{kind=link}
{kind=link}
中文短信文本信息流中多话题的分类抽取*
[张永军, 刘金岭 , 马甲林]
, 马甲林]
, 马甲林]
|
|


作者贡献声明:
张永军: 设计研究方案; 论文起草; 编程并进行实验;
刘金岭: 提出研究思路, 论文最终版本修订;
马甲林: 采集、清洗和分析数据。
【目的】为更有效地在中文短信文本信息流(SMS Text Message Flow, SM_F)中进行多话题的分类提取, 提出一种基于SM_F特点的话题分类抽取方法SM_F_HT。【方法】将SM_F分割成多个短信文本子集SM_Fi, 通过层次的狄利克雷过程信息抽取与TF-IDF相结合, 建立短信文本向量集上多个概率分布, 采用吉布斯抽样并结合特征词属于临时话题的概率进行SM_F话题分类抽取。【结果】实验结果表明, SM_F_HT在困惑度和对数似然比方面优越于模型CCLDA和CCMix。【局限】在短信文本预处理和特征词的抽取方面, 还需进一步优化算法和提高数据质量。【结论】提出的SM_F_HT方法对SM_F的多话题分类抽取是有效的。
[Objective] A topic classification extraction model named SM_F_HT is proposed to find multiple topics more effectively in Chinese SMS text message Flow (SM_F). [Methods] In this model, SM_F is divided into SMS text subsets TF-IDF combined with the hierarchical Dirichlet processes of information extraction are used to build multiple probability distributions of the SMS text vector set. Finally topic classification on SM_F is extracted using Gibbs sampling in conjunction with the probability of the characteristic words which belong to local topic. [Results] Experimental results show that SM_F_HT is superior to CCLDA and CCMix models in perplexity and log likelihood ratio. [Limitations] In fields of SMS text preprocessing and keyword extraction, this algorithm still needs further optimization. [Conclusions] The SM_F_HT scheme is effective for multiple topics classification extraction of SM_F.
手机短信在人们的生活中扮演着越来越重要的角色, 手机短信传播也被冠以“拇指文化”、“拇指文明”和“第五媒体”等美誉, 发展成为一种时代潮流。中文短信文本一般每条字符数都不超过140, 在传递公开信息同时携带了丰富且具有极大价值的信息资源。面对海量中文短信文本动态信息, 利用计算机高速的计算能力, 自动从中文短信文本信息流中识别、锁定和收集突发性新闻话题、识别新话题以及跟踪话题发展趋势等相关任务, 有着重要的社会意义, 可广泛用于信息安全、舆情分析和预警等领域。中文短信文本信息流多话题抽取是根据话题主题, 将中文短信文本信息流中的每一个中文短信文本抽取到话题簇中。中文短信文本信息流具有以下特点[ 1]:
(1) 信息长度短、信息量少, 以词为维度的向量空间模型呈现出高维稀疏的特点。
(2) 手机短信文本夜间发送的较少, 尤其在夜间0:00-3:00点按发送数量呈“谷底”状态。
(3) 对重要话题、突发话题或舆情信息一般收到信息后或修改少量内容或不修改内容(绝大多数都不修改内容)就马上进行传播, 因此表达同一话题的短信文本集中会出现大量重复的特征词。
(4) 当一个新话题或突发话题发生时, 流行词语随着话题不断变化而变化, 并不断有新词出现, 呈现出动态性特点。
(5) 按时间顺序组织的文本信息流更便于内容管理和进一步挖掘, 此时, 在中文短信文本信息流中不同话题的中文短信文本随时间变化而交错出现, 即使相邻的中文短信文本也可能隶属于不同的话题。
随着TDT (Topic Detection and Tracking)项目[ 2] 研究的不断发展, 国内外关于话题发现的相应研究成果逐渐丰富起来。对于短文本信息流的研究, 蔡淑琴等[ 3]提出从微博文本中抽取热点词汇作为元数据, 将这些元数据作为短文本聚类的中心以降低聚类复杂度, 该方法将微博内容看作短文本的形式进行热点话题发现, 其方法停留在利用和改进文本热点话题发现的方法上, 没有利用到微博自身的时序等特点; 马斌等[ 4]融合了微博时序特点, 并将某一时域的微博整合成一个短文本集合, 利用线索树进行长期话题检测。以上研究只是面对单一文本集的, 不适合多文本集中的话题抽取。本文根据中文短信文本信息流的时序特性, 先将中文短信文本信息流分成若干个子文本集, 在子文本集中既有各自的话题, 又有公共话题。类似的研究有Hoffman[ 5]所提出的概率潜在语义分析方法PLSA (Probabilistic Latent Semantic Analysis), 把文本与词之间的语义关联表示为概率, 这样可以将文本映射到低维的语义空间以揭示文本与词的统计特征, 大大减轻了分析海量文本的负担, 但无法处理训练集中未出现的文本和词, 参数也随文本数量的增多呈线性增长。Zhai等[ 6]和Yin等[ 7]提出一种跨文本的混合模型CCMix(Cross-Collection Mixture Model), 讨论了不同文本集之间的共同话题及共同话题在各文本集中的异同之处, 该模型是基于PLSA方法的, 但要比PLSA方法简单, 也易于实现, 类似于PLSA, 它也具有参数随文本数量的增多呈线性增长的不足。赵华等[ 8]针对新闻报道的特点, 通过内容分析法将话题表示为标识中心向量和内容中心向量, 解决包含相同核心内容的两个话题难以区分的问题, 但是内容分析法需要额外词典的支持, 增加了大量的人工维护工作。Paul等[ 9, 10]提出了跨文本集模型CCLDA(Cross Collection LAD), 该模型是一种基于LDA(Latent Dirichlet Allocation)模型[ 11]的分类方法, 它假设一个话题与公共特征信息和具体子集特征信息分布相关联, 体现了话题在各个文本集上的差异。这些方法在一定程度上解决了多个文本集中话题抽取问题, 但是只能对相似度较高的文本集之间的相同话题进行抽取, 对于各文本集中存在的特有话题无法解决。何建民等[ 12]提出了一种基于类熵距离测量的热点话题识别方法, 该方法对社区网络采取了一种层次建模, 社区网络共分话题、事件及事件成员三层, 以事件成员的数目、事件成员比例和事件与话题的相似度作为话题的特征进行多话题提取, 但该方法不能把所抽取的话题进行分类。本文借助TF-IDF思想, 利用狄利克雷信息检索模型把短文本信息流的话题分为长期话题和临时话题, 通过建立一个概率模型来完成多个短信文本子集的话题分析, 进而达到对短文本信息流话题的分类抽取。
根据短信发送和接收的特点, 一个话题经过夜间(如0:00-3:00点)的短信文本传播量处于谷底状态, 本文将该时间区域定义为子集的边界。一个文本集中传播的话题为临时话题, 多个文本集中传播的话题为长期话题。
假设短信文本信息流采用文献[13]的方法进行分词、词义消歧、去除停用词及连词、代词等并经过降维预处理后, 转化的特征向量形式SM_F={(Wi1,ti1; Wi2,ti2;…, Wim,tim)| i=1,2,…,n}。其中Wij是短信文本的特征词, tij是Wij的权值。
定义1: 将短信文本信息流SM_F分割成若干子向量集:
SM_F={SM_F1,SM_F2,…,SM_Ft}
对于话题HT={SM1,SM2,…,SMr} 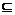
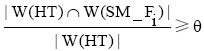
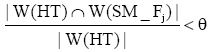
根据话题发生的规律, 描述话题的特征词可能在某时间段内叙事基本相同的大量短信文本中出现, 而在其他时间段出现的类似短信文本较少。同时也说明当一个特征词在某个SM_Fi中出现的多而在其他SM_Fj(j≠i)很少出现时, 说明这个特征词属于临时话题的概率高, 与TF-IDF的思想相吻合。给出如下定义:
定义2: 设短信文本信息流SM_F和临时话题L_HT, 特征词W∈SM_F, nW,SM表示特征词W在短信文本SM中出现的次数, mSM,W表示包含特征词W的短信文本总数, tSM表示SM_F中所包含的全部短信文本总数, 则特征词W属于L_HT的概率pW定义为:
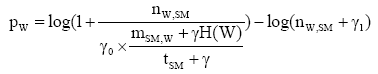 | (1) |
其中, 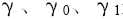
定义2的意义在于 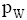
定义2只考虑短信文本的特征词属于临时话题的概率, 但没有考虑特征词对短信文本的影响, 也就是说, 当某短信文本中有多个特征词属于临时话题, 则其他词属于该临时话题的概率就比较大。
定义3: 设SM∈SM_F, nW,SM表示特征词W在短信文本SM中出现的次数, SMTOP表示文本集中 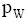
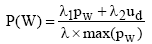 | (2) |
其中, 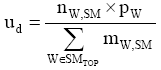
定义3中的ud表示当短信文本中属于SMTOP的词 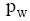
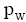
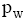
本文短信文本信息流多话题抽取算法的主要思想分为两部分, 先是利用层次的狄利克雷过程和TF-IDF相结合, 生成较为准确的短信文本信息流相关的多项式概率分布模型, 对于短信文本中的一个特征词, 利用吉布斯采样[ 14]和定义3, 抽取出临时话题和长期话题。为了便于叙述, 该算法简记为SM_F_HT, 步骤如下:
(1) 对于短信文本信息流SM_F, 利用前文子集边界确定方法将SM_F分割成若干子向量集:
SM_F={SM_Fi| i=1,2,…,t}
因此有, 存在i, 使得L_HT 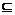
(2) 根据文献[6]和[7], 对每一个话题HT和子向量集SM_Fi, 可以获得HT与SM_F有关的Beta分布 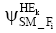
①短信息文本SMij属于长期话题分布向量 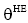
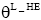
②对于每个长期话题G_HT, 可以得到一个与子向量集无关的多项式分布 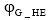
③对于每个长期话题G_HT, 可以得到一个与子向量集相关的多项式分布 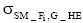
④对于每个临时话题L_HT, 可以得到其多项式分布 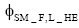
(3) 在特征词的狄利克雷分布中任取Wij∈SMi 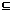
①如果HT是长期话题, 并且可以根据 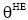
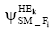
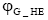
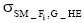
②如果HT是临时话题, 根据 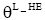
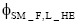
(4) 利用文献[15], 将抽取出的各个临时和长期话题特征词集构造成话题输出。
该算法先是在步骤(2)中把按夜间边界区分的各短信文本向量子集合并为一个大文本向量集, 对于临时话题、长期话题、短信文本集利用狄利克雷分布进行各随机测度的分层建模, 再利用大文本向量集的所有词的测度、短信文本向量子集的所有词的离散概率测度和每个短信文本向量的所有词的离散概率测度并结合公式(2)对SM_F建立一个非参数化的信息检索模型, 最后通过吉布斯采样得到特征词所涉及的话题个数, 根据采样的结果, 利用定义3, 就可以确定特征词属于临时话题的概率。
实验数据是从江苏某短信运营商2012年2月1日0点整到4月30日24点0分时间段中挑选了近10万多条手机短信文本集合进行人工标注, 经过去重、消歧和降维等预处理后得到18 000条手机短信文本。标注了较为热点的如载有化学品的船在江阴段沉船、江苏沿江部分城市出现市民抢购矿泉水、元宵节祝福等100个话题。
困惑度(Perplexity)是当前最常用的度量文本模型性能好坏的评测标准, 它是利用当前训练结果来预测未来文本的能力。困惑度越低, 语言模型对上下文的约束能力就越强, 所表示模型对未知的短信息文本预测能力越强。困惑度的计算公式为[ 16]:
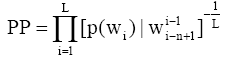 | (3) |
其中, L为测试语料总特征词序列的长度, n是模型的阶数(如n=2时称为Bi-gram)。 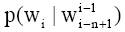
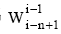
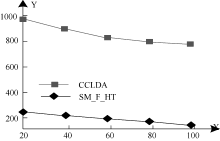
对SM_F_HT模型与CCLDA模型进行了话题抽取的困惑度比较, 实验选取30%的短信文本作为测试文本, 两个模型都进行了2 000次迭代。用X轴表示热点话题的数目, 用Y轴表示困惑度, 则实验结果如图1所示:
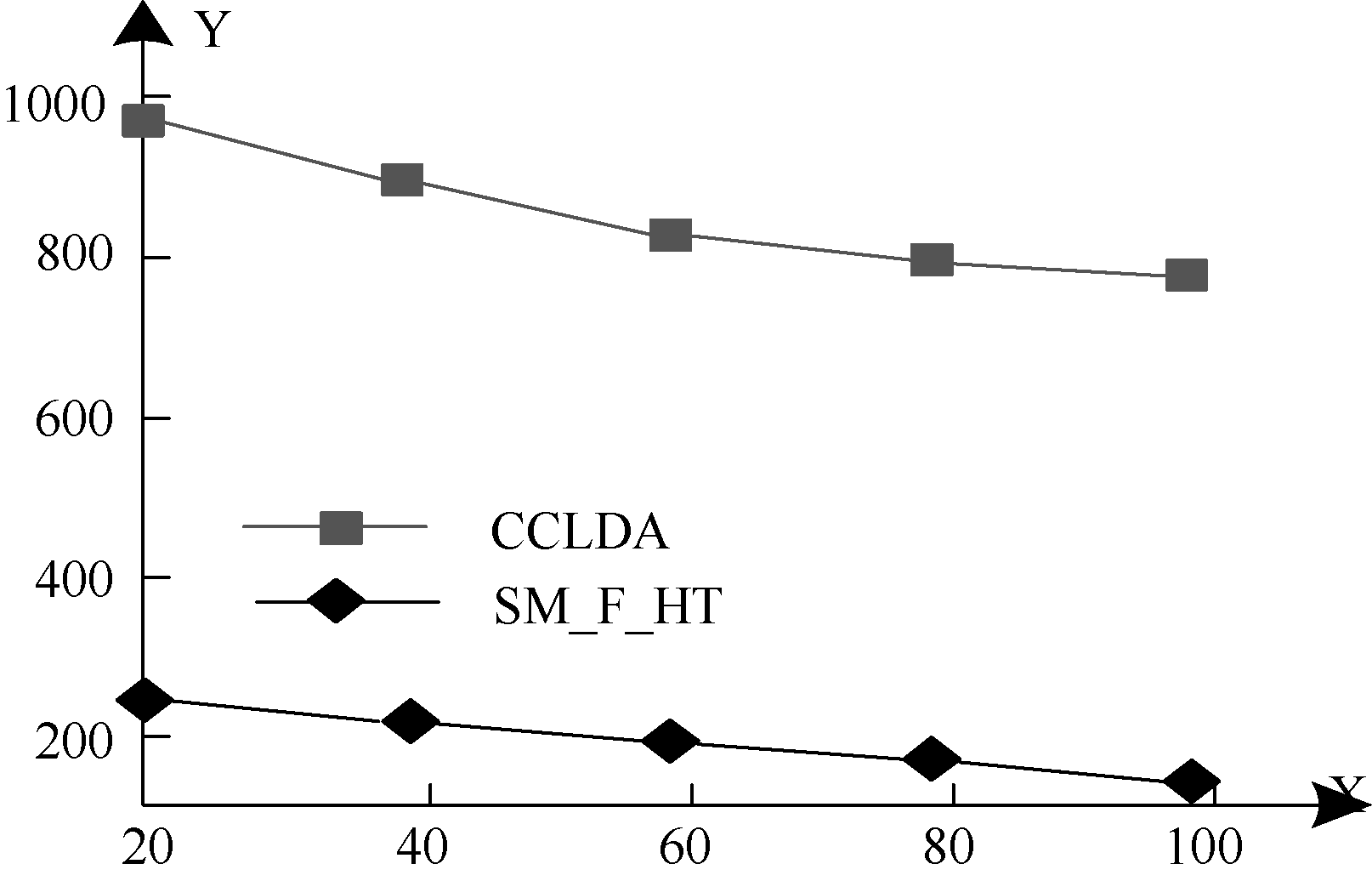 | 图1 话题抽取的困惑度比较 |
从实验结果可以看出, SM_F_HT模型比CCLDA模型进行话题抽取时困惑度小得多, 这是因为SM_F_HT算法更适用于短信文本信息流的话题抽取, 对上下文的约束能力更强。实验中还可以看出困惑度随着话题数量增加而下降, 这是因为话题越多, 降维损失的信息就越少, 而且降维的结果也符合短信文本集的特征。但是如果话题很多, 短信文本信息流的特征词空间维数就越高, 则降维的意义不大, 因此话题的数量不是越多越好, 笔者经过多次实验, 一般在50-80个话题较为合适。
对数似然比(Log-Likelihood Ratio, LLR)是通过独立性假设来检验两个元素出现的相关程度, 它引入Log 似然比统计量, 能够较准确地反映两个元素的相关性, 将其应用到机器学习中, 克服了典型的学习方法对低频词估计不准确的缺点, 保证了计算结果的稳定性。本文利用文献[17]中给出的对数似然比来比较模型SM_F_HT、CCLDA和CCMix的话题抽取性能, 根据短信文本信息流中话题检测的特点, 特征词抽取测试指标包括频度、集中度和分散度等多项统计测试指标。
假设对于话题HTj, 特征词Wi的多项统计测试指标向量为αij, 有:
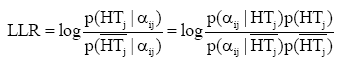 | (4) |
其中, LLR是特征词Wi对于话题HTj的对数似然比, 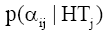
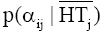
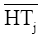
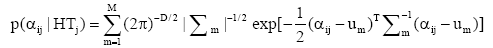 | (5) |
M是符合次数, um是第m次符合的均值向量, 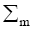
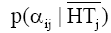
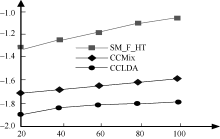
为了实验简单, 本文αij只取频度、集中度和分散度, 而且相应阈值分别取0.9, 0.6和0.6, 取D=3。X轴表示热点事件数目, Y轴表示似然相似度除以100 000, 则实验结果如图2所示:
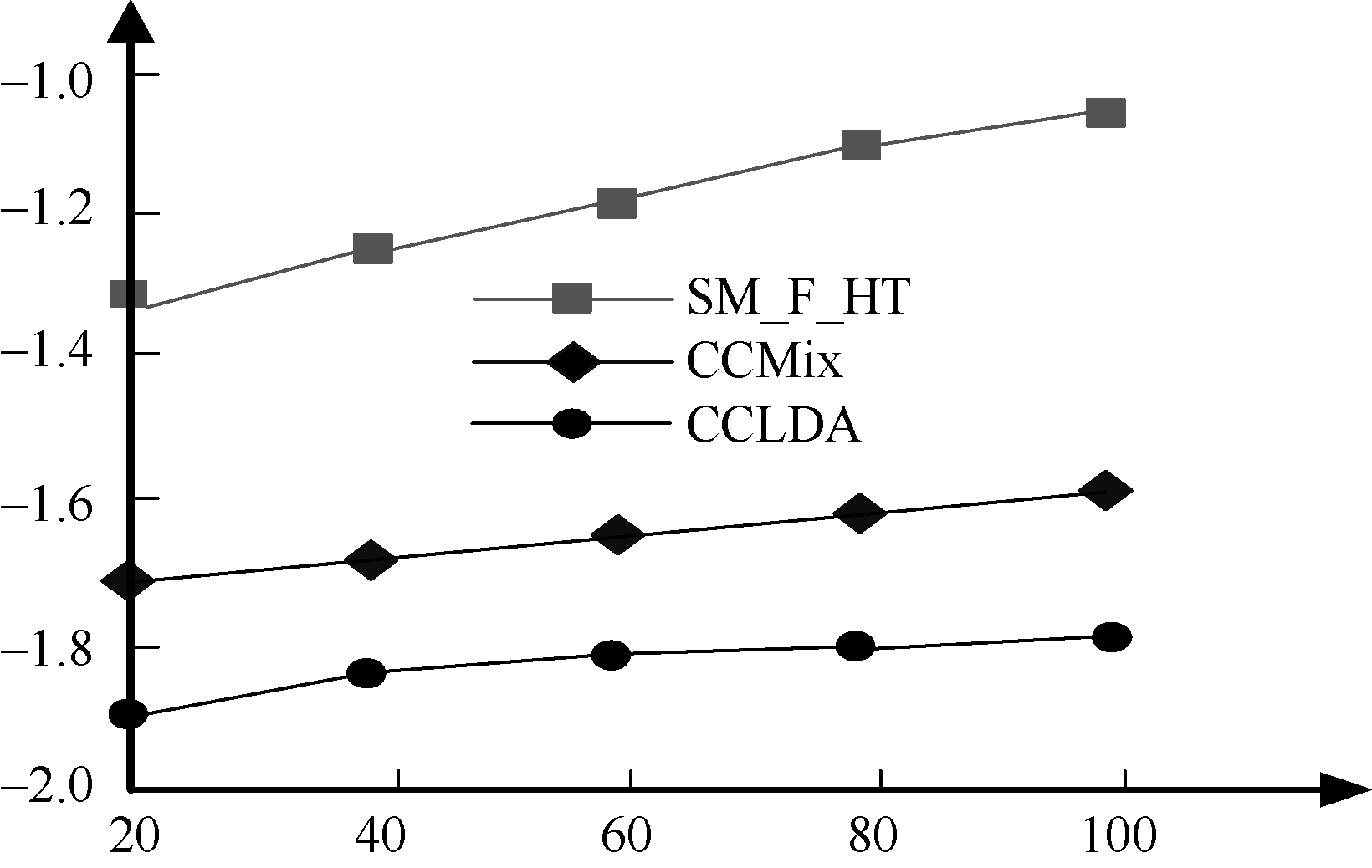 | 图2 三种模型的对数似然值比较 |
从图2可以看出, 与CCMix和CCLDA模型相比, SM_F_HT对数似然比值要大得多, 说明它的区分能力较强, 更容易判断特征词的话题特性。这是因为SM_F_HT比其他两个模型更能全面地利用短信文本信息流的特点, 由于考虑到临时话题, 因此SM_F_HT模型更具有灵活性。
根据短信文本信息流SM_F表现话题的特点, 本文先利用短信文本夜间流量少的特点确定短文本信息流的子集边界, 将SM_F分割成若干个短信文本子集, 通过层次的狄利克雷过程信息抽取与TF-IDF相结合建立了短信文本集特征词属于临时话题的概率分布, 并采用吉布斯抽样确定话题个数, 再结合定义3把SM_F的话题进行分类, 实验结果证明了对于中文短信文本信息流SM_F_HT可以较好地抽取热点话题, 并能够进行有效的分类。下一步工作的重点是有效地提高抽取事件特征词及特征词之间关系的质量。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|