{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
向量空间模型文本建模的语义增量化改进研究
[胡吉明 , 肖璐]
, 肖璐]
, 肖璐]
|
|


作者贡献声明:
胡吉明: 提出研究思路, 设计研究方案, 实施研究过程, 撰写和修订论文;
肖璐: 采集、清洗和分析数据并进行对比实验。
【目的】 基于语义增量对向量空间模型文本分类方法进行改进, 并进行实验验证。【方法】 梳理目前文本表示中语义向量引入和改进的相关研究, 提出文本的语义向量表示实现框架。根据主题词和词汇分别与领域本体中概念之间的映射关系, 构建概念层次树和定位词汇, 计算概念语义相似度, 结合语义增量实现文本的语义向量构建。【结果】 通过文本分类的对比实验发现, 本文所提方法可行且有效, 在宏平均准确率、宏平均召回率和宏平均F1方面优于其他方法。【局限】 在向量空间模型基础上的改进, 语义信息的表达不够充分, 应继续探索文本建模的真正语义化实现方法; 应对多种类型数据进行实验验证, 以提高方法的适用性。【结论】 探索原始向量空间模型的语义化问题, 对当前文本分类及其语义关联等研究具有现实意义。
[Objective] This paper improves the methods of text classification based on VSM using semantic increment, and the model is verified by experiments.[Methods] Combing the studies of semantic vector and its improvement in text representation, this paper improves VSM based on semantic increment, and proposes an implementation frame of semantic vector representation of texts. Furthermore, based on the mapping relationships between words and concepts in domain Ontology, the construction of concept hierarchy tree and words positioning are constructed, semantic similarity of concepts is calculated, and the semantic vector model of texts’ representation is achieved.[Results] The comparative experiments of texts classification demonstrate that the proposed method is feasible and effective, and the performance of this method is better than traditional methods from the perspectives of Precison, Recall and F1-Measure.[Limitations] The description of text semantic information is not good enough, and it is necessary to explore the authentic semantic methods in text modeling. In addition, more comparative experiments on several datasets should be conducted in order to obtain more accurate results.[Conclusions] The semantic improvement on traditional VSM is explored which is important for further text classification and semantic association.
文本表示或建模方法一直是信息检索、文本分类、信息过滤、数据挖掘等领域研究的重点问题, 基于向量空间模型的文本建模是其研究的主要方向。众所周知, 向量空间模型(Vector Space Model, VSM)于20世纪70年代被杰拉德·索尔顿(Gerard Salton)提出后[ 1], 已广泛应用于信息检索、信息组织及信息推荐中。此后众多学者对其进行了改进, 以提高文本内容表示或描述的准确性。但是, 社会网络环境下信息呈爆炸式增长的趋势越来越严重, 研究者越来越重视语义层次的文本描述和表示, 构建文本表示的语义向量空间模型(Semantic Vector Space Model, SVSM)[ 2]以提高文本表示的精度, 降低计算的复杂度。
近年来, 传统向量空间模型的语义化已成为文本特征描述和表示研究的主要方向。典型研究如杨玉珍等[ 3]从文本表示及特征项之间的组织方式入手, 通过特征词与核心词之间的关联关系树表示文本, 实验发现此方法在特征数量较少的情况下仍能保持较好的分类效果。Chang等[ 4]引入领域本体扩展基于向量空间模型的内容检索功能, 通过描述内容概念之间的关系确定所属的内容主题。Tasi等[ 5]认为当前的相似度计算方法没有考虑信息序列的影响, 因此其将VSM和最大共同子序列(LCS)相结合重新计算词汇权重, 得到词汇之间的语义关系, 结果表明此方法能够提高文本相似度计算的性能。Virpioja等[ 6]利用典型相关分析法(CAA)和无监督学习方法挖掘词汇与文本之间的潜在语义关系。Nasir等[ 7]提出一种语义平滑向量空间模型, 计算词汇与文本之间的语义相关性, 以此提升文本聚类效果。Sbattella等[ 8]提出基于概念层和词汇层相结合的领域知识语义挖掘模型, 使用自然语言处理工具挖掘文本内容蕴含的语法和语义信息, 以此扩展语义信息检索引擎中的领域知识和发现新的潜在概念。
基于此, 挖掘词汇或概念与文本内容之间的语义关联是提高文本向量化表示效果的重要途径, 同时也成为文本分类、信息检索和推荐等后续研究和应用的基础。而当前的一个研究问题则是向量空间模型作为文本表示和建模的基础理论, 如何在原始词汇–文本向量的基础上挖掘或者修正词汇与文本之间的关联关系, 使其能够更加准确地表达文本内容。其中效果较好的一种处理方法是在词汇和文本之间建立基于领域本体的概念层次树, 通过词汇–概念和概念–文本之间的两层转化, 得到词汇与文本之间的语义关系。因此, 本文通过语义增量和语义相似度改进语义向量空间模型, 实现文本主题和词汇与领域本体中概念的映射, 达到准确描述文本特征的目的。
在文本语义向量表示中, 本文首先基于LDA主题模型进行文本主题挖掘, 得到两个矩阵: 词汇–主题矩阵(WZ)和文本–主题矩阵(DZ)。在词汇–主题矩阵中, 每一行对应词汇表中的词汇, 每一列对应各个主题(或主题词), 矩阵中的元素值则为某一词汇分配给对应主题的概率; 在文本–主题矩阵中, 每一行对应各个文本, 每一列对应各个主题(或主题词), 矩阵中的元素为文本中的所有词汇分配给某一主题的概率(也可看作是词汇的权重)。 WZ和DZ矩阵中每一行为主题向量和文本向量, 以此为基础进行文本的语义向量构建。
基于SVSM[ 9]的文本表示是将原始向量转换为语义向量, 通过领域本体建立向量空间模型中主题词及特征词汇与领域本体中概念的映射关系, 结合语义相似度[ 10]描述词汇之间的语义关系。SSVM将通过LDA主题模型提取的主题词和词汇映射到领域本体中, 进行文本和词汇的语义信息分析及本体推理[ 11], 得到词汇所对应的深层语义概念, 并把概念作为文本的特征项, 在计算概念特征项权重的前提下, 形成语义空间向量。SSVM能够有效地克服向量空间模型的固有缺陷, 提高文本描述和表示的准确性。
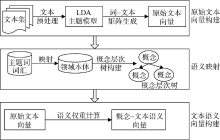
文本表示的语义向量空间模型构建主要是将初始文本向量映射到潜在语义空间, 生成新的文本向量即语义向量, 其文本表示框架如 图 1所示:
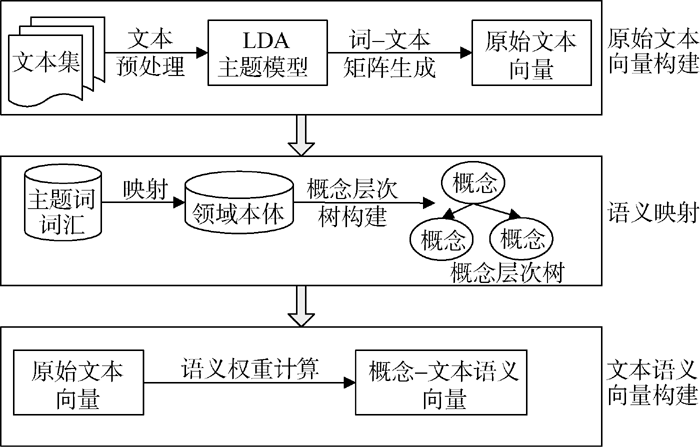 | 图1 基于语义向量空间模型的文本表示框架 |
(1) 原始文本向量构建。首先将文本集进行预处理, 通过LDA主题模型提取主题词和相应的词汇, 按照词汇的主题分布情况, 构造D×T维的文本–主题矩阵CDT和V×T维的词汇–主题矩阵CVT。
(2) 语义映射。将原始的文本–主题矩阵CDT和词汇–主题矩阵CVT中的主题词和所对应的词汇依次与领域本体中的概念建立映射关系, 将主题词和词汇映射为领域本体中的概念, 并对其进行规范化和泛化处理以及权值修正和优化, 根据概念间的关系形成概念层次树[ 12], 对词汇和主题词关系的分析就转化为对概念层次树的分析。
(3) 文本语义向量构建。经过上述处理后, 将原始矩阵转化为概念关系矩阵, 所反映的不再是词汇、主题词与文本之间简单的频率和分布关系, 而是概念特征项之间以及与文本之间的语义关系, 从而降低了特征项和空间维数, 为准确描述文本特征和提高文本分类的精度打下基础。
根据上述文本表示的语义向量空间模型, 模型的各个步骤算法实现如下:
(1) 主题词提取和确定。根据LDA主题模型提取相应的主题词, 在进行语义向量构建时, 需要进行主题词提取, 即选取文本中概率值最大的词汇作为此文本的主题词[ 13], 公式如下:
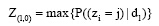
其中, 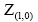
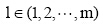
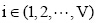
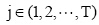
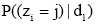
(2) 词汇语义增量计算。假设Z(l,0)为文本d1的主题词, n(l,0)为主题词Z(l,0)在文本dl中出现的次数, 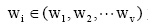
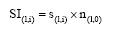
其中, s(l,i)为词汇wi与文本dl的主题词Z(l,0)的语义相似度, 具体计算见3.2节。
(3) 语义向量空间模型构建。给定文本集 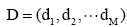

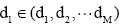

其中, 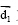
因此, 整个文本集合就抽象为一个权重–语义关联矩阵如下:
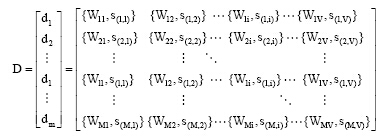
(4) 基于语义增量的权重计算。在传统向量空间模型权重计算公式 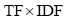
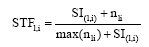
其中, 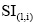
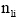
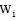
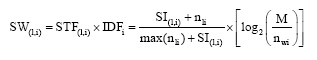
上述分析已经得出, 基于语义向量空间模型的文本表示或建模须将主题词和词汇转化为本体中的概念表示, 通过概念语义相似度计算进行文本的语义向量表示。因此, 在上述算法的基础上, 基于语义相似度计算对算法进一步改进。
构建领域本体旨在实现某一个特定领域内文本集中词汇之间的语义关联。本文采用IS-A属性[ 14]表示概念关系, 从而将领域本体抽象为概念层次树, 对概念关系的分析转化为对概念层次树的解析, 通过概念层次树中概念的深度和之间的距离计算概念或词汇的语义相似度s(l,i)。
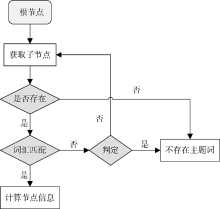
在语义相似度计算之前, 必须解决词汇在领域本体中的相对定位问题。本文通过先序遍历算法实现目标主题词的定位, 再以目标主题词为参考实现其他目标词汇的定位[ 15]。领域本体中的目标主题词定位过程如 图3所示:
 | 图2 主题词定位过程 |
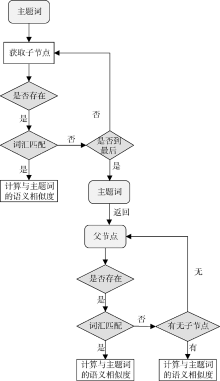
在主题词定位后, 以主题词为参照遍历概念层次树定位词汇。首先遍历主题词的子节点, 若在子节点中未发现目标词汇, 则先序遍历父节点, 直至找到目标词汇。如未发现目标词汇, 则记该词汇与主题词之间的语义相似度为0。目标词汇的定位过程如 图3所示:
 | 图3 目标词汇定位过程 |
概念之间的语义相似度计算是确定词汇和主题词在领域本体中的语义关系的前提[ 16]。根据研究比较[ 17], 为了降低算法在空间和时间上的复杂度, 本文通过计算概念在领域本体中的深度和概念之间的距离实现概念间的语义相似度计算; 词汇所对应的概念在领域本体中的位置决定了概念在领域本体中的深度和概念之间的距离。
(1) 节点概念深度计算[ 18]。在概念层次树中, 设根概念节点Root的深度Dep(Root)为1, 则任一非根节点的概念C在层次树中的深度计算公式如下:
Dep(C)=Dep(parent(C))+1
其中, parent(C)为节点C的父节点。
层次树的深度Dep(Tree)等于树中概念深度的最大值:
Dep(Tree)=max(Dep(C))
(2) 概念距离计算[ 19]。在概念层次树中, 概念之间的距离是由两者的宽度和权值决定的。本文定义从某一概念C引出的边(关系)具有相同的权值W(C), 将概念C的子节点数目定义为其宽度Wid(C), 则概念C的权值计算公式为:
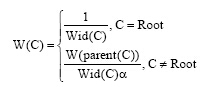
其中, 参数 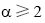
(3) 概念间的语义距离计算。在概念层次树中, 两个概念之间的语义距离Dist(C1, C2)为连接它们的最短路径上所有边的权值之和, 公式如下:
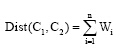
其中, Wi是连接概念C1和C2的最短路径上的第i条边的权值。
从概念层次树的语义分类观点看, 概念C的所有子节点都是由其细分所得。因此, 概念C和其任一子节点的语义距离都小于和其任一兄弟节点的语义距离, 即与其任一子节点的相似度都大于与其兄弟节点的相似度。
(4) 语义相似度计算[ 20]。根据上述语义距离计算的设定, 则概念层次树中任意两个概念的语义距离范围为 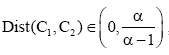
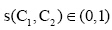
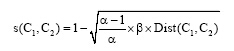
其中, 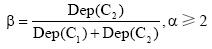
根据上述语义相似度的计算, 可以得到词汇和主题词的语义相似度矩阵Zd如下:

得到词汇与主题词的语义相似度矩阵后, 运用语义增量分别计算每个词汇与当前文本集中主题词的语义增量, 然后计算得出其权重, 得到新的文本–词汇语义关联矩阵:

至此, 经语义相似度计算后得到语义向量空间模型, 以文本–词汇语义向量矩阵的形式展示, 每个文本由矩阵中的每一行向量表示, 从而实现文本的语义向量化表示。至此, 得到每个文本的语义特征向量, 将其作为文本相似度计算和分类的基础。
实验通过文本分类效果以验证所提方法的有效性和优越性。文本分类实验采用语料库TanCorpV1.0[ 21]中的TanCorp-12单层语料词频格式[ 22], 其在多种经典文本分类算法的评测中均表现良好。选取电脑、房产、教育、科技和娱乐5个子数据集, 随机选取文本集的60%作为训练集, 剩余40%作为预测集, 如 表1所示:
| 表1 实验数据集 |
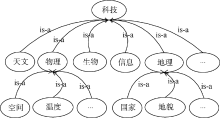
文本预处理后得到训练集文本的原始特征集合及生成原始的基于词汇的文本特征向量[ 23]。利用本体构建工具Protégé创建基于OWL语言的相关文本集领域本体, 其简化形式如 图4所示。使用Java语言在Eclipse平台上实现特征词汇与领域本体概念映射和概念间相似度计算, 将原始向量转化为语义向量, 以此进行基于VSM和SVSM的SVM文本分类实验对比。SVM采用LibCVM工具包[ 24], 本文采用RBF核函数, 其适应性和收敛性较好[ 25]。每次实验重复三次, 最终结果取三次实验的平均值。
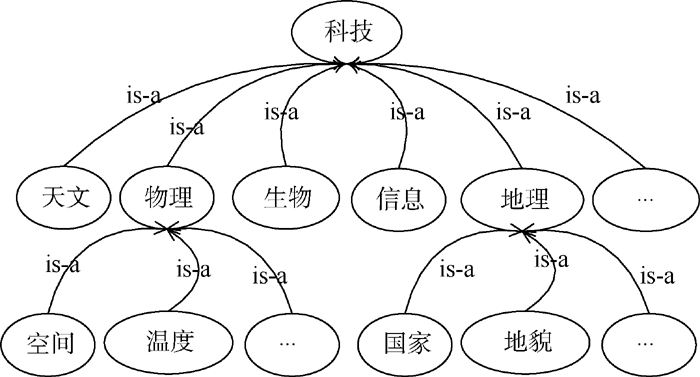 | 图4 科技领域本体 |
在文本分类的效果评测中, 最常用准确率(Precison)[ 26]、召回率(Recall)[ 27]和两者的综合指标(F1-Measure)来评价实验效果。但是为了从整体上综合评测文本表示性能, 本文在上述基础上采用宏平均作为评估标准。宏平均准确率为:
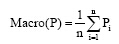
宏平均召回率为:
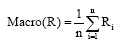
宏平均为:
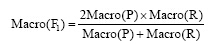
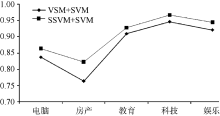
5类子数据集在两组实验中的准确率、召回率和宏平均结果对比如 表2和 图5所示:
| 表2 文本表示实验结果对比 |
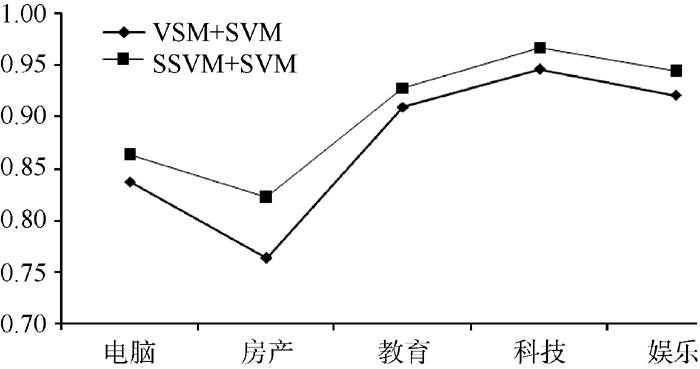 | 图5 两组分类实验的Macro(F1)值对比 |
对比 表2和 图5的实验结果可以得出, 电脑、房产、教育、科技和娱乐文本经过语义向量转化后, 在文本分类上的表现较好, 证明本文所提方法的有效性。
文本表示必须进行结构化处理才能作为机器的运算对象, 而传统的向量空间模型等文本表示方法在文本描述准确性和计算精度上存在缺陷, 不但降低了文本相似度、信息检索和推荐的准确性, 而且造成了较高的计算复杂度。因此, 在分析传统文本向量的基础上, 本文通过语义映射, 构建语义向量空间模型, 将文本原始向量转换为文本语义向量。将文本集中的词汇分为两类: 一般词汇和主题词。将词汇和主题词映射到领域本体中的概念层次树中, 根据词汇与主题词所对应的概念在层次树中的深度和宽度, 计算其语义相似度得出词汇与文本主题之间的语义增量, 以此将原始文本–词汇的权重矩阵转换为文本–词汇的语义矩阵, 实现文本的语义向量化表示。文本的语义向量化表示, 提高了文本描述的准确性, 进而改善了文本分类的效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|