
{kind=link}
关联数据中关系发现的可视化实践
引用本文
洪娜, 钱庆, 范炜, 方安, 王军辉. 关联数据中关系发现的可视化实践. 现代图书情报技术, 2013, 29(2): 11-17
Hong Na, Qian Qing, Fan Wei, Fang An, Wang Junhui. Visualization Implementation of Relation Discovery Based on Linked Data. New Technology of Library and Information Service, 2013, 29(2): 11-17
Permissions
Hong Na, Qian Qing, Fan Wei, Fang An, Wang Junhui. Visualization Implementation of Relation Discovery Based on Linked Data. New Technology of Library and Information Service, 2013, 29(2): 11-17
关联数据中关系发现的可视化实践
摘要
基于关联数据开展关系发现的可视化实践研究:对当前的RDF可视化工具进行调研,从多种角度进行对比分析;选取生物医学作为分析领域,利用RelFinder实现基于生物医学关联数据的关系发现系统,并讨论系统存在的不足及未来的研究方向。
关键词:
关联数据; 关系发现; 交互式; RDF; 可视化
Visualization Implementation of Relation Discovery Based on Linked Data
Abstract
This article implements a visualization exploration and research of relation discovery based on linked data. The authors investigate current RDF visualization tools and compare them in multiple views, choose kinds of biomedical datasets to construct biomedical linked data and apply RelFinder to implement a biomedical semantic relation discovery system. At last, the insufficiency of this system and the future research direction are discussed.
Keyword:
Linked data; Relation discovery; Interactive; RDF; Visualization
1 引 言
传统的知识发现主要基于数据库和文本进行挖掘,KDD(Knowledge Discovery in Database)和文本挖掘的一系列技术进展不断推进着知识发现的研究和应用,然而在当前的数据库或文本中发现两个对象间的关系面临多重困难,主要体现在:术语和实体识别的不精确性、术语的多含义、关系识别的误差和丢失,因此许多研究者开始转换视角,用语义控制资源质量,从资源整合的角度开展关系发现,试图克服当前关系发现面临的上述困难。由此,从关联数据中开展关系发现的研究思路被提出。
遵循关联数据的原则,知识对象在细粒度层次被进一步组织起来,通过RDF结构构建对象之间的关系,将关系发现过程和结果进行可视化展示是辅助发现异构资源之间的联系和隐含知识的有效途径。关系可视化将每一个对象标识成单一节点可有效避免展示上的重复,不仅揭示对象之间的关系,而且还揭示中间对象之间的关系,关系可视化加强了用户的理解,特别是便于理解关系中的关系。因此,本文基于可视化工具RelFinder,设计了面向生物医学领域的关系发现系统,RelFinder能够抽取数据集中给定的对象,并可视化它们之间的关系,支持这些关系的交互式探索。系统试图通过关系发现,识别与疾病相关的基因和SNP(单核苷酸多态性)信息,以及它们之间的关联路径,为疾病、基因、SNP相关性研究的生物医学实验提供疾病候选基因或候选SNP样本,减少生物医学实验投入的成本。
2 RDF可视化研究进展
在当前的研究中,很多工具软件被设计用于浏览和编辑RDF数据文件,例如Progété、OntoEdit、RDF Instance Creator(RIC)等。然而大多数基于文本环境的软件不能应用于数量较大的数据集并使之便于理解和浏览。本文展示的RDF数据是包含大规模数据内容的关联数据资源,需要能够连接成千上万的实例与属性。因此选取恰当的可视化工具来浏览RDF显得非常必要,可以使浏览者高效地理解数据间复杂的内部结构。
2.1 典型RDF可视化工具
目前具有代表性的RDF可视化工具有:
(1)RelFinder[ 1].
在RDF可视化工具方面,RelFinder是最有代表性的成果之一。RelFinder的前身是Lehmann等[ 2]开发的一种对象关系发现工具DBpedia Relationship Finder,其最初的设计目的是基于DBpediaDBpedia.http://dbpedia.org的大量数据,通过探测用户关注对象之间关系的方式来为用户提供一个浏览DBpedia的可视化接口,该工具也可作为用户浏览大量RDF实例数据时的交互式用户接口,之后被多次改进被命名为RelFinder,并广泛应用于其他大量的关联数据和RDF数据集中。RelFinder主要由Philipp Heim(TRUMPF Group)、 Germany Steffen Lohmann (DEI Laboratory, Universidad Carlos III de Madrid, Spain)和Timo Stegemann(University of Duisburg-Essen, Germany)开发,是以开源架构Adobe Flex为基础,用动态视图展示资源间的关系,简单生动且直观,方便使用和操作,高亮和过滤功能支持使用者对关系视图做整体和局部的分析。
(2)Graphviz[ 3].
Graphviz是一款基于DOT语言的开源可视化软件。DOT语言是一种文本图形描述语言。它的描述方法简单直观,易于被计算机和人理解。Graphviz同时具有网络与交互式可操作界面、辅助绘图工具、函数库,并且适用于多种语言。许多应用软件甚至商业软件都集成了Graphviz,例如BioGrapher[ 4]、IdeaTree[ 5]等。在实际运用中,Graphviz的数据往往由外界提供,但它自身也能够利用文本或图形编辑器手工创建与编辑数据。
(3)RDF Gravity[ 6].
RDF Gravity 是一款基于JUNG Graph(Java Universal Network/Graph Framework)接口的面向RDF/OWL数据集的图形可视化工具软件。界面简洁,功能丰富强大,能够满足对数据集进行创建与分析的大多数要求。RDF Gravity 具有图形可视化与导航功能,能够对RDF文件进行局部、全局或者自定义浏览;同时具有全文本查询功能,支持RDQL查询语句和多文件可视化功能。
(4)RDFViz++[ 7].
对于RDF可视化而言,最重要的因素莫过于文件的大小和复杂程度,大多数RDF可视化软件的工具使用单一的算法来表现不同的对象,RDFViz++则可以克服这个缺点。与其他可视化软件仅具有单一的图像风格不同,RDFViz++融合了三种先进的可视化技术,吸取每一种的优势。RDFViz++提供多种图示布局,即使其提供的所有布局方式都不令人满意,用户也可以执行随机的图示布局算法进行布局,直到最后的结果满意为止。
(5)Gruff[ 8].
Gruff 是一款比较强大的可视化RDF浏览器,致力于改善数据检索的过程,使之更加简便、易于操作。Gruff备有多样化的工具,用于图形布局、显示属性表、管理查询。它基于AllegroGraph[ 9]的交互式三元组仓储(Triple-store),可以对本地以及网络的RDF数据集进行浏览、查询、管理以及编辑。它通过节点与连线构成的可视化图形和属性表对节点信息进行展示。与众不同的是,Gruff利用不同颜色对节点与连线进行区分,较其他可视化软件来说更加方便直观。同时,Gruff有独特的图形化查询方式(Graphical Query View),用户使用该方式编辑的图形将被转换为SPARQL或Prolog,并可以对图像查询或文本查询进行储存,甚至查询结果也可以被转换为图形。
2.2 当前工具的特点分析
RelFinder针对Web Data开发,侧重于关系路径的发现,更适合于关联数据的可视化;Graphviz对输入格式的要求较高,需要将待可视化数据转换成其支持的特定DOT格式;Gruff则局限于AllegroGraph三元组仓储的数据处理,而AllegroGraph对存储的配置要求较高,不具有开源性,因此Gruff的使用受到限制。
总体来看,以上RDF可视化软件各有特点和适用领域,互有长短,对于输入输出格式、数据存储和访问方式、分析推理能力、编辑能力、图形统计、可接受数据集大小、以及查询语言等都有不同的要求。
3 关联数据与可视化方法
3.1 关联数据的图结构
关联数据是Berners-Lee[ 10]提出的一种万维网上发布数据的方式,可以看成语义Web的一种实现方式。它一般要求采用RDF数据模型,利用URI(统一资源标识符)命名数据实体,发布和部署实例数据和类数据,从而可以通过HTTP协议揭示并获取这些数据。可见,关联数据的基本原则是采用RDF数据模型将结构化的数据发布到Web上,并采用RDF链接将不同的数据源内部关联起来[ 11]。
RDF的数据模型是RDF图,RDF的基本构成是以三元组(主语Subject、谓语Predicate、宾语Object)形式存在的资源的陈述(Statement)。陈述的主语Subject通常是指向相应资源的URI,谓语Predicate是表示某一属性的URI,而宾语Object既可以是指向某一个资源的URI,也可单纯以一个文字作为属性值。因此RDF图可以被看作是有向标记图(Directed Labeled Graph),其中节点以URI或者文字值来标记,而有向边以谓语的URI来标记。每条有向边及其所连接的两个节点对应于一个RDF三元组。RDF有向标记图可以表示为[ 12]:
V={vxx∈subject(T)∪object(T)}.
E={es,p,o(s,p,o)∈T}.
lV(vx)=(x,dx) 如果x是一个文字(dx是其数据类型)
x 其他.
from(es,p,o)=vs, to(es,p,o)=vo, lE(es,p,o)=p.
其中,RDF图T是一个三元组的集合,其有向标记图表示为G=(V,E,lV,lE),其中,V是RDF图中节点的集合,E是有向边的集合,lV和lE分别是V和E上的标记函数;subject(T)表示T中所有三元组的主语的集合,object(T)表示T中所有三元组的宾语的集合。函数from()和to()给出边的起点和终点。
基于RDF图的存储结构,图中两个节点间关系发现的问题以及一个节点对应所有关系识别的问题可以被看作是图搜索的问题,图的搜索就是从图中某个顶点出发,沿着一系列边遍历图中所有的节点,且每个节点仅被访问一次。常用的图搜索算法有深度优先搜索和广度优先搜索两种。
一般的数据可视化过程,需要在实现时将数据转化成可视化工具所支持的特定格式,如XML,因此转化接口是必不可少的,大多数都是以呈现效果为目的,如要实现交互功能,对接口的转换效率等要求就非常高;与此相比,RDF图本身就是规范的有向图结构,数据的可视化直接基于图的查找方法展开,在可视化效率和交互能力上有较大的提升空间。
3.2 RDF可视化的主要实现方式
RDF可视化的主要实现方式有三种,分别是一次性展示方式、中央节点展示方式和中央图表一次性展示方式[ 13]。
(1)一次性展示方式(Display-at-once)。首先对整个RDF文件进行解析,形成一个包含所有三元组的图示。资源用方形或椭圆来表示,并用箭头从主体指向客体,与多数声明相关的资源只绘制一次,这样,相同资源之间的多元联系便可以用箭头进行表示。这种方式最大的优势在于它将RDF文件一次性完整地呈现出来。然而,当RDF文件逐渐增大时,过于复杂的资源与交错的关系使这种方式所呈现的可视化效果难以令人满意。IsaVizIsaViz.(http://www.w3.org/2001/11/IsaViz/)就是典型的一次性展示方式。
(2)中央节点展示方式(Navigational-centric),也称导航式(Navigational)。这种方式基于用户所选定的中央节点资源,将以中央节点资源作为主体的三元组进行图示。其他部分图示内容展开可以由使用者灵活地控制——每个被展示的客体节点都可以做进一步的扩展。中央节点展示方法为RDF文件可视化提供了一定的灵活性和可操作性,它可以用来处理大量更为复杂的RDF文件,并可以对所需的知识进行定向的探索。然而它的显著缺点是,在处理小型RDF文件时,无法一次性展示完整图示,而这往往是处理小型RDF文件所最需要的。RDFViz++RDFViz.(http://www.rdfviz.org/)是典型的中央节点展示方式。
(3)中央图表一次性展示方式(Centric-graph-at-once)。中央图表一次性展示是将以上两种途径进行结合:所有的三元组声明将会从随机选定或人为选定的中央节点开始被一次性展示。箭头由中央节点开始,至客体节点结束,而客体节点如果同时参与其他的三元组声明,则将会被进一步扩展。中央图表展示在一次性展示基础上的主要改进是:所有不只出现一次的资源都会在不同的三元组声明中被重复绘制。这样,不同于一次性展示,三元组之间箭头的交叉将会消除,其结果也将更加清晰易读。因此,中央图表一次性展示的方法在处理较小的RDF文件时表现出色。同时,当处理较为繁杂庞大的RDF文件时,就要求更大的空间容量和更强的处理能力。因此,中央图表一次性展示方法会将RDF文件分块,用户可以在功能板块内选择局部图表的完全展示。RDF GravityRDF Gravity.(http://semweb.salzburgresearch.at/apps/rdf-gravity/)是典型的中央图表一次性展示方式。为了更好地进行关联数据的可视化实践,笔者从不同角度对比了主要的RDF可视化工具,包括开发工具以及语言平台、应用类型、是否开源、数据输入输出格式、支持三元组仓储、交互能力等方面,对比情况如表1所示:
| 表1 RDF可视化工具基本信息对照表 |
在实际应用中,应用场景是关联数据的可视化,因此,选取的目标是能够很好揭示数据节点之间的关联的可视化工具,同时具有一定的交互能力。
以上RDF可视化工具能够支持交互的较少,只有RelFinder和Gruff具有一定的交互能力,从本文实验开展的底层数据结构、规模、生物医学关联数据的特点、软件的易用性和开源性等方面综合考虑,RelFinder在探索节点间的关系时具有较明显的优势,在效率、揭示规模、易用性上具有总体最优的可视化能力。因此,本文的实验研究基于RelFinder展开。
3.3 RelFinder的实现原理
RelFinder的关系发现过程是基于用户主导的可视化过程,简称ORVI过程[ 14],其中,O表示对象映射(Object Mapping),R表示关系发现(Relationship Search),V表示可视化(Visualization),I表示交互式探索(Interactive Exploration)。其工作过程分为4步:
(1)对象映射。在第一个阶段,每一个输入对象被映射为数据集中的唯一术语。只有在自动映射不成功(例如词的多义性)时,需要用户输入选择。理论上,用户输入的对象可以被唯一匹配到数据集中的一个无歧义的明确对象,然而,实际可能会匹配不止一个对象,后台基于一个SPARQL查询语句,返回一组围绕查找对象的术语列表,该列表按与输入对象的相关性进行排序。此时,用户需要选择一个术语为系统提交一个确切的输入对象。
(2)关系发现。关系发现的过程是指对于给定的对象,查找数据集中对象之间关系的过程。查找的总体目标是要找到尽量多的关系,因为每一个关系在特定的情境中都是有意义的。RelFinder通过RDF图形迭代查找的方法实现该过程,算法支持多种参数的限定,例如关系长度、方向、忽略的属性等。一个查询构建过程由多个SPARQL查询式组成。由于最短路径预先是不可知的,因而RelFinder查找关系的过程是迭代的,路径长度从零开始不断增长,依次迭代直到没有关系。
(3)可视化。RelFinder的可视化视图基于力导向布局(Force-directed Layout)展示,该方式虽不能完全避免重叠,但可以大大减少重叠。这一模型易于理解和实现。然而,由于画图空间有限,可视化展示的节点和边数目受到限制。因此,在被发现的关系较多且超过一定可视化表达能力的情况下,RelFinder会根据预设的排序策略对关系结果自动筛选,仅显示有限数量的关系。
(4)交互。交互功能可以引导用户发现他们最关注的关系。RelFinder提供4种类型的过滤器来支持显示关系的调整,分别是:类过滤器、关系过滤器、长度过滤器和连通性过滤器。过滤器通过标亮或去除某些元素的方式帮助用户探索图形化知识内容,有助于图中展示关系的简化,从而避免图过于杂乱。RelFinder还支持对单个对象的交互式探索。体现在:
①红线:如果一个对象节点被选中,一个红线就会标亮所有包含这个对象的路径关系。
②大头针:支持将一个关系从原图中分离出来,进行独立的分析。
③InfoBox:提供某一个具体节点的详细信息,例如一个对象的图像和简短描述。
4 基于RelFinder的生物医学关系发现实践
本文开展了基于关联数据的关系发现可视化实践研究,采用一系列语义Web技术,基于关联数据理论、方法和技术,整合了疾病、基因、单核苷酸多态SNP、PubMed文献等方面的生物医学数据,并依据关联数据的建设标准对其进行存储、管理、查询和发布,构建了可视化的数据基础。对于每一对实体或概念,通过本文搭建的可视化系统可以方便地发现它们之间的直接关系和潜在关系。在实践过程中,详细分析了RelFinder的工作机制、调用方法和源代码,对其进行了配置、汉化、调用和测试。
4.1 关联数据建设
.
基于关联数据的规范标准,系统采用Virtuoso进行底层存储,支持SPARQL查询和语义检索。在数据建设方面,系统共存储了11个数据集,分别是Disease Ontology、Diseasome、OMIM、HGNC、EntrezGene、Gene Ontology、dbSNP、HapMap、miRdSNP、PubMed、Symptom,将其中的重要关联性内容构建了22 089 203个三元组,存储的部分数据集及三元组数如表2所示:
| 表2 数据来源及三元组统计 |
系统构建了14对数据集之间共12 528 322个映射关系,以三元组的形式存储。系统建设的部分映射关系如表3所示:
| 表3 主要映射关系 |
4.2 RelFinder配置
基于RelFinder的用户最小化努力原则,在RDF资源上使用RelFinder需要进行以下设置[ 15]:
(1)运行环境设置。由于RelFinder是一个基于Flex Adobe Flex–Open Source Framework.(http://www.adobe.com/products/flex)技术的可视化工具,客户端采用Flex及SpringGraph。Flex支持用户和接口之间的基本交互功能,而SpringGraph支持将该网络图及其高复杂度的交互特征无缝集成到应用中。因此,RelFinder在浏览器上运行必须安装Flash Player插件。
(2)config.xml文件配置。RelFinder在不同的RDF仓储系统中均可应用,主要通过配置任意SPARQL端点的方式来加载RDF数据资源,由于SPARQL查询式是在客户端生成,与服务器端和资源相对独立。服务器端采用一系列简单的PHP脚本来实现客户端和SPARQL端点之间SPARQL查询的提交和结果集返回。运行RelFinder仅需修改config.xml中的SPARQL端点,如本地存储Virtuoso的SPARQL端点http://localhost:8890,配置文件中endpoint参数需要配置成:<endpointURI>http://localhost:8890</endpointURI>。
config.xml文件中还可以进行以下配置:设置SPARQL Filter,过滤掉特定的对象、属性或结构关系,排除不重要关系的干扰,以便探索发现有效的关系;设定返回关系的最大长度,从而使布局更简洁等。
4.3 可视化实例与分析
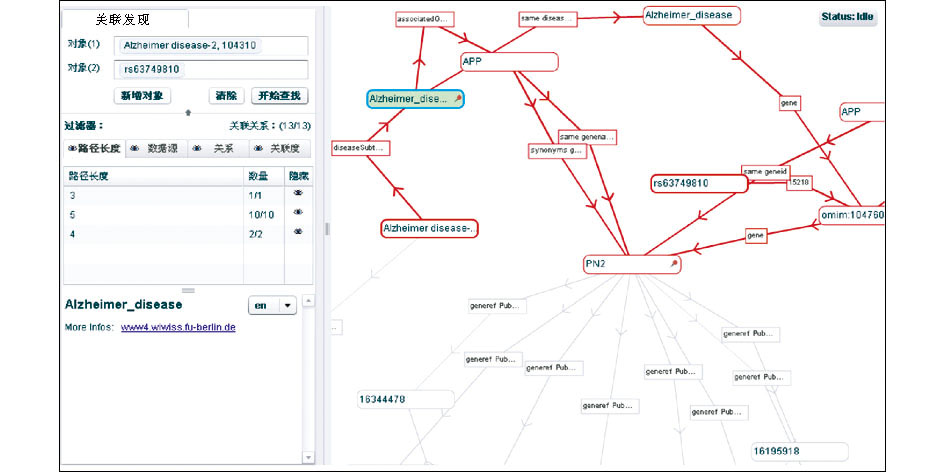
基于以上数据和工具开展语义关系可视化探索的实验,以常见的复杂疾病阿尔茨海默病为例,分析其在关联数据库中与某一具体单核苷酸多态SNP的关系。以阿尔茨海默病Alzheimer disease-2, 104310和单核苷酸多态SNP rs63750643的关系为例,关系发现情况如图1所示:
 | 图1 关联可视化 |
可以发现,Alzheimer disease-2, 104310和rs63750643有6条潜在的关系,其中的两条路径三元组如下:
(1)<Alzheimer disease-2, 104310><disease_subtype><Alzheimer Disease><Alzheimer Disease><associated_gene><APP>
<APP><synonyms_gene><PN2>
<APP><same_genename><PN2>
<Omim:104760><gene><PN2>
<Omim:104760><same_gene><entrenzgene:351>
<entrenzgene:351><allelic_number:15324><rs63750643>
<entrenzgene:351><symbol><APP>
<entrenzgene:351><synonym><PN2>
(2)<Alzheimer disease-2, 104310><associated_gene>
<APOE>
<APOE><same_gene><LPG>
<LPG><pubmed_id><16344478>
<PN2><pubmed_id><16344478>
<Omim:104760><gene><PN2>
<Omim:104760><same_gene><entrenzgene:351>
<entrenzgene:351><allelic_number:15324><rs63750643>
<entrenzgene:351><symbol><APP>
<entrenzgene:351><synonym><PN2>
上述路径三元组的含义是:
(1)Alzheimer disease-2, 104310的上位疾病概念是Alzheimer Disease,Alzheimer Disease的相关基因是APP,APP的近似基因是PN2,PN2在基因的15324位点发生变异,多态性标记为rs63750643。
(2)Alzheimer disease-2, 104310的相关基因是APOE,APOE与LPG属于相同基因,LPG和PN2共现于同一篇PubMed文献,PMID为16344478,PN2在基因的15324位点发生变异,多态性标记为rs63750643。
由此,可以假设Alzheimer disease-2, 104310 和rs63750643有潜在的关系,推荐进入下一步的生物学实验验证。
5 结 语
本文探讨了关联数据中关系发现的方法、思路和系统实现,系统整合了大规模的生物医学数据集并通过RelFinder进行可视化实践,能够有效发现跨数据集的复杂关系,为生物医学潜在知识关联的发现做初步探索。然而,本文的研究和系统开发还存在一定的不足,如关联数据建设的内容深度、数量还不够,需进一步精细化和规模化;RelFinder本身也存在一定的局限性,通过迭代搜索不断增加目标链接的数量和长度的方式降低了搜索性能,系统并不能发现所有的关系,只能发现单项关系,多向关系的处理目前还不能解决。因此,在当前研究的基础上,还将继续改进关联可视化的实现方法与效果。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|