改进TFIDF算法在潜在合作关系挖掘中的应用研究
[孙鸿飞 , 侯伟]
, 侯伟]
, 侯伟]
|
|


作者贡献声明:
孙鸿飞: 提出研究思路和论文框架, 设计研究方案, 论文最终 版本修订;
侯伟: 采集、分析数据以及起草论文。
【目的】 弥补传统方法在潜在合作关系挖掘中的缺陷和不足, 提高潜在合作关系的挖掘效果。【方法】 在分析简单计算法、最小值计算法与传统TFIDF算法缺陷和不足的基础上, 提出改进TFIDF算法, 并将其引入到潜在合作关系挖掘中。【结果】 利用《北大中文期刊核心目录(2012年版)》中19种图书情报类期刊近5年情报学研究方法应用领域的论文作为样本数据, 发现简单计算法与最小值计算法受到作者发文量影响较大, 传统TFIDF算法的挖掘结果很难实现从潜在合作关系转化为现实合作关系, 而改进TFIDF算法对此的满足度则表现得非常突出。【局限】 改进TFIDF算法未考虑论文中作者之间的排名顺序对潜在合作关系的影响。【结论】 通过将4种挖掘结果进行对比和评价, 证明改进TFIDF算法较其他传统方法更科学、更具有优越性和实用价值。
[Objective] In order to remedy the defects of traditional methods in the mining potential cooperation relationship, improve the potential mining effect.[Methods] The paper proposes the improved TFIDF algorithm and applies to the potential cooperation relationship mining based on the analysis of the flaw and the insufficiency of simple calculation method, minimum value calculation method and the traditional TFIDF algorithm.[Results] The simple calculation method and the minimum value calculation method are greatly influenced by authors productivity, traditional TFIDF algorithm result is difficult to achieve the conversion from potential cooperation relationship for practical cooperation, and improved TFIDF algorithm shows very prominent based on regarding the applying research methods of information science field in 19 kinds of journals of Library and Information Science in “Chinese Core Journal of Peking University Directory (2012 Edition)” in recent 5 years as sample data.[Limitations] The improved TFIDF algorithm does not consider the influence between author ranking orders of potential cooperation.[Conclusions] The results show that the improved TFIDF algorithm is more scientific, has more advantages and better practical value than other traditional methods, through comparing and evaluating four data mining results.
学术会议、交流论坛等活动形式为科研合作提供了广阔的平台,科研人员越来越重视彼此之间的合作。这种合作不仅包括巩固和发展现有的合作关系,与此同时,人们还更加积极地探寻未来潜在的合作对象。论文作为研究成果的主要载体,通过对其所包含的相关信息(如关键词、参考文献等)进行分析能够迅速有效地发现作者之间的潜在合作关系,为科研人员寻求现实合作对象提供必要的信息。然而,在海量的论文数据中搜索到与自己研究内容相似的潜在合作者是一件极其困难的事情。近年来计算机技术、数据挖掘技术迅速发展,为科研人员挖掘到与自己研究内容相似的潜在合作者提供了可能。因此,运用文献计量学方法挖掘各个领域中潜在合作关系已经成为图书馆学和情报学中重要的研究内容。
目前, 国内外对潜在合作关系的挖掘主要通过分析论文中的关键词或参考文献实现。
基于引文理论的潜在合作关系挖掘主要是运用论文中参考文献的引用与被引的关系计算作者的引用强度、耦合强度, 并以此衡量作者研究内容的相似度。这种方法主要基于20世纪80年代White等[ 1]提出的作者同被引分析法(ACA)。之后, Jarneving[ 2]通过修改第一作者或单个作者的共被引频次计算方法对ACA进行改进。Zhao[ 3]将ACA基本层面的共被引计数对象从只考虑第一作者拓宽到五位作者。另外, Zhao等[ 4]首次提出作者文献耦合分析法, 利用对作者所有论文中的参考文献分析作者的研究内容, 能够有效地描述作者当前的研究内容, 是作者同被引分析的有效补充。
与基于引文理论的ACA方法相比, 基于共现理论的作者关键词耦合分析法则是利用作者当前已发表的文献进行分析, 而不需要文献之间建立起共被引关系, 因此更能够反映出作者目前的研究现状[ 5]。
作者关键词耦合分析法的核心是构建作者之间合作相似度矩阵。目前, 构建相似度矩阵主要有三种方法:
(1) 简单计算法, 主要通过计算两个作者发表的论文中相同关键词数目确定作者之间的合作相似度。如邱均平等[ 6]利用简单计算法挖掘出我国计量学领域核心作者的潜在合作关系。
(2) 最小值计算法, 主要通过统计两个作者所发表论文中所有相同关键词的出现频数, 并通过累加较少的频数来确定作者之间的合作相似度。如陈远等[ 7]运用最小值计算法计算出基于CSSCI的国内情报学领域作者文献耦合情况。
(3) 传统TFIDF算法, 主要根据关键词在每个作者文献集合中出现的频次和在所有作者文献集合中的分布这两种因素来确定作者之间的合作相似度。如陈卫静等[ 8]利用传统TFIDF加权方法计算作者研究内容的相似度, 进而挖掘出作者的潜在合作关系。
以上三种方法都存在一些缺陷和不足, 导致挖掘效果不是十分理想。首先, 简单计算方法对相同关键词进行简单的统计、累加, 忽略了关键词本身出现次数之间的耦合, 而且很容易受到作者发文量对关键词的影响, 因此影响挖掘的科学性和正确性。其次, 最小值计算方法虽然考虑了关键词本身出现次数之间的耦合问题, 却导致作者发文量对关键词耦合的影响程度增加, 因而很容易得出发文量多的作者与其他高频作者更可能形成潜在合作关系的片面结论。最后, 传统TFIDF算法中IDF计算的主要思想是: 如果作者包含关键词的论文数量占整个论文集合的比例越少, 那么相对于整个论文集合, 关键词具有很好地区分作者论文的能力, 即关键词的IDF值越大。由此可见, IDF的计算是建立在如下假设的基础上: 区分作者i研究领域最有意义的关键词应该在整个论文集合中出现频次较少。然而事实上, 对于很多无关信息, 如“的”、“之”等公共高频词出现的次数越多, 其对论文内容、研究领域的区分能力越弱。由于关键词是反映论文主要内容、作者研究领域和研究方法的特有关键信息, 因此作者的关键词在论文集合中出现的次数越多, 说明作者在关键词所表征的研究领域中研究成果越多, 关键词越能代表作者的研究内容与研究领域。可见, IDF应该是关于作者所发表含有关键词的论文数量的递增函数。因此, 传统TFIDF算法的主要思想违背了通过作者–关键词耦合矩阵挖掘潜在合作关系的基本原理, 需要对传统TFIDF算法进行改进。
另外, 还有学者设计了一些其他的算法来挖掘作者之间潜在的合作关系。如沈耕宇等[ 9]利用作者名次的向量夹角余弦系数算法来求解作者向量的相似度, 进而挖掘科研团队的合作情况。但是此类挖掘算法过于复杂, 同时对计算机程序设计的要求较高, 因此不宜推广。
基于上述分析, 本文通过对传统TFIDF算法进行改进, 并将其应用到潜在合作关系的挖掘中, 详细地介绍了改进TFIDF算法的基本原理及其挖掘步骤。同时, 利用《北大中文期刊核心目录(2012年版)》中19种图书情报类期刊2008-2012年情报学研究方法应用领域的论文作为样本数据, 分别使用上述三种传统方法和改进TFIDF算法进行潜在合作关系的挖掘, 并将4种挖掘结果进行对比和评价。
改进TFIDF 算法基本思想是在核心作者–关键词耦合矩阵S0的基础上,构建核心作者之间潜在合作相似度矩阵S1。其中,S1中的行i和列j代表核心作者,矩阵中第i行和第j列的数据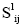 代表作者i与作者j的合作相似度:
代表作者i与作者j的合作相似度:

具体的计算公式为:
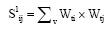 | (1) |
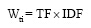 | (2) |
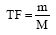 | (3) |
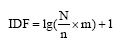 | (4) |
其中,Wti表示关键词t在作者i中的权重;Wtj表示关键词t在作者j中的权重;Wtj与Wti公式性质一致;v表示作者i与作者j共现的关键词数量;M表示作者i所有关键词的频次之和;N表示作者i发表的论文总数;m表示作者i 所发表的论文中含有关键词t的论文数量; n表示论文集合N中包含关键词t的论文数量。
从公式(4)可以看出, 在改进TFIDF算法中, IDF是关于m的递增函数。证明过程如下:
设除作者i以外的其他作者包含关键词t的论文数量为k, 且IDF=f(m), 令m2>m1>0。
因为:
n=m+k
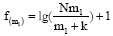
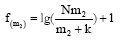
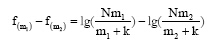
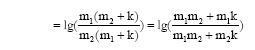
已知:
m2>m1>0且k>0
因此:
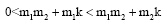
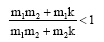
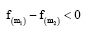
即IDF是关于m的递增函数。由此可见, 改进TFIDF算法的主要思想与潜在合作关系挖掘的基本原理相吻合。
同时, 由公式(4)还可以看出, IDF是关于N的递增函数, 而N的增加也将导致n的增加, 即IDF是关于n的递减函数。由此可见, 改进TFIDF算法削弱了作者发文数量对潜在合作关系挖掘的影响。
另外, 公式(4)中IDF值不能简单地通过 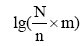
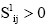
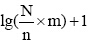
本文选取的论文集共计5 866篇文献[ 10], 以此作为样本数据说明改进TFIDF算法在潜在合作关系研究中的挖掘步骤。
(1) 选取核心作者
利用改进TFIDF算法挖掘作者之间潜在合作关系, 如果作者数量太多不仅没有意义, 同时也大大增加了挖掘难度, 因此首先需要选取样本数据中的核心作者。
根据普赖斯的理论: 发表N篇及其以上论文的作者为杰出科学家, 即为核心作者, 计算公式为:N=0.749(nmax)1/2, 其中nmax为参与合作的作者中发文量最多的论文篇数[ 11]。在本文的样本数据中, 发文量最多的是邱均平, 其参与合作的论文数为81篇, 由此得到N=6.741, 故选取发表论文篇数为7篇及其以上的作者作为核心作者, 共计190人, 部分如 表1所示:
| 表1 核心作者(部分) |
(2) 构建关键词–核心作者耦合矩阵统计核心作者发表论文中所有的关键词, 共计3 647 个, 由此构建出3 647×190 的关键词–核心作者耦合矩阵S0 ,部分如 表2所示。矩阵中第i 行和第j 列的数值 表示作者i所有论文中出现关键词j的绝对频次。
表示作者i所有论文中出现关键词j的绝对频次。
| 表2 核心作者–关键词矩阵(部分) |
(3) 构建潜在合作相似度矩阵
利用改进TFIDF算法的求解公式, 通过编写Excel VBA代码计算出核心作者之间的合作相似度, 构建核心作者合作相似度矩阵。同时, 根据样本数据构建核心作者已合作矩阵, 该矩阵中的数值表示核心作者之间已经合著的论文篇数。最后, 从核心作者合作相似度矩阵中剔除已经合作过的核心作者数据, 由此得到核心作者潜在合作相似度矩阵, 部分如 表3所示:
| 表3 核心作者潜在合作相似度矩阵(部分) |
(4) 将合作相似度矩阵转化为单列矩阵并排序
为了便于比较核心作者之间的潜在合作相似度, 需要将核心作者潜在合作相似度矩阵转化为核心作者潜在合作相似度的单列矩阵并排序, 由此得到潜在合作相似度排名。其中排名最高的前50位核心作者, 如 表4所示:
| 表4 核心作者潜在合作相似度(排名前50位) |
本文分别利用4种方法挖掘核心作者潜在合作相似度的单列矩阵并排序。其中, 挖掘结果中未剔除重复作者排名前20位的核心作者如 表5所示; 挖掘结果中剔除重复作者排名前20位的核心作者如 表6所示。需要特殊说明的是: 由于所采用的挖掘方法不同, 因此所得到的潜在合作相似度并不具有横向可比性, 而潜在合作相似度的计算更看中排序结果。
| 表5 4种方法潜在合作关系挖掘结果(未剔除重复作者, 排名前20位) |
| 表6 4种方法潜在合作关系挖掘结果(剔除重复作者, 排名前20位) |
从 表5中可以看出, 以传统计数为基础的简单计算方法与最小值计算方法得到的潜在合作相似度单列矩阵中排名前20位的核心作者中有很多重复的作者。从 表6中可以看出, 简单计算方法排名第2位的作者在 表5中未排进前20; 最小值计算方法排名第2位的作者在 表5中排名第17位; 而传统TFIDF和改进TFIDF两种方法排名第2位的作者在 表5中分别排名第7位和第3位。
同时结合 表1可以看出存在这样一种趋势: 发文数量多的核心作者在潜在合作相似度的单列矩阵中排名靠前, 这说明简单计算方法与最小值计算方法所挖掘的结果受到作者发文量的影响较大。在这种情况下, 势必会得出发文量越多的核心作者与其他高频核心作者之间潜在合作的可能性越大的片面结论。
因此, 为了更科学、直观地对比评价4种方法的挖掘结果受作者发文量影响的程度, 本文通过计算4种方法挖掘结果的排序名次与其对应的按照作者之间发文量均值作为作者合作相似度排名(即基准数据)之间的标准差来体现。该标准差的计算结果反映4种方法挖掘结果的排序与其对应的基于作者发文量的排序之间的差距, 数值越大说明距离其对应的基于作者发文量的排序结果越远, 受到作者发文量的影响越小。具体的计算公式为:
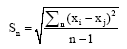 | (5) |
其中,Sn表示前n位挖掘结果的排序名次与基准数据之间的标准差;xi表示某一种方法挖掘结果的排序名次;xj表示xi对应的基于作者之间发文量均值作为作者合作相似度的排序名次;n表示挖掘结果中排名前n位。
同时, 为了能够反映出随着排序名次的增加标准差值的变化趋势, 本文分别计算排名前20、50、100、200、300、400、500位的标准差, 具体结果如 表7所示:
| 表7 4种方法所得标准差Sn对照表 |
从 表7中可以看出, 4种方法的挖掘结果都存在以下趋势: 随着排序的增加, 受作者发文量的影响也在增强, 特别是简单计算方法、最小值计算方法受作者发文量的影响要明显大于传统TFIDF算法和改进TFIDF算法。同时, 通过计算排名前n位标准差的边际增量, 还发现随着排序的增加简单计算方法和最小值计算方法受到作者发文量的影响程度也随之增大, 而传统TFIDF算法与改进TFIDF算法受作者发文量的影响程度却随之减小。
与此同时, 本文还考虑到在一般情况下, 完全陌生的两位作者只能在两种情况下产生潜在合作关系:
(1) 两位作者的研究领域都比较宽泛、应用的研究方法和工具都是通用的, 两者在多个研究领域、多种研究方法和工具上产生广泛的耦合;
(2) 两位作者的研究领域是相同的或者相似的, 并且较为狭窄, 所运用的研究方法和工具都较为特殊, 两者在此基础上产生深度耦合。
其中, 第二种情况下两位作者之间的潜在合作关系更有可能转化为现实的合作, 而第一种情况则往往表现为研究方法和工具的应用公共化, 也可能是研究该问题的通用范式, 虽然两者之间存在广泛的耦合, 但从潜在合作关系向现实合作关系转化的可能性较低。因此, 通过将传统TFIDF算法与改进TFIDF算法的挖掘结果进行对比分析, 依据上述两种情况为评价标准, 将挖掘结果符合第二种情况的方法视为最佳方法。
| 表8 传统TFIDF 算法排名前50 位的耦合关键词表(部分) |
本文通过对比分析传统TFIDF算法与改进TFIDF算法挖掘结果中关键词–核心作者耦合矩阵中具体的耦合关键词及其频次(部分如 表8、 表9所示)来评价两种方法的优劣。从 表8中可以看出传统TFIDF 算法在揭示核心作者之间广泛耦合关系的能力较强, 而揭示核心作者之间深度耦合关系的能力较弱。即传统TFIDF 算法对第一种情况的满足度较好, 而对第二种情况的满足度则差强人意。
与此相对应的是, 在 表9中: 例如关键词“协同过滤”总共出现8 次,而刘海峰、梁昌勇二人在这一研究领域的研究成果就达到7 次,这说明在这一研究领域中二人分别开展了深入的研究工作, 因此二者之间的潜在合作相似度较大,并且从潜在合作转化为现实合作的可能性较大;例如徐健、刘萍二人在关键词“相似度计算”这一研究领域的研究成果占总研究成果的2/3, 这说明在这一研究领域内, 二者之间存在很强的潜在合作的可能性。由此可见, 改进TFIDF 算法对第二种情况的满足度表现得非常突出。
| 表9 改进TFIDF算法排名前50位的耦合关键词表(部分) |
综上所述, 改进TFIDF算法不仅弥补了传统TFIDF算法的缺陷和不足, 而且有效地弱化了作者发文数量对挖掘结果的影响。利用改进TFIDF算法挖掘核心作者之间的潜在合作关系, 既可以揭示核心作者之间的广泛耦合关系, 更可以揭示出核心作者之间的深度耦合关系, 尤其是这种深度耦合关系更有可能将潜在合作关系转变成为现实合作关系。由此可见, 将改进TFIDF算法应用于潜在合作关系挖掘中更具有优势和实用价值。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|