
{kind=link}
{kind=link}
一种基于复杂网络的中文文本表示算法
[杨志墨 , 刘怀亮, 赵辉]
, 刘怀亮, 赵辉]
, 刘怀亮, 赵辉]
|
|


作者贡献声明:
杨志墨:提出论文的架构, 设计研究思路;
杨志墨, 赵辉:采集实验语料, 进行分类实验;
杨志墨, 刘怀亮:论文起草和最终版本修订。
【目的】为解决基于向量空间文本表示模型中语义信息缺失问题, 提出一种基于复杂网络的中文文本表示算法。【方法】利用维基百科中所蕴涵的概念、链接结构和类别体系信息进行词语间相关度的计算, 然后以此为基础将文本表示为以特征词为节点、词语相关关系为边及其相关度为权重的加权文本复杂网络。【结果】实验结果表明, 该文本表示方法可以提高文本相似度计算结果, 改善文本分类效果。【局限】文本网络中共现窗口的选择及跨度的选择规则借鉴的是已有研究。【结论】该文本表示方法可以较好地保留文本的结构信息及词汇间的关联信息, 且利用基于维基百科的词语相关度计算方法使文本网络所表示的语义信息更加准确。
[Objective] To solve the problem of the semantic deficiency in text representation based on Vector Space Model, this paper proposes an algorithm of Chinese text representation based on complex network.[Methods] Word relevance is calculated based on the concept pages, link structure and category system which are extracted from Wikipedia. Then, it represents the feature words of texts as nodes, and puts the semantic relevance relation between words as the edges, and uses the word relevance as edge weight of weighted complex network.[Results] Results of experiments show that the proposed text representation method can improve the calculation of text similarity and improve the performance of text categorization.[Limitations] The selection rules of co-occurred window and span in this paper draw lessons from the existing researches.[Conclusions] This text representation method can better keep the structure information and the correlation information between words. Besides, the computation method of word relevance based on Wikipedia makes semantic information represented by the text network more accurate.
文本表示是文本挖掘的基础, 目前文本处理中广泛采用的是基于向量空间模型(Vector Space Model, VSM)的文本表示方法[1]。该文本表示方法虽具有操作性强及计算简单等优点, 但由于它假设特征词之间是独立的, 因而造成词语间语义关系及文本结构信息的缺失。此外, 在处理海量信息时, 该模型也存在高维性和稀疏性的问题, 这些问题都在一定程度上影响了后续文本挖掘的效果。
近年来, 随着人类语言中复杂网络特性的发现, 国内外一些学者开始研究利用复杂网络对文本进行表示, 主要集中在研究以词的共现关系为基础构建的文本网络[2, 3, 4, 5]方面。该方法通常将文本中的词定义为复杂网络中的节点, 它们之间的共现关系则被定义为边, 以保留词语间的语义关系。根据是否考虑边权重因素, 又可分为无权网络和加权网络。通过复杂网络虽然可以较好地保留文本的结构信息及词汇间的关联信息, 但是在文本复杂网络的构建中, 边的构成方法主要以基于词共现法为主[6], 其中词语间的语义相关关系的
计算主要以基于语料库的方法为主[7, 8, 9], 该方法受语料库影响较大, 不能准确反映出词语间真实、客观的语义关系, 使得文本表示出现偏差, 从而也影响了复杂网络文本表示的效果。
针对上述问题, 本文在前期研究复杂网络文本表示方法的基础上, 区别于文献[9]采用的基于共现频率的词语相关度计算方法, 利用维基百科作为知识源, 通过抽取其所含有的类别、概念及其链接等信息进行词语相关度计算, 以准确衡量词语间的语义关系, 进而以此为基础构建文本加权复杂网络进行中文文本表示, 从而提高文本表示的准确度。并结合复杂网络节点加权度特性对文献[9]采用的基于最大公共子图文本相似度计算方法进行改进, 提出一种基于复杂网络的文本相似度计算方法。实验结果表明, 利用复杂网络对文本进行表示相比向量空间模型文本表示法具有较好的效果。
复杂网络就是结合网络的视角和基本原理的复杂系统, 其中系统中的基本元素或者某种现象被抽象为节点, 而研究对象(两元素或现象)间的关系则被定义为节点的连接边。单一文本复杂网络是用复杂网络视图研究的单一文本结构, 它通常将文本中的语素(字、词)定义为节点, 将字或词间的关系定义为边, 常见的连接关系有共现关系、概念同义、句法关系等。
词语间语义关系一般分为相似关系(等同关系)、相关关系、上下位关系(等级关系)等。现有的基于语义词典(如知网、同义词词林、WordNet等)、基于语料库的方法基本上都是解决词语语义间的相似关系, 而不是度量词语间的语义相关关系。语义相似性和语义相关性是两个不同的概念, 词语间在语义上的相似性指的是两词语在语言应用中的可替代性, 其大小反映了可替代性的强弱, 其本质是词语间拥有某些共同的语义内涵及相同的属性取值[10], 如:开心与快乐。而词语间的相关性反映的是两个词汇在语言应用中在语义上具有的某种相互依赖、相互影响特性, 如相互对立和矛盾(如“ 民主” 、“ 集中” ), 因果关联(如“ 地震” 、“ 海啸” )等关系, 它们之间的关系通常是不可替代的。
国内外对词语相关度计算的研究策略中以基于语料库的方法为主, 该方法利用大规模的语料进行统计, 即将词语在语料库中的频数或者概率分布等统计信息作为词汇语义相关度计算的主要指标; 除此之外, 基于世界知识的相关度计算方法主要基于按照概念间结构层次关系组织的语义词典, 根据概念之间的关系计算词语的相关度[10]。基于语义词典或者本体的方法虽然能够计算词语间的相关关系, 但由于语义词典或者本体涉及的范围与领域有限, 并且词汇的更新速度慢、可扩展能力较差, 所以其效果有时并不理想, 而且目前主要是应用于相似度的计算。
目前, 相关关系量化方法主要有协方差[11]、互信息[12]和共现频率[13]等, 其中共现频率是基于语料库的词语相关度计算的主要方法。基于共现频率方法的基本原理是:在统计语料中对在一定长度窗口单位的两个词进行统计, 它们之间的相关度随着其共现频率的增高而增大。
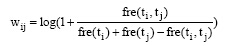 |
其中, fre(ti, tj)表示特征词ti和tj在一定长度窗口单位中共现的频率, fre(ti)、fre(tj)则表示特征词ti和tj在文本di中出现的总频率。fre(ti, tj)越大, 则特征词间的语义相关关系越密切。
基于共现频率的相关度计算方法主要存在的问题是[10]:
(1) 由于语料规模的限制, 如果一些词语没有共现在一定长度窗口单位中, 则其相关关系为0, 这与事实不符。
(2) 词语间相关度计算受低频词的影响较大, 例如:“ 安全” 和“ 警报” , 如果这两个词有一个出现的频数较小的话, 则其共现的次数也就较少, 那么相关度计算的结果就偏小, 这同样不符合实际。
(3) 相关度计算结果的值普遍偏小, 不利于相关度大小的比较和区分。
由于文本中的词语之间不是随意组合的, 离散的字、词语正是通过一定的语义相关关系组合在一起, 才得以形成文本。特别是中文, 丰富的词语语义关系组成了语义丰富的句子、段落、文本等, 进而通过文本传递信息。传统的基于向量空间模型的文本表示方法忽略了文本中重要的词语间的语义相关关系。与向量空间文本表示方法最大的不同在于, 本文提出的基于复杂网络的文本表示方法在文本表示中考虑词语间语义相关关系及上下文结构因素。此外, 以词语间的共现关系为基础构建文本加权复杂网络, 为准确、客观地衡量共现词语间的语义相关关系, 通过引入维基百科来解决已有词语相关度计算的不足。
本文将文本加权复杂网络形式化表示为G=(N, E, W)。N表示节点的集合, N={n1, n2, …, nk}, n表示经过预处理后的原始特征词, k表示复杂网络中的节点个数。E表示加权复杂网络中边的集合, E={eij=(ni, nj)| ni, nj∈ N}。W表示边的权重集合, W={w11, w12, …, wij, …}, wij表示边eij的权重。
复杂网络文本表示过程如图1所示。本文构建的文本加权复杂网络由节点、边及边的权重构成, 其中节点对应文本的特征词, 边表示特征词间的语义相关关系, 在文本中体现为特征词的共现及邻接位置关系, 而边的权值代表特征词的语义相关关系的程度, 权值越大, 表明特征词之间语义相关关系越强。
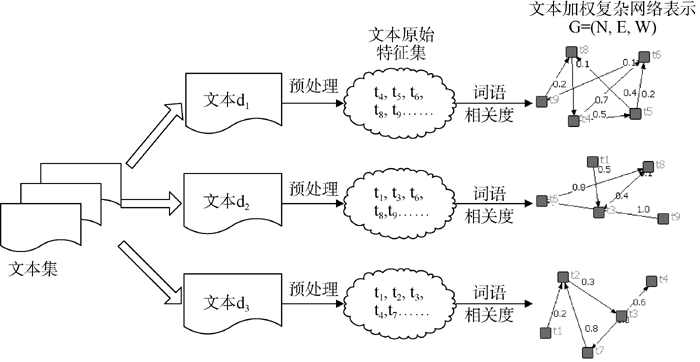 | 图1 复杂网络文本表示过程 |
由于互联网中文本有时会包含较多的缩写词、流行语、专业术语等词语, 普通的语义词典难以识别, 在词语相关度计算时会造成大量的未登录词出现, 而维基百科与传统的语义词典不同, 它作为一个以开放和用户协作编辑为特点的Web2.0知识系统, 具有知识覆盖面广, 结构化程度高, 信息更新速度快等优点[14]。
此外, 基于维基百科词语相关度计算方法可以有效解决基于语料库相关度计算方法(如共现频率法)对语料库的依赖, 从而在一定程度上减少了文本中词频信息对相关度计算结果的影响, 使得计算结果更加符合实际。
以维基百科知识库为数据源, 本文利用其所蕴含的链接结构和类别体系分别计算概念距离和类别距离, 然后将这两个值进行线性组合计算概念间的相关度。首先将词语转化为主题概念, 即进行词语-概念匹配, 其次进行概念间的语义相关关系量化, 以完成词语相关度的计算。
(1) 词语-概念匹配是将词语ti与tj映射为维基百科中存在的主题概念Ci与Cj。当该词语ti与tj存在重定向时, 分别以重定向的概念作为它们的主题概念。
(2) 进行概念间语义相关关系量化, 如果在步骤(1)概念匹配中, 存在特征词无法匹配为概念的情况, 则不进行概念间相关关系的量化, 此时ti与tj由共现频率法确定。
在词语相关度计算中, 对于匹配成功的词语, 基于维基百科的相关度计算方法可以消除共现频率法受文本本身词频影响较大的问题, 可以更加客观地反映词语间的语义相关关系, 而未匹配的词语则采用共现频率法, 目的是完整地构建文本网络。由于本文后续采用图匹配法原理计算文本的相似度, 所以集成两种方法可以在一定程度上提高图匹配过程的精度。
如果步骤(1)匹配成功, 那么通过概念间链接距离和类别距离综合衡量其相关关系强弱, 具体计算方法如下:
(1) 链接距离
计算链接距离的方法运用Milne等[15]提出的基于维基百科链接的概念间语义相关度计算方法 (Wikipedia Link-based Measure, WLM)的思想。本文定义的概念Ci, Cj间链接距离计算公式如下:
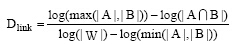 |
其中, Dlink是概念Ci, Cj间的语义距离, A, B是在维基百科中分别与概念Ci, Cj有相互链接关系的概念集合, W则是维基百科中所有概念解释页面的集合。符号“ | |” 表示取集合中的实体数量。
(2) 类别距离
为减少主题概念页面间链接的稀疏性对相关度计算的影响, 在链接距离的基础上, 通过计算概念所属的类别之间的距离, 以便更准确衡量概念之间的相关度。
由于概念可能属于多个类别, 因此, 本文将概念在多种分类关系下不同最短路径中的最小值作为两概念之间的类别距离, 则概念Ci, Cj之间的类别距离计算公式为:
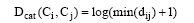 |
其中, dij代表概念Ci, Cj所属类别之间的最短路径距离, 对结果进行Log计算是为了使dij变化幅度平均化, 抑制类别距离与链接距离之间过大的差异。
(3) 相关度计算方法
综合考虑以上两种因素, 本文定义的概念Ci与概念Cj间的概念语义距离计算方法形式上表现为链接距离Dlink和类别距离Dcat的线性组合, 如下所示:
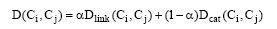 |
其中, α (0≤ α ≤ 1)为调节参数。由此, 在概念间语义距离的基础上, 本文将概念间的相关度计算公式定义为:
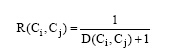 |
最后, 将概念Ci, Cj间相似度作为其所对应词语ti与tj间相关关系的计算结果, 并以此为基础作为文本加权复杂网络中权重的计算方法。
以上述基于维基百科词语相关度计算方法为基础, 提出如下文本表示算法, 具体过程是:
(1) 对中文文本di(1< i< n)进行预处理, 即分词及去停用词的过程。
(2) 经过预处理后, 文本di被表示成特征词的集合, 即di={t1i, t2i, …, tmi}。将特征词作为节点, 采用Cancho等[16]提出的边连接规则, 即将在同一个句子中跨度小于等于2的特征词建立连接关系, 因为常见的相关词在文本中的距离一般都比较接近。虽然存在部分相关词语跨度大于2, 但是这种情况比较少, 此外跨度过大可能会将大量语义无关或相关性很小的词连接起来, 不仅容易产生冗余信息, 也影响了文本语义表达的准确度[17]。
(3) 通过维基百科对节点所对应的原始特征词进行概念匹配, 将其转化为概念网络, 以解决同义词现象。
(4) 对于概念网络中的节点边eij的权重wij, 利用3.2节中基于维基百科的语义相关度计算方法来衡量概念所对应特征词间的语义相关关系。
经过上述步骤后, 文档di的原始特征集合di={t1i, t2i, …, tmi}就转化为由节点集合N={n1, n2, …, nk}、连接边集合E={eij=(ni, nj)|ni, nj∈ N}以及权重集合W={w12, w13, …, wij, …}共同组建的文本复杂网络Gi={[n1, n2, e12, w12], [n1, n3, e13, w13], …, [ni, nj, eij, wij], …}。
利用加权复杂网络对中文文本进行表示后, 通过提取复杂网络间的最大公共子图来衡量文本的相似部分, 从而利用最大公共子图所含有的语义信息量来度量文本间的相似度, 计算步骤如下:
(1) 提取文档di与dx所对应网络SGx与SGy间的最大公共子图[18];
(2) 以最大公共子图为基础进行文本相似度计算。
文献[18]虽然在文本相似度计算中考虑了节点的相似度与边的相似度, 但是未考虑文本网络间最大公共子图提取中相同节点在不同文本中的权重因素, 一方面相同的词语在不同文本中对主题类别的贡献度不同, 另一方面不同类别间文本可能会包含一些交叉的词语, 如果单纯提取共有节点, 不考虑节点在所在文本中的重要性, 可能会造成后续计算的偏差。因此本文在最大公共子图的度量中考虑了节点权重, 定义节点的加权度WD[19]为节点在其原有文本网络SGx与SGy的权重。则相应的最大公共子图度量方法, 即文本网络SGx与SGy的相似度计算方法如下:

其中, max(SGx, SGy节点数)表示两网络中含有的最大节点数; max(SGx, SGy边条数)表示两网络中含有的最大边条数; WDij, WDij° 分别表示相同节点在不同网络中的节点加权度, 即表示最大公共子图节点在其原有网络中的权重; wij, wij° 分别表示网络SGx与SGy中对应边eij, eij° 的权重; eij, eij° 为网络中相同特征词对应的边, β∈(0, 1)。
由于文本表示是各类文本处理技术的基础, 其效果直接影响最终的文本处理结果。因此, 为验证本文提出的文本表示方法的效果, 以文本分类为例, 对其效果进行评价并加以验证。此外, 采用文本处理中常用的F1值[20]作为评价方法。
实验语料来自新浪网、新华网、凤凰网等网站的新闻。从中选取娱乐类、财经类、体育类、教育类、军事类、科技类各500篇。实验采用5折交叉验证法, 将每类文本随机平均分为5份, 4份为训练集, 1份为测试集。其中每份轮流作为测试集, 循环测试共5次, 取平均值为最终测试结果。实验过程中分词统一采用ICTCLAS, 并结合KNN分类算法[21]进行分类处理。
(1) 文本相似度计算中β 的确定实验
为确定文本相似度计算β 的取值, 以得到较好的文本相似度计算结果, 首先进行不同β 值下的文本分类效果对比实验, 实验中统一采用共现频率法进行词语相关度计算, 对比结果如表1所示:
| 表1 不同的β 下的实验结果F1(%)比较 |
由表1可以看出, 当文本相似度计算中β 取0.6左右时, 文本分类效果达到最佳, 表明文本表示的效果较好, 因此后续实验中文本相似度计算中β 取0.6。
(2) 词语相关度计算中α 的确定实验
为确定词语相关度计算中α 的取值, 以得到较好的词语相关关系量化结果, 进行不同α 值下的文本分类效果对比实验, 实验中统一采用本文所提出的基于复杂网络的文本表示方法及相似度计算方法, 对比结果如表2所示:
| 表2 不同的α 下的实验结果F1(%)比较 |
由表2可以看出, 当词语相关度计算中α 取0.7时, 文本分类效果达到最佳, 表明文本表示的效果较好, 因此后续实验中词语相关度计算中α 取0.7。
(3) 不同文本表示方法下的文本分类效果对比实验
本次实验共分为4组, 每组的具体步骤如下:
第1组基于向量空间模型的文本分类方法, 采用向量对文本进行表示, 并结合向量夹角余弦法进行文本相似度计算完成文本分类。
第2组采用基于共现频率的词语相关度计算方法进行文本网络的权重计算, 从而以此为基础进行文本复杂网络表示, 文本相似度计算采用本文的方法。
第3组采用本文提出的词语相关度计算方法, 但是在文本相似度计算中采用文献[18]的方法。
第4组采用本文所提出的基于维基百科的词语相关度计算方法进行词语间相关关系的衡量, 从而完成文本的加权复杂网络表示, 最后文本相似度计算采用本文提出的方法。
实验结果如表3所示:
| 表3 实验结果 |
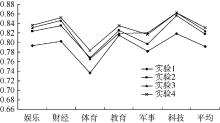
对不同文本表示方法的F1值进行比较, 如图2所示:
 | 图2 F1值对比 |
从表3、图2可以看出, 本文提出的文本表示方法与其他方法相比, 在分类效果上整体有所提高。其中实验4与实验1相比表明, 采用复杂网络表示文本可以较好地保留文本中词语间的语义关系及文本结构信息, 从而能提高文本表示的效果。而实验4与实验2相比则说明采用本文提出的文本表示法中利用维基百科度量词语间的语义相关关系比基于共现频率的方法有较好的效果, 可以在一定程度上使得文本网络所表示的语义信息更加准确。此外, 实验4与实验3相比表明考虑节点权重也利于文本相似度的计算, 可以提高文本处理的效果。
由于在文本分类对比实验中各方法的区别都在文本表示环节, 文本分类结果的提高证明了本文所提出的文本表示方法较其他方法可以较好地表示文本所蕴含的语义信息, 从而提高文本相似度计算结果, 改善文本分类效果。
随着大数据时代的到来, 如何快速、准确地获取用户所需的信息变得越来越重要, 而文本表示作为文本信息处理的基础, 必然得到广泛关注。本文针对传统的基于向量空间模型文本表示法忽略词语间语义关系, 以及已有的词语相关度计算方法准确度不高的问题, 提出一种基于复杂网络的文本表示算法。该方法通过构建文本加权复杂网络来表示文本的结构信息、词语及语义相关关系信息, 通过引入维基百科, 综合考虑链接距离及类别信息进行词语间的相关度计算。此外, 提出一种面向复杂网络文本表示的文本相似度计算方法, 实验表明, 本文所提出的文本表示方法可有效提高文本表示的效果。下一步工作是进一步对文本网络中共现窗口的选择及跨度的选择进行探索和改进, 以适应中文文本的特殊性及不同的文本长度。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|