏好在某一段时间内会相对稳定,但其并不是一成不变的,它会随着时空的转换而更新,因此,预处理的主要任务便集中在:选择恰当的粒度,为所要研究的Folksonomy系统划定时间范围和空间范围,汇总Folksonomy系统中包含的所有数据,整理出相应的用户集U、标签集T和资源集R。
4.2 构建Folksonomy形式背景
Folksonomy形式化是运用FCA挖掘用户偏好的前提。其主要任务是逐一分析用户集U、标签集T和资源集R三个有限集中元素之间的“U-T-R”三元关系。图2是一个“U-T-R”三元关系示例:
 | 图2 一个“U-T-R”三元关系示例 |
依据图2的三元关系,结合定义1,构建目标Folksonomy系统的多值形式背景F:= (U, T, R, Y),其中U={u1,u2,u3},T={t1,t2,t3},R={r1,r2,r3},Y(Y⊆U×T×R)是U,T,R之间的三元关系。每一条“U-T-R”表示用户u 对资源r标记了一个标签t。
Folksonomy多值背景必须通过概念换算转为单值背景才可使用,且概念换算的方式多种多样,本文旨在研究Folksonomy系统中的用户行为分析和用户偏好挖掘,所以只关注两类单值背景,即:FU:= (U,T×R, YU)和FR:= (R,U×T, YR )。
4.3 用户行为分析
用户行为是用户对Folksonomy系统中的资源进行关注并为该资源添加标签的过程,体现了用户对资源感兴趣的程度,同时相同的用户行为也是判定用户标记行为频率和划分具有共同偏好的用户群的基础。
该阶段的任务是通过识别单值形式背景FU:= (U,T×R, YU)(见图3),并运用FCA-Wizard工具[ 11]将之转化成相应的概念格(见图4),在概念格可视化的基础上进行一系列的用户行为分析,具体包括:
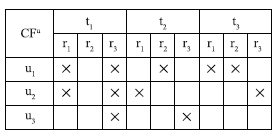 | 图3 用户行为单值背景 |
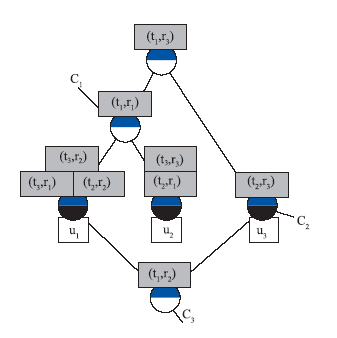 | 图4 用户行为概念格 |
(1)识别用户标记行为。概念格中的每一个节点(用Cm表示)代表的是用户(群)的一簇标记行为,即用户(群)使用标签ti标记了资源rj,节点的外延代表用户(群),节点的每一条内涵表示用户(群)的一次标记行为。例如C1的外延u1,u2构成其用户群,该用户群中用户都用标签t1标记了资源r1。
(2)确定共有标记行为。本文将外延中含有两个及以上用户的节点称为高层节点(如C1),代表用户群的标记行为,其外延是具有共同标记行为的用户群;将只有一个用户的节点称为低层节点(如C2),代表单个用户的节点标记行为;将没有用户的节点称为空节点(如C3),表示没有用户使用该节点内涵中所示的标记行为。
(3)计算用户标记行为频率。节点层次越高,用户群对其内涵所示的标记行为的共识度和认可度越高,用户使用同一标签标记同一资源的频率越高,反之亦然。本文将节点内涵所示的每一条用户标记行为频率FREtirj定义为:
FREtirj= = =  | (1) |
其中,U 

依照式(1),可计算出所有节点的属性中标记行为频率。以图4中C1内涵中的标记行为FREt1r1为例,FREt1r1=2/3=0.67。其余标记频率分别是:FREt1r3=3/3=1;FREt1r2=0/3=0;FREt3r2= FREt3r1= FREt2r2= FREt3r3= FREt2r1= FREt2r3=1/3=0.33。
(4)用户标记行为频率凸显了用户在Folksonomy中使用特定标签标记特定资源的频率和被大众认可的程度,在某种程度上反映了用户偏好。
4.4 用户偏好挖掘
Folksonomy中,标签的作用在于描述资源的某种属性,而资源是一种客观存在的实体,因而将标签视为属性,将资源视为对象,将用户使用标签标记资源看成两者之间的关系,根据FCA理论,就会生成概念,这个概念就是用户偏好。可见,用户偏好挖掘需要从单值形式背景FR:= (R,U×T, YR )入手。
该阶段的主要任务是构建单值背景FR:= (R,U×T, YR ),并用FCA-Wizard将之转化为相应的概念格,如图5和图6所示:
 | 图5 用户偏好形式背景 |
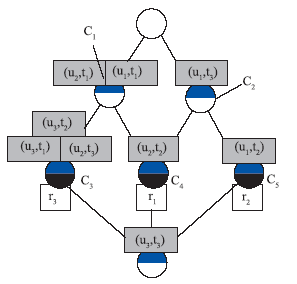 | 图6 用户偏好概念格 |
在概念格可视化的基础上进行如下详细分析:
(1)识别用户偏好。除不含外延的空节点外,概念格中的每一个节点(Cn)代表了用户的一种偏好,节点的外延表示用户感兴趣的资源(集),节点的内涵表示不同用户对该资源(集)的标记行为。
(2)计算用户偏好权重(PI)。用户偏好权重的计算,可借鉴文档检索中经典的TF/IDF权重原理,理由如下:
①每个用户偏好中包含的每一个“用户-标签-资源”组代表了一次用户标记行为,而用户标记行为频率恰能反映用户使用标签ti描述资源rj的频率,即代表偏好节点的TF特征。一个偏好节点可能含有若干个标记行为和包含若干项资源(即资源集),针对只有一项资源的偏好节点,用户使用标签tq(q∈i)标引该资源的频率最高,就反映了节点Cn的用户偏好的TF特征;针对有多项资源的偏好节点,所有资源rj标记行为频率最大值之和就反映了节点Cn的用户偏好的TF特征。
②每个偏好节点拥有的子节点数越多,偏好的普遍重要性就越高,因此本文认为偏好节点的子节点数反映了偏好的IDF特征。
用户偏好权重(PI)是其TF特征与IDF特征之积,并将之定义为:
PI =TF
=TF 

其中,FREtirj 



图6中,以偏好节点C1和C3的用户偏好权重为例,PI(C1)= TF(FREt1r3+ FREt1r1)×IDF(ln(7/2))=(1+0.33)×1.253=1.70,PI(C3)= TF(MAX{1,0.33,0.33})×IDF(ln(7/1))=1×1.95=1.95。同理,其余偏好节点的偏好权重是:PI(C2)=0.84,PI(C4)=1.31,PI(C5)=0.64。
(3)计算偏好相似度(PS)。若概念格中两个概念节点间足够相似,则它们描述了共同或相近的用户偏好,为避免这种现象,就需要计算概念相似度。借鉴Jaccard相似系数,本文采取用两个概念外延集合的交集与并集比率的方式来计算,公式如下:
PS = =  | (3) |
若PS超过一个既定的阈值,就判定两个节点表达的用户偏好是足够相似的,一般将偏好节点的阈值设置为0.7。
根据概念相似度计算公式,图6中,PS(C1, C2)=1/3=0.33,PS(C1, C3)=1/2=0.5,PS(C1, C4)=1/2=0.5,PS(C1, C5)=0/3=0,PS(C2, C3)=0/3=0,PS(C2, C4) =1/2=0.5,PS(C2, C5) =1/2=0.5,PS(C3, C4) =0/2=0,PS(C3, C5) =0/2=0,PS(C4, C5) =0/2=0。
(4)选取用户偏好。在所有的偏好节点中,选择偏好节点PI最高且与其他节点的PS值不超过阈值,确立为该时段中Folksonomy用户偏好。
图6中PI排序为:PI 




4.5 用户偏好转移
选取不同的时段,重复上述工作,就可以得出不同时期Folksonomy系统的用户偏好。分析新偏好中所包含的用户、标签和资源,与前一阶段进行对比,就可找出用户偏好转移的具体方面和详细原因。
5 结果及讨论
根据实验结果,节点C3和节点C1为偏好节点,从节点C3中可以看出,用户u1、u2、u3都用标签t1标引了资源r3,形成了用户群的偏好;从节点C1中可以看出,用户u1、u2都用标签t1标引了资源r1、r3,形成了用户群对资源集的偏好。因此,在该Folksonomy系统中,所有用户均偏好和认可使用标签t1标引资源r3;绝大多用户形成的用户群偏好和认可使用标签t1标引资源r1、r3,且认为资源r1、r3是同类资源。
通过前述研究过程的具体验证,可以看出本研究提出的基于FCA的Folksonomy用户偏好挖掘模型完全具备可行性、合理性和易用性,且有如下优点:
(1)从用户行为分析的基础上去挖掘用户偏好,较其他方法更具科学性和合理性;
(2)从“用户-标签-资源”的三元关系出发对用户偏好进行了挖掘,解决了其他方法依据“标签-资源”或“用户-标签”的二元关系用户偏好挖掘的局限性,使得结果更全面、更科学;
(3)不仅能解决其他方法对单一用户的偏好挖掘的问题,更能解决对用户群的偏好挖掘难题。
该模型也存在着一定的局限性,在计算用户偏好权重时,该模型应用文档检索中的TF/IDF原理来表达用户偏好权重,这种应用假设用户偏好的权重体现出TF特征和IDF特征,故而与文档检索权重确立的原理相同,在操作上具有相似性,但实质上两者仍然有一定的差异性。
6 结 语
Folksonomy用户行为分析及用户偏好挖掘的相关研究随着Folksonomy的不断推广而越来越被国内外学者关注和接受,同时也出现了一系列的Folksonomy用户偏好挖掘方法,这些方法有着各自的优势和独特性,但同时也存在只侧重标签而忽视资源的内容,只关注单用户偏好而忽略用户群偏好,只注重静态偏好而忽视时间推移带来的动态变化等弊端。本文提出了一种基于FCA的Folksonomy用户偏好挖掘方法,通过构建Folksonomy多值背景及单值背景,利用概念格分析Folksonomy用户行为及用户偏好,在一定程度上解决了当前方法存在的上述典型问题,具有创新性和启发性。限于时间和精力,本文只研究了单系统多兴趣用户偏好挖掘,针对多系统多兴趣用户偏好挖掘将是本文后续的研究方向。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|