{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
卖家描述与买家评论相符度模型研究
[王倩倩 , 袁勤俭]
, 袁勤俭]
, 袁勤俭]
|
|


作者贡献声明:
王倩倩: 提出命题、设计方法和模型, 数据获取与分析, 论文撰写;
袁勤俭: 指导修改论文, 以及最终版本修订。
【目的】通过构建买家评论与卖家描述的相符度模型, 对淘宝中卖家描述的商品特性与买家评论是否一致进行探讨。【方法】研究卖家的商品描述和买家的评论这两个文本信息, 提取产品属性特征词和判断情感词极性, 最后选取三家淘宝网店进行模型评估实验。【结果】发现B商家宝贝描述与买家评论相符度较高, A店次之, C店最差。其中, C店的“里衬”和“正品”两个产品属性, 卖家描述与买家评论不相符。【局限】卖家描述的内容和买家评论的内容未能全面涉及, 没有包括卖家的商品标题信息、卖家的图片说明信息以及买家秀中买家提供的照片信息。【结论】经过模型计算后的结果能够更细节、准确地反映出商品在哪些属性上相符以及多大程度上相符, 进而更有效地辅助消费者进行决策。
[Objective] This study discusses wheather commodity characteristics described by sellers are consistent with comments or not, by building the conformity model between description of sellers and comments of buyers.[Methods] Study the text of description and comments, extract the key attributes of products and determine polarity of emotional words, then select three Taobao shops to evaluate the model.[Results] The result shows that there are higher consistent degrees in B shop, A shop is the second, C shop is the worst. There are two attributes “in line” and “authentic” in C shop, which are not consistent with the comments.[Limitations] All the information from sellers and customers are not contained, such as title and picture information of products, and the photo information from customers.[Conclutions] The results can tell which attributes are consistent with the sellers description and how much they match. This result can support consumer’s decisions more effectively.
Web2.0 的兴起改变了人们以往使用互联网的方式, 从先前单一的读取互联网信息转变为现在参与互联网信息构建, 这些信息被称为用户自生成内容。众所周知, 淘宝、亚马逊等电子商务网站都有自己的评价系统, 这些网站都承载着用户的自生成内容, 能够给其他消费者提供参考, 也可以帮助商家收集用户意见, 了解消费者偏好。
随着电子商务的高速发展, 网络购物也呈不断攀升的趋势, 越来越多的在线评论遍布于网络。加之, 电子商务网站的评论体系仍不够完善, 消费者往往很难在大量的评价文本中快速找到自己想要的信息[ 1]。消费者最为需要的信息是想了解其他消费者口中的产品评论与卖家所描述的是否一致, 如果其他消费者都表示此产品和卖家描述的一样好, 那么这件商品就值得购买, 否则还需要再看看其他的商品。因此, 需要建立一种买家评论与卖家描述对比的体制, 判断卖家是否给出了商品的真实信息, 帮助消费者进行购买决策。
产品评论挖掘是指挖掘Web网页中的用户对商品或服务的评价信息, 通常采用自然语言处理技术, 发现产品功能、属性、用户态度等有价值信息的过程, 目前主要包括以下几个方面: 评论质量分析、评论特征词抽取、评论极性判断以及评论挖掘结果显示。
(1) 评论质量研究。评论质量的成果较多, 主要集中在评论效用的计算[ 2]、产品评论有用性分析[ 3]、高质量评论的提取[ 4]以及垃圾评论的识别和过滤等。Chklovski指出Web上存在着大量的噪音评论, 严重影响了评论的质量, 需要对它们进行过滤[ 5]。李志宇提出了在线评论效用的排序计算模型, 将高效用的评论前置, 帮助买家进行购买决策[ 6]。
(2) 评论中属性特征词的抽取。产品属性特征词的提取方式有人工提取和自动提取两种。人工提取是针对该领域的产品建立属性特征词表, 邀请该领域的专家对产品的属性特征进行定义[ 7]。自动提取的方式主要是基于计算机技术, 其中精准度较高的是Popescu等的研究, 他们利用Konwitall系统自动生成的鉴别短语和提取词的PMI值, 根据贝叶斯分类筛选出产品的属性特征词[ 8]。
(3) 评论极性判断研究。评论极性判断包括判断不同属性特征词的极性和整个句子的极性。不同属性特征词的极性需要判断买家对单个产品特征(比如手机屏幕大小)的褒贬态度[ 9], 因此更多地倾向于对词语、短语的态度进行分析[ 10]。
(4) 评论挖掘结果显示研究。将研究评论挖掘结果直观地展示给消费者, 帮助生产商和用户提供决策, 如, Liu等采用图形化的方式来展示挖掘结果, 比较两个产品在相同产品特征上的不同评价, 分别给出不同的褒贬性判断[ 11]。
目前的研究大多致力于挖掘买家的产品评论信息, 而较少考虑到卖家提供的产品描述信息[ 12]。同时, 大多数研究基于技术和算法的改进, 而基于应用层面的内容考虑较少。本文将卖家的描述信息和买家评论有效性指标考虑进来, 通过加权求和计算出卖家描述与买家评论的相符度分值, 辅助消费者在大量的评论中获取关键的信息。
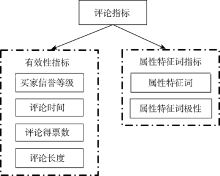
买家评论指标分为两部分: 基于外部因素的有效性指标, 主要包括买家信誉等级、评论时间、评论长度、得票数, 这些有效性指标反映了评论的效用有多大[ 13]; 基于评论内容的属性特征词指标, 主要包括属性特征词和属性特征词极性, 它们反映了评论中提到了哪些产品属性, 买家对这些产品属性的态度是怎样的。如图1所示:
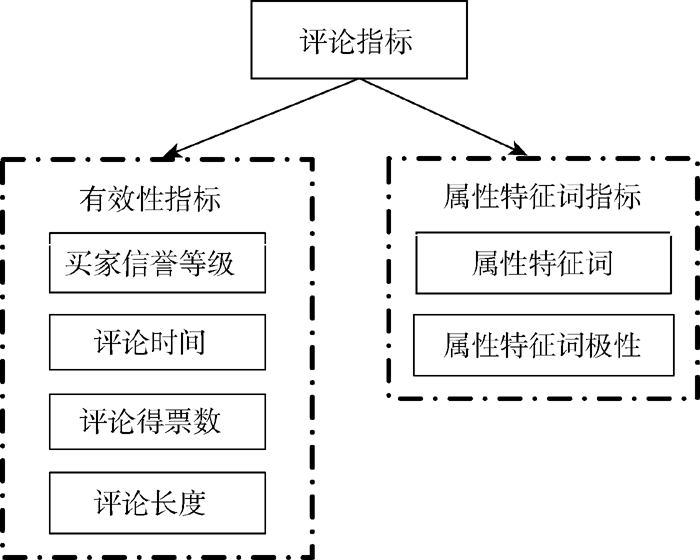 | 图1 评论有效性指标和属性特征词指标 |
在研究买家和卖家描述相符度时, 首先比较两者属性特征词的重复程度。假设买家评论中含有A个产品属性特征词, 卖家描述中含有B个属性特征词, 则重复的个数为A∩B, 个数最少的一方为min(A,B)。由此提出本文的命题1: 如果A∩B/min(A,B)≥80%, 则认为属性特征词匹配符合要求, 即买家与卖家属性特征词相符度较大, 能够较好地反映商品的特征。
如果买家和卖家在同一个属性特征词上给出的极性80%以上一致, 则认为卖家在产品属性特征词极性的描述上与真实物品相符。由此提出本文的命题2: 假设卖家给出的极性值为a, 买家给出的极性值为b, 如果a/b≥80%, 则认为该属性特征词极性匹配一致。
买家的购买经验对评论的有效性产生一定的影响。一般而言, 经验丰富的买家其评价更为客观、中肯, 而经验较少的买家, 往往对商品富有极大的想象, 如果商品与自己想象的有落差, 会给出一些极端的评论, 严重影响了其他买家对商品的认识和判断。基于此提出本文的命题3: 买家信誉越高, 其评论所占的权重越大, 买家信誉对评论有效性的权重为w1。
评论时间也是评论有效性的一个很重要的因素。如果评论时间过长, 比如三个月以前的评论, 那么很有可能在这三个月内商家改进了商品, 原本评论中所说的属性特征已经改变。基于此提出本文的命题4: 评论的时间越近, 有效性越好, 时间对有效性的权重为w2。
投票数是指某条评论被其他买家点赞同的次数。如果评论的阅读者认为词条评论有用, 可以点击“投票”或“有用”按钮, 系统会自然计数加1次。因此, 得票数越多说明该条评论越有用。基于此提出本文的命题5: 得票数对商品有用性的权重为w3。
评论长度反映在评论的字数上, 如果评论的字数较多, 说明买家认真填写评论, 并且提到的产品属性特征词也较多, 具有很大的参考价值。因此, 评论长度也是评论有效性的一个很重要的指标, 故提出本文的命题6: 评论长度对评论有效性的权重为w4。
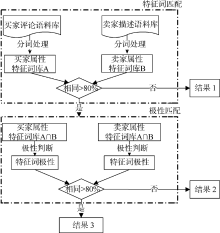
本文的模型分为两个阶段, 第一阶段是特征词匹配阶段, 即先利用网络爬虫获取在线商品的买家评论信息和卖家描述信息, 建立两个语料库; 然后分别对这两个语料库提取产品属性特征词, 生成买家属性特征词库A和卖家属性特征词库B; 如果买家和卖家属性特征词重复的部分占这两个属性特征词库最少一方的80%以上, 则认为属性特征词匹配成功, 进入下一个阶段。第二阶段是属性特征词极性的匹配阶段, 如果相同的属性特征词上给出的极性程度有80%以上一致, 则认为第二阶段匹配成功, 即卖家在产品属性特征词的极性描述上与买家感受相符, 相符程度高。如图2所示:
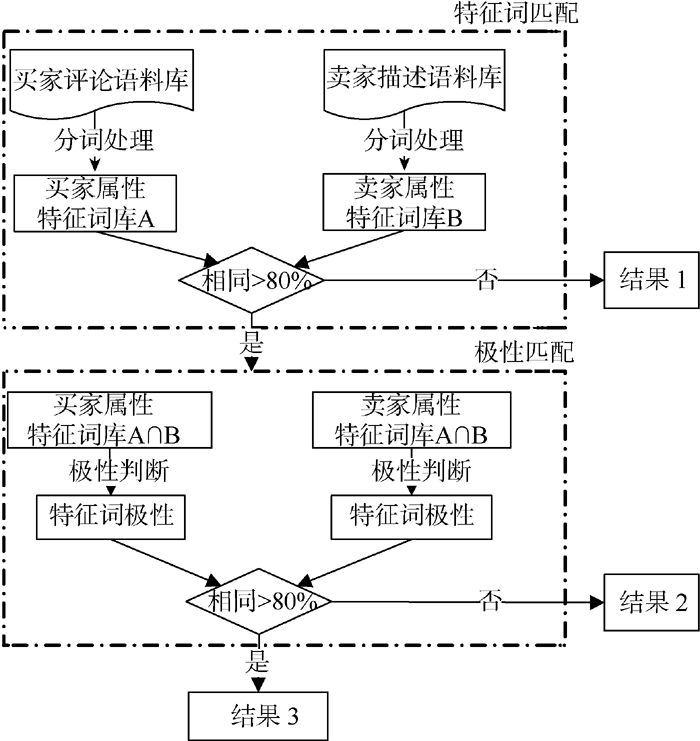 | 图2 卖家描述与买家评论相符度判断流程 |
(1) 评论内容获取
本文采用GooSeeker公司的集成网络信息抓取工具包MetaSeeker[ 14]。MetaSeeker的组件可以按照用户的指定从商品网页上筛选出用户所需要的信息, 本文共需要提取两部分语料库,即产品评论语料库和产品描述语料库。笔者认为字数大于等于两个汉字的评论才算是有效的评论, 因此对系统设置一个阈值让系统自动判断, 如果评论字数大于等于两个汉字(即4个字节)则进行提取, 否则视为无效评论, 跳转到下一条评论进行判断, 进而可以去除无用评论。同时, 如果遇到同一个ID买家有多条相同的评论, 本文规定只提取其中的一条, 进而排除了同一买家重复的评论。
(2) 分 词
对卖家和买家的两个语料库分别进行分词处理, 包括文本切分、停用词删除、词性标注等处理。本文采用中国科学院计算技术研究所的ICTCTAS分词系统[ 15]进行分词和词性标注, 每篇文本标注后的格式如表1所示:
| 表1 买家评论文本分词 |
(3) 提取属性特征词
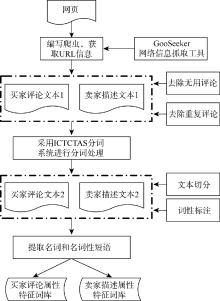
本文的属性特征词提取采用自动提取和人工结合的方式。将分词的结果导入Excel中, 按照词性对结果进行分类, 提取出名词和名词性短语作为属性特征词集合的备选。再通过Excel的替换功能将“衣服”、“大衣”这种比较宽泛的词语用空格进行替换, 进而删除不是产品属性的名词。分别构建两个属性特征词库, 即买家评论属性特征词库和卖家描述属性特征词库。具体流程如图3所示:
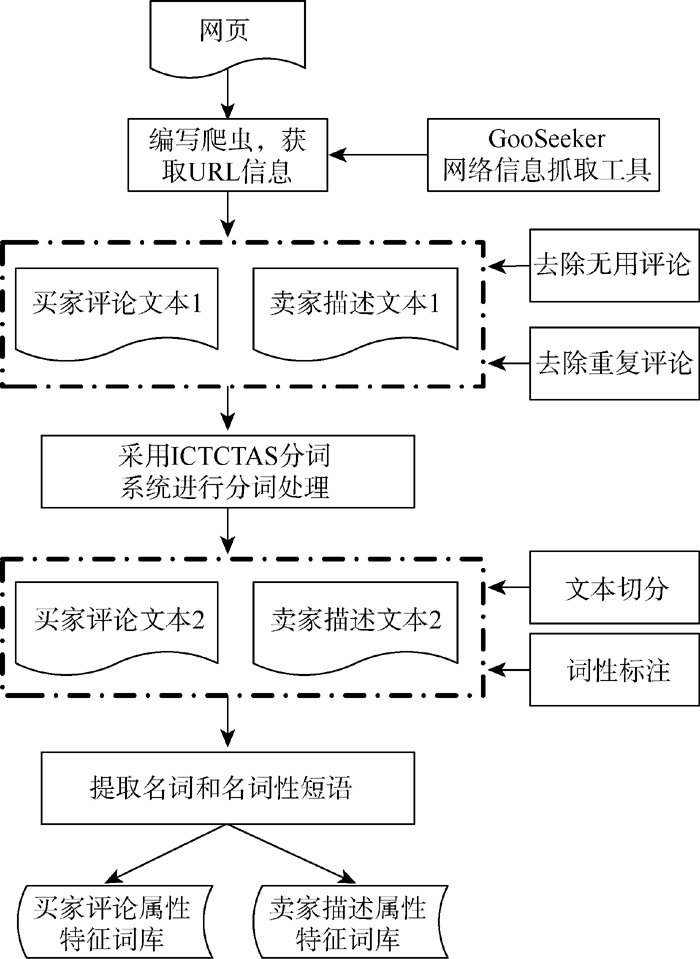 | 图3 卖家描述和买家评论属性特征词提取流程 |
参考极性词表即可方便地计算出卖家的产品属性极性。假设卖家给出的极性只有两种, 一种是正向的极性+1, 一种是负向的极性-1。例如, 卖家描述为: “此款羊毛大衣颜色很正, 版型挺, 很厚, 需要注意的是腰部不是收腰设计的, 而是宽松的哦”这段描述文本的属性特征词和极性如表2所示:
| 表2 卖家描述极性强度得分 |
买家评论中属性特征词极性计算需要经过三个步骤:
(1) 单条评论中买家评论属性特征词极性判断
本文主要参考台湾大学的简体中文情感极性词典[ 16], 该词典包含8 276个负极性词语和2 810个正极性词语。同时, 本文又人工添加了一些表示观点的网络新词汇, 如正向情感词: 给力、拉风、牛B、赞、顶等; 以及负向情感词: 汗、无语、晕、垃圾等[ 17]。例如, 一位买家的评论为: “这质量, 太无语了, 说的是羊毛其实根本不是, 除了款式、颜色好看外, 根本不值这个价。” 该条评论的极性得分如表3所示:
| 表3 买家评论极性强度得分 |
(2) 4个指标的分值判断
买家信誉等级的分值计算依靠淘宝网原有的买家信誉等级, 由于大多数买家的信誉集中在皇冠以下, 所以规定两颗星及以下为0.1分, 三颗星为0.2分, 四颗星为0.3分, 依次类推, 五个钻为0.9分, 一个皇冠及以上为1分。
评论时间的分值依靠距离现在的时间差, 时间差越大, 分值越小。时间差在10天以内记为1分, 10-20天为0.9分, 依次类推, 80-90天为0.2分, 大于90天均为0.1分。
得票数根据淘宝评价页面中显示的“有用”个数, 因为点击此类的人较少, 所以规定大于等于9个有用为1分, 8个为0.9分, 依次类推, 1个为0.2分, 0个为0.1分。
评论长度可以根据评论文本汉字的个数来计算。本文规定20个汉字及以下为0.1分, 21-30个汉字为0.2分, 依次类推, 91-100个汉字为0.9分, 大于100个汉字为1分。
(3) 买家评论有效性计算
假设买家信誉等级、评论时间、得票数和评论长度4个有效性指标的分值分别为f(1)、f(2)、f(3)、f(4), 权重分别为w1、w2、w3、w4, 则该条评论的有效性最终得分的计算公式为:
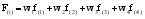 | (1) |
其中, i=1,2…n,n表示有n条评论。为了计算有效性中各个指标所占的权重, 本文邀请一些专家对这4个指标的重要性进行比例分配, 4个指标权重之和必须等于1。例如, 买家信誉为0.3分, 评论时间为0.5分, 得票得分为0.2分, 评论长度得分为0.4分。这4个指标经过专家打分后的权重分别为0.25,0.20,0.25, 0.30, 则该条评论有效性的分值为 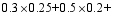
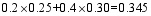
(4) 多条评论属性特征词综合极性得分计算
本文将所有评论中的属性特征词极性得分乘以所在评论的有效性得分, 然后求和取均值, 得出该属性特征词极性的最终得分。假设有n条评论都提到了第t个产品属性, 这n条评论的有效性为F(i), 其中i=1,2…n。评论中第t个产品属性的极性分值为ei, 其中i=1,2…n, 则这n条评论中第t个产品属性的综合极性得分计算公式为:
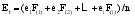 | (2) |
其中, i=1,2…n, t=1,2…m。i表示任意一条评论, 共有n条评论; t表示任意一个属性特征词, 共有m个属性特征词。例如, 一件商品共有3条评论, 这3条评论中“质量”的极性分值分别为+1、+1、-1, 有效性得分为0.345、0.45、0.125, 则“质量”这个属性的综合极性得分为: (1×0.345+1×0.450-1×0.125)/3=0.223。
相符度计算分为两步: 将买家属性特征词的极性得分除以卖家属性特征词极性得分, 求出单个属性特征词的对比结果; 将所有属性特征词的对比结果求平均值, 得出总的相符度分值。假设Ets表示卖家的属性特征词得分, Etc表示买家的属性特征词综合极性得分, t=1,2…m表示一共有m个产品属性词。则相符度的计算公式为:
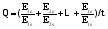 | (3) |
本文获取了淘宝网上一款销量较好的女士羊毛大衣的三家店铺的评论和宝贝描述, 最终得到这三家店铺的评论个数分别为A店1 708条、B店2 056条、C店1 922条。 然后分别构建属性特征词库, 经过比对后, 保留重复的属性特征词, 具体如表4所示:
| 表4 买家和卖家重复属性特征词 |
为了确定买家评论的4个有效性指标的权重, 邀请专家对4个指标进行打分, 邀请的专家中有女装皇冠卖家还有经验丰富的买家, 通过阿里旺旺进行沟通, 发放电子问卷表格并回收答案, 最后计算每个有效性指标的最终权重得分, 如表5所示:
| 表5 有效性指标权重分配 |
根据多条评论属性特征词综合极性得分计算公式, 计算出买家属性特征词的综合极性得分, 再根据极性词表比对得出卖家描述中属性词极性得分, 结果如表6所示:
| 表6 三个店铺属性特征词极性得分汇总 |
分别对属性进行分析, 可以看出对A店而言, 只有夹棉这个属性值的比值(0.809/1=0.809>80%)大于80%, 说明卖家描述与买家评论在商品的夹棉属性上相符程度高, 其余的属性相符程度并不高; 对于B店而言, 质量、版型、厚度、里衬以及尺寸这5个属性均相符度较高; 对于C店而言, 颜色、紧身、标签、版型、包装和尺寸相符度较高。
下面考虑最终相符度计算, 以A商家为例, 买家评论与卖家描述是否相符的最终相符度得分为:
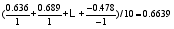 | (4) |
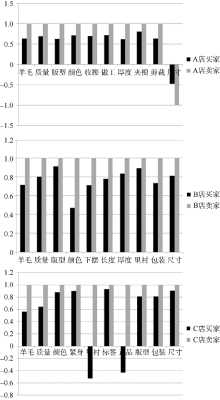
同理, B商家和C商家的最后得分分别为0.766 0和0.551 1。将它们各个属性特征的极性得分数值分别用柱状图来表示, 如图4所示:
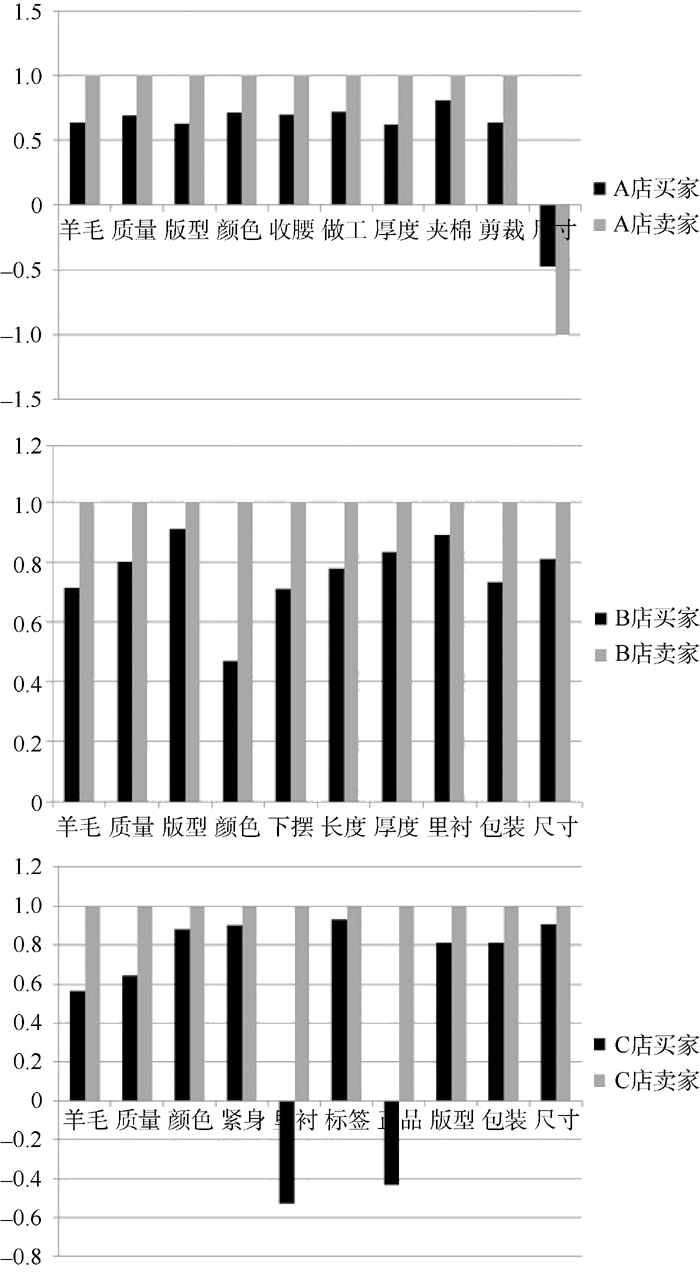 | 图4 三个店铺属性特征词极性得分对比 |
通过上面的结果可以看出, B商家分值最高为0.7660, 说明与宝贝描述相符的程度很好, 相符度为76.60%, C商家相符度最差, 只有55.11%。分析每个商家产品的属性特征词得分可以看出: 商家A销售的商品中除了尺码得分比较低以外, 其他属性都较好。并且商家A在描述中已经提到: “本店尺码比正常的码号要小, 请各位买家购买时尽量选择比平时衣服大一号”。卖家对于尺码的描述中也表示: 尺码与常规不符, 尺码的情感得分也为负值, 所以如算式(4)中计算的, -0.478/-1最后一项的结果就为正值, 在最后计分时除法抵消了负号对总分的影响, 相符度得分仍然较高。商家B的所有产品属性得分都较高, 除了颜色的分值最低。因此, 商家B需要更新照相设备或者将照片处理后再上传, 使颜色尽量与宝贝实物相符。商家C最注重包装和商标这些商品外在的东西, 而买家均反映版型很好, 但是质量、含羊毛量以及里衬一般, 里衬和是否正品的评判分值为负, 买家对它是否是正品表示怀疑, 因此该店的相符度得分最低。
将本文的结果与淘宝原有的系统比较发现:
(1) 淘宝系统中的“宝贝与描述相符”得分是根据各买家对店铺的打分, 计算出的平均值, 这个分值的评判过于简单。而本文是对文本进行定量化的处理, 将买家和卖家的属性特征词极性分值进行比较得出的相符度分值, 该分值更具有准确性和科学性。
(2) “大家印象”是最近淘宝新增加的语义评论内容, 这部分没有对评论的有效性进行分析, 只是提取了评论中的高频词作为“大家印象”, 如图5所示:
 | 图5 淘宝评价系统中“大家印象” |
而本文给出的属性特征词以及极性得分考虑了影响评论有效性的4个指标, 降低了一些经验不足的买家或者没有认真写评论的买家的中差评对平均分值的影响, 同时也降低了时间久远的评论对目前产品的影响, 更好地向消费者传递出商品的真实信息。
(3) 淘宝给出的“大家印象”中关键词评判过于模糊, 也容易产生歧义。比如图5中的“尺寸有偏差”这一项, 使人不清楚到底是卖家没有说明衣服尺寸有偏差, 还是卖家已经说了且买家也确实认为尺寸不符。这两个对“宝贝与描述相符”得分的影响是截然相反的。如果卖家没有说清楚, 则相符度分值应该减少; 如果卖家说清楚了, 则相符度得分应该增加。由于淘宝原始系统的“大家印象”没有考虑到卖家的商品描述信息, 因此会让一些卖家蒙受委屈, 而本文考虑到了这点, 将买家评论与卖家描述对比起来研究就会避免上述的误区。
研究发现, 如果评论中含有买家上传的照片则会对评论的效用产生很大的影响, 本文仅仅考虑了文本的对比, 对于图像的挖掘和比对仍有待研究。同时, 本文的数据来自服装类的体验性商品, 研究模型能否很好地适用于书籍、数码产品等一些搜索性商品, 仍有待进一步证实。研究还发现, 买家评论中还会出现“还行”、“一般”、“就那样吧”这样的中性词, 由于本文考虑的是评论与卖家描述的相符程度, 而不是一篇专门的对评论情感极性判断的文章, 因此限于篇幅的影响, 只考虑了极性较强的情感词的判断。其实对于情感的程度细分, 还可以划分为很多等级, 比如“很好”、“好”、“不错”、“还行”、“一般”、“不行”、“较差”、“很差”、“极差”等多个等级, 在研究时还需要请专家对这些词进行极性打分计算。如何对极性强度进行判断以及极性程度的细分将是未来的研究方向。
商品评价信息无论是对消费者而言还是对商家而言都是十分重要的信息来源, 判断商品的评论与卖家给出的信息是否一致, 可以很好地检验卖家是否诚信经营, 也可以很好地帮助消费者或者第三方平台辨析信息的可靠性。因此, 判定卖家描述信息与买家评价信息的相符度具有很好的实际应用价值。
本文以淘宝为研究背景, 将买家评论与卖家描述对比起来分析, 并结合评论有用性指标, 构建了买家与卖家相符度计算模型。结果以数值和图表两种方式呈现, 准确、形象地反映了卖家描述在各个属性上的相符程度, 能有效地帮助买家进行决策。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|