{kind=link}
关联数据环境下数据溯源描述语言的比较研究
引用本文
倪静, 孟宪学. 关联数据环境下数据溯源描述语言的比较研究. 现代图书情报技术, 2013, 29(2): 18-23
Ni Jing, Meng Xianxue. The Comparative Analysis of Major Provenance Vocabularies in Linked Data Environment. New Technology of Library and Information Service, 2013, 29(2): 18-23
Permissions
Ni Jing, Meng Xianxue. The Comparative Analysis of Major Provenance Vocabularies in Linked Data Environment. New Technology of Library and Information Service, 2013, 29(2): 18-23
关联数据环境下数据溯源描述语言的比较研究
摘要
介绍目前国外主要的数据溯源描述语言:DCMI术语、OPM-O、PV、VoIDP、PROV-O, 从来源和目的、资源描述角度、主要服务对象和解决的问题、标注方式、词表结构等方面分别对以上数据溯源描述语言进行比较分析, 以期为国内外学者在关联数据环境下进行溯源描述语言的选择和消费提供帮助。
关键词:
数据溯源; DCMI术语; OPM-O; PV; VoIDP; PROV-O
The Comparative Analysis of Major Provenance Vocabularies in Linked Data Environment
Abstract
This paper discusses the provenance vocabularies: DCMI Term, OPM-O, PV, VoIDP and PROV-O, then separately compares and analyzes the similarities and differences between them from five dimensions : aim, description, service providing, annatation method and vocabulary structure.The authors aim to enable the provenance research community to move towards the adoption and consumption of provenance vocabularies in linked data environment.
Keyword:
Data provenance; DCMI term; OPM-O; PV; VoIDP; PROV-O
1 引 言
关联数据提供了以URI为约束的RDF模型在网上显示、连接和共享信息的方法。这种开放数据源的出现, 打破了数据仓储之间的障碍, 以丰富的数据为人们提供应用和服务。但是, 关联数据发布的特点在于:数量增长快, 草根式发布, 质量参差不齐; 分布式发布下, 连接的复用越来越普遍; 动态更新会进一步导致数据的不一致性。由此可见追溯原始数据、记录数据历史的重要性。众所周知:作为Wikipedia的关联数据集、最大的关联数据集——DBpedia, 由于Wikipedia允许被任何一个人来编辑, 因此辨别这些数据的来源与认定质量非常困难。Berners-Lee[ 1]在提到“Oh yeah?”按钮时, 曾提及数据面临的“溯源问题”, 继而提出了信任的问题。
Provenance译作“溯源”、“起源”, 数据溯源也称为“数据族系” (Data Lineage)、“数据系谱” (Data Pedigree)、
“数据来源” (Data Derivation)等。按照W3C[ 2]的定义“一个资源的溯源是描述实体和所涉及的生产和发送过程或以其他方式影响该资源的记录。溯源提供评估真实性、得到信任、以及允许可重复性的重要基础。溯源声明是上下文相关的元数据的形式, 按照自己的溯源, 溯源声明可以成为自己的重要记录。”.
国外对数据溯源的研究会议和组织项目很多[ 3, 4, 5, 6], 特别是W3C于2009 年9月专门开设了W3C Provenance Incubator Group[ 7]来研究语义网环境下的数据溯源, 设立了“为语义技术、语义开发、语义标准的数据溯源研究提供最新技术和发展规则”的目标。2011年, 《Journal of Web Semantics》发行了“Using Provenance in the Semantic Web”为主题的专刊, 讨论语义网环境下数据溯源的一系列问题, 这从一个侧面说明数据溯源是当前语义网领域研究的重点之一。国内在这方面的研究十分有限[ 8], 与国外尚存在较大的差距。
本文选取目前在关联数据环境下应用较多的数据溯源模型和术语集:DCMI术语 (DCMI Metadata Terms)[ 9]、OPM-O (Open Provenance Model Ontology)[ 10]、PV (Provenance Vocabulary)[ 11]、VoID (Vocabulary of Interlinked Datasets)[ 12]、VoIDP (Vocabulary of Interlinked Datasets Provenance)[ 13]、PROV-O (PROV-Ontology)[ 14], 从描述语言模型的来源及目的、描述角度、可解决的问题及词表结构特征等方面分别进行了比较分析, 以期为正在蓬勃发展的关联数据在可靠和信任的基础上发展提供参考。
2 目前主要的溯源模型
2.1 DCMI元数据术语
DC元数据组织提出的核心元数据词汇, 通常指DC。从1995年起, 原始的数据集包含15个广义定义的元素仍在使用。核心元素没有具体的使用范围限制, 使用对象可任意取值 (即任何客体都可以作为适用对象)。这些核心元素已经被扩展、提炼并且加入了新的元素。扩展的词汇表指“DCMI元数据术语”, 包括55个属性 (涵盖了核心元数据, 增加了其他元素和元素限定)。
目前, DCMI组织认为DC核心元素已经过时, 应优先使用DCMI元数据术语[ 15]。这两种元素有不同的域名。核心元素集往往用dc作为前缀, 而采用dct (或determs)作为新出现的DCMI元素集的前缀。
DCMI元数据溯源任务工作组 (DCMI Metadata Provenance Task Group)创立于2009年, 其工作目标是定义一个允许构建描述的陈述或描述集断言的应用大纲。该应用大纲应当建立一个所需的数据元素共享的模型以便圆满描述元数据表达的集合, 来集中导入、访问、使用和发布所述事实的有关质量、权力、进度安排、数据源类型、信任情况等[ 15]。
由于元数据溯源信息本身是元数据, 它应当可以类似的方式再度发布并且配合使用元数据陈述或其描述的元数据集。任务工作组也负责创建使用说明, 介绍以足够鲁棒的方式链接“内容”元数据集合与其溯源元数据, 以避免多次重复的发布过程。
该工作组于2012年12月11日发布工作草案[ 15], 将DCMI元素集与PROV进行映射, 将DCMI元数据术语分为描述性元数据和溯源性元数据, 如表1所示:
| 表1 DCMI元数据术语的分类 |
表1中没有列入一个特殊的术语:Provenance。这一术语被定义为“自创建以来资源的所有权和保管权方面状态的任何变化, 对于真实性、完整性和解释具有重大意义”。这一定义与传统的艺术作品溯源的定义一致, 尽管与溯源相关, 但可能与大多数的具体指明资源溯源某一方面的DCMI元数据术语重合, 因而未被列入。
2.2 OPM模型
.
OPM溯源模型的提出最初是针对科学工作流, W3C选择这一模型作为指定的标准模型[ 16], 并将其他模型 (如:针对关联数据的Provenance Vocabulary模型)与它进行了映射。选择OPM的动机是:
(1)这是一个包含了溯源各个方面的通用的和广义的模型;
(2)它经过多年持续发展, 代表了业内的努力, 经过多次讨论、实践应用和多个版本修改;
(3)许多团队 (包括)正在或已经将自己的词汇与OPM映射。
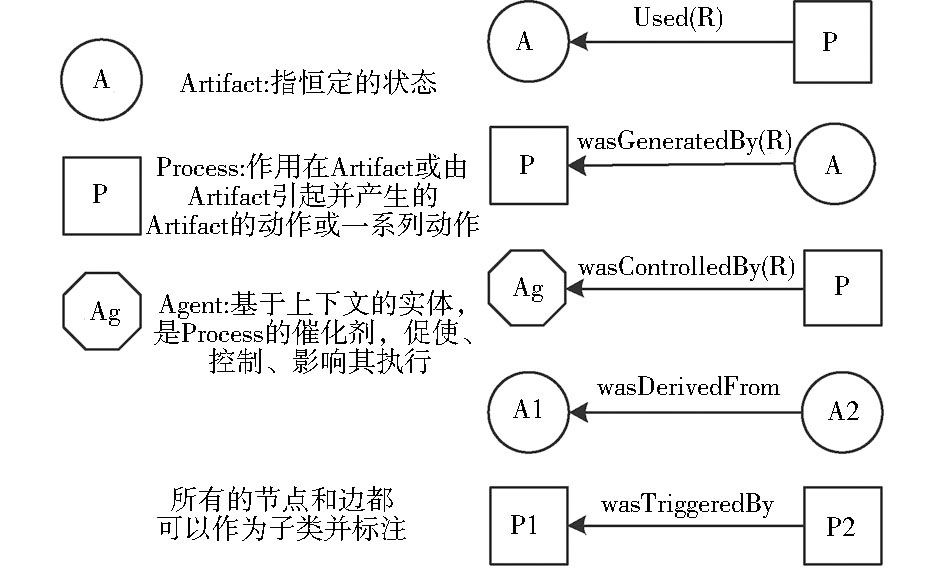 | 图1 OPM标注图例[ 16] |
OPM标注如图1所示, 主要由三个基本概念构成, 即 Artifact (what things happen to)、Process (things happening)和Agent (what controls things happening)。与此三个概念相关的属性包括:used (Role) 属性说明处理过程中使用了哪些状态实体, was generated by (Role)属性说明某个状态实体的产生是由哪个处理引起的, 两者是互逆的关系; was controlled by (Role)属性说明该处理被哪个代理实体控制; was derived from属性说明状态实体之间的关系; was triggered by属性说明处理之间的因果关系。
OPM这一溯源模型的设计主要基于以下需求:通过共享的溯源模型兼容层, 允许溯源信息在不同的系统之间交换; 允许开发者创建和共享操作在这一溯源模型下的工具; 以周密的、与技术无关的方式定义溯源; 支持任何“事物”的数字化溯源表达, 无论它是否由计算机系统产生; 允许多种层次上的描述共存; 定义一个规则的核心集合, 该集合用于识别基于溯源表达的有效推理。
2.3 PV模型
Hartig等[ 11]提出将具有质量概念的关联数据发布于网上, 将溯源信息集成到关联数据中, 并解释了如何利用这些信息查找过时的信息, 并提出建议, 即:将关联数据发布到Web时以相同的方式生成关联数据的溯源信息, 提出一个词汇表Provenance Vocabulary[ 11],
| 表2 OPM本体的类和属性 |
基于该词表, 发布者可以描述数据溯源。在获取溯源词汇表中的元数据后, 数据集的溯源信息存储在VoID表中, VoID表基于二维:数据创建和数据访问。
Provenance Vocabulary由三部分组成:通用词汇、数据创建词汇和数据访问词汇。通用词汇的类是Actor (执行者)、Execution (执行)、Artifact (执行结果)、DataItem (数据条目, 是执行结果的子类)、File (文件, 也是执行结果的子类)等, 属性包括 yieldedBy (由谁产生)、performedBy (由谁执行)、performedAt (在何时执行)、operatedBy (由谁执行)等。使用通用词汇, 可以描述溯源信息如:Artifact (某个执行结果)是一个Execution而yieldedBy, 并且performedAt某一时间performedBy一个Actor。数据创建类是DataCreation、CreationGuideline, 属性是CreatedBy、usedGuideline、usedData等。数据访问类包括DataPublisher、DataProvidingService、DataAccess, 属性是usedBy、retrievedBy、accessedService和accessedResource。
2.4 VoIDP
VoID (Vocabulary of Interlinked Datasets)[ 12]是一个 RDF Schema 词表, 是描述关联数据集的元数据, 作为关联数据集和用户 (人或机器)之间的桥梁, 它包含数据发现、数据目录和数据存档, 用于帮助用户发现如 DBpedia这样的海量关联数据集中的可用信息。VoID本身不是用于起源信息描述的, 但却是数据集的起源信息元数据表达和存储的基础。
VoID中有两个核心类, 其中最基本的概念是dataset。一个dataset是由一个发布者发布、维护和组合的RDF三元组集。RDF图是纯粹的数学结构, 与RDF图不同, 术语dataset具有社会的维度:把一个数据集看作是有一定意义的三元组集合, 它有一定的主题, 来源于特定的资源或处理, 完成某一项服务或由某个特定管理员组合的集合。而且, 一般而言, 一个数据集可以在网上通过可解析的HTTP URIs或一个SPARQL Endpoint访问, 它包含足够多的三元组, 具有简明而综合的意义。
由于大多数的数据集描述了定义好的实体集, 因此数据集也可以看作是某些实体集的描述集合, 它们通常共享一个共同的URI前缀 (如:http://dbpedia.org/resource/)。
Linkset是两个数据集之间RDF链接的集合。Linkset是RDF三元组集合, 该三元组所有的主语在一个集合, 所有的宾语在另外的集合, 即主语和宾语位于不同的集合。RDF链接通常具有owl:sameAs属性 (谓语), 但是其他任何属性也可以成为RDF链接的谓语。VoID:Linkset是 VoID:Dataset的子集。
Omitola等[ 13]讨论了将溯源信息应用到关联数据的问题并定义了VoIDP (Vocabulary of Interlinked Datasets Provenance)词汇表。VoIDP是一个轻量级的溯源词汇表, 它是VoID词汇表的延伸, 在表达和存储上均沿用了VoID的方式, 可使发布者在发布时添加溯源元数据信息、描述其关联数据集的起源信息。VoIDP可以用来具体指明VoID文档中的溯源事件, 也可以单独使用具体指明数据条目中的溯源事件。VoIDP涉及的类和属性如表3所示:
| 表3 VoIDP的类与属性[ 13] |
2.5 PROV-O
众多的词表研究形成了词表的海洋, W3C除了讨论模型的映射之外, 正在讨论形成一个概要的溯源本体:PROV本体 (即PROV-O)。PROV本体定义了使用W3C OWL2 网络本体语言的PROV数据模型 (PROV Data Model)的规范模型。该规范描述了组成PROV本体的类、属性以及用户权限限定集。该本体规范提供了在不同领域中使用PROV本体表达、交换和整合溯源信息的起源应用的实施基础。
PROV本体类和属性不仅被定义为能直接用来表示起源信息, 而且能够专门用于各个领域内的特殊应用起源细节的建模。因此, PROV本体有望直接应用, 同时作为创建特定领域起源本体的参考模型, 并且为互操作的起源建模奠定基础。
依照所需要以及想要在其起源信息中包含多少细节, PROV-O用户可能只需要用到整个本体的一部分。据此, 将术语分为三类:起点术语、扩展术语、修饰性术语, 以渐增的方式引入本体。
起点的类和属性是其余两个本体的基础, 这些术语用来创建简单的起源描述。扩展的类和属性提供与起点本体建立相互关系的类和属性。与上述起点本体的类与属性的应用相似, 扩展的类和属性大多为上述类与属性的子类和子属性。修饰性类与本体提供了与上述两类本体属性的二元关系 (即非此即彼的关系)。尽管直接以二元断言的形式应用上述两类本体, 这类本体中的术语的应用采取了与上述两类本体不同的模式。该类本体的术语用来提供二元关系的附加属性, 该模式允许用户提供前两类本体中所没有描述的详尽细节。
3 比较分析
表4对几种词汇表在来源和目的、资源描述角度、主要服务对象和解决的问题、标注方式、词表结构等方面进行了比较。
| 表4 数据溯源描述语言的比较 |
(1)来源和目的的比较
DCMI元数据术语源于网上信息查询, 其目的是建立一套描述网络电子文献的方法, 以便网络信息检索; OPM-O源于工作流, 目的是在不同系统之间交换起源信息; PV源于关联数据的发布和查询, 目的是将关联数据发布到Web, 同时以相同的方式生成关联数据的起源信息; VoID作为发布和使用关联数据集的桥梁, 是描述关联数据集的元数据, 目的是数据发现、数据目录和数据存档; VoIDP是VoID词汇表的延伸, 可使发布者描述其关联数据集的溯源信息, 使资源关系发现和使用更容易, 提供更可信的资源推荐; PROV-O用于表达和交换在不同的系统和不同语境下产生的的溯源信息, 也可以用于创建新的类和属性, 为基于不同应用和不同领域的起源信息建模。
(2)资源描述角度的比较
DCMI没有描述资源之间的动态影响关系, 侧重于静态关系的描述; OPM-O是通用的标注元素, 从状态、代理和处理三个方面提供灵活的起源细节描述; PV遵循了OPM, 抽象描述, 轻量级, 从创建和访问两个角度构建元数据; VoID基于DC元数据表达通用的元数据、访问元数据、结构化元数据, 并且连接数据集; VoIDP主要补充了起源元数据; 而PROV-O基于OPM建立, 能够表达复杂的溯源关系, 应用范围广, 它以渐增的方式引入本体, 使用者可根据需要选择。
(3)主要服务对象和解决的问题比较
DCMI元数据术语和OPM提出比较早, 重点在于为数据发布者提供表述其数据起源的信息, 其他4种描述词汇均出现在关联数据环境下, 不仅着眼于数据发布, 而且充分考虑了数据消费者的服务。
DCMI元数据术语能够回答“谁、什么时候、怎样影响了哪些资源的变化?” ; OPM-O支持任何“事物”的数字化起源表述; PV能够解决“如何消费这些信息, 如何查找过时的信息?”的问题; VoID的重点是“对于特定的属性集, 哪些资源符合要求?哪里可以找到这些资源?”, 用于帮助用户发现如DBpedia这样的海量关联数据集中的可用信息; VoIDP具体指明“一条数据是何时产生的?如何产生的?用过什么数据?谁操作的?”; PROV-O和PROV-AQ[ 17]以及PROV-DM[ 18]一起, 形成一个特定领域中应用程序的起源信息交换和管理的框架。
(4)标注方式的比较
标注方式主要有两类:一类是基于RDF/RDFS, 另一类是OWL/OWL2。RDF/RDFS标注的特点是:表示建模原语涉及以类型层次组织起来的词汇, 包括子类关系和属性关系、定义域和值域限定以及类实例。但是,属性的局部辖域、类不相交性、类的布尔组合、基数约束等使其在描述表达上存在局限性。自从2004年起OWL就成为W3C推荐的用于对本体建模的一个标准,其设计的核心在于要在语言表达性和高效推理之间找到合理的平衡。OWL2[ 19]则使常用语句更易使用、增强了表达能力的新结构、对数据类型的扩展支持、简单的元建模能力和扩展的注释能力。
(5)词汇表结构的比较
从词表规模来看, DCMI术语、OPM-O以及PROV-O比较复杂和详细, 提供的可供描述的类和属性较多。其他词表均采用轻量级的词表, 其中PV最为简洁, VoID和VoIDP均复用了已有的词汇表。
4 结 语
这些术语表、本体之间虽然存在异构, 但它们都是对起源信息的概念化描述, 只是描述的方式和层次不同。其主要目的是将起源信息组织成一个层次清晰、可追溯的逻辑结构, 是对人类追本溯源的抽象描述。
从整体来看, DCMI元数据术语、VoID主要是基于静态描述数据属性的信息而构建的, 用来支持如指示储存位置、历史信息、资源寻找等功能。即通过描述数据的内容或特色, 进而达到协助数据检索的目的。它们与OPM以及PROV不同之处在于:OPM以及基于OPM的PV、PROV模型是基于活动对于所描述资源的影响而构建的, 也就意味着:代理并非直接与资源相关, 而是与导致资源创建的活动相关。
此外, DCMI术语的缺点是:不能回答在哪里发生了影响; PV尽管在三元组的级别上编码细粒度并且使得起源信息绑定在三元组上, 但是对于一个大的数据集而言可能包含数量十分巨大的三元组, 如果加上起源编码可能导致起源信息的量远远超过实际数据的量; VoID已有支持的平台[ 20], 并提供应用程序开发接口, 可实现由关系数据库向RDF直接映射, 同时提供基于VoID的元数据支持; VoIDP是在VoID上的延伸, 便于未来提供可信任的基于语义的数据集推荐引擎; PROV正在成为W3C起源工作组候选的推荐标准。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|