

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
图像检索技术在“经典阅读”教学系统中的实现与应用*
[吴坤1  , 颉夏青
, 颉夏青2 , 白权威3 , 吴旭2, 3 ]
, 颉夏青|
|


作者贡献声明:
吴坤, 吴旭: 提出研究思路, 设计研究方案;
吴坤, 白权威: 建立并实现研究模型, 部署应用并进行实验、数据采集和分析;
吴坤, 颉夏青: 论文起草;
吴旭: 最终版本修订。
【目的】扩展“经典阅读”教学系统的图像检索途径, 提高经典名著教学资源的利用率。【应用背景】“经典阅读”系统是基于阅读学分机制的教学体系创新平台, 增加图像检索功能是对已有文本检索的补充和拓展, 能够提升教学效果。【方法】建立基于特征语义的图像检索模型进行图像特征值提取、归一化和相似性度量, 实现检索请求提交、图像检索、结果反馈和图片管理等功能模块。【结果】实现图像分类自动化, 能够通过相关图像检索到相应图书, 准确率介于92%到100%之间。【结论】提升“经典阅读”教学系统的用户体验, 改善“经典阅读”教学效果。
[Objective] This paper trends to expand retrieval approach in “Classic Reading” Teaching System and improve utilization of classical teaching resources.[Context] “Classic Reading” Teaching System is a credit-based innovation platform on teaching system, and adding image retrieval function can greatly extend the existing text-based retrieval and improve teaching effects.[Methods] This paper establishes the Semantic-Based Image Retrieval Model including extracting features, vector normalization and similarity measurement, realizing four modules including query-submit, image-retrieval, result-feedback and image management.[Results] The images in the platform are classified automatically and students can find the book with a related image, and the precise of image retrieval lays between 92% and 100%.[Conclusions] It can improve user experience as well as the teaching effects of “Classic Reading”.
为有效推广经典阅读, 引导大学生选读由专家推荐的经典名著, 北京邮电大学构建了基于阅读学分机制的“经典阅读”教学体系创新平台, 其教学活动已在实践工作中取得了较好的效果。然而, 用户调查表明, “经典阅读”教学系统通过经典书目列表向学生提供图书简介、全文、馆藏等相关信息, 只是被动地“等待”学生参与而非主动“吸引”, 虽拥有丰富的图片等多媒体资源却未充分利用。为此, 本文采用基于特征语义的图像检索技术来丰富检索途径, 一方面提高经典名著的利用率, 另一方面增加平台的趣味性, 提高“经典阅读”教学活动参与度, 提升教学效果。
图像作为一种主要的多媒体资源, 相较于文本信息有更丰富的内涵、更形象的表现力、更强的感染力。当学生被互联网上一些图书插图等与经典名著相关的图片所吸引, 却不知道具体书名时, 如果能够抓住这种偶然触发的兴趣, 帮助学生实现由相关图片到经典名著的定位, 就能够主动吸引学生参与到经典阅读中来, 相比生硬的图书列表、静态的图书简介更加形象、有吸引力。另一方面, 当前“经典阅读”教学系统的检索结果仅包括书名、作者、摘要等文字信息, 若辅之以相应的图书插图等图像展示, 会增加学生对经典名著的关注和兴趣, 进而转化为阅读的动力。
当前常用的图像检索技术有两种, 即基于文本的图像检索(Text Based Image Retrieval, TBIR)[ 1]和基于内容的图像检索(Content-Based Image Retrieval, CBIR)[ 1]。由于文本描述难以充分表达图像包含的复杂信息, 而且检索结果的准确性依赖于关键词的标引, 所以基于文本的图像检索受主观因素影响较大而且检索效率低; 基于内容的图像检索能够较客观地通过提取图像的内容特征如颜色等进行相似度比对实现检索过程, 检索效率较高。基于内容的图像检索实质是基于特征语义的图像检索, 很多系统已经利用多种方法进行了应用, 如基于颜色[ 2, 3, 4, 5, 6]、基于纹理[ 7]、基于形状[ 8]和基于空间关系[ 9]等。随着图像检索技术的发展, 基于图像高层语义的图像检索技术逐渐成熟, 能够更好地解决人所理解的“语义相似”与计算机理解的“视觉相似”之间的“语义鸿沟”(Semantic Gap)[ 10]问题。
“经典阅读”教学系统中, 由于不同书目的插图特征差异较显著, 只需要提取图像的底层语义特征就可以很好地区分不同图书的插图, 进而通过比对图像特征值检索到图片相关的书目, 得到较好的检索结果, 所以利用图像的基础特征即可满足“经典阅读”教学系统图像检索功能的需求。
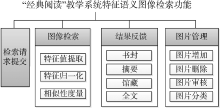
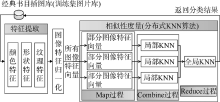
基于上述分析, “经典阅读”教学系统的图像检索功能主要包括检索请求提交、结果反馈、图像检索和图片管理4个模块, 如图1所示:
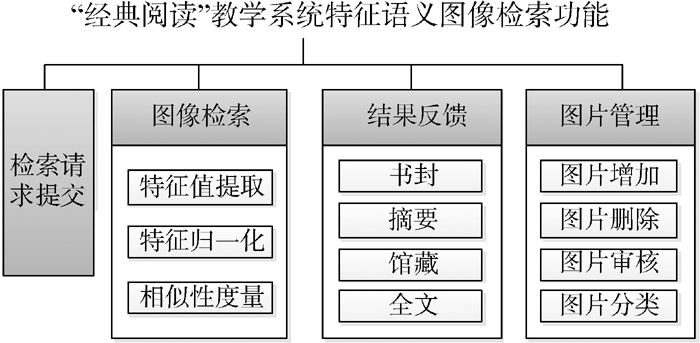 | 图1 “经典阅读”教学系统特征语义图像 检索功能模块设计 |
(1) 检索请求提交模块是图像检索功能的用户输入端。用户可以浏览文件选定图片并上传实现检索, 也可以将图片拖曳到检索框中实现上传。
(2) 图像检索模块是核心功能模块, 包括特征值提取、特征归一化和相似性度量三个子模块, 通过提取输入图片的多种特征值形成特征向量并进行归一化, 再经过与已有图片库的图片进行相似性度量完成图片分类, 获取图片所属书目。
(3) 结果反馈模块从数据库中提取目标书目的书封、摘要、馆藏和全文等信息通过一定的展示方式呈现给用户, 并且将与输入图片相似度最高的10张插图展示出来, 还可以通过“查看更多”浏览相似度较高的其他图片。
(4) 图片管理模块主要完成图片的增加、删除和审核以及图片分类4个子模块。其中图片分类子模块完成已有图片库的自动分类, 同时也是图像检索模块的预处理模块, 完成已有图片的训练。
“经典阅读”教学系统图像检索功能包括4个模块, 其中图像检索模块和图片管理模块的图片分类子模块是核心功能, 各模块的实现都基于Drupal[ 11]开源框架完成。
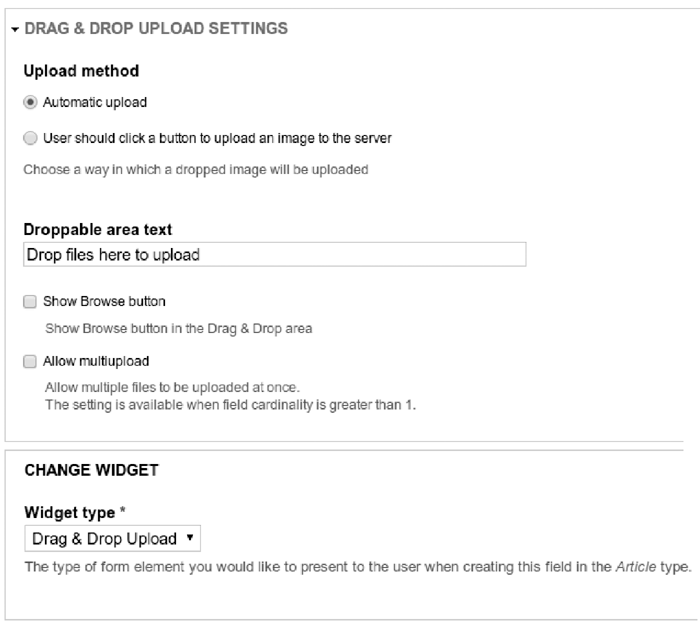
检索请求提交模块基于Drupal的“Drag & Drop Upload”模块实现了图片上传功能, 如图2所示, 用户直接点击上传图标实现图片上传, 也可以将图片拖曳到检索框实现上传。实现过程中, 需要在Drupal.org[ 11]下载该模块并进行安装、设置, 安装过程中拖曳上传功能的设置如图3所示, “Automatic Upload”选项可实现拖曳后自动上传, 另外本系统只支持一次上传一张图片完成检索。
 | 图2 检索请求提交模块功能界面 |
 | 图3 拖曳上传图片功能设置 |
图像检索模块是“经典阅读”教学系统的核心模块, 是基于图像的底层特征语义建立的, 实现过程包括图像特征值提取、特征向量归一化、相似性度量三大步骤。
(1) 特征值提取
本研究首先对“经典阅读”365种图书的插图进行了观察和分析, 发现同一种书的插图的绘画风格、配色、亮度以及尺寸非常相近, 而不同书的插图则差异很大, 如图4所示。由此推断, 判断输入图像所属的图书可以通过比对颜色、形状两个特征来实现。另外, 图像的纹理特征包含了很多重要信息, 而且是与颜色、形状特征相独立的, 所以纹理特征的提取具有重要的意义。
 | 图4 两种不同图书的部分插图图像特征对比 |
这三个特征都比较稳定, 对于图像的旋转、平移和尺度变换不敏感, 特别是纹理特征对于噪声有较强的抵抗能力, 所以允许在模型建立过程中对特征值进行变换。本文选取颜色直方图[ 12]、灰度共生矩阵[ 13]、不变矩方法[ 14]分别提取图像的颜色、纹理和形状特征。提取图像的特征越多, 对图像的描述越精细, 但是后续的存储和计算也更复杂, 通过实验验证, 将颜色分为16种分量较为合适, 因此, 通过提取插图的16维颜色特征、8维纹理特征、7维形状特征形成31维的特征向量。
(2) 特征向量归一化
使用多特征进行图像检索时, 由于不同特征的物理意义和取值范围不同, 在进行相似性度量时会产生很大的偏差, 因此先对特征向量进行归一化[ 15]来消除这种偏差, 从而提高检索的准确率。特征向量归一化的过程如下:
将特征向量记为:
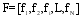
计算出图像库中各特征向量的各个分量的均值和方差; 将特征向量归一化到[0, 1]区间:
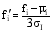
其中, 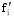
(3) 相似性度量
完成给定图片的归类首先要判断给定图片与数据库中每个图片的相似程度, 然后分析相似度最高的K张图片的所属图书情况将给定图片定位到某一本书。本文用欧氏距离[ 16]来判断两个图片的相似程度, 欧氏距离越小则说明相似度越高。在此基础上, 选择K近邻(K-Nearest Neighbor, KNN)[ 17]分类算法来完成相似性度量。一本书的已有插图构成一个类别, 已有插图的分类是通过图片管理模块的图片分类实现的, 那么如果给定图片在特征空间中的k个最相似(即特征空间中最邻近)的图片大多数属于某一个类别, 则该图片也属于这个类别。如果k=1, 那么简单判定给定图片属于其近邻所属分类。
图像检索模块完成了图片的分类, 将图片对应到其所属的图书。结果反馈模块基于Drupal的Views模块, 通过对Views模块进行模板覆写修改CSS代码对结果内容进行组织、排版显示, 如图5所示, 首先利用书名从数据库中提取图书的简介、馆藏链接、全文链接等相关信息, 同时, 提取与输入图片相似度最高的10张图片展示在结果集中, 一方面提高图片多媒体资源曝光率和利用率, 另一方面也能够丰富结果集形式, 全方位满足学生需求。
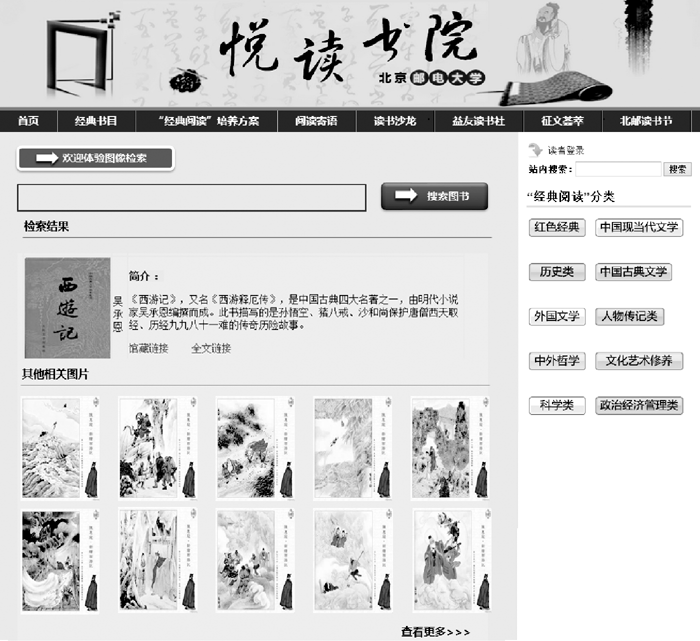 | 图5 结果反馈模块界面 |
图片管理模块中, 对图片的增加、删除、审核是通过Drupal的Image模块实现的, 图片分类的实现过程如图6所示:
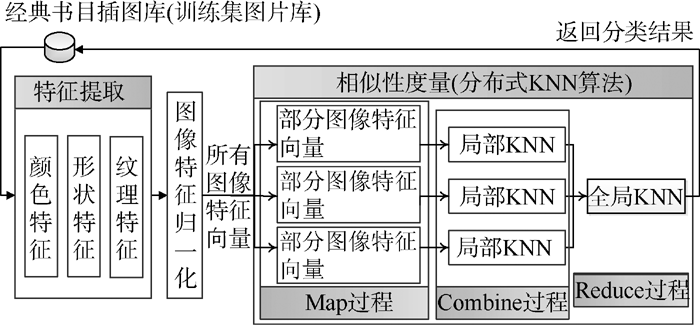 | 图6 图片分类功能的实现流程 |
原有插图库中的图片分类对于系统来说是未知的, 因此首先对每个图片进行特征值提取并分别进行特征归一化, 得到所有图片的特征向量, 进而基于KNN算法进行相似性度量。为了提高图片分类的效率, 在相似性度量时基于Hadoop[ 18]分布式环境利用MapReduce[ 19]编程框架实现了分布式的KNN算法, 主要分为三个处理阶段: Map阶段、Combine阶段和Reduce阶段。首先将所有向量分成若干份, 对于每一份中的向量两两计算欧氏距离并利用KNN算法进行比对, 最后在Reduce过程对所有向量进行比对, 完成所有图片的分类, 并将分类结果在原经典书目插图库中进行标记。
为了验证图像检索功能的应用效果, 本文先从实验角度较客观地对检索准确度进行了评估和验证, 然后从用户角度基于用户打分对图像检索功能的应用效果进行分析。
为了验证检索的准确性, 从“经典阅读”教学系统的数据库中随机选择100本书的近5 000个插图作为训练集(被检索集), 其中每本书的插图作为一类, 另选50张图片作为测试集(检索集), 部分测试集图片如图7所示。使用正确率来衡量分类准确率:
 | 图7 测试集部分图片 |
其中, n为分类正确的图片数量, N被分类的图片总数。
由于测试集图片是否包含在训练集中会对检索结果有所影响, 所以本文采用极端法设计了两组实验, 对照组中训练集包含所有测试集的图片, 实验组的训练集完全不包含测试集图片。实际应用中, 用户所传图片包含在已有数据库的概率介于两者之间, 因此结果的准确率也介于两者之间。
使用KNN分类算法时准确率会受到k值的影响, 随着k值的变化, 准确率的变化如图8所示:
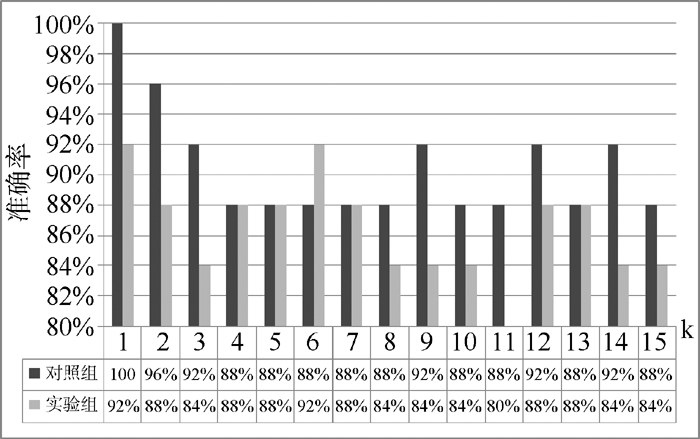 | 图8 准确率随k变化的变化趋势 |
由图8可知, 随着k值的增长, 对照组和实验组的准确率都有所降低, 对照组最小不低于88%, 实验组则在80%到92%之间波动, 平均为86%, 略低于对照组的90%。对照组的准确率总体高于实验组。
在实际应用中, k=1, 则检索结果是唯一的, 而当k大于1时, 则可能出现多个结果, 例如当k=10时,如果与被检索图片相似度最近的10个图片中分别有4个图片属于图书A, 4个图片属于图书B, 那么此时检索结果应该有A和B两种图书。但只有当不同图书的插图差异较小时才会出现这种情况, 而本系统平台不同图书的插图差异明显, 特征值相差较大所以出现概率很小。由于当k=1时, 检索的准确率最高, 因此在实际应用中将k设为1, 此时图像检索功能的准确率高于实验组的92%, 而低于对照组的100%, 也就是说图片被定位到不相关图书的概率低于8%。
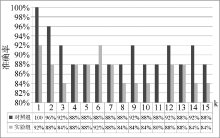
为评估图像检索功能在“经典阅读”教学系统上的应用效果, 课题组通过调查问卷的方式收集到有效反馈表100余份, 反馈表从图像检索功能的用户体验和检索质量两个主要方面对应用效果进行打分。用户体验从图像检索功能的友好性、交互和界面的易用性两个维度进行评估, 而对图像检索质量本身的评估则通过响应速度和查准率来进行。统计结果如表1所示:
| 表1 学生对图像检索功能用户打分统计(5分制) |
表1为用户对图像检索功能打分的结果, 学生对功能友好性、交互易用性的打分分别为4.1和3.9, 综合两项指标的平均分为4.0, 可见图像检索功能具有较好的用户体验; 学生对图像检索功能响应速度和查准率打分分别为4.5和4.3, 综合平均为4.4, 说明图像检索质量能够满足学生需求。
本文通过建立特征语义图像检索模型实现了图像分类自动化和图像检索功能, 包括检索请求提交、结果反馈、图像检索和图片管理4个模块。实验表明, 图像检索的准确率较高, 而且通过分析学生反馈, 可知图像检索功能更好地揭示了图片多媒体资源, 提升“经典阅读”教学系统的用户体验, 提高学生亲近经典的兴趣。
在未来的工作中, 还需要进一步丰富和充实“经典阅读”图书目录和图书的图片库, 为学生带来更好的用户体验的同时提升“经典阅读”的教学效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|