

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
专题知识库中文本聚类结果的可视化研究——以中华烹饪文化知识库为例
[许鑫 , 洪韵佳]
, 洪韵佳]
, 洪韵佳]
|
|


作者贡献声明:
许鑫: 提出研究思路, 设计研究方案, 负责最终版本修订;
洪韵佳: 进行实验, 采集数据, 起草论文。
【目的】 通过对专题知识库中文本资源的可视化展现为用户提供更直观的导航。【方法】 在多层次文本聚类生成的资源划分结果的基础上, 通过主题发现、降维处理与可视化展现等步骤, 实现专题知识库中文本资源的可视化导航。【结果】 提出一种TF-ICF主题词抽取算法, 并综合利用优化的树图与散点图实现专题知识库的可视化展现, 帮助用户便捷地了解知识库概况、定位所需关注的主题、理清各资源间的关联。【局限】 在可视化展现过程中存在部分人工干预, 知识库可视化展现的交互性仍有待改善。【结论】 提出的可视化方法能较好地应用于专题知识库的资源展现, 对进一步优化专题知识库的用户体验有重要意义。
[Objective] An intuitive navigation is provided to users by the text visualization of clustering results in the domain knowledge base.[Methods] The visual navigation of the texts in the domain knowledge base is realized by the procedures of topic discovery, dimensional reduction and visual display based on the automatic multi-level text organization by clustering.[Results] An algorithm of topic extraction named TF-ICF is put forward, and the visual display of domain knowledge base is realized by the optimized tree map and scatter diagram to help users know about the overview of knowledge base, find the required topics, understand the relation between different texts.[Limitations] The visual display partly depends on the manual participation, and the interaction of the visualization needs to optimize further.[Conclusions] The visualization method is applied successfully in domain knowledge base and helps to optimize the users’ experiences further.
专题知识库是利用信息技术对某一特定主题或领域的知识进行有序化组织、展现和管理的知识应用系统[ 1]。随着人们越来越多地关注于如何从海量信息中快速地发掘精准信息, 全面涵盖特定领域重要信息的专题知识库成为当前研究热点。目前, 一些学者对专题知识库的设计与构建进行深入研究[ 2, 3, 4], 并通过文本聚类等方法在专题知识库中实现了高效的文本自动组织[ 5]。
然而, 随着用户对专题知识库建设要求的日益提升, 仅仅具有合理组织的简单专题知识库已无法满足用户的需求。在各类需求中, 越来越多的用户希望专题知识库能提供更直观的导航方式, 以便于其快速了解专题知识库所含资源的概况, 理清各资源间的关联, 便捷地找到所需的关键资源。鉴于上述日益增长的用户需求, 本文对文本资源自动导航方式进行研究, 基于多层次文本聚类获得的文本自动组织结果, 提出一种适于专题知识库导航的可视化方法, 并结合多层次文本聚类结果特点对文本可视化过程所涉及的主题词抽取与主题描述构建等方法进行部分优化。
文本可视化作为一种直观、高效的信息表现形式, 近年来获得了国内外学者越来越多的关注, 各类文本可视化软件[ 6, 7]相继出现。在基于文本聚类结果的可视化研究中, 特征信息的降维、空间展示与知识发现是三个重要的研究方面:
(1) 特征信息的降维
降维一直是文本可视化研究的关键问题, 即把文本所具有的高维特征信息映射到低维(二维或三维)空间中, 使得各文本能够与低维空间中的点一一对应。早期常用的传统降维方法主要是主成分分析法(PCA), 然而主成分分析作为一种线性降维方法, 当文本的特征数据间线性程度不高时, 会造成对特征的提取性能下降, 在降维的同时一些重要的文本特征易被丢失[ 8]。鉴于主成分分析的上述不足, 近年来, 非线性的核主成分分析法(KPCA)、独立成分分析法(ICA)和多维尺度分析法(MDS)等被纷纷提出, 并广泛地应用于特征信息的降维过程中。Scholkopf 等[ 9]将核函数与主成分分析相结合, 通过计算特征空间数据构成的核矩阵特征向量求解主成分, 从而实现了高维到低维空间的映射; 冯燕等[ 10]利用独立成分分析法从高维的独立成分特征信号中提取出少量的独立成分, 从而实现了降维过程; Pu等[ 11]、Jee等[ 12]利用基于欧氏距离的多维尺度分析法将可视化中心投影到一个二维空间上, 对各类文本的可视化实现了较好的降维。在上述常用降维方法中, 多维尺度分析法相对更为成熟且更适用于文本特征信息的降维, 因此, 本文在开展特征降维时也借鉴了该方法。
(2) 空间展示
空间展示是在上述降维的基础上利用图形或图像在二维或三维的空间中将可视化的结果展现出来, 是文本可视化研究的重要步骤。目前, 可视化的空间展示技术已较为成熟, 根据其展示的不同原理, 主要可以分为基于图标、像素、图形、层次、几何等可视化方法[ 13]。在面向文本聚类结果的可视化展示中, 基于层次的树状图和基于几何的散点图是最常用的两种空间展示方法。此外, 在一些研究中知识地图[ 14]、层云图[ 15]、色度图[ 16]等新的空间展示方法也被进一步引入聚类结果的可视化展现中。目前可视化空间展示形式丰富多彩, 且各项技术已趋于成熟, 然而各类空间展示研究仍以技术发展为主, 较少结合具体的应用场景探讨适宜的空间展示方案。
(3) 知识发现
文本可视化技术可以帮助用户直观、便捷地发现文本的特征、主题以及文本间的关系等。Don等[ 6]开发了FeatureLens文本可视化平台, 通过可视化技术帮助用户直观地发现不同类型文本集中语言特征的使用模式。在文本主题发现上, Krishman等[ 17]利用IN-SPIRE软件以山峰与山谷的三维形式向用户形象地展示了文本的主题之间的关系; 王伟[ 18]通过对聚类结果的可视化展示帮助用户便捷地了解网络热点事件及其演变趋势。在文本间关系的挖掘中, Tirunagari等[ 19]通过抽取概念与主题间的关系, 利用可视化技术直观地表现了海事事故调查报告中事故间的因果关系。在上述文本可视化技术所具有的知识发现功能中, 主题发现是面向聚类结果的可视化中最主要的知识发现功能, 然而在开展主题发现时较少结合文本聚类结果的特点为各类簇赋予既有代表性且具区分度的主题。
综上所述, 可以发现目前聚类结果可视化的相关研究较多, 许多技术可被借鉴, 然而, 结合聚类结果特点和具体用户需求的相关研究较少。鉴于上述不足, 本文结合聚类结果的特点, 对现有主题发现方法进行优化, 并进一步结合主要的用户需求提出一套适合专题知识库的文本可视化展示方案, 以帮助用户快速地了解专题知识库所含资源的概况、理清各资源间的关联、找到所需的关键信息。
专题知识库因其具有某一领域全面且深入的信息资源而获得越来越多用户的喜爱, 因而, 结合用户对专题知识库的需求, 可以发现一种既能描述知识库中资源的总体概貌、又能帮助用户了解关键主题的可视化方法较适宜于专题知识库。
鉴于专题知识库中文本组织的树状结构特点, 在开展知识库可视化研究前, 本文首先利用基于领域本体的多层次文本聚类方法对专题知识库的文本资源进行自动组织, 该方法通过多层次文本表示与相似度计算能较好地将知识库中的文本集划分为多层次的类簇, 提升专题知识库的管理效率[ 5]。
在利用上述聚类方法自动生成多层次类簇的基础上, 进一步开展聚类结果的可视化研究。结合类簇特点, 对各层级中的各类文本进行主题发现, 并根据用户在了解资源概况、寻找所需主题相关信息等方面的需求, 在降维处理的基础上选用较适宜的树图和散点图这两种可视化表现形式展现专题知识库中文本的分布情况与关键主题。该多层次文本聚类结果可视化方法的基本思路如 图1所示:
 | 图1 多层次文本聚类的可视化方法 |
如 图1, 通过读取多层次文本聚类分析产生的文本划分结果与文本表示矩阵的TXT格式文档开展主题发现与降维处理, 并在此基础上生成树图与散点图以展现专题知识库所含的资源。
主题发现也被称为主题抽取或主题识别, 是一种方便用户从大规模信息中快速、准确地了解关键内容的方法[ 20]。基于聚类分析的主题发现的一般流程是从文本特征项中自动抽取核心特征词或术语, 并结合类簇和文本自身的组织和结构发现各类的相关主题。因此, 在主题发现过程中主题词的抽取与主题描述的构建是两个重要的环节。
鉴于“簇内相似度尽可能高, 簇间相似度尽可能低”这一聚类原则, 本文借鉴TF-IDF算法, 提出一种从聚类结果中抽取主题词的方法——TF-ICF(词频–倒排类簇频率)加权算法。该算法综合考虑特征词在表示类簇主题与区分不同类簇上的贡献程度, 认为特征词在文本中出现的次数越多, 其对文本所在类别的主题表示越重要, 则应赋予的权值越高; 而其在越多的类簇中出现, 即其类簇频次越高, 则其区分不同类簇的能力越弱, 其被赋予的权值应越低。其数学表示形式如下所示:
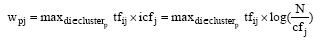
其中, clusterp是某层级聚类结果中的类簇P, tfij是特征词tj在文本di中的词频, cfj是特征词tj在该层级所包含类中的类簇频次, N是该层级所包含的类簇总数。
本文在利用上述算法为特征项赋予权值后, 结合各层级文本聚类分析的特点, 为各层级主题词抽取赋予不同的阈值, 如由于底层的特征词众多, 所以在低层级聚类的主题词抽取时设定较高的阈值——前1%; 而高层级特征词相对较少, 因此在高层级聚类的主题词抽取时设定较低阈值——前10%。
主题描述构建是在主题词抽取的基础上, 对关联度高的主题词进行合理的组织, 从而形成主题描述的过程[ 23]。共词分析法是一种重要的主题描述构建方法, 它利用文本集合中词对共同出现的频次来判断词汇之间的关联关系, 一般认为两个词在文本中共同出现的频率越高, 则这两个词的关联越紧密[ 23]。在主题词抽取的基础上, 进一步利用共词分析法构建了各簇类的主题描述。
在共词分析中, 共词矩阵通常被建立以描述词对的共现频次, 对于有N个主题词的共词分析可以形成 N×N维的共词矩阵。本文通过两个主题词在各簇类中共同出现的文本数量来表示两个主题词间的密切程度。在共词矩阵的基础上, 进一步选择共现次数最多的一至两个主题词对来描述各类簇对应的主题, 如 图2所示:
 | 图2 主题描述构建示意图 |
文本聚类结果的可视化是直观地展现专题知识库所含主题、实现知识库高效导航、优化用户体验的重要手段。基于上述专题知识库中各类别主题发现的结果, 本文通过对各文本特征项的降维处理, 为专题知识库文本可视化制定一套合适的可视化展现方案。
文本聚类结果的可视化是将高维的文本向量映射到二维或三维的可视化空间中, 以图形或者图像的形式展现文本的特性与文本间的关系, 从而帮助用户以直观的方式快速地掌握大量文本中有效的信息以及文本间复杂的关系和潜在的发展趋势[ 24]。因此, 将高维文本向量降维至二维或三维是实现文本聚类结果可视化的关键环节。
本文选用多维尺度分析法(MDS)这一较为成熟的方法开展可视化降维处理, 以更好地反映文本对象间非线性关系, 展示文本集内对象的整体分布情况。以多层次文本聚类分析过程中生成的底层文本间相似度矩阵作为MDS分析的数据源, 通过迭代比较文本对象间的相似程度获得文本对象在二维空间中的标度, 为对文本聚类结果开展进一步的可视化展现提供了重要的基础。
根据文本聚类结果多层次的特点与知识库用户的主要需求, 选用树图和散点图两种可视化表现形式来展现专题知识库中文本的分布情况与关键主题, 并对传统的树图和散点图进一步优化。
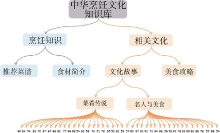
在绘制树图时, 基于主题发现的结果, 将各类簇的主题按类簇所在聚类层级映射到树图相应的层次中, 并将文本对应的编号映射到其所属类簇对应的主题下。为更清晰地展现知识库层次结构, 进一步以不同的文字大小与底纹颜色来标识各节点。其中, 节点的文字大小依据主题所在层级从高到低逐步缩小, 节点的底纹颜色根据其所属的一级主题的不同而不同, 以便于用户快速地定位到其所需的主题与文本资源,如 图3所示:
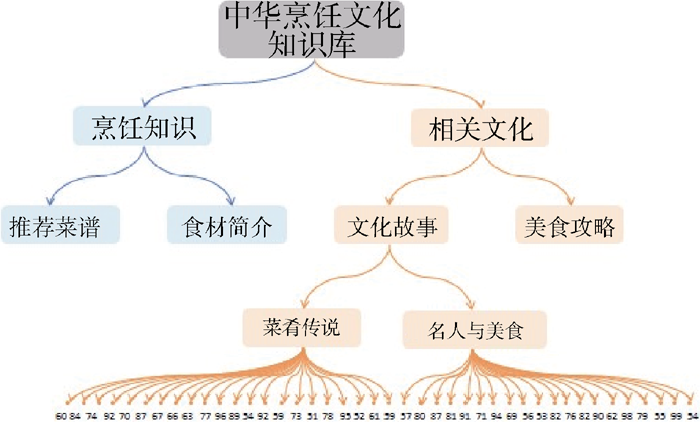 | 图3 可视化树图展示示例 |
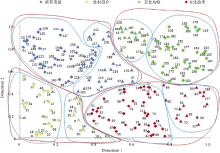
在生成散点图时, 利用多维尺度分析中获得的文本对象在二维空间中的标度值来绘制各文本对应节点所在的位置。同时, 以圆形区域的形式对文本集对应的散点进行划分, 并根据主题发现的结果以图例方式为各圆形区域赋予相应的主题文字。同时, 以不同颜色的节点来表示文本所属的不同二级类簇, 并以节点的不同形状来进一步区分文本所属的不同三级类簇, 以便于用户直观地了解文本的分布情况及文本间的潜在关联关系, 如 图4所示:
 | 图4 可视化散点图展示示例 |
通过上述文本聚类结果的可视化展现方案, 本文将专题知识库所含资源直观、形象地展现在用户眼前, 从而为用户提供了更便捷的可视化导航。
本文以本实验室搭建的中华烹饪文化知识库为例[ 4], 从该知识库中随机抽取出200篇文本资源作为实验数据。基于多层次文本聚类分析[ 5]获得的三个层次文本自动组织结果, 利用所提出的可视化方法对实验资源进行主题发现与可视化展现, 以验证该方法在专题知识库中的适用性。
首先利用TF-ICF算法开展主题词抽取, 为验证该算法的有效性, 将其与TF-IDF算法获得的主题词抽取效果进行对比, 典型类簇抽取结果如 表1所示:
| 表1 TF-ICF与TF-IDF算法主题词抽取效果对比 |
如 表1所示, 通过TF-IDF算法进行的主题词抽取容易丢失部分文档频率很高但对类簇主题有关键标识作用的特征词, 如“菜肴”、“食材”等, 且易提取在个别文本中具有较高频率的特征词, 如“历史”、“成都”等, 而TF-ICF能较好地平衡上述问题, 为各类簇提取更具代表性的主题词。
在主题词抽取的基础上, 利用共词分析法为各层级类簇赋予相应的主题, 典型类簇的主题发现结果如 表2至 表4所示:
| 表2 类簇C2主题发现结果及其主题词共现矩阵 主题: 相关文化 主题词组配特点: 菜谱+食材+名人 |
| 表3 类簇C2.1主题发现结果及其主题词共现矩阵 主题: 文化故事 主题词组配: 强调菜肴及名人信息 |
| 表4 类簇C2.1.2主题发现结果及其主题词共现矩阵 主题: 名人与美食 主题词组配特点: 多人物称谓、年代等, 如“皇帝”、“历史”等 |
为了提供更便捷的可视化导航, 基于聚类分析中获得的第三层级文本相似度矩阵, 利用多维尺度分析法开展特征降维处理, 并结合主题发现结果, 以树图和散点图的形式对多层次文本聚类结果进行可视化展现, 如 图5和 图6所示:
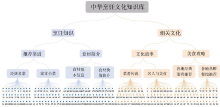
 | 图5 文本聚类结果的可视化树图展示 |
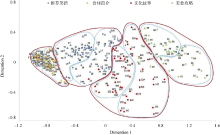
 | 图6 文本聚类结果的可视化散点图展示 |
从 图5的树图中, 用户可以便捷地了解实验对象——中华烹饪文化知识库中文本的关键主题。该知识库的实验文本集主要包括“烹饪知识”与“烹饪相关文化”两大类内容, 这两大类中的文本又可进行第二、第三层的进一步细分。根据该树图的展示, 用户可以快速地捕捉到自己感兴趣的主题, 并便捷地定位到与该主题相关的文本, 从而为用户提供了更好的知识库导航。
根据 图6的散点图, 用户可以进一步了解到知识库中文本集的分布情况及文本间的关联关系。从文本分布情况来看, “食材简介”与“美食攻略”主题下的文本间距离最远, 文本内容差异性较大。此外, “食材简介”主题内的文本分布最为集中, 文本间相似度最大。从各文本间的关联关系来看, 部分文本的代表节点非常接近, 如第7、8、12篇文本的代表节点, 这表现了此三篇文本的内容极为相似, 用户若对其中一篇文本感兴趣, 那他很可能对其他两篇文本也较有兴趣, 这为后续的知识库智能导航、推荐服务等知识服务研究提供了借鉴。
为了满足用户在快速了解知识库资源、获得便捷导航方式等方面的需求, 本文在利用文本聚类方法开展多层次文本自动组织的基础上, 结合聚类结果特点及专题知识库用户需求, 提出一种适用于专题知识库的文本聚类结果的可视化方法, 该可视化方法由主题发现与可视化展现两个主要环节组成。在主题发现过程中, 提出一种新的主题词抽取方法——TF-ICF(词频–倒排类簇频率)加权算法, 并在此基础上通过共词分析法实现了主题描述的构建。在可视化展现过程中, 利用多维尺度分析法将高维的文本特征成功映射到二维空间中, 并进一步结合用户需求与聚类结果多层次的特点, 选用并优化了树图与散点图来综合展现专题知识库中文本的分布情况与关键主题。
通过实验验证了所提出的聚类结果的可视化方法能帮助用户更直观地了解专题知识库中所含文本资源的分布情况及关键主题, 对进一步优化专题知识库的用户体验有着重要意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|