{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
网络商品评论的特征-情感词本体构建与情感分析方法研究*
[杜嘉忠1 , 徐健1  , 刘颖
, 刘颖2 ]
, 刘颖|
|


作者贡献声明:
[1]徐健: 提出研究思路, 设计研究方法;
[2]徐健, 杜嘉忠, 刘颖: 文献调研, 收集和研究;
杜嘉忠, 刘颖: 选定研究数据, 对数据进行收集和清洗;
杜嘉忠: 研究过程实施, 原型系统开发, 数据分析, 论文起草和修改;
徐健, 刘颖: 论文审阅、定稿和最终版本修订。
【目的】解决情感分析领域使用通用情感词典进行情感分析时, 在特定领域内无法识别领域专用情感词, 以及同一情感词描述不同特征时可能表达出不同情感倾向的两个问题。【方法】提出一种基于领域专用情感词的网络评论情感分析方法。该方法构建特征-情感词本体, 利用本体对网络上的产品评论进行情感分析。并与基于Senti-HowNet词典的情感分析方法进行对比。【结果】本文方法在特征层的情感倾向分析的准确率和召回率都有显著提高。【局限】本文方法中的本体需要尽可能完整的特征词集和情感词集, 并且情感分析结果好坏直接依赖于本体的构建是否完善; 由于网络文本的不规范性, 特征词和情感词抽取以及情感分析的过程都不考虑句法结构; 数据分析过程对问题进行了简化, 仅考虑特征粒度的情感倾向, 未考虑连词等对情感倾向有影响的其他因素。【结论】对专用情感词和通用情感词进行分类管理, 解决了两个问题, 情感分析结果得到提高。
[Objective] In a specific domain, sentiment analysis, mostly based on general lexicon, cannot identify the context-specific sentiment belonging to the domain. Also, the same word in the specific domain shows different polarities (positive, negative, neutral) when describing different properties. The objective of this paper is to solve the problems described above.[Methods] A sentiment analysis approach based on domain-oriented specific sentiment phrases is proposed. By developing feature-sentiment Ontology, general sentiment and specific sentiment can be divided during the process of sentiment analysis.[Results] The proposed method shows fairly better results of precision and recall in terms of phrase-level sentiment analysis.[Limitations] In order to get better analysis, the Ontology should cover the concepts in the related field as much as possible and should be well-built; the authors ignore the syntactic rules during the concept extraction and sentiment analysis, because the product comments are not normative; in the phase of sentiment analysis, the authors assume that the context like conjunction would not affect the polarity.[Conclusions] The new method not only makes improvement on sentiment analysis by solving the problem described above, but also proposes a new way for sentiment lexicon management.
电子商务和社区论坛的发展, 使特定产品的网络评论数量激增。特定产品的网络评论, 具有数据量大、描述特征集中、便于获取、包含主观情感等特点, 这些特点为利用这些产品评论进行情感分析提供了便利。通过对产品评论文本进行情感极性(正向、负向、中性情感)分析, 能够为消费者购买决策提供更全面的参考信息, 同时也可为商家了解顾客需求、改进产品提供决策支持。
情感词表的完整性、句子语境变化等都将影响情感分析的结果。某些情感词会经常用于描述某些特征, 而某些情感词与某些特征的结合, 会表达出不同的情感倾向, 例如“性价比高”和“价格高”。针对这些问题, 本文引入专用情感词和通用情感词的概念, 以手机产品评论为语料, 构造带有情感词的手机产品本体, 提出特征-情感词本体的情感分析方法, 来分析句子的情感倾向, 以期解决情感词描述不同特征表达不同情感倾向的问题, 提高情感分析精度, 并通过领域的知识, 识别领域专用情感词, 提高隐含识别的效果。
情感分析是当前文本挖掘领域的研究热点之一, 通过计算机分析和处理文本中所包含的用户的观点、情感和主观性内容[ 1], 常见的方法之一是通过情感语义倾向判断来进行情感分析。
基于语义倾向的情感分析研究的基本原理是利用通用情感词典或者编纂情感词表来进行情感分析。典型的研究有Tong[ 2]构建的在线评论跟踪系统, 该研究通过人工添加和标注情感词, 并基于词表进行情感分析。有学者使用种子词和WordNet扩展词表[ 3], 也有学者在通用情感词表的基础上, 添加领域情感词典[ 4]来扩展情感词表, 再基于词表匹配以及利用算法和规则计算情感倾向。该方法能获得较好的分析结果, 但面向具体领域的情感分析时, 只能得出简单的情感分析结果, 难以得知情感是针对哪个具体对象而表达的, 因此没有充分利用领域的知识来归纳和检索情感分析结果。
针对上述问题, 为了优化和充分利用情感分析的结果, 有学者开始探索利用领域本体对特定领域的文本进行情感分析的方法。主流的研究思路是借助于特征本体概念集获取和归纳评价对象, 使用通用情感词典, 如General Inquirer或Senti-WordNet等, 判断情感倾向[ 5, 6]。这些研究使用通用的情感词典进行分析, 忽略了情感词依赖领域和语境的特性, 也忽略了某些情感词会经常用来描述部分特征, 某些情感词可以描述所有特征。Yin等[ 7]提出了产品导向的领域本体建模的方法, 并且把情感词与本体结合, 从汉语评论文本中抽取特征观点对(FOP), 但是该方法仅限于隐含特征和表达情感倾向信息的识别, 并未应用于情感分析。因此, 国内有学者[ 8, 9]提取部分特殊评价词, 并形成与特征的搭配映射, 再结合特征本体和情感词典进行情感分析。尽管如此, 此方面的中文文本情感分析的相关研究还是较少。
综上所述, 目前相关研究存在的问题主要有三个: 使用领域情感词典的研究忽略了具体领域内概念间的相互关系, 不利于情感分析结果的充分利用; 而基于本体的分析方法虽然结合了领域知识, 却依赖通用情感词表, 忽略了领域内的专用情感词; 此外有关隐含特征识别的研究非常少。这些不足导致情感分析难以解决情感词因语境不同而表达不同情感倾向的问题, 难以充分利用领域内专用情感词进行隐含特征识别。因此, 本文提出基于特征-情感词本体的情感分析方法, 试图解决上述问题, 优化情感分析结果。
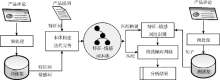
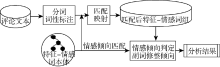
本文提出了基于特征-情感词本体的情感分析方法, 该方法不仅解决了第2节提出的问题, 而且提供了一种非线性的情感词典管理的方法, 实现了情感词分类管理。该方法主要包括两个过程: 本体构建以及情感分析, 如图1所示:
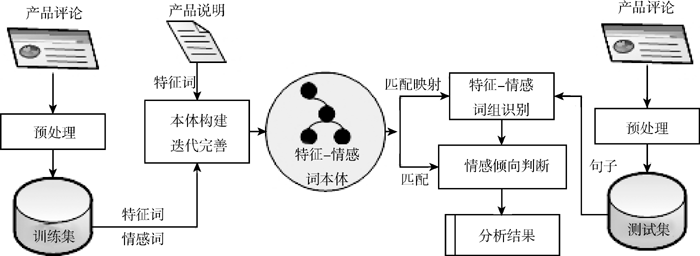 | 图1 基于特征-情感词本体的情感分析基础流程 |
(1) 本体构建过程如图1左部所示, 首先利用产品说明手工提取特征词添加至本体, 然后通过训练集提取产品评论中的特征词以及情感词, 形成特征情感词本体。本体构建过程将在3.1节和3.2节详细展开。
(2) 情感分析过程如图1右部所示, 首先利用特征-情感词本体, 对每个句子中的特征和情感词进行匹配和映射, 形成特征-情感词组。然后, 将特征-情感词组与本体进行匹配, 计算出句子中各个特征情感词组的情感倾向, 最后计算整个句子的情感极性, 得出分析结果。情感分析过程将在3.3节详细说明。
为了更充分地利用领域知识, 提高情感分析的效果, 以及通过专用情感词探测隐含主题, 笔者提出特征-情感词本体。该本体是一个包含特定产品的部件、属性、情感词以及它们之间关系的知识模型, 用于识别出文本中所描述的部件或属性, 以及分析情感倾向。
(1) 特征-情感词本体定义
本研究中的本体定义了产品的部件以及相应的属性, 并且定义了专用情感词和通用情感词。因此, 特征-情感词本体中的每一个产品部件的完整概念C可以定义为一个六元组, 即:
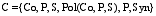 | (1) |
其中, C代表产品一个部件的完整概念; Co代表产品部件, 表示产品某部件的概念, 如“屏幕”; P代表属性, 表示产品某部件的特定属性概念集, 如“色彩”; S代表情感词, 如“艳丽”; Pol(Co,P,S)代表情感极性, 情感极性受到语境的影响, 这里的语境表示的是所描述的部件Co或者属性P, 例如, “性价比高”和“价格高”, 两个语境下, 隐含的部件Co均代表“手机”, P分别代表“性价比”和“价格”, S均为“高”, 而情感极性Pol分别为正向和负向; R代表一个关系集合, 即Co与P的关系, P与S的关系等。例如, P与Co之间的关系是“是属性”关系; Syn代表Co、P的同义词集合。本体中主要包括6种概念层次关系: “是部件”是产品与部件间关系; “是属性”是部件与属性间关系; “是通用情感词”是部件或属性与通用情感词集间关系; “是专用情感词”是部件或属性与其专用情感词集间关系; 上下位关系(见图3中的“是子类”)是属性或部件与其子类的关系; 类和实例的关系是部件或属性与其同义词的关系, 以及情感词集与其实例的关系。
(2) 特征-情感词本体构建过程
本研究的领域本体采用了计算机辅助、手工构建的模式, 基于评论语料库来构建和扩展本体。特征-情感词本体构建的主要流程包括产品特征概念与情感词抽取和向本体添加情感词集两个步骤。
①产品特征概念与情感词抽取
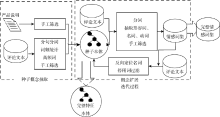
特征概念与情感词抽取的过程包括两个, 分别是: 种子概念获取和概念扩展, 具体流程如图2所示:
 | 图2 特征概念和情感词抽取过程 |
产品的特征概念主要有两大来源: 产品的参数说明和产品评论文本。情感词来源于产品评论文本。产品说明中包含与产品相关的完整信息, 包括基本部件以及部分属性和参数, 因此通过抽取产品说明中的相关信息, 可以获取有关产品的基础概念。产品评论文本由用户产生, 因而评论中包含着一些非专业名词、惯用语等。因此, 从评论文本中抽取的产品概念可扩充本体中的同义词集。
种子概念抽取是通过对产品说明中的概念进行手工抽取, 并对评论语料中的高频词进行筛选, 进而形成种子词、构建种子词本体的过程。种子本体是一个特征本体, 包含产品的特征和属性, 概念层次关系包括“是部件”、“是属性”、概念上下位关系、类和实例关系4种。种子本体是由种子概念遵循这4种关系构成的。
概念扩展过程包含产品概念扩展和情感词表扩展。已经有学者开始研究网络情感词自动识别技术[ 10], 但是准确率和召回率不能满足本研究需求。为了获得全面准确的词表, 本文利用计算机辅助形成候选集, 再利用手工筛选的方式来扩展词库。首先基于种子本体中的概念, 选择与中心词距离最近的形容词、名词、动词和副词加入候选集; 其次手工筛选候选集中的词语, 把筛选后的产品概念加入本体, 并且把情感词添加到情感词集合; 最后反向利用情感词, 来定位和挑选低频的特征[ 11](产品部件和属性), 经过几轮迭代, 便可以得到较为全面的产品概念和情感词。
②情感词集添加至特征本体
本实验中所构建的本体部分截图如图3所示:
 | 图3 本体模型的部分截图 |
特征概念和情感词概念抽取完毕后, 需要在本体中添加和标注情感词。本研究区分专用情感词和通用情感词, 对本体中的情感词实行分类管理。关于专用情感词的定义和分类会在3.2节说明。若情感词为通用情感词, 则添加至通用情感词集合, 并添加情感倾向标注; 若情感词为专用情感词, 需要根据情感词所描述的部件或属性, 来判断并标注其情感倾向, 并加入到对应的专用情感词集。情感词标注“1”代表该情感词在该语境下, 是正向情感词; “-1”代表负向情感词; “0”代表中性情感词。例如“高”一词, 作为“价格”的专用情感词, 情感倾向标注应为“-1”, 表示该情感词在语境下, 表达出负向情感。相反, 在描述“摄像头”的“像素”属性的语境下, 情感倾向标注应为“1”, 表示该情感词在该语境下表达正向情感。
本文中的专用情感词和通用情感词概念, 是在特定领域内定义的, 不同的领域会有不同的专用情感词和通用情感词集。例如, 在手机产品领域, “死机”是该领域的一个通用情感词, 在日用品产品领域并不存在这个词语, 因此也不会是该领域的情感词。
目前对于特定领域情感词分类的研究较少, Yin等[ 7]把手机领域中情感词划分为通用意见(General Opinion)和专用意见(Specific Opinion), 并且分别定义为观点词与特征的一对多和一对一的关系。这种划分在一定程度上可以解决情感分析隐含特征识别的难题, 但是对于某些情感词描述不同特征表达不同情感倾向的问题难以解决。因此, 本文提出一种改进的定义。针对一个产品领域, 通用情感词是指词语本身表达了情感, 而且在大多数的语境下适用, 并表达相同的情感倾向的情感词, 例如“喜欢”、“垃圾”、“划痕”等。而专用情感词有两种情况, 第一种是指只会在特定语境下出现的情感词, 在其他语境不会或极少出现的情感词, 例如“超薄”, 一般只会在描述手机机身厚度的语境下出现。第二种是指情感词可用于描述领域中多个特征, 但描述领域中某些特征时, 表现出与一般情况不同的情感倾向。例如, 手机产品领域, “手机掉电很快”, “快”这一情感词在这个语境下属于负向情感的专用情感词, 但是“快”也是该领域的一个专用情感词, 因为它在大部分语境下表达了正向的情感, 例如“屏幕反应很快。”
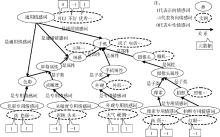
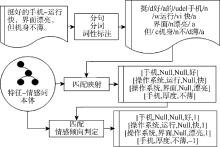
根据以上定义, 需要用不同的方法实现情感词的分类。情感词分类的流程如图4所示。首先利用图2中提取到的“完整情感词集”和“完整特征本体”, 把情感词与特征以共现对的形式抽取, 形成特征-情感词共现库。再采用图4中两种分类法进行分类。分类方法1(改进的TF-IDF分类法)适用于区分通用情感词与第一种专用情感词; 分类方法2适用于区分第二种专用情感词。
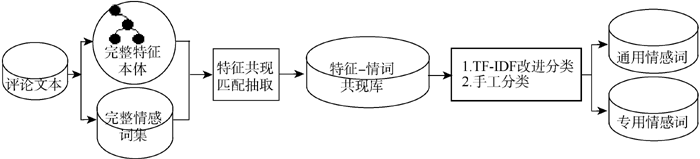 | 图4 情感词分类流程 |
分类方法1基于一个假设: 专用情感词会频繁与某部件共现, 且不会或很少与其他的部件或者产品属性共现, 因此, 基于TF-IDF[ 12]来设计改进算法, 以区分第一种专用情感词和通用情感词。分类算法为:
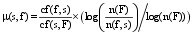 | (2) |
其中, 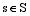
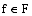
图4中分类方法2为手工分类, 因为该类专用情感词的正确识别, 主要依靠人工总结和识别的方法。然而, PMI-IR算法[ 13]等相似度计算方法, 也适用于第二种专用情感词的筛选, 但该情感词的分类目前仍存在难点, 具体的分类算法有待研究和尝试。
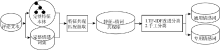
基于特征-情感词本体的情感分析方法的主要流程包括: 预处理、特征-情感词组匹配映射、情感倾向分析。情感分析基本流程如图5所示, 对一个经过预处理的句子, 利用本体匹配特征和情感词, 同时匹配副词表中的副词。再通过本体中的上下位关系、同义词关系, 将句子中特征词映射到本体中相应的特征上, 形成特征-情感词组。最后利用本体, 对该特征-情感词组的情感倾向进行判定, 结合副词, 修整情感倾向, 得出分析结果。
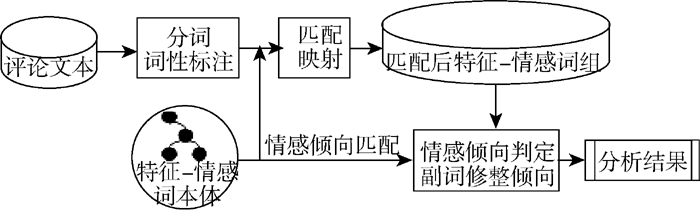 | 图5 情感分析的基本流程 |
(1) 特征-情感词组匹配与映射
特征-情感词组是一个多元组, 包含部件、属性、对情感倾向有影响的副词和情感词, 表示为[部件, 属性, 副词, 情感词]。在某些语境下, 属性可以缺省, 因为某些情感词描述的对象是部件本身, 并不针对某个具体的属性。例如: “外壳掉漆”描述的是外壳本身, 不存在明显属性, 因此属性是一个缺省值。对情感倾向有影响的副词主要是否定词, 例如“没有”、“没”、“不”等。
特征-情感词组的匹配映射过程是把句子中的每一个词都与本体中的所有词语进行匹配, 匹配到的有可能是部件、属性或情感词, 这三者不分先后。若探测出属性词, 则通过本体概念间关系, 映射出隐含的部件, 将二者一并加入特征-情感词组中; 若探测出的情感词属于专用情感词, 则可映射出文本隐含描述的特征。例如, “手机很卡”, 特征-情感词组为[操作系统, 流畅度, NULL, 卡]。“卡”是描述操作系统的流畅度, 利用本体概念的相互关系, 映射得出隐含描述的特征。
(2) 情感倾向分析
情感倾向分析是基于匹配和映射得出的特征-情感词组来分析的。本体中包含通用情感词和专用情感词词集, 而且每个词都标注了情感倾向, 因此只需要匹配本体中的这些情感词所在的语境, 获取该语境下情感倾向即可。例如: “卡”一词, 在本体中描述的是操作系统的流畅度, 因此与特征-情感词组的匹配, 情感倾向标注为“-1”, 即结果为[操作系统, 流畅度, Null, 卡, -1]。若句子有多个特征, 整个句子的情感得分则表示为所有特征的情感强度之和。
为了验证本文方法的有效性, 将上述方法与基于Senti-HowNet的情感分析方法进行对照实验。首先确定实验数据集; 其次进行特征概念和情感词抽取, 手工构建本体; 最后通过特征-情感词本体对测试集进行情感分析, 将分析结果与对照实验进行对比。
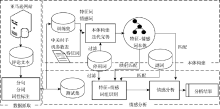
实验过程如图6所示, 包括数据抓取、本体构建和情感分析三部分。
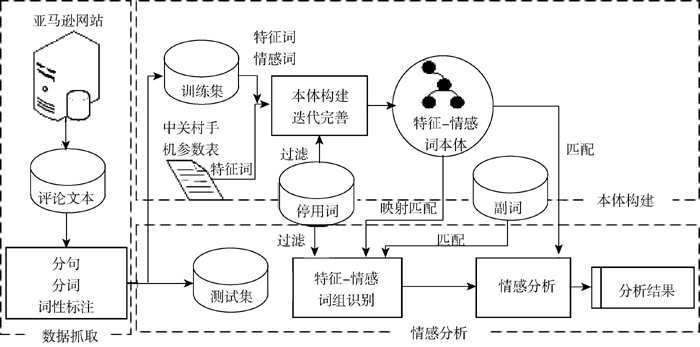 | 图6 基于特征-情感本体的实验流程 |
选取亚马逊网站手机产品类目中评论数量较多的10款产品[ 14], 共爬取1 048个评论文本, 经过分句和预处理, 一共有2 865个句子, 这些句子即为概念和情感词抽取的训练集。测试集是从训练集筛选出的情感倾向表达明显且表达完整的600个单句。本文实验构建了一个否定副词表, 共12个表示转折的常用副词, 例如: 没什么、没、不够、无、太等。停用词表使用常用的中文停用词表, 包含1 296个词语。预处理过程中, 使用了ICTCLAS 2013版本的开源分词系统[ 15]。对照实验中, 使用Senti-HowNet[ 16]的情感词库, 包含中文正面评价词3 730个, 负面评价词3 116个, 正面情感词836个和负面情感词1 254个。
本文使用Protégé 4.2[ 17]构建本体, 利用Jena API对本体进行检索和利用。实验利用中关村iPhone 5的参数, 选取“屏幕”、“触摸屏”、“电池”、“尺寸”、“充电器”等35个概念, 从评论文本生成的高频词中提取词频大于10的53个概念, 因此种子本体中包含88个概念。种子本体包含上下位关系、“是属性”关系、“是部件”关系、类和实例关系共4种。部分概念如表1所示:
| 表1 种子本体中概念归类 |
按照3.1节的流程扩展本体概念, 最终形成的特征-情感词本体共包含167个特征概念术语(包括部件、属性和同义词), 得到情感词共有384个。
使用3.2节提出的基于TF-IDF改进分类算法(见公式(2))对情感词进行分类, 以手工分类为标准, 通用和专用情感词分类的正确率为54.31%, 设置的阈值为0.7。经过笔者分析, 该结果正确率偏低, 是由数据量不足引起的数据稀疏造成的。例如“不咋的”、“气人”等大量的通用情感词仅出现了一次。因此, 随着数据量的增加, 算法的准确率会提高。本研究中, 通用情感词的数量为263个, 专用情感词数量为75个, 其中既是通用情感词又是专用情感词的数量为46个。本文的分析方法依赖较全面的概念术语以及情感词的准确分类和倾向标注, 因此通过机器辅助分类得到的结果还需要通过手工修正再添加至本体。
以本文采用的实验数据中某句子的分析处理为例, 详细说明情感分析的过程。具体情感分析过程如图7所示:
 | 图7 情感分析过程实例 |
首先对句子进行分词和词性标注处理, 利用特征-情感词本体匹配映射出4个特征-情感词组。然后把每一个特征-情感词组与本体进行匹配, 得出的结果结合副词修正情感倾向, 然后把情感倾向计算结果添加至特征-情感词组中。
对比实验参考了Yin等[ 7]研究中的一个对照实验, 利用本文构建的特征本体(不包含情感词)来探测句子特征, 情感词的匹配和情感倾向的判断, 使用了Senti-HowNet的情感词库。
对于实验结果的评价, 本文采用同类实验普遍采用的准确率、召回率和F1-指数来进行评价[ 11, 18, 19]:
(1) 情感分析召回率:
 | (3) |
(2) 情感分析准确率:
 | (4) |
(3) F1-指数:
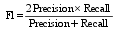 | (5) |
采用基于特征-情感词本体的情感词分析方法和基于Senti-HowNet的情感分析方法实验结果对比如表2所示:
| 表2 对比实验结果 |
实验数据显示, 本文方法比基于通用情感词表以及情感词表单独管理的情感分析方法效果更好。使用本文方法, 可以探测出句子当前描述的特征, 而且可以根据专用情感词, 推测出隐含描述的对象。例如, 本文方法正确判别“价格高”为负向情感, “性价比高”为正向情感, “流量掉得快”为负向情感, “手机运行很快”为正向情感等。而Senti-HowNet词典对于“高”和“快”两个词语, 均判定为表达正向情感。再如, 对于“手机很轻, 很薄。”这个句子, 本研究的算法分析结果是[手机, 重量, 很, 轻], [手机, 厚度, 很, 薄], 情感倾向均为正向情感, 识别出隐含特征分别为重量和厚度。Senti-HowNet会判断出“轻”为正向情感, “薄”为负向情感, 无法完全正确分析, 而且无法映射出当前所描述的属性。此外, 分析得到的细粒度结果可以轻易地根据本体进行归纳和可视化处理, 更好地优化情感分析的效果。
实验数据表明本文方法表现都优于基于Senti- HowNet的情感分析方法, 这是因为传统的通用情感词难以覆盖很多手机领域专用的情感词和评价词, 而且传统的方法忽视了情感词在不同语境下的多倾向性, 因而难以根据当前描述的对象计算出正确的情感倾向。
本文提出了基于领域专用情感词的网络评论情感分析方法, 提高了特定领域网络评论文本情感分析效果。该方法通过使用改进的TF-IDF算法来区分通用情感词和专用情感词, 构建带有情感词的本体, 解决了情感词基于不同语境表达不同情感倾向的问题, 提供了一种新的情感词典管理方法。
但是, 本研究目前还存在非常多的不足, 例如在该方法中, 领域术语和情感词的抽取准确率仍然有待提高, 依赖人工方式来构建本体和情感词典的方式, 包含非常大的工作量。此外在情感分析方法上, 仍有可提高的空间。
未来的研究会集中在提高专用情感词的辨析正确率, 以及引入情感强度计算, 深化分析结果等方面。同时本文做了非常细粒度的情感分析, 因此情感分析结果可以应用到许多领域, 例如评论检索、可视化结果等。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|