{kind=link}
{kind=link}
从互联网上自动获取领域平行语料
[邵健, 章成志 ]
]
]
|
|


作者贡献声明:
邵健: 设计研究方案, 实验设计与实施, 数据清洗与分析, 论文起草;
章成志: 提出研究思路, 讨论研究方案, 数据采集及分析, 最终版本修订。
【目的】对获取的双语语料进行分类, 对分类后的双语语料进行句子对齐处理, 生成领域平行语料。【方法】利用基于SVM算法的文本分类器对获取的中英双语语料进行分类。使用长度法和词汇法相结合的句子对齐工具对分类后的语料进行句子对齐工作, 为提高句子对齐的正确率, 利用人工对齐的中英平行语料计算中英文句子长度参数, 结合中英双语词典, 获取高质量的专业领域平行语料。【结果】使用该方法, 对每个领域语料进行句子对齐后, 取得95.45%的句子对齐正确率。计算得到的句子平均长度比为1.7777, 方差为1.2640。【局限】由于双语语料的初始对齐程度比较好, 因此句子对齐正确率可能不具有普遍代表性。【结论】从实验结果看, 该方法是有效的, 能够获取质量令人满意的领域平行语料。
[Objective] To automatically obtain domain parallel corpora via classified bilingual corpora and sentence alignment.[Methods] Classify bilingual corpora based on text classification technology, use sentence alignment tool to align classified bilingual corpus based on length information of bilingual sentence and bilingual dictionary. This paper uses artificial aligned bilingual corpora to calculate length parameters.[Results] The results obtain 95.45% rate of sentence aligned correctly. The length mean is 1.7777 and variance is 1.2640.[Limitations] Due to the extent of the initial alignment of bilingual corpus is satisfied, so the result of alignment is not universally representative.[Conclusions] The result proves the method presented in this paper is effective, so this method can acquire high quality domain parallel corpora.
平行语料是一种很有利用价值的资源。如在统计机器翻译领域, 需要利用平行语料训练模型, 进行翻译工作。翻译的效果受到语料规模大小的影响, 一般情况下, 语料库的规模越大翻译质量就越高[1]。然而, 初始获取的双语语料包含大量噪音, 双语句子之间存在着缺失、错位、一对一、一对多等现象, 需要经过处理才能使用。使用句子对齐技术可以解决上述问题, 句子对齐技术是根据双语句子之间的特征找出最匹配的句子, 常用的句子特征有长度信息、词汇信息、标点符号和位置信息等。准确计算出双语句子的特征信息能够提高句子对齐的准确率, 获取高质量的平行语料。
平行语料所属的领域不同也会影响翻译效果。统计机器翻译系统需要从经过句子对齐和词对齐的平行语料中学习翻译知识。因此, 训练语料所属领域与测试语料所属领域的重合度也在一定程度上影响着翻译效果, 当重合度大时, 翻译效果较好。当在特定的领域中使用平行语料时, 专业领域平行语料具有比一般平行语料更好的应用效果。
以往关于平行语料的获取研究只注重平行语料的规模和质量, 对领域平行语料的研究比较少。为了获取高质量的领域平行语料, 本文首先采用文本分类技术对获取的双语语料进行分类, 获取不同类别的双语语料。然后结合双语词典和句子长度信息使用句子对齐工具对分类后的双语语料进行句子对齐处理, 最后生成高质量的领域平行语料。
平行语料的获取主要有两种方法。一种方法是从各种数据库或文献中挖掘平行语料, 例如各国法律文献、专利数据库等。吴琳等[2]利用网页的URL命名特点获取专利数据库的网页, 最终获取双语语料。另一种方法是从双语Web站点获取双语语料资源, 进行处理后生成平行语料。随着互联网的发展, 越来越多的网站提供双语信息, 这使得互联网成为一个蕴含着丰富双语资源的潜在双语语料信息源。这也推动了基于Web获取平行语料方法的发展。
互联网中蕴含的双语语料大多以网页的形式呈现, 因此基于Web的方法主要是对双语平行网页的抓取、验证以及提取双语语料。具体步骤为: 获取双语网站以及过滤无关网站, 获取候选双语网页, 过滤候选双语网页, 抽取平行句对。基于Web获取平行语料的系统有STRAND[3]、BITS[4]、PT Miner[5]、WPDE[6]、Pupsniffer[7]等。
由于互联网网页的复杂性, 获取平行语料的步骤主要可分为平行网页的获取和抽取平行句对。在获取平行网页时, 先从互联网中获取可能含有双语信息的网站, 这种类型的网站称为候选双语网站。微软WPDE系统[6]利用锚文本和图片的ALT信息搜寻双语网站。利用URL模式和HTML结构可以从候选双语网站中筛选出候选双语网页, 除PT Miner[5]同时利用了这两种信息外, 其他系统只单独地利用其中一种信息。刘奇等[8]利用URL模式和HTML结构相结合的方法获取平行网页, 并显著提高了机器翻译的质量。筛选出候选网页后, 就是平行网页验证步骤, 这一步主要是验证候选网页是否是真的平行网页, 为后续的平行句对抽取做准备。平行网页验证可以利用句子之间的长度信息、HTML标签和词汇等信息。
互联网中包含各个不同领域的信息, 经过上述步骤处理后的语料是混杂的。领域平行语料对统计机器翻译、专业领域双语术语抽取等领域来说是重要的基础数据资源。因此, 从互联网中获取领域平行语料还需要对经过上述处理的数据进行分类, 然后对分类的语料进行句子对齐处理。
句子对齐技术用于调整双语语料之间的句子位置, 使之一一对应。一般来说, 双语语料中总会出现: 缺失、一对一、一对多、多对多等情况。句子对齐技术利用双语句子之间的特征找到最优的匹配模式。句子对齐的方法主要分为三种: 基于长度的方法(长度法)、基于词汇的方法(词汇法)、混合的方法。
长度法由Gale等[9]和Brown等[10]提出, 这种方法基于一个观察, 即源语言中长度较长的句子与目标语言中长度较长的句子对应的概率更大, 源语言中长度较短的句子与目标语言中长度较短的句子对应的概率更大。不同的是, Brown等[10]的方法是以词汇为单位计算句子的长度。
长度法一旦在对齐过程中出现错误的对齐结果, 就会影响后续句子对齐工作的准确度。词汇法由Kay等[11]提出, 这种方法的优点是准确率高, 缺点是对齐速度慢。Chen[12]认为Gale等[9]和Brown等[10]的算法只考虑句子长度, 忽略了词性, 因此构建了一个简单的词对词翻译模型。Church[13]利用英法语言中的同源词进行句子对齐工作, 取得了良好的效果。
考虑到长度法对齐速度快但准确率低且鲁棒性差, 词汇法对齐速度慢但准确率高且鲁棒性好, 因此有学者将上述两种方法结合应用到句子对齐工作中。Wu[14]使用领域词典结合句子的长度信息, 对中英文的语料进行句子对齐实验, 取得了较好的效果, 并研究Gale等[9]和Brown等[10]基于长度的方法在非印欧语系中的效果。Moore[15]在分析长度法和词汇法的利弊的基础上, 提出将句子长度信息和句子词汇信息综合利用的混合方法。
也有学者使用其他方法实现句子对齐, 如Fattah等[16]使用基于概率神经网络(P-NNT)和高斯混合模型分类器的方法, 研究英语和阿拉伯语的句子对齐。Sennrich等[17]使用基于机器翻译的对齐方法, 基本思想是计算机器翻译的文本和BLEU值的相似度, 以此找到可靠的对齐作为锚点。Trieu等[18]对Moore[15]的方法进行改进, 加入词聚类改善稀疏数据的问题。熊文新[19]对初次对齐的结果进行再对齐时加入语言学规则, 提高了对齐的正确率。
本文的目的是获取高质量的领域平行语料, 因此选择混合方法中长度法和词汇法相结合的方法, 这种方法改善了长度法的固有缺点, 也提高了词汇法计算的速度, 并且能够使句子对齐结果获得高正确率。
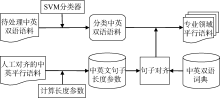
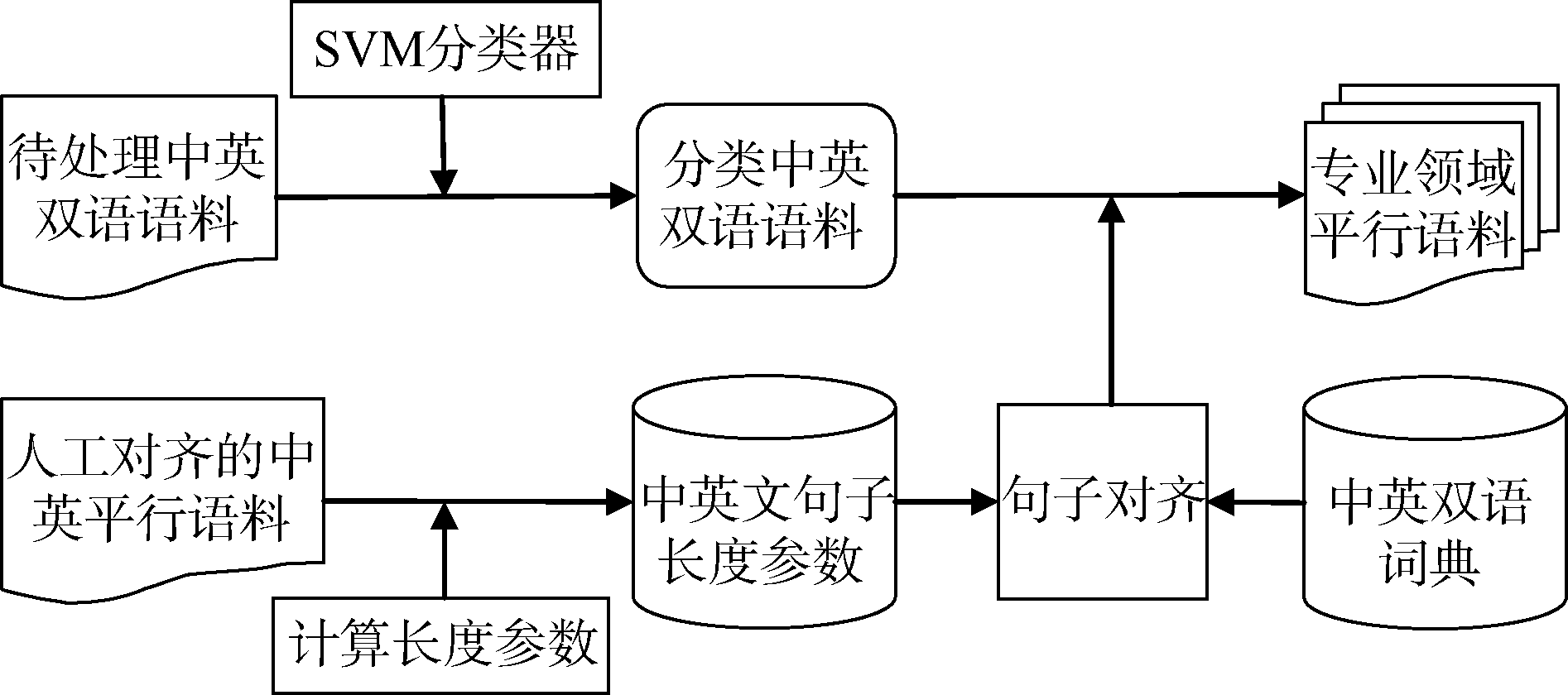
使用基于SVM算法的分类器, 对中英双语语料进行分类, 生成分类双语语料; 使用人工对齐的中英平行语料计算长度法所使用的长度参数; 利用句子对齐工具, 结合双语词典和中英句子长度参数对分类双语语料进行句子对齐, 生成领域平行语料。具体流程如图1所示:
为了获取高质量的领域语料, 文本分类是一个重要的环节。选择适当的分类算法对文本分类的准确率有重要影响, 基本的文本分类器算法有朴素贝叶斯、支持向量机(Support Vector Machine, SVM)、K-最邻近法、神经网络等。其中SVM是Vapnik[20]提出的一种高效的分类算法, 适合处理多分类问题, 特别适合处理大样本集合的分类问题。SVM将降维和分类结合, 在实际应用中取得了良好的效果。因此本文选择SVM算法作为分类器的分类算法。
在文本分类问题中, 特征的选取对文本分类结果也有着重要影响。应尽量保留文本中对分类有用的特征, 去除无用的特征, 特征选择能够提高分类效率, 并提高分类准确率。常用的特征提取方法有信息增益(Information Gain , IG)[21]、卡方检验(CHI)[22]、互信息(Mutual Information, MI)[23]、文档频率(Document Frequency, DF)[24]等方法。其中卡方检验可以用来检验两个变量的独立性, 基于卡方检验的特征选择方法的效果已在大量的实验中得到验证, 综合考虑后, 选择卡方检验作为特征选择方法。
文本分类是利用从训练集中得到的不同类别的特征词汇判断测试集中文本属于哪个类别。在本实验中, 考虑中国香港的新闻与中国内地的新闻用词上有许多不同之处, 因此本文未采用中国内地新闻分类训练语料作为训练集训练分类器, 而是采用中国香港新闻语料作为训练集。具体的步骤如下:
(1) 对训练集文本进行分词;
(2) 对训练集进行特征选择;
(3) 对训练集进行文本表示;
(4) 使用十折交叉验证法检验分类器的准确率;
(5) 对测试集进行分类。
(1) 中英句子长度参数
长度比及其方差的精确度对句子对齐的结果有重要影响。因此本文使用人工对齐过的中英平行语料计算这两个参数。由于双语语料存在1:1、1:2、1:0等多种对齐模式, 因此平行语料中的中英文句子数是不相等的。在计算时, 将对应的句子长度相加, 然后进行计算。例如, 1:2模式, 中文一句对应英文两句, 在计算时, 将两个英文句子的长度相加, 与一个中文句子的长度对应, 然后代入公式计算长度比。
根据Gale等[9]的定义计算中英句子的平均长度比, 如公式(1)所示:
其中, en为第n个英文句子长度, cn为第n个中文句子长度, n为句子总数, 由于长度法的鲁棒性差, 在中英句对齐中取得的效果不理想, 因此在实际中大部分是将长度法和词汇法或者其他方法结合使用。本文计算的长度参数可供后续句子对齐研究工作使用和参考。
(2) 句子对齐工具的选择
在对HunAlign[25], Champollion[26]和Bilingual Sentence Aligner[15]三种开源句子对齐工具进行研究之后, 综合考虑易用性、准确率、处理速度三个方面, 最终选择HunAlign作为本次实验的句子对齐工具。
①HunAlign[25]由匈牙利技术与经济大学和匈牙利科学院语言学研究所研发。所采用的对齐策略是Gale等[9]的长度法结合词汇法。在字典存在时, 使用字典和长度算法对齐双语句子; 在字典缺失的情况下, 则只采用长度法对齐双语句子, 然后利用上一步中对齐的句对生成双语字典, 进行再对齐。使用C++编写, 在处理大规模语料时, 能够高效过滤文本中低可信度的对齐结果。
②Champollion[26]最初是为了对齐中英句子而开发的, 由宾夕法尼亚大学语言数据联盟研发, 后来扩展了其他语言的句子对齐功能。它认为语料中是有噪音的, 并且考虑到复杂的句子对齐模式, 以及句子的缺失和插入等情况。采用词典对齐为主, 长度法对齐为辅的策略。不同的是, 它给每个相应的词汇使用TF× IDF计算权重, 认为句子中不同词汇对句子对齐的结果有着不同的影响。
③Bilingual Sentence Aligner[15]由微软研究院开发, 利用句子长度、对应词汇和同源词对齐句子, 取得了较高的准确率。使用长度法对语料库进行对齐, 选择其中对齐概率最高的结果训练IBM模型; 结合长度法和词汇法对语料库进行再对齐。它不需要外部词典, 采用Perl编写。
综上所述, HunAlign使用命令行操作, 在双语字典暂时缺失的情况下也能进行句子对齐工作, 并能自动生成双语词典。对齐不同的双语语料时, 只需更换双语词典及修改长度参数, 具备易用性。从准确性方面来看, HunAlign在对齐时不仅会给出结果, 还会给出句对之间的相似度, 可以根据需要, 调低或调高相似度的阈值生成不同质量的平行语料。HunAlign使用C++语言编写, 相比其他语言的处理速度, 占有优势。所以选择HunAlign作为句子对齐工具, 并使用中英双语词典, 将长度参数修改为中英文的长度参数。
本次实验从中国香港新闻资料库①(① http://www.isd.gov.hk/pr/chi/.)中采集测试语料, 所采集新闻的时间段为1998年4月1日到2014年1月31日。中国香港新闻资料库提供简体、繁体、英文三种文字的新闻。本文采集简体中文和对应的英文新闻文本。共采集60 254篇新闻, 每篇新闻作为一个文本, 共939 763个中文句子, 880 952个英文句子。
采用中国香港政府新闻网②(② http://sc.news.gov.hk/TuniS/www.news.gov.hk/tc/index.shtml.)的新闻语料作为训练集, 每类包含700篇文本。中国香港新闻网将新闻分为7类, 分别为: 财经、教育与就业、社区与健康、环境、治安、基建与物流、行政与公民事务, 本文按照以上类别对测试语料进行分类。
使用LibSVM[27]分类器对采集到的文本进行分类。LibSVM是Chang等基于SVM算法开发的分类与回归分析工具, 在使用时调整参数及调整格式以适合LibSVM进行计算。使用TF× IDF计算特征的权重, 特征数量为2 000。为了检验分类器效果, 使用训练语料进行十折交叉验证。
根据计算得出, 平均正确率P为0.794, 平均召回率R为0.797, F值为0.795, 计算公式如下:
其中, 正确率最低的类别是治安类, 正确率最高的类别是教育与就业类, 正确率从高到低排名依次为: 教育与就业、环境、行政与公民事务、基建与物流、财经、社区与健康、治安。本次实验所用训练语料存在的缺点是质量比标准的分类语料差, 例如每周都会有财经类金融指数报告、水质检测等新闻, 这些新闻造成词汇的重复, 对分类起干扰作用。各个类别的正确率和每次交叉验证的平均正确率如表1所示, 其中编号1-10指十折交叉验证实验的编号。
| 表1 SVM分类器十折交叉验证结果(正确率) |
使用从中国香港政府新闻网站采集的中文语料作为训练集, 测试集为从中国香港新闻资料库采集的语料, 共60 254篇文本, 对其中的中文文本进行分类。再按照中文文本的类别对相应的英文文本进行分类。经过分类后的结果如表2所示。
| 表2 分类结果分布情况 |
其中, 财经类有10 628篇文本; 教育与就业类有4 762篇文本; 社区与健康类有12 257篇文本; 环境类有4 930篇文本; 治安类有12 558篇文本; 基建与物流类有8 332篇文本; 行政与公民事务类有6 823篇文本。经过观察, 造成分类错误的主要原因是文本的长度过短及文本中数字所占比重太大。
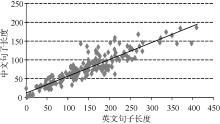
为提高对齐的准确率, 需要精确地计算长度参数, 本文使用经过人工对齐的中英平行语料计算平均长度比以及方差, 并使用此参数对齐句子, 其中包括771 512个中文句子, 800 354个英文句子, 中英句对739 919个。为探究中英文句子长度之间的关系是否符合Gale等[9]的研究, 因此对中英句子的长度进行抽样, 如图2所示:
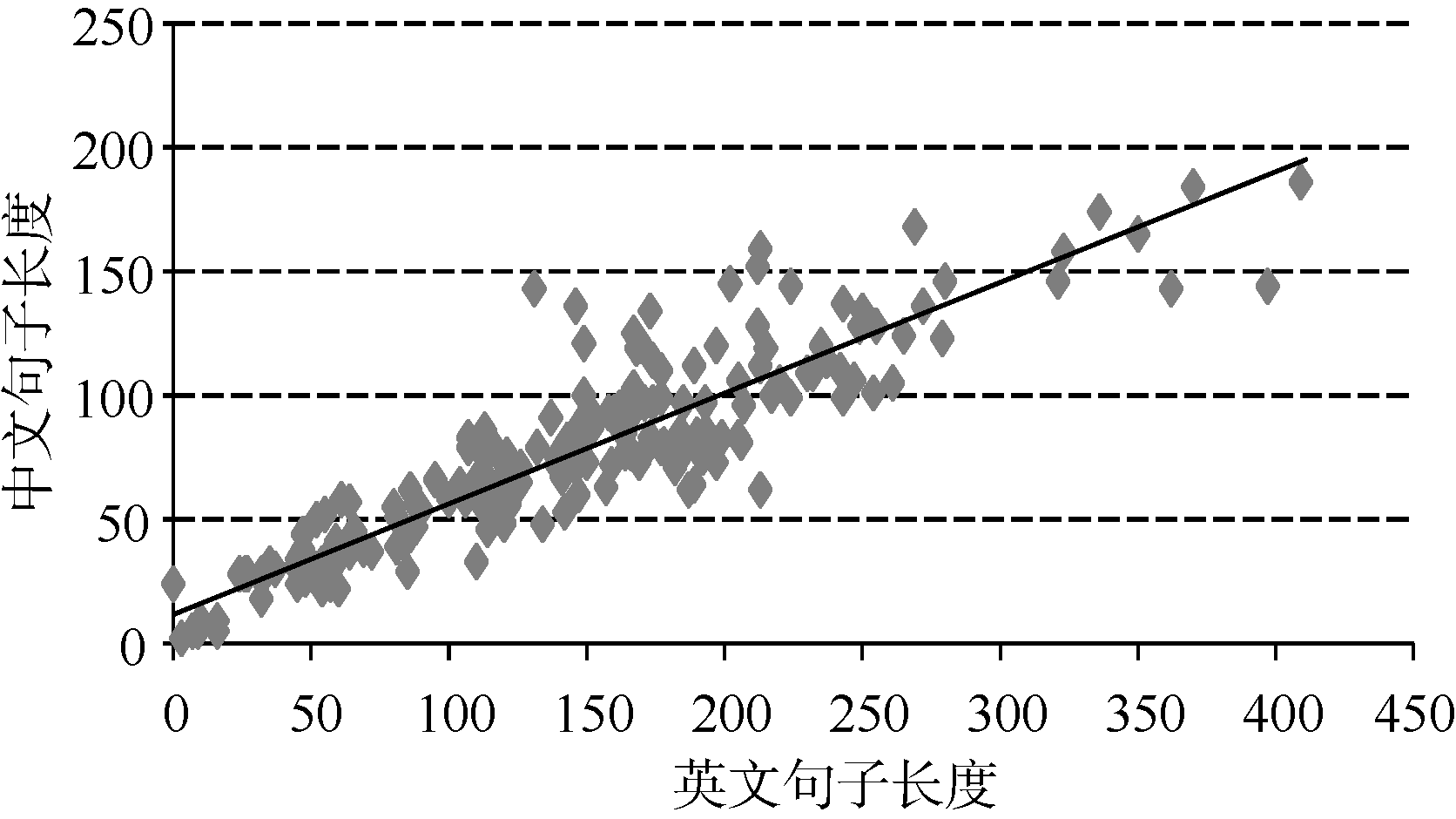 | 图2 中英句子长度抽样 |
图2表示的是中英句子长度的数据抽样, 横轴代表英文句子长度, 纵轴代表中文句子长度, 可以看到除了极少数的点无规律外, 大部分的点都呈现出很强的相关性, 利用此信息能够计算Gale等[9]定义的句子之间的相似度。
在获取的所有文本中不区分类别随机抽取1 000篇文本, 人工测评句子对齐的正确率, 共13 553个中文句子, 14 205个英文句子。对齐之后, 不对任何对齐模式进行排除, 一共有13 825个句对。然后将相似度小于零的句子和其他模式(2:2, 2:3, 3:3等)的句子排除, 统计正确率。经过筛选后的句子对齐总数为9 916个, 统计结果如表3所示:
| 表3 中英句子数统计 |
在统计句子对齐的正确率时发现, 长度比较短的句子对于对齐结果的干扰比较大。长度短的句子有较高的概率被合并到长度较长的句子中, 形成1:2或者2:1的对齐模式。这种对齐结果会干扰后续的对齐结果, 导致连续错误。本次对齐结果中的错误对齐也大多是这类错误。造成这种错误的原因是因为词汇法是利用词典匹配句子中的词汇, 以此计算双语句子之间的相似度, 句子中包含的词汇越多计算结果就越精确; 而短句子所包含的词汇量少, 在双语词典中对应的翻译词汇可能很少或者不存在, 就会造成计算结果的错误。本次实验使用的语料是中国香港新闻语料, 若使用中国内地的新闻语料对齐结果正确率会更高。
进行实验的中国香港新闻语料是质量比较高的语料, 初始状态时段落与段落之间是相互对应的, 因此笔者对段落之间设置了标记, 防止在出现对齐错误时发生错误蔓延的情况。其中相似度小于零的句对中也有正确的对齐结果, 但正确率相对较低。为了获取高质量的平行语料, 将相似度小于零的对齐结果排除。中文句子和英文句子用“< => ” 隔开, 句子后的数字为HunAlign结合长度法和词汇法计算出的句子之间的相似度, 句子对齐样例如下:
生产 总值 , 销货 总额 , 业务 收益 及 其他 收入 ; < => gross output, sales of goods, business receipts and other income; < => 2.09392
增加 价值 用以 量度 对 本地 生产 总值 的 贡献 ; < => value added a measure of contribution to Gross Domestic Product ; < => 2.3241
酒店 集团 对 香港 旅游业 充满 信心< => Hotel group shows strong confidence in HK tourism market< => 1.80519
外汇 基金 对 香港 私营 部门 的 债权 总额 为 1, 042 亿 港元 .< => Claims on the private sector in Hong Kong amounted to HK$104.2 billion.< => 2.11636
为了测量句子对齐之后双语语料的质量, 笔者使用GIZA++[28]对最终生成的平行语料进行词对齐, 然后训练NiuTrans[29]统计机器翻译模型, 并使用NIST08[30]标准测试集作为语料。将NIST08语料分为两部分: 一部分做开发集; 一部分做测试集。其中, 开发集为前1 000句, 测试集为后731句。最后测得BLUE值为0.137。
无论是双语术语抽取还是统计机器翻译都依赖于平行语料。在双语术语抽取中, 以双语核心术语对为双语术语种子, 利用大规模的平行语料, 抽取更大规模的双语术语。在统计机器翻译中, 对于其基于短语的方法、基于层次短语的方法和基于句法的方法, 都需使用平行语料训练翻译模型。而领域平行语料是对平行语料的进一步处理, 对专业领域双语术语抽取和统计机器翻译等领域有重要作用。
本文研究了平行语料的获取以及句子对齐技术, 使用一种快速获取高质量专业领域平行语料的方法, 对获取的双语语料进行分类, 之后进行句子对齐工作, 生成领域平行语料。探讨并分析了几种主要的句子对齐方法的优点和缺点, 从三个方面介绍了现有开源的句子对齐工具, 计算中英文句子长度参数。
未来工作包括: 提高分类和句子对齐的正确率、生成更高质量的领域平行语料、使用领域平行语料抽取领域核心术语、生成领域双语词典等。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|