

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
中文UGC信息源的本体概念抽取研究*
[唐晓波, 胡华 ]
]
]
|
|


作者贡献声明:
唐晓波: 提出研究思路, 设计研究方案;
胡华: 进行实验; 采集、清洗和分析数据; 论文起草; 最终版本修订。
【目的】实现基于UGC信息源的本体概念抽取。【方法】针对UGC信息源特征, 提出一种基于语言学的细粒度词抽取组合并应用统计过滤组成概念的本体概念抽取方法, 建立基于UGC信息源的概念抽取模型并对原型系统进行验证。【结果】在UGC信息源概念抽取实验中, 该方法的结果比其他4组概念抽取方法的表现更为优异, 准确率达68.42%, 召回率达85.35%。【局限】概念抽取的测试集来自信息质量较高的UGC信息源, 部分信息经过人工过滤, 语料规模存在不足。【结论】概念抽取方法与技术在实现基于UGC信息源的本体概念抽取中具有一定的意义。
[Objective] In order to extract Ontology concepts from Chinese UGC information sources.[Methods] This paper proposes a mixed Ontology extraction method which extracting the fine-grained words and combining them into concepts based on linguistic methods and filters the concepts based on statistical methods. To prove the methods, the paper establishes the Ontology extraction model and develops a prototype system of concept extraction which is based on the UGC sources.[Results] The method has more excellent performance than other four concept extraction methods as the comparative samples in the experiments of concept extraction from UGC. The results of the accuracy rate and the recall rate respectively reaches 68.42% and 85.35%.[Limitations] The test set of concept extraction is from high-quality UGC sources and some of the test set is filtered manually.So the corpus scale is not enough.[Conclusions] This concept extraction method and technology has some significance in the Ontology concept extraction based on UGC.
随着Web2.0技术的迅猛发展, 社会化媒体(Social Media)已成为全球信息传播和共享的重要资源平台, 是人们生活中不可缺少的部分。用户生成内容(UGC)作为用户利用社会化媒体的结果, 成为互联网领域新的应用和商业模式, 存在巨大的潜在价值[ 1]。用户参与内容的创造, 一方面为互联网提供了丰富的知识, 另一方面也形成了“无序、去中心化、碎片化”的UGC信息, 加剧了用户在社会化媒体中的“信息过载”和“信息迷失”[ 2]。如何从海量UGC中提炼出具有价值的知识并进行科学合理的组织, 供用户及研究人员查询并利用, 是当前的迫切需要。
本体作为一种能在语义层次上表达知识的概念模型工具被广泛使用, 它是解决信息增长与信息利用之间矛盾的办法之一。由于UGC信息的特点, 使用手工方式构建UGC信息源中的本体不太现实, 需要应用本体学习(Ontology Learning)技术自动构建本体。概念抽取是本体学习的基础, 也是本体构建中最重要的组成部分之一。由于UGC信息分布稀疏, 变化迅速且表达不规范, 文本中含有大量口语化、缩略形式以及用户自创的词汇, 因此给计算机自动化地实现概念抽取造成很多障碍。
目前本体概念的获取方法主要有: 基于语言学的方法、基于统计的方法及混合方法。
基于语言学的方法是以语言学为基础, 应用词汇的构词规则来实现概念抽取[ 3], 如化柏林[ 4]运用词表与规则相结合的方法从句子中抽取方法术语; 丁君军等[ 5]通过人工构建规则的方法, 提出属性抽取的9大类描述规则。基于语言学的概念获取方法具有很多优点: 极少存在歧义; 抽取规则简单, 效率较高。但是该方法的可移植性较差, 面对大量数据制定规则时, 需消耗大量的时间及精力, 同时还受语言学知识质量的影响, 且人工规则无法涵盖全部本体概念, 易造成提取规则之间的冲突。
基于统计的方法是通过分析大量语料文本, 获取词语在文本中的各类统计数据, 进行概念抽取。如Yang等[ 6]通过互信息、信息熵与共生句子来完成概念的提取并实现本体构建; Cohen[ 7]对词频统计法添加参数控制并进行过滤, 实现概念抽取。基于统计的概念抽取方法存在很多优势: 能够处理大规模的数据, 并且跟语言本身无关, 移植性强。但是缺点也比较突出: 首先需要大规模语料的支撑, 其次通过统计获得的概念语义相对语言学方法来说较弱。
将语言学与统计方法结合的混合概念抽取方法可以利用两种方法的优点进行概念抽取, 结果较为理想, 也是目前概念抽取研究的主要方向。如Ji等[ 8]和Vu等[ 9]利用统计方法获取初始概念, 并以语言学方法扩充和过滤所得的概念; 刘柏嵩[ 10]应用基于规则的方法对术语进行抽取并通过互信息统计量对概念进行筛选; 屈鹏等[ 11]利用专家分析术语规则, 并应用多种统计算法进行概念抽取。
综合概念抽取的研究现状, 本文应用语言规则和统计结合的混合抽取方法来实现基于UGC信息源的概念抽取。由于UGC信息中存在大量的新词以及新概念, 短语的组合方式多样且有很多并不符合语法规则的概念, 无法通过人工有效地找到提取规则, 部分概念的中心词搭配具有特殊性, 因此本文在充分了解UGC信息源基础上, 针对中文UGC信息源进行人工监督状态下的自动概念抽取和过滤, 尝试从UGC信息中获取期望的本体概念。
本文用统计方法找到信息源中的语言规律,从而指导概念的抽取。通过对手机术语的构词规则进行统计分析, 根据语言学知识及领域知识, 找到术语的词素、词根以及高频的词组组合规则, 应用这些规则来指导UGC中的概念抽取。
该方法利用计算机获得词性规则, 因此提取工作量较小, 且方法的可移植性较好, 对出现频率较低的术语抽取有较好的效果, 但是会降低提取的准确率, 同时建立规则的过程中, 规则的获取需要大量的文档作为支持。
本文针对中文复合词的一般规律, 通过找到短语词组中的中心词实现短语词组的抽取。中心词可以是复合词构造的词组, 也可以是对事物的限定。中心词一般作为其扩展词的上位类存在, 指代更一般的概念。因此通过基于中心词的概念抽取可以获得一些出现频数少、但是与中心词相关程度高的词。
依据文献[ 12]对科技术语的分析, 发现非语素词、语气词、状态词、叹词、拟声词、代词、处所词和标点符号无法构成术语, 同时术语以助词、连词为中心词前词, 以方位词、连词和助词为中心词末尾词的搭配极少出现, 包含名词、动词、量词的术语占99.74%。因此本文结合对UGC信息源中术语的观察, 对基于中心词的抽取方法进行语言规则限定: 抽取概念中无分隔词, 如连词(/c)、代词(/r)、语气词(/y)等; 抽取概念中至少含有一个名词或名词成分(/n、/vn、/an、/ng); 抽取概念的尾部词为动词、名词或名词成分(/n、/v、/vn、/an、/ng)。
互信息是Shannon信息论中的一个重要概念, 用于表示信息之间的相关性。将其引入到概念过滤中可以描述两个词之间的相互性, 用以判断词之间联系的紧密度, 确认词组是否是一个独立的概念。文献[ 13]应用9种评估内部结合紧密度的常用统计量实施二字词抽取, 结果发现互信息具有最好的词语抽取效果, 独立应用的F值达到54.77%。
中文词语并不只是二字词, 文献[ 14]提出的基于互信息的扩展方法——重要词法模式发现(Significant Lexical Patterns), 将互信息的计算扩展到n字词之间。这种算法忽略对数因子, 将计算简化为频数之比, 因此提高了计算效率, 并可有效测量多字词之间的互信息。为了降低UGC信息源中概念抽取的成本, 本文将多字之间的互信息计算扩展到多词之间, 公式如下[ 14]:
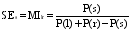 | (1) |
词x出现的频率为 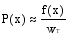
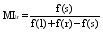 | (2) |
其中,s=w1w2...wn-1wn为提取的词组, l为s的最长左子词组, 即1=w1w2...wn-1, r为s最长右子词组, 即r=w2...wn-1wn,f(x)是x在语料中出现的频次。扩展后的互信息公式可以描述词组是否比其子词组更适合作为一个独立概念。
信息熵是Shannon借鉴了热力学熵的概念用以表示特定信息的出现概率, 是信息排除冗余后的平均信息量。可以使用信息熵来测量一个词对其上下文的依赖程度。
本文通过计算词的左右信息熵(Left and Right Entropy)来判断一个词的边界是否确定, 以此衡量其完整性。左右信息熵在中文新词识别中有着广泛的应用[ 15]。公式表述如下:
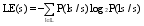 | (3) |
 | (4) |
其中, s是目标概念, l和r分别是目标概念的左邻接词和右邻接词, L表示s的所有左邻接词的集合, R表示s的所有右邻接词的集合。P(ls/s)表示在s出现的情况下, l和s共现的条件概率, 同理P(sr/s)。LE(s)和RE(s)越大, 表明目标概念左或右邻接词越离散, 说明s通常不会依赖于其左或右边的词而单独出现, 独立成词的可能性越大。
基于UGC信息源的概念抽取是从大量的UGC文本中获取相关的本体概念。概念抽取是本体构建中至关重要的一步。概念由一些领域相关的术语构成, 往往包含一些其他领域所没有的特殊词, 如何抽取这些特殊词成为概念抽取的重点。
本文构建了基于中文UGC信息源的概念抽取模型, 如图1所示:
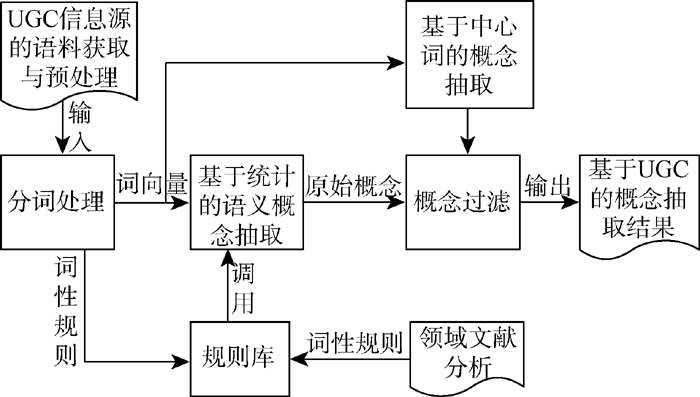 | 图1 基于中文UGC信息源的概念抽取流程模型 |
针对不同的UGC信息源, 分别应用爬虫获取UGC文本并保存到相应的文档集中, 然后对文档集进行文本预处理, 这是本体概念抽取的第一步。由于选用多种UGC信息源, 因此需要采取不同形式的预处理; 同时, 针对UGC信息离散的特点, 将无知识性的信息进行过滤, 如描述UGC用户发布信息的时间、心情、状态等内容, 降低本体概念提取中的噪声。由于目前无有效地理解UGC语义的方法, 因此对部分内容进行人工过滤。经过这些处理后, 得到测试文档。
应用词性规则统计方法对专业领域文献中术语的构词规则进行分析, 找到该领域术语的词性组合规律。仅用专业领域文献的术语构词规则无法完全体现UGC信息源中概念的语言特点, 因此结合从UGC信息源中抽取的高频词性组合规律, 对两组词性组合进行合并和去重, 得到概念的规则库。UGC信息源的词性组合规律需要在人工监督下按照语言学中术语的构词规则剔除不符合的词性组合, 并选择合适的阈值进行抽取。
对测试文档进行分词和概念抽取。概念分为单词概念和词组概念, 本文对测试文档中的单词概念进行直接抽取, 应用词频统计和常用词典的抽取方法, 抽取单词作为本体概念; 调用规则库中的词性规则对词组概念进行抽取, 得到包含单词本体概念和词组本体概念的原始概念集。
抽取分词文档中的单词, 过滤后得到中心词。通过对中心词左右邻词的抽取与分析, 得到基于中心词的合成词, 将合成词作为新的中心词进行左右邻词的抽取与分析。将所得的全部概念保存为基于中心词抽取的原始概念集。
基于统计的概念抽取得到的原始概念文档中, 存在着一部分概念, 它们虽然满足词性规则, 但不是完整或者是由两个或者两个以上独立概念组合而成的, 这些都不能满足要求。因此, 需要通过互信息来判断概念的独立性, 消除两个或两个以上独立概念组成的概念; 通过左右信息熵来判断概念的完整性, 消除不完整的概念。与过滤后的基于中心词抽取的概念文档合并, 得到基于UGC信息源的概念抽取结果。
为了选取具有代表性的UGC信息源, 本文依据UGC信息源的类别, 对网络百科、博客、论坛、微博进行概念分布状况的比较和分析。在各信息源中选取1 000字左右的文本, 进行人工概念提取。经过实验, 发现网络百科中的概念集中程度较高, 专业论坛其次, 博客和微博最少, 千字中分别仅提取到9个与3个概念。考虑到信息长短的结合、概念分布密度大小的结合、内容专业性高低的结合, 为较好地体现UGC信息特征, 本文选取了以下具有代表性的UGC信息源, 包括网络百科、问答社区、专业论坛和知识博客。
应用本文开发的工具将UGC信息源中的信息爬取到文档集中, 将单位文本标题作为文件名进行保存, 并对文档进行预处理。具体工作包括: 过滤与选取与主题无关的文本; 过滤回复信息; 过滤用户名、发布时间、图片链接等信息; 过滤字数少于阈值的文本等; 将过滤后的文档集保存为TXT格式的测试文档集。
文本经过预处理后, 需要进行分词处理。应用ICTLAS的最新版本——NLPIR汉语分词系统, 其主要功能包括中文分词、词性标注、命名实体识别、用户词典功能。同时, 该版新增微博分词、新词发现与关键词提取的功能[ 16]。
用NLPIR分词系统对文本进行分析后, 得到一个词向量, 其中的每个词都带有词性标记, 如名词、动词、形容词等。NLPIR的分词功能具有很多优点, 如智能/n手机/n可以自动分词成为智能手机/n_newword, 提高了文本概念提取的准确率, 降低了文本概念提取的成本。
对分词结果进行统计排序, 选定合适的阈值得到高频词汇表。通过常用词汇表过滤掉与领域无关的常用词, 得到本体的单词概念词表。需要进一步处理分词文档, 得到词组概念, 解决概念如“多点触控”, 其分词为“多/m点/qt触控/n_newword”的问题。
本文将手机术语领域文献, 经过分词后连同UGC分词文档导入到词性组合规则抽取模块, 建立分隔词表, 以减少词性组合的噪音并提高文本词性组合提取的准确率; 对部分词性进行限定, 如将nr人名、ns地名、nt机构团体、nz其他专有名词等同于名词n进行处理, 降低词性组合的维数。遍历分词结果, 对词性组合进行提取并统计。由于领域文献和UGC信息概念分布与特征的不同, 选择不同的阈值和限定规则进行抽取。本文根据UGC概念的特征, 选择5词以下的组合, 得到词性组合的结果, 汇总结果建立词性规则库。
调用词性规则库, 遍历分词文档, 提取领域概念, 进行词频统计, 算法如下:
(1) 调取规则库词性规则集;
(2) 遍历分词文档, 调用词性组合集, 对比分词文档中词的词性, 符合规则组合则输出概念, 如果不符或词性组合大于4, 则判断下一个词, 直至最后一个词与词性;
(3) 获得所有概念, 按照绝对频次统计排序。
对提取的概念进行人工试验, 找到提取价值不大的概念频次, 确定绝对频次阈值, 对概念进行初步筛选。
概念中存在需要过滤的非独立概念, 应用互信息方法进行概念过滤, 算法如下:
(1) 调用原始概念文档, 将概念分为左、右词串, 获取概念词、左词串与右词串的频次;
(2) 调用公式(2), 获取概念的互信息值;
(3) 输出概念词、概念词频次、左词频次、右词频次与互信息值。
根据人工试验, 选取合适的互信息阈值进行过滤。
概念中存在非完整概念需要过滤, 应用左右信息熵方法进行概念过滤, 算法如下:
(1) 调用原始概念文档, 遍历测试文档, 获取概念词频次、概念词左邻词词表及频次、概念词右邻词词表及频次;
(2) 调用公式(3)和公式(4), 计算概念词的左右信息熵值;
(3) 输出概念词、概念词词频、左信息熵值、右信息熵值、左邻词及频次、右邻词及频次。
根据人工试验, 选取合适的左右信息熵阈值进行过滤。
由于互信息会过滤掉一部分以高频词为中心词的组合词, 需要将这部分漏掉的中心词的下位概念补充到概念抽取结果中。具体算法如下:
(1) 抽取UGC分词文档中的名词, 过滤掉低频词后作为中心词;
(2) 抽取中心词的左右邻接词性为名词、动词和形容词的词, 得到合成词, 人工过滤无意义的词组, 得到新中心词;
(3) 重复步骤(2)直到所获得的词组中单词的数量超过5或者左右无邻接词。
保存所有的中心词, 得到基于中心词的概念抽取结果。
本文的实验环境为 Intel Core i5-2430 2.4GHz的CPU、4GB的内存、500GB硬盘的笔记本电脑, 操作系统为Win7。实验工具采用C#的VS2008开发工具, .NET Framework为4.0版本。
(1) UGC信息源文本的获取、语料预处理
本文UGC的文本数据集来源于百度百科、互动百科、百度知道、威锋网论坛区, 应用网络爬虫以iPhone为类目或标题共获取200条文本数据, 字数共计100 875个。对文本进行预处理和分词后共得到 47 631个词。专业领域文献来自于电脑之家的“产品术语解释”, 应用爬虫获取文本数据46条, 字符数共计37 686个, 预处理和分词后共得到20 964个词。
(2) 词性规则库的建立
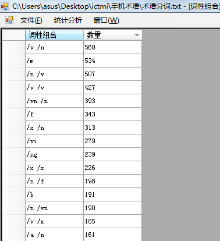
对专业领域文献分词文档, 应用C#开发的词性组合抽取工具模块进行词性组合的抽取与统计, 如图2所示:
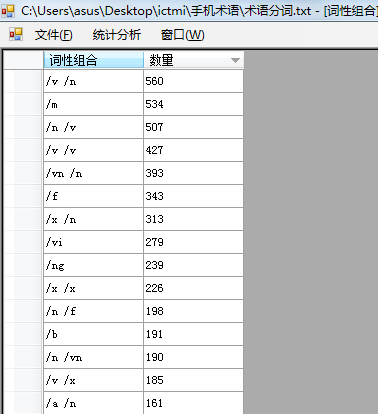 | 图2 词性规则抽取与统计界面 |
程序运行后, 得到专业术语组合的规则与频数, 经过试验, 选择阈值在10以上的词性组合。对UGC文本分词结果进行词性组合分析, 选择频次阈值为25以上的词性组合。共得到词性组合数171组, 对部分词性组合进行归约, 建立规则库。其中最多的为名词短语, 符合语言规律, 部分结果如表1所示:
| 表1 词性规则组合 |
(3) 基于规则的概念抽取
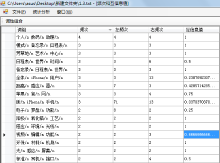
运用C#平台开发的概念抽取工具模块, 对建立的规则库进行概念抽取, 共抽取概念词17 489个, 选取阈值大于3的概念词进行保存。部分结果如表2所示:
| 表2 概念词抽取 |
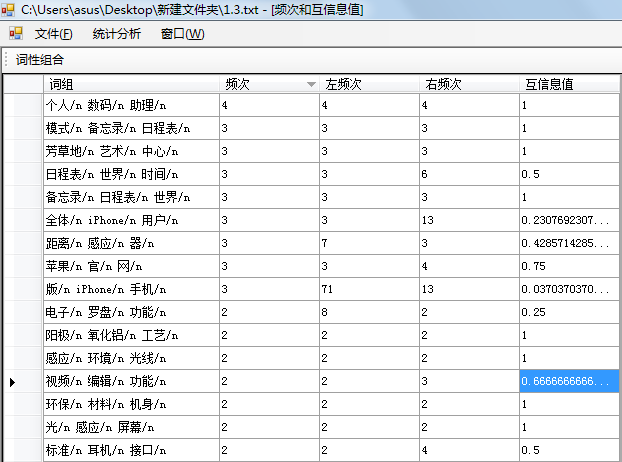
(4) 基于互信息的概念过滤
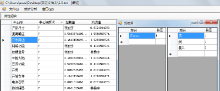
将原始概念文档导入开发的互信息过滤工具模块, 计算每个概念的互信息值, 界面结果如图3所示, 通过反复测试, 发现互信息值取0.2效果较好。
 | 图3 基于互信息的概念过滤功能界面 |
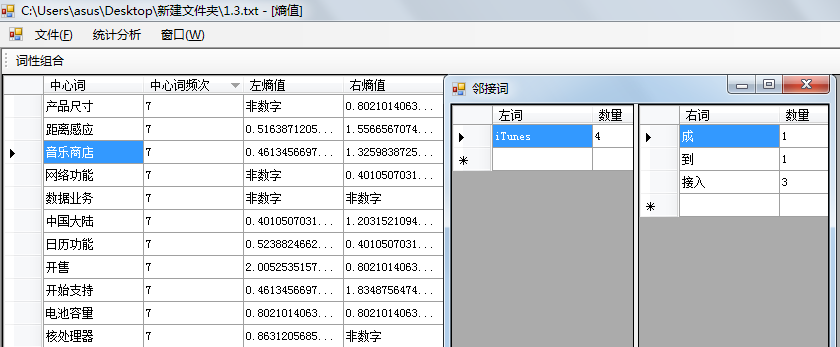
(5) 基于左右信息熵的概念过滤
将抽取概念词导入开发的信息熵过滤工具模块, 计算每个抽取概念的左右信息熵值, 结果如图4所示, 通过反复测试, 发现左熵值大于1, 右熵值大于1时效果较好。
 | 图4 基于左右信息熵的概念过滤界面 |
(6) 基于中心词的概念抽取
运用C#平台开发的中心词概念抽取工具, 抽取分词文档中的名词, 选取频次阈值在15以上的词作为中心词, 计算其左右信息熵值, 剔除阈值小于1的名词, 共得到中心词74个, 部分结果如图5所示:
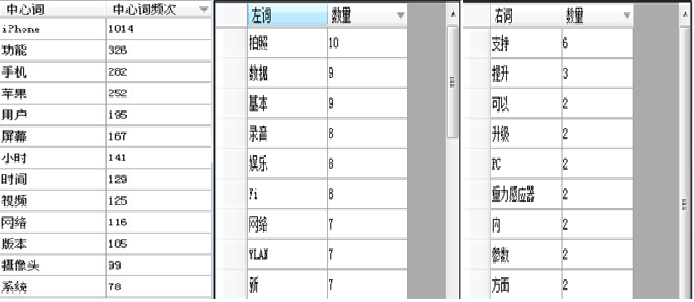 | 图5 基于中心词的概念抽取界面 |
抽取中心词的高频左邻词词性为名词、动词、形容词, 高频右邻词词性为名词与动词, 将其组合成新词, 重复进行几次后, 共得到概念数量为167个。
选取绝对频次阈值为3, 互信息阈值大于0.2, 左熵值和右熵值阈值大于1, 进行基于规则的概念抽取和过滤, 得到概念数量为182个, 部分结果如表3所示。如果抽取概念的左右信息熵结果为非数字, 说明该概念无左邻或右邻词, 处于开头、结尾或以分隔符分开, 可以作为边界词认定。
| 表3 社会化媒体本体概念抽取结果 |
基于中心词的抽取结果, 去重后共得到概念数量为247个。为了对概念提取结果进行验证, 本文通过手工提取, 从测试文档集中共提取的概念数量为198个。为了测试本文概念提取方法的准确率和召回率, 采用4种不同的概念抽取方法对测试文档进行实验, 共获得4组对比样本进行实验结果比较。
样本1采用本文提出的基于词性规则、中心词、互信息和信息熵的综合方法; 样本2采用结合互信息、信息熵及词性规则的综合统计方法; 样本3采用互信息的统计方法; 样本4采用信息熵的统计方法, 样本5采用基于语言学的中心词方法。比较结果如表4所示:
| 表4 实验结果验证 |
对比实验结果可以发现: 应用本文方法对UGC信息源中的概念进行抽取, 召回率和准确率表现都优于其他方法。经过对实验结果的分析, 本文方法与样本2方法相比, 应用了基于中心词的概念抽取方法, 因此, 对如“苹果/n手机/n, 蓝牙/n功能/n”等中心词的频率过高导致互信息值比较低的概念的抽取效果较好, 提高了概念抽取的召回率。同时, 混合方法对UGC信息源的概念抽取效果明显优于单独使用基于语言学或统计的抽取方法。部分概念没有召回的原因是某些概念与动词的固定搭配, 或者UGC文本中标点符号的省略, 导致概念左右信息熵值低于阈值而被过滤。如概念“全景照片/n_newword”一词, 其左邻词只出现“拍摄”和“支持”, 因而该词的左信息熵值低于阈值; 还有如“电子罗盘”和“指南针”这两个概念总是一起出现, 且很少用标点符号分隔, 导致进行左右信息熵判断概念完整性时, 系统认为“电子罗盘”一词不是右边界词而将其过滤掉。这种情况产生的原因一部分是由于方法有待改进, 另一部分则是语料库规模不够大。
实验抽取的概念中存在多种非正规的概念表达方式, 如“爱疯” 、“前镜头”、“触屏”等, 这些概念等同于“苹果手机”、“前置摄像头” “电容触摸屏”, 影响了抽取结果的准确率。这是由于与一般的非UGC信息源的概念抽取方法相比较, 本文抽取的概念只经过常用词表过滤, 并没有经过领域文献筛选, 同时对概念的切分粒度较细, 因此会得到很多非正规表达的词语。但是非正规表达词语的抽取对UGC信息进行本体关系抽取时具有重要意义。抽取到的非正规概念的关系可以与正规表达的本体概念进行映射合并, 从而对整个本体关系进行丰富。因此, 本文使用的概念抽取方法与技术对基于UGC信息源的本体概念抽取具有一定的意义。
本文以传统的基于语言学与统计的概念抽取方法为基础, 针对UGC的特点对概念抽取方法进行扩展, 提出一种综合应用中心词与词性规则进行抽取并通过互信息与左右信息熵过滤的概念提取方法; 构建了基于UGC信息源的概念抽取模型, 应用基于中心词与词性规则的方法来抽取UGC信息中的领域概念, 并综合应用绝对词频法、互信息法和左右信息熵法对抽取的领域概念进行过滤, 建立基于UGC信息源的本体概念抽取原型系统。经过实验分析, 本文提出的基于UGC信息源的本体概念抽取方法在准确率和召回率上表现优异。
针对本文提出的概念抽取方法, 笔者将在下一步的研究中提高语料库规模, 优化概念抽取算法来适应UGC信息大数据的特点, 以期进一步提高本体概念抽取的准确率和召回率。同时, 对UGC信息中概念关系的抽取也将是未来的研究方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|