
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
电子商务中垃圾评论检测的特征提取方法
[游贵荣1, 2  , 吴为
, 吴为3 , 钱沄涛2 ]
, 吴为|
|


作者贡献声明:
游贵荣: 提出研究思路, 设计研究方案;
游贵荣, 吴为: 设计实验过程;
吴为: 实验数据采集、预处理和分析;
游贵荣: 论文起草及最终版本修订;
钱沄涛: 论文审核及对部分内容进行关键性补充修改。
【目的】 针对电子商务中产品评论存在较多垃圾评论的问题, 提出新的特征提取方法, 提高垃圾评论的识别率。【方法】 根据量化评价的思想, 使用词性路径匹配模板检测评论中的评价句, 并在分词中加入自定义评价词词典, 提高评价句的识别率。利用评价句的数量能够很好地区分与产品无关的评论或垃圾评论的优点, 结合评论的主题词、情感倾向、文本结构等, 有针对性地提取相应的特征。【结果】 实验结果显示, 利用该特征识别垃圾评论的准确率为97.96%、F值为88.48%。【局限】 该方法主要用于中文垃圾评论的识别, 不适用于英文产品评论。【结论】 所提取的特征能够高效准确地识别垃圾评论, 亦可用于正常评论的有用性量化评估及排序, 有广泛的应用价值。
[Objective] A feature extraction method is proposed aiming to detect spams and improve recognition rate from regular product reviews in electronic commerce.[Methods] Based on the idea of quantitative evaluation, features are extracted comprehensively in terms of reviews’ intrinsic characters such as the number of evaluation sentence, sentiment tendency, topic word and text structure. The number of evaluation sentence is the key feature to distinguish spams from regular product reviews using Part-Of-Speech (POS) path matching templates, and a custom dictionary is imported to improve recognition rate of detecting evaluation sentence.[Results] Experiment results show that the spam recognition precision can reach 97.96% and F-measure reach 88.48%.[Limitations] This method is mainly used to identify Chinese review spams, is not suitable for the English product reviews.[Conclusions] Review spams can be effectively and accurately detected by the proposed features. Furthermore, these features can also be applied to evaluate and rank the regular product reviews, and other related applications.
电子商务的快速发展, 使用户在购买和使用商品后发表的产品评论数量急剧增加。因缺乏对用户评价的有效激励机制, 导致用户对评价内容的表述较简单, 亦存在较多相同或相似的评论, 甚至是广告或和主题无关的内容。虽多数电子商务网站对用户的评价内容设置了是否“有帮助”或“有用”的投票机制, 但实际有投票记录的却很少。因消费者在网上购物时信息不对称情况相对严重, 及羊群效应的存在, 故网民的网购行为受用户评价因素的影响最大[ 1]。网络评论形成速度快、语言随意和多变, 一些热门产品可能会出现成千上万条质量参差不齐的评论。如何从大量的产品评论中提取有价值的信息, 成为意见挖掘领域近年来广受关注的一个研究热点。
为减少用户对评价内容的参考成本, 帮助用户快速进行购物决策, 多数电子商务平台提供评论信息的不同排序方式(如天猫的“按信用”和“按推荐”)[ 2]。而该排序方式中, 仍存在较多和评论主题无关的广告等垃圾评论信息。要区分垃圾评论与正常评论, 特征选择的好坏直接影响着分类器的分类精度和泛化性能。由于产品评论具有句子较短、断句随意、用词口语化和语法标点符号使用不规范等特点, 因此从内容和形式自由度高、垃圾数据噪声大的评论信息中, 提取区分垃圾评论和正常评论的特征比较困难。产品垃圾评论与常见的垃圾邮件、博客和短信有相似之处但又不同。垃圾邮件、博客中存在大量无意义的富含关键字的复制博客或链接, 及含广告的图片或文本, 目的是欺骗搜索引擎或欺骗用户点击广告来牟利。与产品垃圾评论最接近的是垃圾短信, 主要内容都是短文本, 平均长度为几十个汉字。垃圾邮件、博客和短信可通过发送行为的特征检测(如黑白名单过滤、基于社会网络特征和位置特征等), 而产品评论主要通过分析文本内容进行识别。用于邮件的文本分类算法, 虽可用于产品评论, 但分词后特征向量偏小, 影响分类结果, 而关键字过滤方法则不利于泛化。
在英文产品垃圾评论识别研究方面, Jindal等[ 3]将在线购物网站上产品的垃圾评论分为: 非可信评论、针对品牌的评论和无实质内容的评论, 通过过滤重复评论和建立回归模型的方式识别垃圾评论。但重复评论并不一定是垃圾评论, 可采取去重和排序的方式, 不直接展示给消费者。Liu等[ 4]根据英文产品评论的信息量、可读性和主观性三个方面提取特征, 使用支持向量机(Support Vector Machine, SVM)建立机器学习模型区分评论质量的高低。因中文“长字符串”的书写方式, 使计算机在理解中文方面远比英文要困难得多, 很多在英文意见挖掘领域较为成功的方法和研究成果不能直接应用到中文领域。目前处理中文垃圾评论的研究相对较少, 国内为数不多的垃圾评论研究者, 多数使用的实验数据仍是英文产品评论。李霄等[ 5]以数码领域的相机评论为研究对象, 从评论、评论者和被评论的商品三个方面选择11个特征。其主要特征为评论中是否提到产品名称、属性和品牌, 结合评论长度、正/负面评论词的数量、评论中字母的密度、数字及字符的密度和评论者是否为匿名等特征, 使用SVM模型来检测中文产品垃圾评论, 其实验的数据集仅涉及相机这个数码领域的单一产品, 重点在于4种特征的组合、SVM核函数的选择和参数优化对实验结果影响的对比。
本文从组成评论的短句粒度角度, 提出量化评价的概念, 通过识别评论中能够表达用户评价产品的评价句, 并利用评价句的数量及其在评论中所占的比重, 作为度量评论质量好坏及检测垃圾评论的重要指标。根据正常评论的句法词性搭配统计知识, 首次使用词性路径匹配模板来检测评论中的评价句, 并在分词中加入与表达评论和情感倾向相关的评价词词典, 提高评价句的识别率。从评论的粗粒度角度, 主题词特征用来区分整条评论是否和产品主题相关, 目的是过滤和产品主题无关或含有广告的评论。文本结构特征用来识别评论信息中是否存在较多重复的评价词或广告信息。情感倾向特征用来识别评论信息是否过分褒贬。最终在产品评论的评价句数量、主题词、情感倾向、文本结构和作者属性5个方面有针对性地提取14个特征。经真实数据集的实验验证, 本文提取的特征比较全面、针对性较强且易于实现, 能够高效准确地识别垃圾评论, 在不同产品类型中的泛化性较好; 亦可利用此特征, 对正常评论的有用性进行量化评估及排序, 有较大的实用价值。
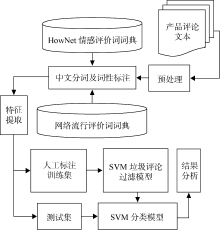
针对垃圾评论进行特征提取和实验验证所采用的方法如 图1所示:
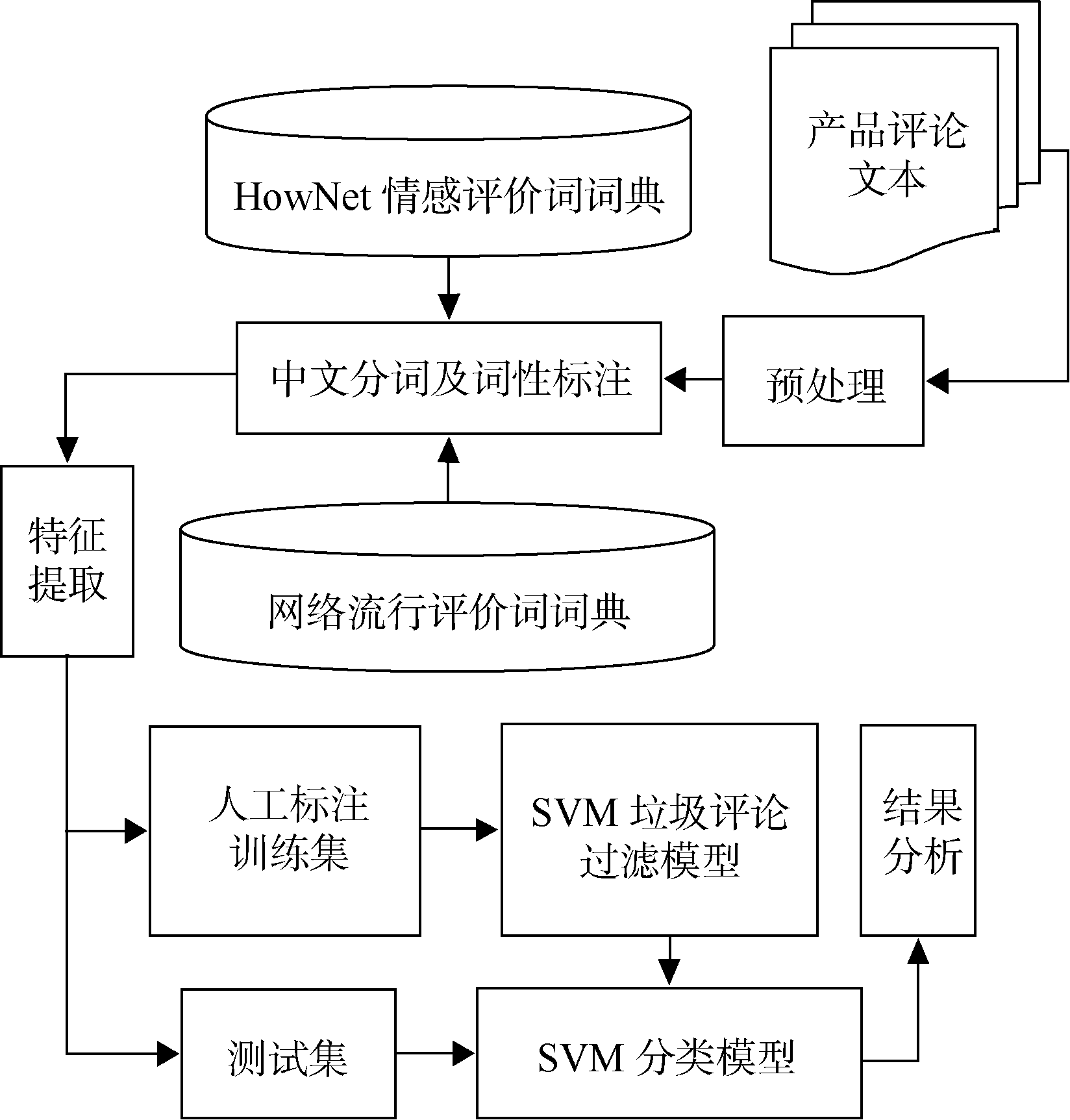 | 图1 研究方法示意图 |
主要包括预处理、中文分词和词性标注、特征提取、建立分类模型和结果分析等步骤。其中, 中文分词和词性标注是中文产品评论处理的重要基础性工作, 分词工具采用中国科学院计算技术研究所的ICTCLAS2011[ 6], 其可通过自定义词典优先功能, 将与评论信息分析相关的评价词或未登录词设置为自定义词典, 提高特定领域的分词效果。分类模型采用在文本分类方面性能较好的SVM。
表达用户褒贬倾向和感情色彩的词语称为极性词, 本文主要采用HowNet[ 7]极性词, 加入一些评论作者常用的、和表达情感相关的网络流行词[ 8], 及一些口语化的词语与简写。并根据在线商品交易评价的特点, 对极性词进行情感极性标注, 最终形成极性词词典。为使分词系统更好地识别产品评论中的极性词, 将极性词词典中汉字个数大于1的词语导入到ICTCLAS自定义词典中。因这类词多数为短语, 不易区分其词性, 在此将其称为“评价词”, 并用“/I”进行标注。在ICTCLAS词性标注规则中, 名词用“/n”标注, 形容词用“/a”标注, 副词用“/d”标注, 动词用“/v”标注, 标点符号等虚词用“/w”标注。为便于描述, 后文和词性有关的内容中, 就用“n”表示名词、“a”表示形容词、“d”表示副词、“v”表示动词、“I”表示评价词, “nv”为名动词、“na”为名形词。
因多数产品评论一般由多个短句组成, 断句较随意, 标点符号使用不规范, 部分使用空格或其他字符进行句子分割。本文假设产品评论都由多个短句组成, 为描述方便, 给出以下相关定义:
定义1: 产品特征词指词性为“n、v、a、d和I”与描述或评论产品特征相关的词。
定义2: 评价句指构成产品评论文本每个短句中, 包含产品特征或评论观点的句子。
定义3: 句法词性搭配结构指评论句子经过分词和词性标注后, 句子呈现各种词性按某种顺序组合的特征, 如: “n+d+a”。
设产品单条评论文本集R={r1,r2,…,rM},ri(i=1,2,…,M),为产品评论中某一短句, M为评论短句的个数, 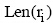
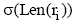
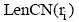
产品特征和评论观点的抽取是意见挖掘的两项重要任务, 产品评论质量的高低很大程度取决于评论文本中评价句数量的多少。因此, 如何识别评论中的评价句, 是本文特征提取的重点。众多学者利用句法词性搭配结构来提取中文产品评论中的产品特征信息[ 9, 10, 11, 12, 13, 14]。其中, 冯秀珍等[ 12]对产品评论词性分析后, 选择表达产品特征及评价最为常见的词性, 并进行重要程度排序(表达产品特征的词性重要程度依次是n>v>nv, 表达特征评价的词性重要程度依次是a>na), 实现对产品特征及语义的抽取。扈中凯等[ 14]在12个词性路径模板得出两个频率较高的词性路径模板, 23.7%的产品特征词和情感词符合“n+a”词性路径模板, 11.8%符合“n+d+a”词性路径模板。
经分析, 若评论句子中存在产品特征词, 则该句子具有评价句特征的概率很大。在实际评论中, 因评论作者的简写或省略, 较多评论句子中虽无产品特征词, 却有表达对特征评价的a和与表达情感有关的d、v或I, 该类评论句子也应具有评价句特征。故将词性路径模板用于评价句的检测, 同时为了提高分词系统对评价词的识别率, 在分词系统中加入自定义评价词词典。最终使用 表1所示的词性路径匹配模板集P, 按优先级顺序提取评价句。
| 表1 词性路径匹配模板集P |
对于评论中的每个短句, 本文认为如果和 表1中的任一模板匹配, 该短句就有评价句特征。如: “衣服收到了, 穿着挺好的, 质量还不错, 衣服大小合适, 颜色没图片上的鲜艳。卖家服务态度很好, 满意。”经过分词后得到:
衣服/n 收到/v 了/y ,/w 穿着/n 挺好/I 的/u ,/w 质量/n 还/d 不错/I ,/w 衣服/n 大小/n 合适/I ,/w 颜色/n 没/v 图片/n 上/f 的/u 鲜艳/a 。/w 卖家/n 服务/vn 态度/n 很好/I ,/w 满意/ I 。/w
提取具有评价句的特征为:
穿着 挺好, 质量 还 不错, 大小 合适, 颜色 没 鲜艳, 卖家 服务 很好
其中“衣服收到了”和“满意”两个短句和模板不匹配, 不是评价句, 其余5个短句有评价句特征。
为说明其可行性, 随机选取天猫商城中的童装、不粘锅和移动电源三类商品的评论, 评论文本长度 >20字符, 每类500条评论, 进行人工统计和实验分析对比, 结果如 表2所示:
| 表2 词性路径模板统计表 |
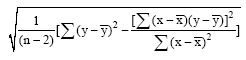 |
其中, x表示每条评论文本中实验提取的评价句总数, y表示每条评论文本中人工统计的评价句总数, n为样本总数500。
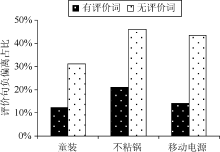
实验结果表明, 利用词性路径匹配模板来检测评价句, 其标准差和回归标准差都较小, 最大偏离百分比为24.69%, 验证了其可行性。另外, 若在分词时不加入自定义评价词词典, 在词性路径匹配模板中也剔除“I”匹配项, 则实验结果和人工统计的误差较大, 主要体现在评价句总数的负偏离上, 平均有24.50%包含评价词的语句未被识别, 如 图2所示:
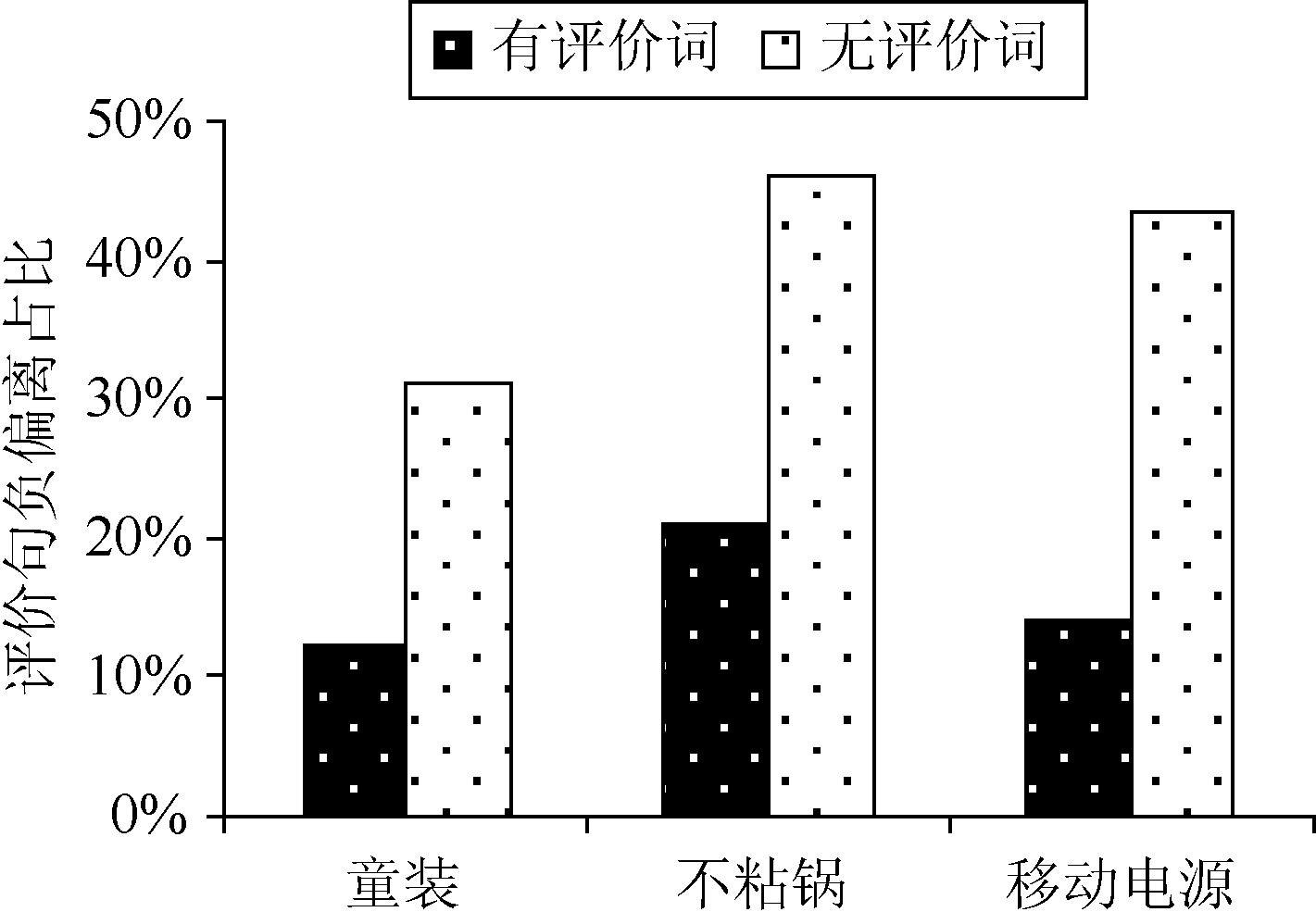 | 图2 评价词对评价句识别的影响 |
判断ri是否为评价句公式如下:
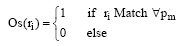 |
垃圾评论主要有以下几类: 评价词多次出现; 与当前产品无关, 而是对其他产品的评论; 掺杂着正常评论与广告信息; 未对具体产品属性评价, 却在其他方面过分褒贬的评论。据此特点, 本文从产品评论的评价句数量、主题词、情感倾向、文本结构和作者属性5个方面有针对性地提取14个特征, 如 表3所示:
| 表3 特征分类一览表 |
为区分该产品评论是否存在广告或与产品主题无关的信息, 根据表达产品特征的词性主要为n的特点, 在评价句中, 属于词性路径匹配模板前5类的, 抽取出其首次出现的n集合, 作为该评论的主题词。若某评论句较长, 出现多个表达产品特征的词语, 如连续多个n、d或a等, 则根据汉语修饰语的排序特点, 在词性路径匹配模板中, 提取最先匹配的n, 如评价句: “衣服/n 质量/n 很/d 不错/I”, 则提取“衣服”作为主题词。计算主题相关系数特征的方法如下:
假设经评价句特征提取后得到K个主题名词集合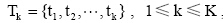
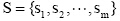
 |
其中, hit("S")表示在搜索引擎中查询S返回的页面数, hit("S" and "Tk")表示在搜索引擎中S和Tk共同作为关键字搜索所返回的页面数。
产品评论是表达消费者对产品各种特征的主观感受, 其情感倾向特征对其他潜在消费者的购买决策有很大影响。本文的情感倾向判断, 通过统计评论中每个句子的正面或负面情感倾向, 句子的情感倾向判断
采用Hu等[ 17]的方法。先利用极性词词典找出句子中的极性词并判断其极性, 再查找句子中去除该极性词后是否还存在“没”、 “没有”、“无”和“不”等否定词, 若存在就将评价句的极性取反。因每个评价句较短, 故不必考虑多重否定的情况。若整条评论中, 特征F5或F6中有一个为0, 且另一个值相对较大, 则可能是过分褒贬的垃圾评论。
因含广告的垃圾评论一般内容较长、句子长短不一, 包含URL链接地址、QQ号和其他非汉字字符等, 故本文参考Chen等[ 18]的研究并结合中文文本的特点, 在评论文本结构方面选择F7-F12特征, 从而区分含广告或特征词重复的评论。
鉴于目前专门对中文垃圾产品评论检测或识别的研究较少, 且尚无公开的中文标准数据集。为使实验数据集更具代表性, 在网上交易数量前三位的商品种类[ 1]中, 通过定制爬虫程序随机抓取天猫商城和京东商城上销量较大的6种商品评论信息。经评论文本去重、HTML标签替换和删除评论文本长度≤20字符的低质量评论等预处理工作后, 在6种商品中各随机选择1 500条评论作为实验数据集, 最后对数据集中的垃圾评论进行人工标注, 具体分类统计情况如 表4所示。其中, 评论文本长度≤20字符的评论平均占评论总数的63.46%, 且多数为易识别的垃圾评论, 故将其剔除。
| 表4 实验数据分类统计表 |
分类工具采用LibSVM[ 19], 核函数采用径向基核函数, 训练时控制SVM对输入量变化的敏感程度的γ参数, 经交叉验证后定为0.8, 其余参数用默认值。选用文本分类器中最常用的评测指标, 即准确率、召回率和F值作为垃圾评论识别的评判标准。因京东商城无匿名评论, 故实验先用天猫商城的三类产品评论的混合数据, 随机选取80%数据作为训练集, 剩下20%为测试集。连续实验5次后对结果取其平均值, 验证所提取特征的可行性, 并与文献[5]的评测指标进行对比。随后采用交叉验证的方法, 分别用天猫商城的其中一类产品评论作为训练集, 逐个对其余5种产品评论进行测试, 以检验该检测模型是否具有不同类别产品评论的泛化性。
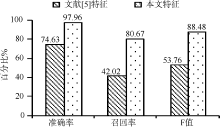
分别使用本文方法与文献[ 5]的特征提取方法, 对天猫商城中的三类产品评论的混合数据进行垃圾评论检测效果对比, 结果如 图3所示。相对于文献[5]提出的11个特征, 本文提取的特征识别准确率和F值均有较大提高(文献[ 5]的实验数据集中包含文本长度≤20字符的低质量评论, 其最好的实验结果识别准确率为78.16%、召回率为72.18%、F值为75.05%)。
 | 图3 垃圾评论识别结果对比 |
交叉验证垃圾评论的识别实验结果如 表5所示:
| 表5 交叉验证实验结果统计表 |
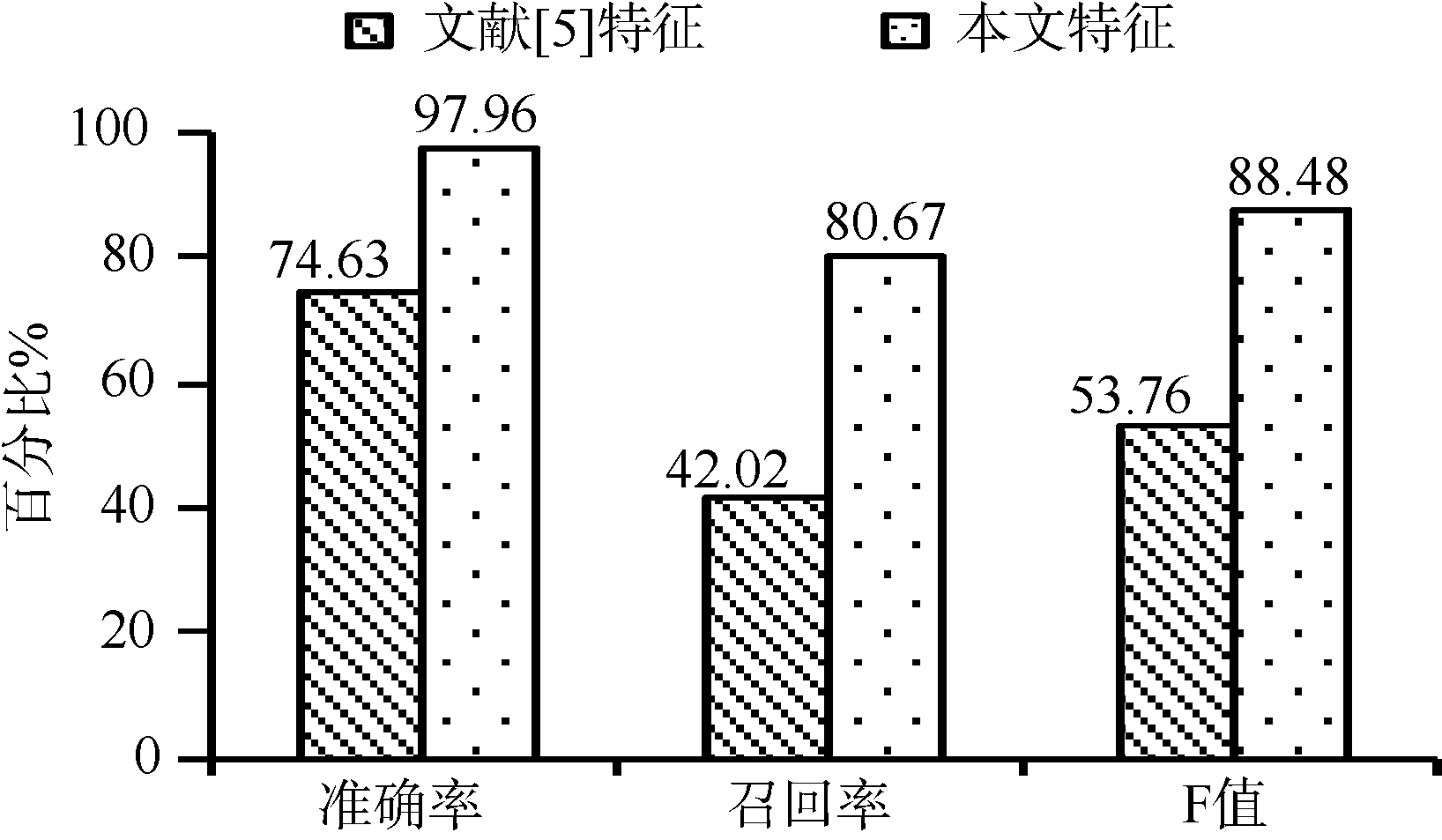
虽不同商品的训练数据生成的模型文件, 对其他商品的垃圾评论识别有一定的影响, 但平均垃圾评论识别的准确率为83.60%、召回率为75.19%、F值为78.52%, 说明本文所选特征的有效性, 且对不同类别产品评论的泛化性较好。其中, 6种产品的垃圾评论信息中, 非评价句(垃圾评论句)在每条评论信息中平均所占比重均较大, 分类统计如 图4所示, 表明评价句特征在区分垃圾评论和正常评论中的重要性。
 | 图4 垃圾评论中非评价句所占比重 |
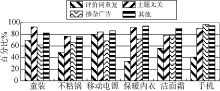
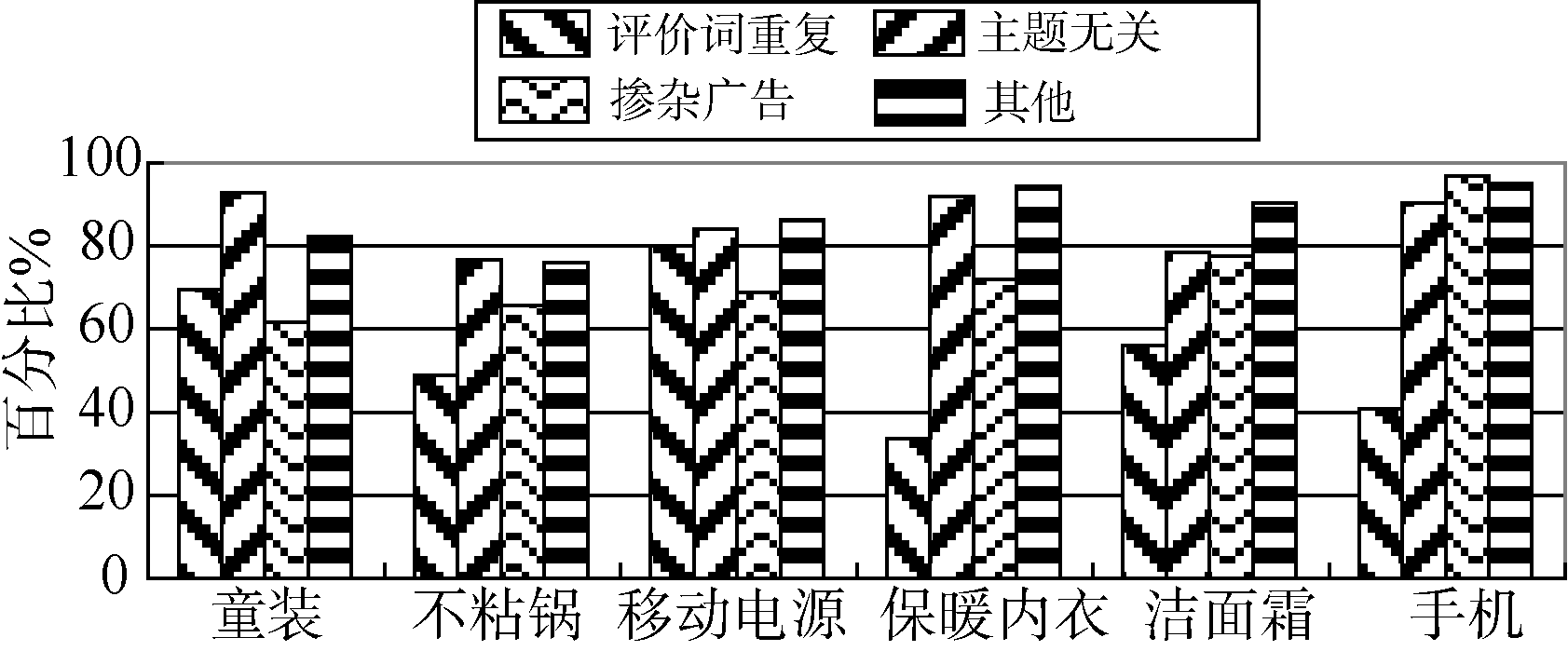
从垃圾评论分类看, 京东商城中带广告的垃圾评论相对较少, 但评价词重复、与产品无关的垃圾评论较多。而天猫商城中则掺杂广告的垃圾评论较多, 分类统计情况如 图5所示。另外, 本文提取的特征是为了过滤中文垃圾评论, 如果评论内容为英文、汉语拼音或含有较多英文商品名称, 则会被识别为垃圾评论。
 | 图5 垃圾评论分类统计 |
本文通过分析电子商务中在线交易产品评论信息, 从评论信息是否对消费者购买决策有积极作用出发, 提出量化评价的概念, 给出了识别评价句的方法, 综合5个方面有针对性地提取14个产品评论文本特征。实验证明, 该特征能够较好地区分垃圾产品评论, 识别准确率为97.96%、F值为88.48%。虽利用评论主题词和产品名称计算PMI值, 需依赖百度搜索引擎, 但绝大多数评论主题词数量较少, 只需在首次碰到时计算即可。考虑到不同时期的结果可能不同, 系统模型参数可定期进行更新。为能够识别产品评论英文商品名称, 后续的工作可考虑加入英文词典, 以提高垃圾产品评论的识别率。同时, 利用本文提取的评价句数量特征, 并结合其他特征, 进行产品评论有用性量化评估, 为产品评论有用性排序提供理论与技术基础。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|