{kind=link}
专利文本技术挖掘研究进展综述
[胡正银1, 2  , 方曙
, 方曙1 ]
, 方曙|
|


作者贡献声明:胡正银: 研究过程实施, 进行具体文献调研、分析与论文撰写;
方曙: 研究命题的提出、设计, 论文修订。
归纳基于文本专利技术挖掘通用流程提炼其中关键技术并对典型挖掘场景进行分析。
【文献范围】以“专利挖掘、专利分析”等在Elsevier、Springer、CNKI数据库进行检索并参考全球技术挖掘相关会议共阅读相关文献105篇
【方法】梳理其关键技术专利知识表示的研究现状与发展趋势选取三类典型技术挖掘场景进行分析通过归纳总结、提炼出专利技术挖掘未来发展趋势与研究热点。
【结果】专利知识表示的粒度与结构决定了专利技术挖掘的深度、广度与维度。基于SAO基础语义单元面向技术难题与解决方案的专利技术挖掘有望成为未来发展趋势与热点。
【局限】本研究仅探讨现有文本挖掘、统计分析、自然语言处理技术在专利技术挖掘中的应用情况 对这些技术本身的发展趋势关注不足。
【结论】本研究有助于全面了解专利技术挖掘的概貌、涉及的关键技术及主要应用场景。
This paper generalizes the framework of patent technology mining based on text, extracts the key techniques and analyzes some typical application scenarios.
[Coverage]Chooses 105 papers from Elsevier, Springer, CNKI databases and Global TechMining Conference, and refers 66 papers at last.
[Methods]Review semantic knowledge representation of patents, analyze the research progress of three typical technology mining scenarios and summarize the hot research topics of patent technology mining based on text.
[Results]The result shows that the semantic knowledge representation of patents is very important to patent technology mining. And patent technology mining oriented to problems and solutions based on SAO units will be the hot research topics.
[Limitations]Only focuse on the applications in patent technology mining of the techniques (e. g. Text Mining, Statistics and Natural Language Processing), but the development trendency of these techniques need to pay more attention.
[Conclusions]This paper will facilitate to give an overview of patent technology mining, the key problems and the typical application scenarios.
技术挖掘是21世纪初, 美国学者Porter等提出的基于历史科技文献分析当前和未来技术发展现状与趋势的理论与方法, 研究范畴包括: 技术监测、技术竞争情报、技术趋势预测、技术路线图、技术评估、技术前瞻、技术流程管理、科技指标等[ 1]。技术挖掘的载体是已发表的科技文献, 包括: 学术论文、专利文献等。挖掘对象除了科技文献元数据字段, 如: 题名、作者、专利权人等外, 还深入到文献内容层面, 如: 文摘、全文、专利权利要求等。技术挖掘方法除基础统计分析外, 还包括: 知识抽取、文本挖掘、语义分析、数据可视化等。
与其他科技文献相比, 专利文献在文本表示方面具有格式规范、用语严谨等特点[ 2], 更容易表示成结构化语义模型; 在技术内容方面具有系统详尽、分类科学等特点[ 2], 更适合进行深度技术挖掘。因此, 专利文献成为技术挖掘使用最多的信息源。
专利技术挖掘内涵丰富, 从宏观层面上看, 可应用于未来技术趋势预测、技术前瞻研究等; 从中观层面上看, 可帮助研发机构进行技术监测、技术竞争情报分析等; 在微观层面上看, 可通过分析技术创新的基本元素、流程及方法, 作为改善和发明其他专利的基础, 为具体技术研发提供知识服务[ 1, 3]。
根据挖掘对象不同, 专利技术挖掘可分为: 专利元数据字段挖掘与专利文本挖掘两种。前者无论是方法论, 还是技术手段上都比较成熟; 而后者则是研究重点。
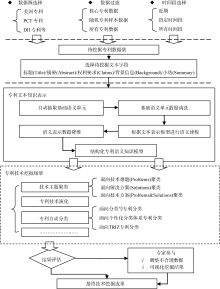
参考Porter等提出的通用技术挖掘流程与框架[ 1, 4], 结合专利分析实际场景与流程, 归纳出专利文本技术挖掘流程如下: 确定待挖掘专利数据集、专利文本知识表示、分析专利技术挖掘场景、技术挖掘结果评估与修订。具体流程如图1所示, 其核心部分是: 专利文本知识表示与技术挖掘场景分析。
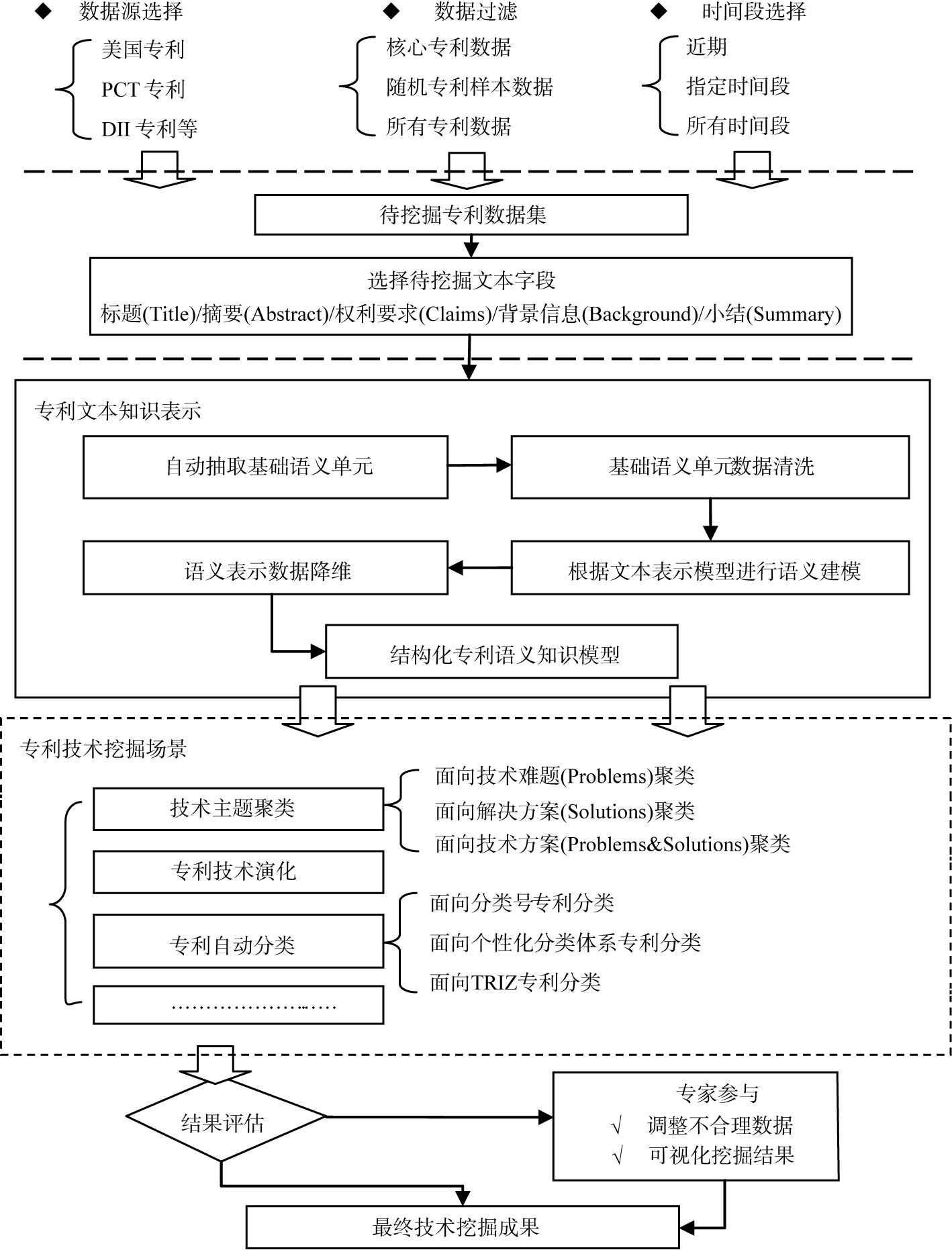 | 图1 专利文本技术挖掘流程图 |
专利文本知识表示是利用语义或文本表示技术, 从非结构化专利文本中抽取出能体现专利技术信息的结构化知识, 构建结构化语义模型。它是技术挖掘的基础与前提。根据语义建模方法不同, 现有研究可分为: 基于本体工程、基于向量空间模型、包含语义信息的向量空间专利知识表示三大类。
(1) 基于本体工程专利知识表示
该方法通过广泛专家咨询, 构建专利本体来进行知识表示。专利本体中不仅含有概念, 而且含有关系, 能充分、全面描述专利信息。它的典型研究项目是PATExpert。 PATExpert是欧盟FP6资助的一个项目, 目标是通过构建全面规范的本体来对专利进行全方位语义表示, 以支持语义层面上的专利分析与利用[ 5]。该项目核心专利本体包括: 专利元数据本体(Patent Metadata Ontology)、专利结构本体(Patent Structure Ontology)、专利内容本体(Patent Content Ontology)与专利图例本体(Patent Drawings Ontology)[ 6, 7]。PATExpert定义的核心专利本体已成为其他类似研究的事实参考标准。此外, 还有一些针对特定应用的专利本体研究, 如: IBM印度研究院利用本体对生物医药类专利建模, 实现基于生物医药术语与关系的语义检索[ 8]; Ghoula等对专利进行基于本体的语义标注, 为专利知识检索与推理提供数据支持[ 9]; 姜彩红等利用本体对中文专利进行知识抽取, 为构建专利知识库提供基础语料[ 10]。
该方法涉及的关键技术是本体映射与合并, 即: 如何准确、自动地将特定专利映射到标准化专利本体中。其优点是可多层次, 多角度地揭示专利语义信息。但缺点也显而易见: 构建专利本体需要大量专家参与, 费时费力, 不能满足敏捷场景下技术挖掘需求。
(2) 基于向量空间模型专利知识表示
向量空间模型(Vector Space Model, VSM)是一种经典的文本表示模型, 它凭借简单易懂的表示过程, 众多成熟的算法工具, 在文本表示中得到了广泛的应用。VSM核心思想是将各种信息对象作为向量空间元素进行建模, 如: 文档、技术、概念、术语、检索等都表示成向量空间的向量。最简单的VSM是将专利文档直接表示成关键词权重向量。这种方法借鉴已有文本表示技术, 成熟易用, 在专利技术挖掘中得到广泛的应用, 如: Yoon等研究以关键词向量为基础, 绘制专利技术关联图[ 11]。Lee等用关键词向量表示产品资料、科技论文和专利文献, 通过分析关键词在三种文献中的分布, 制作基于关键词的技术路线图[ 12]。Kim等研究了基于关键词向量的专利聚类及可视化方法, 用于新兴技术的预测[ 13]。
该方法涉及的关键技术是关键词向量降维, 即: 如何在准确完整地反映专利技术信息的前提下, 减少向量空间维度。其优点是简单易用。但由于关键词通常是名词或名词词组, 相互之间缺乏语义关系, 难以揭示专利深层次技术信息, 不能适用于微观层面的专利技术挖掘。
(3) 包含语义信息的向量空间专利知识表示
鉴于VSM专利知识表示的不足, 研究人员探讨利用三元组(Subject-Action-Object, SAO)来表示专利。它本质上依旧是一种VSM, 但专利不再简单表示成关键词向量, 而是表示成内部具有一定语义关系的SAO向量。
早期, 基于SAO语义知识表示技术出于生物信息学研究的需要。生物学家希望能从大量的生物医学文献中挖掘出蛋白质与基因间的相互作用, 从而发现基因的特定功能[ 14, 15, 16, 17, 18, 19]。鉴于SAO语义表示技术在生物信息学领域的巨大成功, 美国国家医学图书馆整合相关资源, 启动了面向生物医学领域的语义知识表示项目(Semantic Knowledge Representation, SKR)。SKR以一体化医学语言系统(UMLS)为基础, 结合专家知识库系统, 从海量生物医学文献中自动抽取SAO结构, 实现生物医学文献的语义表示[ 20]。该方法很快被移植到专利上来, 如: Gaetano等利用自然语言处理技术从专利中抽取SAO结构用于技术功效分析, 以此为基础开发了PAT-Analyzer系统[ 21, 22, 23]。 Invent Machine公司的语义TRIZ软件GoldFire中集成了SAO抽取功能, 并能自动将其分为4种类型[ 24, 25]: 组成(Made up of)、所属(Part of)、功效(Function)、相互作用(Interaction)。
研究人员结合专利文本特征, 进行了进一步研究, 如: Sheremetyeva根据美国专利权利要求语言表述特点, 利用谓语词典, 将具有同义Action的SAO进行归并, 有效降低了SAO维度[ 26]。Yang等将专利权利要求合并成效用(Utility)、功能(Functionality)、拥有(Contain)等8种语义类型, 大大降低了SAO维度[ 27]。在此基础上, 他们利用依存树将专利权利要求表示成基于SAO的语义概念图, 建立起SAO之间的语义关系[ 28]。Choi等基于相似性对SAO进行分类, 构建技术分类树[ 29]。Choi等在韩国国家自然科学基金的资助下进一步研究基于WordNet及专利功效分类的SAO本体构建, 实现了面向功效的专利检索[ 30]。Kim等参照TRIZ中技术矛盾与发明原则将专利技术表示为技术难题与解决方案(Problems & Solutions, P&S), 并从词法-句法角度研究P&S表达模式[ 31]。Hu等利用主题模型(Topic Model)进行SAO降维, 在此基础上实现了面向P&S的专利知识表示[ 32]。
该方法涉及的关键技术是SAO降维与知识重新表示。其优点是不需要像本体工程那样设计复杂语义知识模型, 语义映射较本体简单快捷; 相对关键词向量, 具有较丰富的语义表示能力。但现有研究大多没有考虑专利特有技术特征, 难以对SAO内部元素间语义关系进行深入挖掘。
(4) 小 结
总之, 基于本体工程专利知识表示需要大量专家参与, 费时费力; 基于VSM专利知识表示则因关键词之间缺乏语义关系, 难以应用于深层次技术挖掘。包含语义信息的向量空间专利知识表示则兼具两者优点, 成为研究与应用的主流与热点。三类专利知识表示模型比较如表1所示:
| 表1 三类专利知识表示模型比较 |
专利技术挖掘范畴很广, 本文选取技术主题聚类、专利自动分类与专利技术演化三类典型场景作为代表, 分析其研究进展。
(1) 技术主题聚类
专利技术挖掘中, 很少对专利本身进行聚类, 多是对包含的技术主题进行聚类。根据聚类目的不同, 可分为揭示技术主题分布、基于技术主题聚类的应用、研究技术主题之间的关系三类。
揭示技术主题分布是专利技术聚类最根本, 也是最常见的应用。通常采用数据挖掘领域的一些成熟算法, 如: K-means聚类、层次累积聚类、多维尺度分析与自组织映射等对专利技术主题进行聚类。Tseng等对专利分析中主题聚类进行了系统研究, 归纳出流程如下: 关键词的选取、权重计算、相似度计算、聚类算法的选择、多步骤聚类、生成聚类簇标签、对聚类结果进一步分组等[ 33]。
基于技术主题聚类的应用则是将技术主题聚类作为其他应用的中间结果, 如: Kang等利用技术主题聚类结果来提升专利检索性能[ 34]。
研究技术主题之间的关系属于对聚类结果的进一步挖掘与分析, 是目前专利聚类研究的重点。如: Kim等在关键词聚类的基础上, 计算关键词在不同聚类簇之间的数量分布, 结合专利申请时间, 分析出代表新兴技术的关键词[ 13]; Wang等分析连接不同聚类簇特征关键词, 将其作为技术过渡特征词予以研究[ 35]; Yoon等结合多维尺度分析与离群点探测寻找独特的专利, 认为这些专利有可能反映最新技术趋势[ 36]。
目前研究大多用关键词来表示技术主题, 研究重点集中在技术主题术语收敛(Term Clumping)与技术主题间相似度计算。前者可使发散的关键词术语按照指定的规则收敛, 为聚类提供高质量的基础数据; 后者则为复杂聚类及聚类后处理提供数据支持。
(2) 专利自动分类
专利分类既是组织管理专利的一种手段, 也是技术挖掘的重要应用领域。根据分类体系不同, 目前研究分为三类: 基于分类号自动分类、基于个性化分类体系自动分类、面向TRIZ自动分类。
分类号是专利领域最权威, 应用最广泛的分类体系。目前, 相关研究集中在如何建立更完善、统一的分类号体系, 如: 欧洲专利局和美国专利商标局在2010年达成协议, 在国际专利分类系统(International Patent Classification, IPC)基础上共同合作, 创建并实施统一的联合专利分类系统(Cooperative Patent Classification, CPC)[ 37]。针对专利分类号系统层次结构复杂的特点, 优化与改进分类算法也是一个关注热点。如: Fall等基于IPC分类体系, 比较朴素贝叶斯、支持向量机与K-NN三种分类算法的效果, 通过优化训练集来提高一个专利分配多个分类号的准确率[ 38]。刘玉琴等基于IPC层次结构, 针对不同层次类别建立特征向量, 从而在各层次上实现专利自动分类[ 39]。Krier等基于欧洲专利分类系统进行专利自动分类, 以便将相关专利申请分配给技术背景接近的审查员[ 40]。
专利分类号系统对技术描述过于宽泛, 难以满足特定目的技术挖掘需求。因此, 基于个性化分类体系的专利自动分类成为研究重点, 如: Falasco基于美国专利分类系统, 实现根据产品功能与效果将专利进行再次分类[ 41]。Teichert等研究了基于专利的5个功能类别进行专利自动分类的方法[ 42]。Lai等在IPC基础上, 提出了应用于企业研发技术定位的专利分类方法[ 43]。Hu等结合术语收敛与主题模型, 研究自动构建个性化的专利技术知识组织体系[ 44]。郭炜强等将IPC作为领域知识, 从专利文本中抽取特征关键词进行专利自动分类研究[ 45]。Kim等对专利文档知识结构进行了重新组织, 将其分为技术领域(Technogical Field)、目的(Purpose)、方法(Method)、权利要求(Claim)、解释(Explanation)、实例(Example)等6个部分, 并在此基础上对专利进行分类[ 46]。
面向TRIZ自动分类则是依据TRIZ中发明原理或技术难题进行分类, 目的是帮助用户寻找利用了相似的发明原理或者解决了相似技术难题的专利。这些专利在技术领域上可能相差很远, 分布在不同的分类号体系中[ 47]。Loh等对TRIZ 40条发明原理进行专利自动分类, 包括: 选取其中6条发明原理, 利用多种分类算法进行的小规模专利自动分类[ 48]; 分析40条发明原理之间的相似性, 对其进行重新分组[ 49]; 通过分析发明原理的专利句法信息, 归纳出相应的句法与语法模式, 基于关联规则进行面向发明原理的分类[ 50]。国内近两年也有类似的研究, 如: 梁艳红等进一步将发明原理归纳为显性发明原理与隐性发明原理两大类, 并实现了面向显性发明原理的专利自动分类[ 51]。翟继强等结合中文自然语言处理技术, 实现中文专利面向发明原理的自动分类[ 52]。
分类体系是自动分类的基础与前提。目前, 专利自动分类研究重点是构建个性化分类体系。面向个性化分类体系的专利分类中, 数据分布往往不平衡, 如果直接利用传统分类器进行分类, 准确率普遍较低[ 32]。非平衡数据集分类问题是专利自动分类中技术难点与关键点。
(3) 专利技术演化
技术演化分析技术主题产生、发展、突破创新、转移和变化乃至湮灭的过程, 是专利技术挖掘的重要内容之一。技术演化研究方法包括: 引文分析法、文本挖掘法、TRIZ演化模型法、德尔菲法等。其中文本挖掘法、TRIZ演化模型法常用于专利技术演化分析。
根据技术表示粒度不同, 可将文本挖掘法分为基于关键词与SAO两种。基于关键词的技术演化分析主要集中在中观或宏观层面, 如: Yoon等基于专利关键词共词分析和形态学分析, 绘制移动电话领域技术演化路线图[ 53, 54]。Lee等通过构建专利关键词演化地图, 发现新的技术机会[ 55]。方曙等研究关键词聚类簇分布随时间变化关系, 以此为基础发现新兴技术与基础技术[ 56]。
基于SAO分析专利技术演化是近几年出现的研究热点, 常与TRIZ技术系统8大进化法则[ 57]、9窗口演化模型[ 58]结合起来进行微观层面技术演化分析, 如: Yoon等系统结合SAO与离散点探测分析技术演化趋势, 从而识别新兴技术集群[ 36, 59, 60]。Park等将SAO与TRIZ进化法则结合起来, 分析技术演化进程, 筛选领域重要专利[ 61, 62]。Zhang等基于GoldFire提供的语义TRIZ数据, 结合术语收敛与技术路线图, 发现与定位潜在新兴技术[ 63, 64]。
基于关键词的技术演化分析相对成熟。基于SAO的技术演化分析是目前研究重点与热点, 涉及的关键技术包括: 基于SAO对技术进行语义表示、构建演化模型。
(4) 小 结
目前, 技术主题聚类基础是关键词; 专利自动分类基础是分类号、关键词; 专利技术演化分析的基础则是关键词与SAO基础语义单元。三种专利技术挖掘场景研究现状如表2所示:
| 表2 三种专利技术挖掘场景研究现状 |
专利文本技术挖掘的关键技术是专利文本知识表示, 包含语义信息的向量空间专利知识表示是目前研究重点; 典型场景包括: 技术主题聚类、专利自动分类、专利技术演化等。专利知识表示的粒度与结构决定了各场景技术挖掘的深度、广度与维度。P&S是专利技术的核心概念, 专利知识表示能否准确揭示P&S信息, 对专利技术挖掘成果优劣至关重要。现有研究总结如表3所示:
| 表3 专利文本技术挖掘总结 |
总之, 现有研究大都基于向量空间模型, 在关键词或SAO层面对数据量较小专利集进行技术挖掘。Topic Model是一系列基于概率模型, 旨在发现大规模文档中隐含主题结构方法的统称[ 65]。与向量空间模型相比, Topic Model在复杂知识表示、处理大数据量文本方面具有优势, 如: 潜在狄利克雷分配模型(Latent Dirichlet Allocation, LDA)可将海量科技文献表示成一系列主题的概率分布, 主题表示成一系列关键词的概率分布[ 66]。相对于直接将文献表示成关键词或SAO向量, LDA生成了新的技术特征(主题或P&S), 更能揭示文献深层次知识结构。基于概率主题模型, 面向P&S的专利技术挖掘将能深化专利技术挖掘程度, 拓展专利技术挖掘范围, 更新专利技术挖掘视角, 有望成为未来的发展趋势与研究热点。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|