{kind=link}
{kind=link}
{kind=link}
面向中文专利文献的单层并列结构识别
[石翠 , 王杨, 杨彬, 姚晔]
, 王杨, 杨彬, 姚晔]
, 王杨, 杨彬, 姚晔]
|
|


作者贡献声明:
石翠: 提出研究思路, 设计研究方案, 进行实验分析, 撰写论文;
王杨: 实验分析, 论文编辑; 杨彬: 设计论文框架及修改论文;
姚晔: 论文修订。
【目的】 为提高并列结构识别结果的准确率, 根据专利文献中并列结构的特点, 提出一种规则与条件随机场相结合的并列结构识别方法。【方法】 根据中文专利文献中并列结构的特点, 运用规则提取对称并列结构; 对规则提取的并列结构进行捆绑, 运用条件随机场识别单层的并列结构; 在上述识别结果的基础上, 运用错误驱动的方法, 对识别结果进行后规则处理。【结果】 实验结果表明, 该方法可以有效地识别专利文献中的单层并列结构, F值达到76.57%。【局限】 实验所用规则可以进一步改进, 规则的运用直接影响并列结构的识别效果。【结论】 规则与条件随机场相结合的识别方法对于中文专利文献中单层并列结构的识别是有效的。
[Objective] In order to improve the accuracy of identification results, according to the characteristics of coordinate structures in Chinese patent literature, this paper presents an identification method combining rules and Conditional Random Fields(CRFs).[Methods] According to the characteristics of coordinate structures, using the rules to extract the symmetrical coordinate structure. Bundling the coordinate structures, using CRFs to identify non-nest coordinate structure. On the basis of the above identification results, using the wrong driver method to deal with the identification results to get the final identification results.[Results] The experimental results show that this method can identify the non-nest coordination in the patent literature effectively and get the F value of 76.57%.[Limitations] Rules used in the experiments can be further improved. The application of the rules directly affects the identification results of coordinate structures.[Conclusions] The identification method by combining rules and CRFs is effective for non-nest coordination in Chinese patent literature.
并列结构[ 1](Coordinate Structure), 也称联合结构、联合短语。朱德熙[ 2]指出, 联合结构是由两个或更多的并列成分组成的。并列成分可以叠加在一起, 中间没有形式上的标记, 也可以用停顿隔开。一般认为并列结构中的并列成分是相似的, 并列结构的自动识别研究几乎全是围绕并列成分的相似性进行的。
专利语料中并列结构具有复杂性、离散性以及结构的长距离性, 使并列结构的自动识别十分困难。有效地分析和识别并列结构, 对于依存句法分析乃至中文信息处理具有极其重要的意义, 具体分析如下:
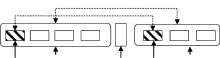
(1) 并列结构的识别结果有利于提高句法分析的性能。由于并列结构一般表现为长距离关联或依存, 目前广泛使用的统计句法分析器很难处理, 分析效果较差。 图1(a)和 图1(b)分别为使用专利语料训练的句法分析器分析结果和正确分析结果。
 | 图1 依存句法分析结果图 |
(2) 并列结构的识别结果可以应用于机器翻译等领域。以下例句是并列结构标识前和识别后谷歌翻译器的翻译结果。
例句: 在另一种方法中, 该源设备可以从一个[通信频带最宽的、或者位置最靠近的]组内设备接收该内容信息的复制。
识别前翻译: In another method, the source device can be a communication band from the widest, or position of the group closest to the device receiving the content information copying.
识别后翻译: In another method, the source device from a [widest communication band, or the location of the nearest] group device receives a copy of the content information.
显然, 对并列结构进行标识的翻译结果要优于不对并列结构进行标识的翻译结果。
针对有标记并列结构, 有关学者进行了多方面的考察与研究。吴云芳[ 3]利用现有的语言资源, 从句法、语义两个层面详尽地考察并列成分之间的约束关系, 并对这些约束关系进行形式化的描述, 而后基于知识描述进行并列结构的自动识别。吴云芳对并列结构的识别主要运用规则的方法, 而规则的方法有其固有的缺陷, 如: 规则的冲突、不完备、优化难等问题。王东波等[ 4, 5]详细统计和分析有标记联合结构的内部语言学和外部语言学特征, 并针对有标记并列结构的内部和外部语言学特征, 分别运用规则和统计的方法, 对并列结构进行自动识别。但该方法没有融合规则和统计的优点, 进而提高识别结果的准确率。苗艳军等[ 6, 7]分析了宾州中文树库中并列结构的内部和外部的语言学特征, 对有标记并列结构进行自动识别。苗艳军运用最大熵和错误驱动相结合的方法对并列结构进行识别, 融合规则与统计的优点, 但最大熵模型可以引入更多特征且错误驱动规则可以进一步完善。昝红英等[ 8, 9]与周丽娟等[ 10]根据虚词用法知识库中的连词用法, 构建了连词结构短语规则, 实现基于规则的连词结构短语识别, 并将连词用法作为特征采用条件随机场模型实现基于统计的连词结构短语识别, 但对连词结构短语的识别也没有充分融合规则和统计的优点。Agarwal等[ 11]运用规则的方法, 对英语篇章进行并列结构的识别, 识别出81.6%的并列结构。由于其识别范围是一篇文章, 故该方法的可移植性差。Hara等[ 12] 与Hanamoto等[ 13]运用统计和规则相结合的方法实现英语并列结构的自动识别。其对并列结构的识别虽然在前人的基础上有所提高, 但识别准确率并不理想, 尤其是形容词性和方位词性的并列结构识别的准确率只有58.5%和51.4%。Popel等[ 14]分析了26种语言的三种主要类型的依存树库(Prague, Moscow, Stanford), 对并列标记在依存树库中的不同表示能力分别做了详细的分析, 得到Prague类型的表现能力要好于其他两种类型, 为以后解决并列结构自动识别问题做了很好的铺垫。本文在中文专利文献语言学特征的基础上, 运用条件随机场对专利文献中的单层并列结构进行识别, 识别前后都运用规则进行处理。
本文识别有标记的单层并列结构, 即下面例句1中的并列结构以及例句2中内层的并列结构:
例句1: 该/r 通信/v 接口/n 1215/m BL【发送/v 和/c 接收/v】 BL【电/n 、/wp 电磁/n 、/wp 或/c 光/n】 信号/n , /wp 这些/r 信号/n 携带/v 表示/v 各种/r 类型/n 的/u 信息/n 的/u 数字/n 数据流/n 。/wp
例句2: 当/p 在/p LAN/ws 联网/v 环境/n 中/nd 使用/v 时/g , /wp 计算机/n 802/m 通过/p BL【BL【有线/b 和/c //ws 或/c 无线/b】 通信/v 网络/n 接口/n 或/c 适配器/n 856/m】 连接/v 至/p 局域网/n 852/m 。/wp
用于自然语言处理的统计机器学习模型有很多种, 如: 最大熵、隐马尔可夫、条件随机场等。通常情况下, 对于序列标注问题, 条件随机场(CRFs)作为一个无向图模型比隐马尔可夫模型、最大熵模型等有向图模型识别的效果好[ 15]。条件随机场是Lafferty等[ 16]在最大熵和隐马尔可夫模型的基础上, 提出的一种基于无向图的学习模型。其核心思想是利用无向图理论使序列标注结果达到整个观察序列的全局最优解。CRFs已经广泛应用到词性标注、组块识别和命名实体识别等任务中, 并且取得很好的效果。CRFs的突出优点是可以相对任意地加入任何与处理对象相关的语言学特征[ 17], 且模型对于长距离关联有很好的描述能力, 能够很好地利用字、词等信息, 因此本文选择条件随机场作为识别中的统计模型。
并列结构的识别关键是识别并列结构的边界, 本文采用S/E(Start/End)编码方式[ 18]: B表示并列结构的首词, I表示并列结构的内部, E表示并列结构的尾词, O表示并列结构的外部词语。王东波[ 5]与周丽娟[ 10]根据联合结构和连词结构短语的平均长度采用七分位进行标注。专利文献中的并列结构特点是跨度大, 其中跨度超过10个词的并列结构占27.46%[ 20]。本文采用条件随机场和规则相结合的方法进行并列结构的识别, 后期的规则根据并列结构的特点改变并列结构的左右边界, 为了简化规则编码, 本文采用四分位标注, 即除了并列结构的开始词和结尾词之外, 并列结构的内部都标注为I。由于特征是基于条件随机场的短语识别的核心, 所以特征选择的好坏决定了短语识别效果[ 19]。根据专利文献中并列结构的复杂性以及长距离性等特点, 在前人研究的基础上, 综合考虑词、词性、并列标记、并列边界词等特征, 设计特征模板的候选特征集, 如 表1所示。其中, W表示词, P表示词性, C表示是否为并列标记, B表示是否为边界词。
| 表1 构成模板的候选特征集 |
在中文专利文献中有一些理想的并列结构, 如例句3所示, 但是由于并列结构的跨度大, 或者位于嵌套的并列结构中, 用统计机器模型的识别效果并不理想。由于专利文献中, 理想的并列结构都是由包含“和”或“或”的并列标记以及由并列标记“及”和“与”连接的, 所以本文设计的规则都是在并列标记“及”、“与”以及包含“和”或“或”的并列标记的基础上进行的。
例句3: 这里/r , /wo 特定/b 的/usde R-ACH/sym 正在/nt 使用/v BL【扇区/n A1/sym 的/usde 位置/n 1/m 上/nd 的/usde 功率/n 控制位/n , /wo 扇区/n B3/sym 的/usde 位置/n 2/m 上/nd 的/usde 功率/n 控制位/n 和/c 扇区/n C2/sym 的/usde 位置/n 4/m 上/nd 的/usde 功率/n 控制位/n】。/wj
根据专利文献中并列结构自身的特点和对称性, 本文制定以下并列结构提取规则:
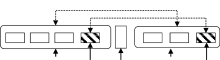
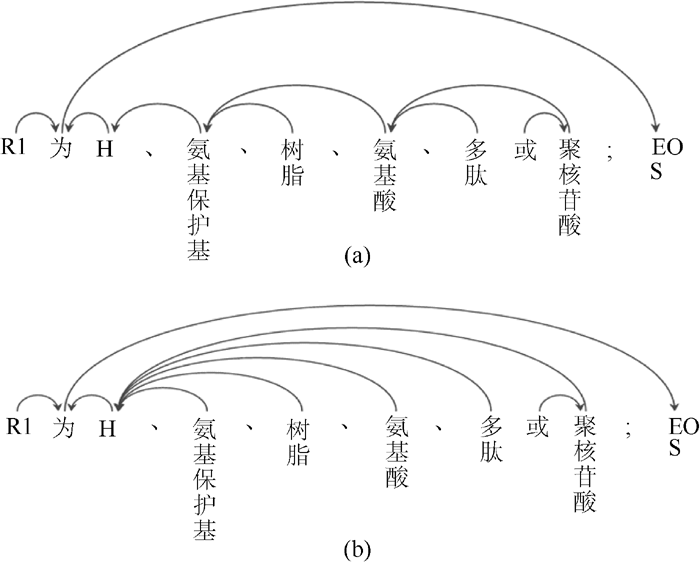
(1) 利用规则提取专利文献中首词或尾词相同的并列结构。首词相同的并列结构识别策略如 图2所示; 尾词相同的并列结构识别策略如 图3所示:
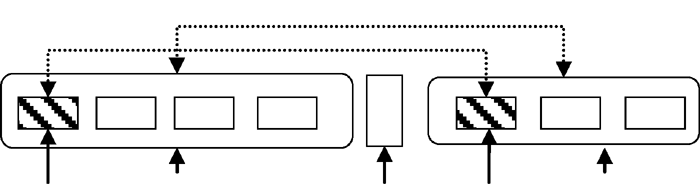 | 图2 首词相同的识别策略 |
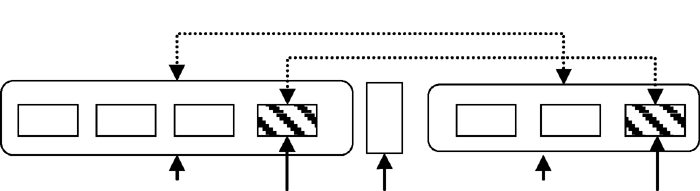 | 图3 尾词相同的识别策略 |
在识别结果中剔除自身和自身形成并列的情况, 如例句4所示。在向前及向后的查找过程中进行必要的剪枝, 如遇到不作为并列标记的标点符号, 则停止查找。为了提高识别的准确率, 只保留首词和尾词相同的, 并列成分之间的长度差小于等于2个词的并列结构。如果是首词相同或尾词相同, 只保留长度相等且尾词性和首词性相同的并列结构。
例句4: 在/p 穿过/v BL【井孔/n 和/或/c 井孔/n】周围/nd 的/sed 地下/n 构造/n 之后/nd 进行/v 检测/v 。/wj
(2) 根据并列标记“/”的特点[ 20], 利用规则提取由并列标记“/”连接的前后词性相同的并列结构, 如例句5所示:
例句5: 溶剂/n 混合物/n 梯度/n 为/vx 含/v 0.01%/sym TFA/sym 的/usde 5%/sym -/wp 100%/sym BL【乙腈/n //wp 水/n】
(3) 根据相差一个前缀的并列结构特点[ 20], 用规则提取出相差一个前缀的并列结构, 如例句6所示:
例句6: 对于/p BL【可见光/n 或/c 不/d 可见光/n】 辐射/v , /wo 与/c 常规/n 的/usde 彩色/a 滤波器/n 相比/v 带宽/n 窄/a 得/usdf 多/a 。/wj
(4) 专利文献中有一类并列结构也有理想的对称性, 如例句7所示。该类并列结构并列标记前为“)/wkr”, 例句5所示的并列结构应该属于尾词相同的情况, 这种情况在第(1)条规则中被去除, 其提取方法与尾词相同的并列结构类似。
例句7: 加入/v BL【二氯甲烷/n (/wkl 10/m 毫升/q )/wkr 和/c 氢氧化铵/n (/wkl 25/m毫升/q )/wkr】的/usde混合物/n
(5) 用规则提取并列连词前词词性为“m”(数词)的并列结构, 该类并列结构有两种理想的并列结构形式。一种情况是数词之间的并列, 如例句8所示; 一种情况是数词作为名词后缀, 带后缀的名词之间的并列, 如例句9所示。
例句8: 增益/n 设置/v 在/p BL【0/m 和/c 48/m】 dB/q 之间/nd
例句9: 器械/n 20/m 总体/n 上/nd 包括/v BL【一/m 伸长/v 构件/n 22/m 、/wd 一/m 手柄/n 部分/n 24/m 、/wd 一/m 致动/v 机构/n 26/m 和/c 一/m 可/v 变形/v 部分/n 28/m】
在前词性为“m”的并列结构中, 有两种特殊情况需要单独处理。一种情况是“一个”和“多个”的并列或“一种”和“多种”的并列或类似的并列。这种情况下, “一个”是一个词, “多个”是两个词, 如例句10所示。另一种情况是并列标记前为名词的尾词缀, 并列标记后为数量词, 该数量词一般为“一”、“一个”、“第一”。
例句10: 所述/v 板/n 使用/v BL 【一个/m 或/c 多/m 个/q】呈/v 连续相/n 的/usde 层/n
(6) 用规则提取并列连词前词词性为“sym”(英语字符)的并列结构, 该类并列结构与前词性为“m”的情况类似也有两种理想的并列结构形式。一种情况是“sym”之间的并列; 一种情况是“sym”作为名词后缀, 带后缀的名词之间的并列。对于这种情况不列举例句, 参照前词性为“m”的情况。
(1) 放弃识别效果欠佳实际应用不大的并列结构
根据并列结构的特点及其对实际应用的影响, 在已经识别出的并列结构中剔除以下三种情况:
①识别结果中不包含并列标记;
②并列标记为“并”、“并且”、“且”, 但不包括词长相等, 首词性和尾词性都相同以及首词相同两种情况;
③并列标记为“,”, 但不包括并列成分为“sym”之间和“m”之间并列的情况。
剔除②和③中并列结构的原因是: 由上述并列标记连接的并列结构大都为句子级的并列结构, 对于实际应用帮助不大; 存在上述所列情况时, 并列结构的识别效果欠佳, 影响并列结构识别的准确率。
(2) 处理处于“在 
处于“在 
例句11: 倾斜/v 的/usde 坡面/n 25/m 在/p 各/r BL【凹进/n 23/m 和/c 表面/n 24/m】 之间/nd 延伸/v , /wo 当/p 凸轮/n 22/m 相对/v 于/p 毂/n 9/m 按照/p 在/p 图/n 5/m 中/nd 如/c 箭头/n “/wyl A/sym ”/wyr 所示/v 具体/a 方向/n 旋转/v 时/g , /wo 使/v 棘爪/n 18/m 逐步/d 径向/v 地/usdi 向外/nd 移动/v 。/wj
例句12: c/sym )/wkr 设置/v 在/p 所述/v BL【顶片/n 和/c 底片/n】 之间/nd 的/usde 吸收芯/n ; /wp
例句13: 气体/n 调节器/n 在/p 主外壳/n 内/nd BL【入口/n 与/c 出口/n】 之间/nd 串联/v 对准/v
从例句11、12、13中发现, 并列结构的左边界不是“在”, 且位于“在 
例句14: 磁场/n F2/sym 穿过/v BL 【流出/v 流体/n 42/m 和/c 进入/v 空气/n 46/m】 之间/nd 的/usde 界面/n
通过上述分析, 本文用如下的规则对并列结构的右边界是“之间”的并列结构进行处理:
如果并列成分长度相等、对应词的词性相同确定该并列结构识别结果正确; 如果并列结构的左边界是“在”也认为该并列结构的识别结果正确; 否则, 先在并列结构左边界的前面查找“在”(遇到标点符号结束), 如果找到, 将并列结构的开始调整到“在”后面的词。如果没找到, 在并列结构内部查找“在”, 将并列结构的开始调整到“在”后面的词。这样就能处理识别结果中下列两种识别错误的并列结构:
错误实例1: 在/p 密封/v 部件/n (/wkl 30/m )/wkr 的/usde 顶壁/n (/wkl 31/m )/wkr 的/usde 内/nd BL【表面/n 和/c 轴承/n 部件/n (/wkl 20/m )/wkr 的/usde 上端/nd 表面/n】 之间/nd 形成/v 润滑剂/n 存储/v 间隙/n (/wkl 73/m )/wkr 。/wj
错误实例2: 该/r 方法/n 包括/v : /wp BL【利用/v 所述/v 共享/v 秘密/n 向/p 第一/m 服务器/n 认证/v 该/r 客户端/n , /wo 通过/p 第二/m 服务器/n 在/p 该/r 客户端/n 与/c 所述/v 第一/m 服务器/n】 之间/nd 发送/v 与/p 该/r 认证/v 过程/n 相关联/v 的/usde 信令/n ; /wp
(3) 处理多个并列成分的识别结果
根据包含多个并列成分的并列结构的并列标记分析[ 20], 本文剔除并列结构识别结果中错误的情况。
本实验使用由沈阳航空航天大学知识工程中心标注, 经自动分词、词性标注并人工校对的语料, 且用“BL【】”标注语料中所有有标记的并列结构。该语料共包含6 133个句子, 词性标注采用863词性标注集。将语料的前4 133句作为训练集, 后2 000句中, 1 000句作为测试集, 1 000句作为开发集。
并列结构识别的测试指标包括准确率(P)、召回率(R)、F值, 计算公式如下:
 |
 |
 |
(1) 基本实验
本文的baseline实验选取王东波[ 5]的基于条件随机场的联合短语识别中的最长联合特征模板, 其特征为: W-2, W-1, W0, W1, W2, W-2/W-1/W0, W-1/W0/W1, W0/W1/W2, P-2,P-1, P0, P1, P2, P-2/P-1/P0, P-1/P0/P1, P0/P1/P2。特征说明参照 表1, 方括号括起来的为复合特征, 使用中文专利语料进行单层并列结构的识别实验。实验把词和词性作为特征。参照公式(1)和公式(2), N表示系统中识别正确的并列结构个数; Ns表示系统中识别的全部并列结构的个数; Nt表示测试语料中实际的并列结构个数。
由于专利文献中的并列结构具有复杂性和长距离性, 因此本文在最长联合特征模板的基础上将窗口大小扩充到4后选取特征具体如下: W-4, W-3, W-2, W-1, W0, W1, W2, W3, W4, W-2/W-1/W0, W-1/W0/W1, W0/W1/W2, P-4, P-3, P-2, P-1, P0, P1, P2, P3, P4, P-2/P-1/P0, P-1/P0/P1, P0/P1/P2。
在4窗口实验的基础上, 根据专利文献自身的特点, 对个别特征进行微调, 并增加语言学特征: 是否为边界词; 是否为并列标记, 得出语言学特征模板,其所选特征为: W-4,W-3,W-2,W-1,W0,W1, W2, W3, W4, P-4, P-3, P-2, P-1, P0, P1, P2, P3, P4, C-3, C-2, C-1, C0, C1, C2, C3, B-3, B-2, B-1, B0, B1, B2, B3, W-4/W-3, W-3/W-2, W-2/W-1, W-1/W0, W0/W1, W1/W2, W2/W3, W3/W4, P-4/P-3, P-3/P-2, P-2/P-1, P-1/P0, P0/P1, P1/P2, P2/P3, P3/P4, W-2/W-1/W0, W-1/W0/W1, W0/W1/W2, P-2/P-1/P0, P-1/P0/P1, P0/P1/P2。
其中, 并列标记主要有连接并列成分的并列连词, 如: 和、或、与、或者、及、及其、并、并且等; 标点符号, 如: 顿号、分号等以及复合标记, 如: [, 或者]、[; 或者]、[; 以及]、[和/或]等。边界词是指大多出现在并列结构外部, 而不出现在并列结构内部的词语, 通过统计分析, 在专利文献中可以作为边界词的词语有: 包括、限于、涉及、可以、如、来、根据、是、等等、等、分别、都、之一等[ 20]。
语言学特征模板下的训练语料样例如下:
在 p N N O
包括 v N Y O
至少 d N N B
一个 m N N I
服务器 n N N I
和 c Y N I
至少 d N N I
一个 m N N I
客户机 n N N E
的 u N N O
分布式 n N N O
计算 n N N O
系统 n N N O
中 nd N N O
其中, 第1列为词; 第2列为词性; 第3列为是否并列标记, 是并列标记为Y, 否则为N(逗号, 分号等不一定为并列标记的标记为N); 第4列为是否为并列结构的边界词, 是边界词标记为Y, 否则为N; 第5列为并列结构标识。
基础实验结果对比如 表2所示:
| 表2 基础实验结果对比 |
(2) 个别词性细分的实验
词、词性是本文选取的两个主要特征, 通过对语料分析发现, 对词性的标注不够细致。本文在原来词性标注的基础上, 通过计算机自动改变个别词的词性, 初步达到对某些词性的细分。原始词性和个别词性细分的对比如 表3所示:
| 表3 原始词性和个别词性细分的对比 |
对训练语料和测试语料的个别词性进行细分后, 运用语言学特征模板进行个别词性细分的对比实验, 实验结果如 表4所示:
| 表4 个别词性细分对比实验结果 |
(1) 语料捆绑
从 表4可以看出, 个别词性细分后的并列结构识别结果要优于原始的识别结果, 所以, 后续的所有实验都在个别词性细分的基础上进行。通过对实验结果分析发现, “所”与后面动词被识别为并列结构的外部和内部, 如例句15所示:
例句15: 在/p 该/r 超声/n 处理/v 停止/v 后/nt , /wo 进行/v 测量/v 以/c 确定/v 在/p 所/ussu BL【述/v 超声/n 处理/v 停止/v 时/g 的/usde 结合/v 速率/n 或/c 其后/nt 一段/m 预定/v 时间/n 时/g 的/usde 结合/v 速率/n】。/wj
事实上, “所”与其后面动词应该为一个整体作为并列结构的内部或外部。针对上述情况, 对训练语料和测试语料进行预处理, 即把“所+v”的情况进行捆绑处理。如: 所/ussu述/v→所述/v; 所/ussu需/v→所需/v等。除此之外, 为了能更方便进行前期的规则处理, 对一些复合标记进行捆绑。捆绑的复合并列标记有: 和/c //wp 或 /c→和/或/c; 或/c(和/c、及/c、以及/c) 与前面的逗号、分号、顿号, 如: [、/wd 或/c]→[、或/c]。语料进行捆绑前后的对比实验结果如 表5所示:
| 表5 语料捆绑前后对比实验结果表 |
(2) 基于规则的条件随机场并列结构识别
运用3.2节所列规则提取对称并列结构, 并对识别出的并列结构进行捆绑, 作为一个词输入, 词性选择并列结构的尾词性。训练语料和测试语料都运用语料捆绑后的语料, 训练模板运用语言学特征模板。
由于识别出的并列结构作为一个词输入, 该实验识别结果包含一些嵌套的并列结构, 本文提取嵌套并列结构内层的识别结果。
(3) 基于错误驱动的并列结构后规则处理
运用3.3节所列的并列结构后处理规则, 对基于规则的条件随机场并列结构识别结果进行规则后处理。单层并列结构的识别结果对比如 表6所示:
| 表6 单层并列结构识别结果对比 |
并列结构识别是自然语言处理中的难点, 本文运用统计和规则相结合的方法对中文专利文献中的单层并列结构进行识别。实验结果表明, 本文方法能够有效地识别出中文专利文献中的单层并列结构。但实验结果有待进一步提高且未解决嵌套并列结构的识别问题。在今后的研究工作中, 将寻找一种有效识别嵌套并列结构的方法。
(致谢: 感谢沈阳航空航天大学知识工程研究中心张桂平教授、蔡东风教授以及周俏丽老师对本文的帮助和支持。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|