{kind=link}
基于潜在语义分析的关键词-分类号对应关系研究
[夏冬1 , 肖晓旦1 , 李国垒1 , 陈先来1, 2  ]
]
]
|
|


作者贡献声明:
夏冬, 肖晓旦, 陈先来: 提出研究思路, 设计研究方案;
李国垒, 夏冬: 进行实验;
夏冬: 采集、分析数据, 起草论文;
陈先来: 最终版本修订。
【目的】通过探索关键词-分类号的对应关系, 为对照系统的建立打下基础。【应用背景】辅助不熟悉分类号的论文作者进行论文标引, 同时协助用户结合关键词和分类号完成更精确的检索。【方法】对构建的关键词-分类号矩阵进行奇异值分解, 得到关键词、分类号的三维语义坐标, 再根据查询提问式的向量表示与分类号坐标进行相关度计算并降序排序。【结果】相比单个、三个及三个以上关键词, 两个关键词与分类号的对应关系有较好效果。在100对包含两个关键词的词组中, 有91对能够确定至少一个相关的分类号, 准确率达到91%。【结论】两个关键词与分类号的对应关系结果较为理想, 为构建对照系统打下良好基础。
[Objective] This paper attempts to explore the relationship between keyword and Chinese Library Classification for building a foundation for the comparison system.[Context] To help the authors unfamiliar with CLC make indexing and to assist users to complete more precise retrieval through combining keywords with related CLC.[Methods] Through decompositing constructed Keywords-CLC matrix with SVD (Singular Value Decomposition), A three-dimensional semantic coordinates between keywords and CLC is obtained. Then, according to vector representation of a query and the CLC coordinates, the correspondence is calculated and sorted in descending order.[Results] Comparing with single, three or more keywords, the correspondence accuracy between two keywords and CLC achieved better results. Among 100 phrases containing two keywords, 91 phrases are able to determine at least one associated CLC, the accuracy rate reaches 91%.[Conclusions] The correspondence effect between the phrases of two key words and single CLC is positive and lays a good foundation for the construction of the comparison system.
撰写科研论文是科研工作的重要组成部分。国内的许多期刊要求论文作者在正文前不仅要标引关键词, 还要根据《中国图书馆分类法》(Chinese Library Classification, CLC, 简称《中图法》)标注分类号。对于并不熟悉《中图法》的论文作者, 确定分类号要比确定关键词的难度大得多。以综合性医科大学学报为例, 其中的论文往往隶属多个学科, 随着新兴的交叉学科不断出现, 要为某篇文章找到一个恰当的分类号非常不易。由于《中图法》自身存在着分类划分不足、深度不够的缺陷, 且现有期刊通常要求对文章进行深度标引, 即使是专业的标引人员, 受水平所限, 标引结果也存在一些错误[1, 2]。本文通过挖掘海量文献数据, 借助数理统计分析方法— — 潜在语义分析(Latent Semantic Analysis, LSA)研究二者的对应关系, 建立关键词-分类号的对照系统, 旨在为用户信息检索和辅助标引提供支持, 从而提高信息的利用价值。
由于国内用户多用关键词检索文献, 但关键词难以从全局上反映知识的结构性, 漏检率高; 而分类法中的分类号揭示了文献与所属学科的关系, 便于族性检索, 因此文献标引的正确与否极大影响着文献检索功能的发挥[3]。图书资料的分类工作具有较强的专业性, 对于并不了解分类法的论文作者, 若能通过确定的关键词对应到相关分类号, 则能在标引时减少繁琐的查询工作, 而文献的正确标引也为用户的精确检索带来极大的便利。基于此, 建立起一个关键词-分类号的对照系统是非常必要的。
关键词检索和分类号检索是两种不同的检索方法。一篇文献中通常有多个关键词, 关键词和分类号间存在复杂的多对一甚至多对多的对应关系。经查阅相关文献, 杨贺等[4]采用互信息法(MI)、卡方检验法(Chi-Square)、最大似然估计法(MLE)等方法计量分析了关键词与《中国图书资料分类法》分类号的关联关系; 陈先来等[5]也基于互信息方法构建了关键词-叙词对照表; 朱伟丽等[6]在互信息法的基础上探索关键词-叙词表的自动构建研究; 李国垒等[7]则运用潜在语义分析方法实现了关键词与主题词的对照, 显示出潜在语义分析在语义空间分析中具有较好的应用价值; 钟伟金[8]利用相互包容算法研究了分类号与关键词的对应关系并取得良好的效果。不难看出, 有关分类号与叙词的对应关系研究较多, 而关键词与分类号的对应研究则较少。钟伟金[8]虽然由分类号对应单个关键词获得了较好效果, 但未考虑关键词与分类号的反向对应, 尚存在不足。本文重点将研究关键词-分类号的对应关系。
本研究通过中国生物医学文献服务系统(SinoMed)[9]从肿瘤类期刊中随机选取《中国癌症》、《中国肿瘤临床》、《中华病理学杂志》、《中华放射肿瘤学杂志》、《中华肿瘤》、《肿瘤》、《肿瘤防治研究》近5年(2009-2013)的文献, 导出“关键词” 和“分类号” 两个字段用于研究。
潜在语义结构指文本中词与词之间存在某种联系, 其隐含于词在上下文的使用过程中。潜在语义分析即是用特定的方法对文本进行分析, 以寻找这种潜在语义结构。不需要确定的语义编码, 仅依赖于上下文中词与词的联系, 并用语义结构表示词与文本, 达到简化文本向量的目的[7]。本文通过对获取到的关键词、分类号进行分隔预处理, 逐个统计关键词与分类号的共现频次生成对应矩阵, 运用奇异值分解构建潜在语义空间。当用户提交关键词进行分类号查询时, 将该查询向量投影到语义空间中与分类号坐标进行相关度计算, 经计算排序后, 返回给用户查询结果, 主要步骤如图1所示。
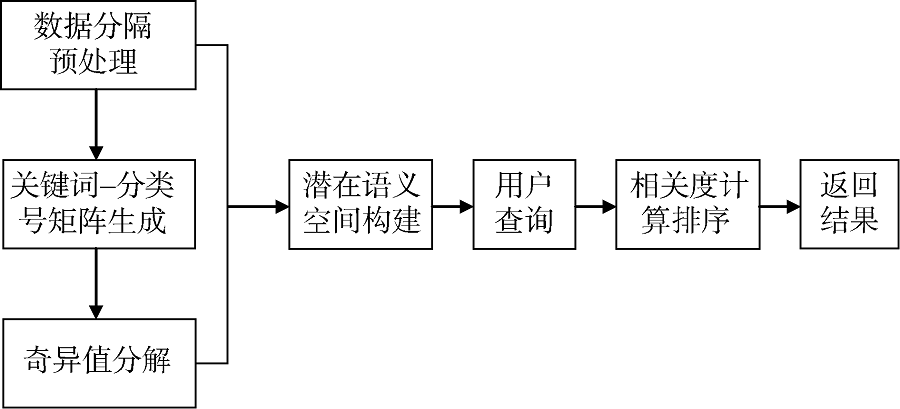 | 图1 研究步骤流程图 |
导出的题录信息数据共6 333条。首先将题录信息中的关键词与分类号分离, 以表格形式形成对应关系, 如表1所示, 其次对分类号进行以下处理:
| 表1 关键词与分类号对应关系表示例 |
(1) 删除部分没有分类号只有关键词的题录信息;
(2) 对加标星号的主分类号, 删除该主分类号前所标示的星号;
(3) 由于样本量不大, 对于已经标引至三位数字甚至更细的分类号, 将其控制在三位数字分类以内, 不足三位数字的保持原分类深度;
(4) 经前三步数据处理后, 某些题录中会出现相同的分类号, 对这种相同的分类号不再进行去重。因为分类号重复说明这一关键词与此分类号高度相关, 增加分类号与关键词的共现频次统计的同时相当于对该分类号进行加权。
编制程序实现表1中关键词、分类号的切分, 使之成为关键词集合、分类号集合。在切分时, 以其中的分号作为依据。经切分统计, 本研究共提取到关键词 6 032个, 分类号266个。
在此基础上, 逐个统计关键词与分类号共现的次数。根据每个关键词与每个分类号之间的共现频次, 生成关键词-分类号矩阵, 如公式(1)所示。
其中, 矩阵X的每一列代表一个分类号向量, 每一行代表一个关键词向量。xij表示第i个关键词与第j个分类号共现的频次。本文生成的关键词-分类号矩阵X大小为6 032× 266, 部分示例如表2所示:
| 表2 关键词-分类号共现矩阵X部分示例 |
关键词-分类号矩阵X生成后, 对矩阵X进行SVD奇异值分解, 即。利用Matlab输入奇异值分解命令[10], 矩阵X经分解后得到三个矩阵。根据潜在语义分析理论, 由于二维语义空间信息失真较大, 本文建立一个三维语义空间。在该计算结果中取
最大的三个奇异值。相应地, 取U的前3列和V的前3列, 得到矩阵U3、
、V3。在
中取最大的三个奇异值, 在U3、V3中取对应三列, 可以得到所有关键词和分类号的三维语义空间坐标, 部分示例如表3、表4[11]所示:
| 表3 关键词在三维语义空间内的坐标向量(部分示例) |
| 表4 分类号在三维语义空间内的坐标向量(部分示例) |
三维潜在语义空间包括关键词、分类号和查询向量。要生成查询向量, 首先需要提交查询条件表达式q, 然后根据各关键词的出现频率生成查询向量Xq, Xq中第i个元素的数值, 表示第i个关键词在提问式q中出现的频率[7]。以查询关键词“紫杉醇” 为例, 由于紫杉醇位列关键词第3 723位, 故:
Xq=[…0; 0; 0; 1; 0; 0; 0…]; (1表示第3 723位关键词出现1次)
用公式(2)[10]对Xq 进行处理:
Dq为提问式的向量表示, 即查询向量在三维语义空间中的坐标向量。
本文选取单个关键词进行相关分类号查询, 由于单个关键词与较多分类号存在共现, 对应关系效果不理想, 故以两个关键词作为词组进行查询。以“紫杉醇; 同步放化疗” 两个关键词为例, 首先以这两个关键词在SinoMed中进行不限定检索, 并导出所有检出文献的分类号。然后根据该关键词组在Matlab中生成查询向量Xq1, 并将Xq1投影到三维语义空间中得到其三维语义空间坐标向量Dq1 (-0.5185, 0.5155, -0.5042), 最后通过余弦公式计算该关键词组与每一个分类号的相关度, 将相关度进行降序排序, 结果如表5所示。
| 表5 分类号及其相关度 |
在获得的查询分类号中, 本文设定取相关度前10%的分类号(26个)进行匹配。通过将查询到的分类号与检索系统中的分类号进行匹配, 可以发现, 在与关键词组“紫杉醇、同步放化疗” 有对应关系的分类号中, R916和R282以较高的相关度排在第2位和第5位。为评价整体对应关系的构建效果, 随机选取存在共现的两词词组100对进行验证。经检索文献, 查询相关分类号并进行匹配, 按照分类号取前10%进行匹配的标准, 实验准确率达到91.0%, 部分示例如表6所示:
| 表6 验证词组及结果展示(部分示例) |
除此以外, 本次实验还尝试将语义空间坐标维度提高到4维, 但4维坐标由于计算更为复杂, 匹配条件更为苛刻, 分类号的相关度出现下降。无论是单个关键词还是两个词的关键词组, 对应准确率均不如三维坐标好。
本文依据关键词与分类号的共现频次矩阵, 运用潜在语义分析方法, 通过奇异值分解构建潜在语义空间, 探索关键词与分类号的内在关系。由于每篇文献中每个关键词通常对应多个分类号, 经统计多篇文献后, 矩阵中一个关键词就与多个分类号存在低频次共现。而由于分类号的相关度值并非按共现频次高低排列, 故通过矩阵计算后, 用户查询到的最相关分类号并不一定是共现频次最高的。研究结果也表明, 在查询单个关键词相对应的分类号时, 本文不如钟伟金[8]单个分类号与单个关键词的对应准确率高。这可能由于某一关键词可以被归入多个类下, 并且需要两个甚至更多关键词同时出现才能确定其最可能的分类号。本研究以两个关键词组成的关键词组进行分类号查询, 取得了满意的效果。而以三个关键词或者四个关键词进行匹配验证, 由于关键词增多, 限定的文献量减少, 导致匹配准确度显著降低, 很难实现对应。此外, 通过加大样本数量, 使得某个关键词共现频次高的分类号更多, 生成更加稀疏的矩阵, 对应关系可能会更明显。本文结果说明潜在语义分析方法在构建关键词-分类号对照系统方面具有良好的效果, 可以用于两个关键词的词组与分类号之间的映射。
对一篇文献而言, 其内容往往需要多个关键词概括, 也意味着需要多个分类号对应。本文虽对两个词的关键词组与分类号的对应关系进行研究, 取得了一定成果, 但关键词与分类号的对应关系仍需深入探讨。在接下来的研究中, 选用其他方法探索三个及三个以上关键词与分类号的对应将是努力的方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|