{kind=link}
基于改进C-value方法的中文术语抽取
引用本文
胡阿沛, 张静, 刘俊丽. 基于改进C-value方法的中文术语抽取. 现代图书情报技术, 2013, 29(2): 24-29
Hu Apei, Zhang Jing, Liu Junli. Chinese Term Extraction Based on Improved C-value Method. New Technology of Library and Information Service, 2013, 29(2): 24-29
Permissions
Hu Apei, Zhang Jing, Liu Junli. Chinese Term Extraction Based on Improved C-value Method. New Technology of Library and Information Service, 2013, 29(2): 24-29
基于改进C-value方法的中文术语抽取
摘要
提出一种改进C-value的术语抽取方法,即IC-value方法。利用停用词对文本进行预处理后,采用一种基于串频统计的抽取算法提取候选术语;对候选术语进行语言规则过滤;从逆文档频率、破碎子串和术语长度三个方面改进C-value方法得到IC-value方法,并用来计算候选术语的术语度。以1 000篇乙型肝炎相关论文摘要进行实证研究,结果证明IC-value方法在准确率和召回率方面都要优于C-value、TF-IDF和V-value,有较强的长术语发现能力,且识别破碎子串的效果十分明显。
关键词:
术语抽取; 串频统计; 语言规则; 术语度
Chinese Term Extraction Based on Improved C-value Method
Abstract
An improved C-value term extraction method is introduced in the paper. Firstly, the domain-specific text corpora is preprocessed by stop word list. Secondly, a term extraction algorithm based on the co-occurrence frequency of multi-character is applied to get candidate terms. Lastly, term selection is completed based on termhood computed by IC-value which is the improvement of C-value in terms of inverse document frequency, meaningless substring and term length. Empirical study is conducted based on 1 000 abstracts of articles about Hepatitis B. The results indicate the proposed IC-value is much better than C-value, TF-IDF and V-value in both precision and recall. And IC-value also has good performance in long term extraction and it is very effective in filtering meaningless substring.
Keyword:
Term extraction; Statistics of string frequency; Linguistical rules; Termhood
引 言
术语是某种语言中专门指称某一专业知识活动领域一般(具体或者抽象)理论概念的词汇单位,它是专业领域知识系统中的重要组成部分,集中体现和承载了一个学科领域的核心知识[ 1, 2]。当今科学技术高速发展,各个学科领域的新知识不断涌现,与之相应的是学科领域内术语的层出不穷。通过术语可以快速了解各个学科的发展动态,对于科学研究甚至国家发展规划具有重要意义。但是依靠人工收集不断涌现的新术语费时费力,跟不上更新速度,然而,利用计算机实现术语自动抽取可以解决这一问题。另外,术语自动抽取可以辅助编纂专业词典[ 3],同时也是信息检索、文本挖掘、机器翻译[ 4]等的重要部分。
归纳现有的术语自动抽取方法,主要分为以下4类。
(1)基于词典的方法。该方法通过与领域词典中的词匹配抽取术语,简单易行,但存在大量术语变体不易识别、术语不断更新使得领域词典不易维护等问题[ 5]。
(2)基于语言学规则的方法。该方法基于以下假设,即术语作为一个独立的语言单位,其语言结构也应该是稳固的[ 6]。也就是说术语需要满足一定的语法结构。语言学规则的方法通过构建语言规则来识别术语。但语言学规则难以发现,费时费力。同时,语言学规则识别术语时会产生大量噪音。并且不同领域的术语语言学规则也有所差异,导致可移植性差。
(3)基于统计学的方法。该方法以统计学理论为基础,利用术语在语料中的统计属性来识别其中潜在的术语。常用的一些统计学方法有串频统计[ 7]、互信息[ 8, 9]、Log-likelihood[ 10]等。统计学的方法受专业领域的限制小,移植性良好。但利用统计学方法提取术语会存在无意义的字串组合(如公共破碎字串[ 11])、常用词语(非术语)等噪音。
(4)基于机器学习的方法。如岑咏华等[ 12]利用隐马尔科夫模型进行中文术语识别研究。但这些模型是监督型的方法,需要一个适当的训练集对模型参数进行训练,而获得合适的训练集要耗费大量时间和人力,并且不同的领域训练集也不同,导致训练出来的模型可移植性差。
实际的术语抽取往往将以上方法有选择性地结合在一起。比如为了充分利用语言学方法和统计学方法两者的优点,常常使用规则与统计相结合的方法。
本文使用统计与语言规则结合的方法获取候选术语集,并提出一种改进的C-value方法,即IC-value方法,来计算候选术语的术语度值。利用停用词表对文本进行预处理,在此基础上,采用一种串频统计的方法提取文本中的重复字符串,把这些字符串作为候选术语;采取逆向的方法,利用候选术语的词性将一些明显不能作为术语的候选术语过滤掉;从逆文档频率、公共破碎子串和术语长度三个方面改进了Frantzi等[ 13]提出的C-value方法,用于计算候选术语的术语度(Termhood),并取一定的阈值过滤候选术语。该方法既不需要专业领域的词典,也不需要训练模型和总结语法规则。术语抽取流程如图1所示:
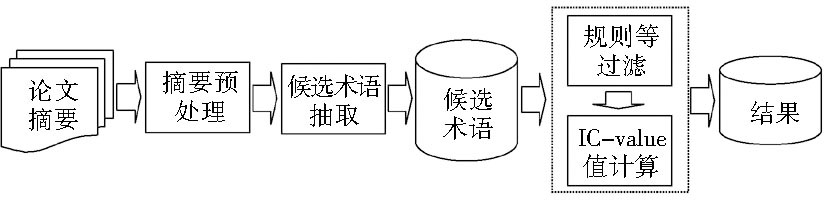 | 图1 术语抽取流程 |
2 候选术语的获取
首先利用停用词表预处理文本,这样可以提高术语识别的效率和正确率。之后,采用一种串频统计的方法提取文本中的重复字符串作为候选术语。
2.1 停用词选取
本文选取乙型肝炎相关论文的摘要作为实验数据。从互联网上获得一般停用词[ 14];通过阅读50篇论文摘要,人工确定与该领域相关的停用词,同时剔除一些与该领域无关的一般停用词。由于医学文献的特殊性,有大量缩写和其他非中文字符,因此本文也将字母和阿拉伯数字作为停用词使用。
2.2 基于串频统计的候选术语抽取
本文采用的候选术语抽取算法基于以下假设:某篇专业领域文档中重复出现的字符串很有可能是该领域的专业术语[ 7]。比如在一篇有关乙型肝炎的摘要中,“乙型肝炎病毒”一词多次出现。本文采用的候选术语抽取算法说明如下:
候选术语抽取算法的过程类似于寻找最大频繁项集的过程。若将文本看作字符串str=a1a2…an(n≥2),其中ai(1≤i≤n)表示字符串中的一个字符,则候选术语抽取即是在字符串str中寻找出现频次满足阈值的最长子串substr=ai…aj(1≤i≤j≤n)。最长子串的概念如下:若某满足阈值要求的子串与相邻字符合并得到的子串不能满足阈值要求,则称其为最长子串。结合本问题的特殊约束条件,可将问题转化为寻找最大频繁项集(相应于最长字串的概念,与通常意义上的最大频繁项集有所差异)的过程如下:.
设t={a1,a2,…an}表示文本,ai项表示字符串中的字符,t中的任何连续项{ai,…aj}(1≤i≤j≤n)构成一个项集。将项集{ai,…aj}的支持度设为其在t中的出现频次,即support({ai…aj}) = freq({ai…aj}),若support({ai…aj}) ≥σ,则称项集{ai,…aj}为频繁项集,其中σ是设定的阈值,即重复的频次。候选术语抽取即转换为在t中寻找满足support({ai…aj})≥σ的最大频繁项集。在算法实现上可参考Apriori算法。
值得注意的是该算法会提取出现频次大于其父串的重复子串。例如,若重复子串“乙型肝炎病毒”在文本中的出现频次大于父重复子串“慢性乙型肝炎病毒”的出现频次,则两者都将被提取,否则,仅提取“慢性乙型肝炎病毒”。因此,该算法可以提取嵌套术语。
3 术语选择
3.1 语言学规则过滤
由于术语词性构成规则很难总结,并且几乎每种规则都会产生噪音。因此,本文采取逆向的方法,利用候选术语的词性将一些明显不能作为术语的候选术语过滤掉。先采用中国科学院计算技术研究所的汉语词法分析系统ICTCLAS对候选术语进行分词及词性标注;再对经过分词及词性标注的候选术语总结明显不能作为术语的语言学规则,如表1所示:
| 表1 非术语词性构成规则 |
3.2 术语度计算(IC-value)
候选术语中一般包括有普通词语搭配、无意义的字串和术语,要从中选择出正确的术语,简单的有频次排序选择法[ 9],该方法虽简单易行,但是仅考虑候选术语的出现频次而没有考虑候选术语的长度以及文档频率;使用领域相减[ 2]的方法可以过滤掉一般词语,但需要一个对照语料库,且存在一般词语识别能力不足等问题;基于TF-IDF方法及其变形形式的术语选择也是常用的方法[ 11]。以上方法都没有考虑到嵌套术语和候选术语长度的问题。
相比之下,C-value方法虽然考虑了术语长度和嵌套术语,但也存在一些问题。目前,已有不少人从不同的角度对C-value方法进行改进。许德山等[ 15]结合上下文环境在C-value基础上进行改进,提出V-value方法,在一定程度上提高了术语识别的准确率。还有人将领域类别信息[ 16]、文档频率[ 17]等融入C-value值计算中。以上改进方法没有考虑到逆文档频率、公共破碎子串以及提高长术语发现能力的特殊意义。
本文从逆文档频率、公共破碎子串和术语长度三个方面改进C-value方法,具体说明如下:
(1)C-value方法不能有效过滤一些出现频次很高的普通词汇。按C-value方法计算术语度,则出现频次高的普通词汇会获得较高的C-value值,而无法得到有效过滤,因此本文在C-value值计算中融入逆文档频率,降低高频次普通词汇的术语度值。
(2)C-value方法不能很好地区别公共破碎子串与嵌套术语。例如,“病毒性肝炎肝衰竭”与“病毒性乙型肝炎”都是词串“病毒性”的父串,“病毒性”为公共破碎子串,而并非嵌套术语。“细胞免疫”的父串有“细胞免疫应答”、“细胞免疫功能”等,“细胞免疫”为术语。事实上,若某一子串是公共破碎子串,就不应该独立出现;而若某一子串是术语,就应该会独立出现。因此,为了有效区分公共破碎子串(如“病毒性”)与术语(如“细胞免疫”),在计算中将C-value中的f(a)-
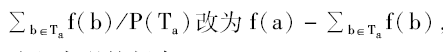
(3)短术语多为如细胞、基因、乙肝、血清和病毒的术语,在领域内具有相对普遍的意义。该类术语可以与其他词组合成更具针对性的长术语,比如淋巴细胞、肝炎病毒等。长术语一般具有更为特定的含意,因此提高长术语的发现能力很有意义。为此可增加候选术语长度在术语度值中的权重,因此本文认为用代替更为妥当。
综上所述,IC-value计算公式如下:
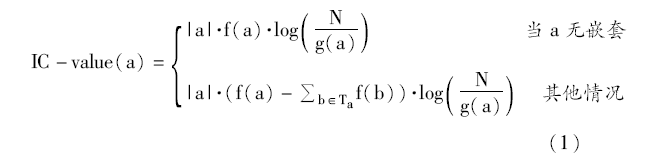
其中,a表示候选术语,IC-value(a)指候选术语a的IC-value值,|a|表示候选术语a的长度,即候选术语包含的字数,f(x)表示x(x取a或b)在文档集中出现的频次,g(a)表示候选术语a的文档频率,b是候选术语a的嵌套候选术语,Ta表示候选术语a的嵌套候选术语集合。需要注意的是,在计算f(b)时较短的嵌套候选术语的频次要扣除嵌套它的候选术语的频次。举例来说,“细胞”的嵌套词语有“细胞免疫”、“细胞免疫应答”、“细胞免疫功能”等。在计算细胞的嵌套候选术语的总频次 b∈Taf(b)时,“细胞免疫”的f(b)值应为“细胞免疫”的词频减去“细胞免疫应答”和“细胞免疫功能”的词频。
根据公式(1)计算得到每个候选术语的IC-value值,其值越高,成为术语的可能性就越大。
4 实验及结果分析
4.1 实验及其结果
.
本文选取2007年到2011年共1 000篇有关乙型肝炎相关论文的摘要,并以此进行术语抽取实验。
(1)利用停用词对摘要进行预处理,并采用基于串频统计的候选术语抽取算法从预处理文本中抽取候选术语,将阈值设置为2,并且抽取长度大于1的候选术语,共得到3 916个候选术语。
(2)对抽取的候选术语集进行分词及词性标注之后,使用非术语语言学规则进行过滤,将明显不能作为术语的候选术语过滤掉。同时发现候选术语集中包含一些地名,本文利用候选术语是否包含“省”、“市”、“县”将地名过滤。经过以上处理,最终得到3 270个候选术语。
(3)对于最终得到的3 270个候选术语,计算其TF-IDF、C-value和IC-value值,同时为了与文献[15]的方法比较,也计算V-value值(由于在此仅用文献摘要,因此在计算V-value时没有使用加权TF-IDF)。然后分别按照TF-IDF、C-value、V-value和IC-value值大小进行排序,并按照排序结果选取Top500。人工判定3 270个候选术语是否为术语,并以此来判定Top500中的术语是否正确,从而计算出不同方法的Top500术语选择的正确率。同时,从1 000篇摘要中随机抽取50篇摘要,人工识别出其中的术语,共计265个,来检验不同方法Top500的召回率。其中,准确率和召回率的计算公式如下:
准确率=正确的术语数抽取出的术语总数×100% (2)
召回率=
| 表2 TF-IDF、C-value、V-value和IC-value方法 Top500术语选择的准确率 |
| 表3 TF-IDF、C-value、V-value和IC-value方法 Top500术语选择的召回率 |
4.2 实验结果分析
由表2可以看出,IC-value方法的Top500术语抽取的准确率要比其他三种方法高。在抽取的Top100术语中,IC-value方法要比TF-IDF和V-value方法高出23%,比C-value方法高出12%。基于C-value改进的V-value方法抽取术语的准确率远不如IC-value方法,甚至不如C-value方法,但比TF-IDF方法略好。由此可见,IC-value方法有效提高了术语抽取的准确率,效果优于V-value方法。
由表3可以看出,针对随机选取的50篇摘要中的265个术语,IC-value方法的Top500术语抽取召回率比C-value、TF-IDF和V-value效果略好,但是,4种方法Top500的召回率都在30%以下,召回率普遍较低。分析50篇摘要中的265个术语,发现其中共有62个术语在整个文档集中的出现频次为1,本文方法无法抽取。并且265个术语中在文档集出现频次少于等于10的术语共148个,而其中被TF-IDF、C-value、V-value和IC-value方法识别的术语都不足10个,分别为0、8、4和8,说明4种方法对低频术语的识别能力较差。由此可见召回率偏低的主要原因是低频术语较难抽取。
为了更好地评价抽取结果,对4种方法的Top500进行更为深入的分析。在对Top500中正确抽取的术语分析后发现,IC-value、 C-value、V-value和TF-IDF方法得到的长度大于2的术语分别为335、320、254和196个。可见IC-value发现长术语的能力比C-value方法稍优,远优于V-value和TF-IDF方法。
另外,在由TF-IDF和C-value方法得到的Top500中有许多没有意义的破碎子串,比如“慢性乙”、“夫定”、“荧光定”、“慢性肝”等。统计4种方法Top500中破碎子串的个数如表4所示。
可以发现IC-value方法能有效地区分破碎子串和术语。主要原因是在TF-IDF、C-value和V-value的
表4
| 表4 TF-IDF、C-value、V-value和IC-value方法 Top500中破碎子串的数量 |
计算公式中没有考虑到破碎子串的问题,在计算相应值时不按其破碎子串独立出现的次数计算,导致其对应值较高。而IC-value方法使用f(a)-b∈Taf(b)(子串独立出现的频次)计算术语度值。
5 结 语
由于语言学规则很难全面总结,本文使用一种基于串频统计的候选术语抽取算法提取候选术语。然后采取逆向的方法,利用候选术语的词性将一些明显不能作为术语的候选术语过滤掉。针对术语选择问题,考虑逆文档频率、破碎子串和候选术语长度的权重三个方面,对C-value方法进行了改进。最后,以1 000篇乙型肝炎相关论文摘要对本文提出的方法进行实证研究。结果证明,本文提出的IC-value方法在准确率和召回率方面都要优于TF-IDF 、C-value以及V-value方法,且有较强的长术语发现能力,识别公共破碎子串的效果十分明显。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|