{kind=link}
{kind=link}
{kind=link}
用户主导下的专家检索可信度评测机制研究*
[李纲, 叶光辉 ]
]
]
|
|


【目的】为降低专家检索过程中的噪声并提升用户满意度, 提出构建用户主导下的专家检索可信度评测机制。【方法】在BIR模型基础上, 阐述评测机制运行需要遵循的原则和假设, 围绕专家特征设置参数, 依次设计前后端可信度评测机制。【结果】以学术专家检索为例, 说明后端可信度评测通过求解最佳专家特征向量目长来降低检索噪声, 前端可信度评测将用户相关性反馈作为检索路径选择的必要参照。【局限】前端可信度评测不适用于用户提问较长的情形; 后端可信度评测对专家信息组织方式要求高。【结论】综合两种可信度评测机制, 该机制可提升专家检索关联资源的广度和用户参与的深度。
[Objective] In order to reduce the noise and enhance customers’ satisfaction in expert retrieval system, the authors put forward the idea of credibility evaluation mechanism under user’s control. [Methods] Firstly, based on the binary independence retrieval model, this paper brings out the principles and assumptions that the design of evaluation mechanism needs to follow. Secondly, fousing on expert feature to define parameter, this paper has respectively designed the front-end credibility evaluation mechanism and the back-end credibility evaluation mechanism. [Results] Setting academic experts retrieval for example, the authors point out that the front-end mechanism corresponding to information organization attempts to reduce the noise in the expert feature recognition via finding the best length of expert eigenvector, while the back-end mechanism deeply integrates users into the retrieval by setting user relevant feedback as the necessary reference of path selection. [Limitations] The front-end mechanism can not deal with user query including more words, and the back-end mechanism has higher requirement of expert information organization. [Conclusions] Making combination with two mechanisms, this new mechanism can expand associated resources for expert feature recognition and upgrade user involvement.
专家是拥有专门知识和技能, 并能推动知识经济发展的重要群体。通常来讲, 专家多指来自高等院校、科研院所、企业等机构的研究人员。但在互联网时代, 专家的外延正不断被拓展, 科研社区(科学网、小木虫等)、技术社区(CSDN等)[ 1]及QA系统[ 2]中的中心节点也逐渐成为该网络内的专家。网络专家不同于机构专家, 他们属于小众专家。随着机构专家对网络沟通方式的适应, 机构专家和网络小众专家的交集越来越多。因此, 现阶段, 单一根据学术知识库资源来对专家进行特征识别是不完善的, 还需要综合社会网络资源、Web资源来提取专家特征[ 3, 4]。
为了更好地利用专家资源, 不少专家学者都在积极构建科技咨询系统[ 5, 6]、专家检索系统[ 7, 8]、基于本体的专家定位系统[ 9]、FacFinder专家搜索引擎[ 10]、SmallBlue专家搜索软件[ 11, 12]等。检索系统已成为定位和利用专家资源的重要途径, 目前国内三大学术数据库(CNKI、万方和维普)都提供有学者或专家检索入口, 但数据量并不大。截至2013年10月25日, 万方共收录专家11 183位, 且专家信息组织偏重外部特征, 对内容特征的揭示不深。除此之外, 专家检索还存在以下问题:
(1) 综合多渠道信息资源提取的专家特征, 在实现专家信息完备的同时也造成了较大的信息噪声和冲突[ 4]。因此在源头强化专家信息组织方法和技术的同时, 也要在终端引入用户评测机制。
(2) 专家检索存在多种ExpertRank[ 13]算法, 但这些算法只是将用户作为接收检索结果的客体, 没有为用户设置参与算法执行的变量, 用户自主检索功能不强, 更无从谈及个性化专家检索。
基于上述问题获取的检索结果可信度有多高?其大小可作为结果相关度判断的标准之一, 为用户接受或拒绝检索信息提供参考[ 14, 15]。如果将专家检索理解为是对信源实施的可信度评估, 则在专家排名[ 4]、群体决策[ 16, 17]、同行评议[ 18, 19]等咨询活动中, 围绕专家意见或观点所应用的方法、模型、算法、系统等可划定为是对信息内容所做的可信度评估, 目前该领域国内外研究也多围绕此展开。作为序贯相联的过程, 信源可信度评估是后续评估的基础, 对此, 笔者进行了有益的探讨, 希望通过相关可信度评测机制的设计来改进专家检索过程, 提升用户参与度。
本文阐述的可信度评测机制包括两部分: 前端可信度评测机制, 对应专家检索过程; 后端可信度评测机制, 对应专家信息组织过程。这两部分有机配合, 共同提升着检索结果的可信度。为了最大程度上解决以往专家检索中出现的信息噪声、用户参与度不高等问题, 同时保证前后端可信度评测机制设计的一致性, 有若干设计原则和研究假设需要共同遵循。
(1) 用户自定义原则
自定义使得用户可以根据自身要求来对检索结果进行准确调整。它建立在多次检索反馈基础之上, 用户对检索结果做出相关性评价, 评价结果将通过一组参数来定量化描述, 这组参数将影响下一次检索算法执行时的路径选择。用户自定义原则是可信度评测机制设计的前提和基础。
(2) 收敛原则
一般情况下, 用户找到合适专家即完成当前检索, 但这一过程可能要经历多次反馈。为了避免由于数据库中专家信息不详、缺失等原因所造成的死循环, 当连续多次检索结果趋于一致时, 则确认检索结果趋于收敛。因此, 从某种意义上讲, 收敛是用户能够参与到检索过程中的极限。
可信度评测机制吸收了基于二值独立概率检索模型(BIM)的思想[ 20], 以概率论为数学理论基础, 包括若干前提假设:
(1) 标引词独立性假设
专家信息组织过程可描述为: 识别与专家相关的资源, 并通过一定方法和技术手段提取专家特征词, 构建专家特征向量。在之前研究[ 21, 22]中, 笔者分别论述了基于学术资源的专家特征识别方法、基于社会网络资源的专家特征识别方法、基于Web资源的专家特征识别方法和综合多种资源的专家特征识别方法, 这4种方法几乎涵盖了获取专家特征的所有途径。无论专家检索系统采用哪一种特征识别方法, 专家特征向量都统一采用二值处理, 即某词在专家特征向量出现则为1, 反之则为0, 这种处理方式即建立在标引词独立性假设之上。
(2) 索引词独立性假设
根据用户类型, 检索提问可分为自然语言检索和专业检索。一般用户使用自然语言表达自身需求, 提交检索后系统会采用基于向量空间模型的方法, 统计词频, 获得用户提问向量。专业用户则直接使用布尔逻辑运算符和关键词来组织检索式, 提交检索后系统通过真值表法[ 23]将检索式解析为用户提问向量。无论是哪一种方式获取的用户提问向量, 都要遵循索引词独立性假设, 采取二值处理方式。
(1) 专家信息组织过程
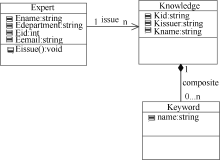
后端可信度评测机制同专家信息组织方法密不可分, 在此笔者采用基于学术资源的特征识别方法来组织专家信息。该方法中专家特征向量设计相对复杂, 主要依托专家发布的学术资源。专家和学术资源具有一对多的发布(issue)关系, 关键词是组成(composite)学术资源的一部分, 笔者采用类图描述了三个实体和两组关系, 如图1所示。专家和学术资源都存在外部特征维度和内容维度。专家的外部特征维度采用四元组<Eid,Ename,Edepartment,Eemail>来描述, 学术资源的外部特征维度使用三元组<Kid,Kname,Kissuer>来描述, Eid和Kid作为主键唯一标识每一条记录, Kissuer和Ename存在着对应关系。
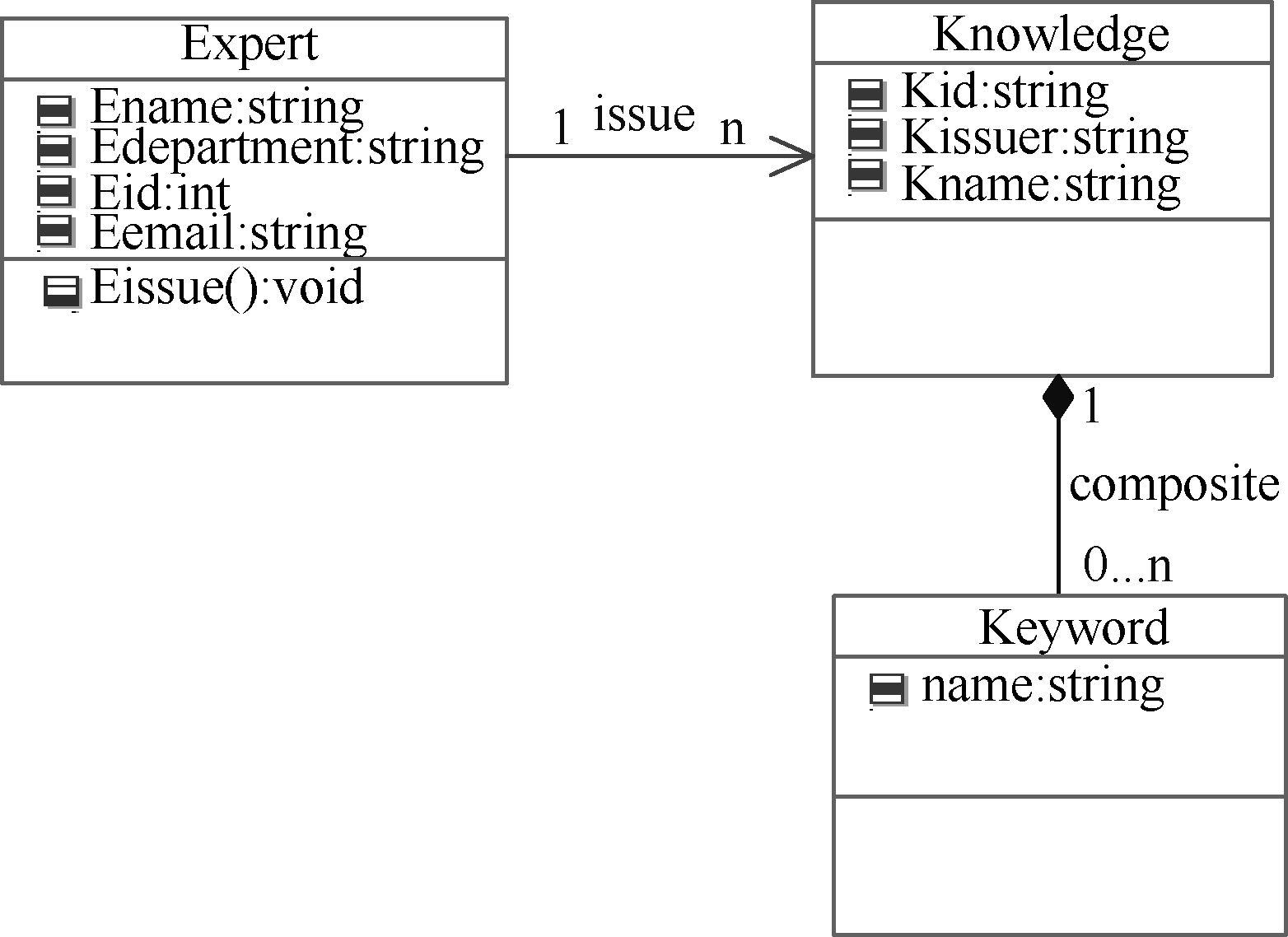 | 图1 专家-学术资源静态结构 |
鉴于目前多数专家信息组织都偏重外部特征(参照万方的专家检索或CNKI的学者检索), 笔者使用内容维度来完成专家特征向量的设计。作为弱实体, 关键词如社交网络中的标签, 有效地连接了设计过程。图1中实体间多重性经过两次传递, 可推知专家特征向量ve等同于其发布的n个学术资源中关键词vk的频次叠加, 形如公式(1), 这样处理充分考虑到专家科研的时间跨度和研究方向演化等因素, 基本描述了专家的研究点。
 | (1) |
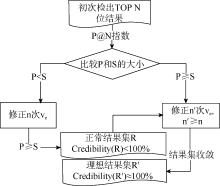
(2) 后端可信度评测过程
学术资源包括期刊、专著、专利、标准等。从不同类型资源中抽取的关键词表达力度也不一致, 一般情况下专著的表达力度要强于期刊。不仅如此, 在实际工作中还存在部分文献没有关键词、作者署名次序不一致等问题。鉴于这些情况, 专家特征向量无法精确描述, 且存在噪声。本文降噪方式就是根据专家学术资源中的关键词频次来取舍, 保留中高频次关键词, 放弃部分低频关键词。降噪处理后得到的关键词为专家特征词, 其数量称之为专家特征向量的目长, 用l表示。
组织好的专家特征向量按照与用户提问向量的匹配度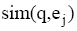

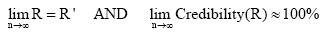 | (2) |
此时确认得到的相关专家集合 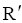
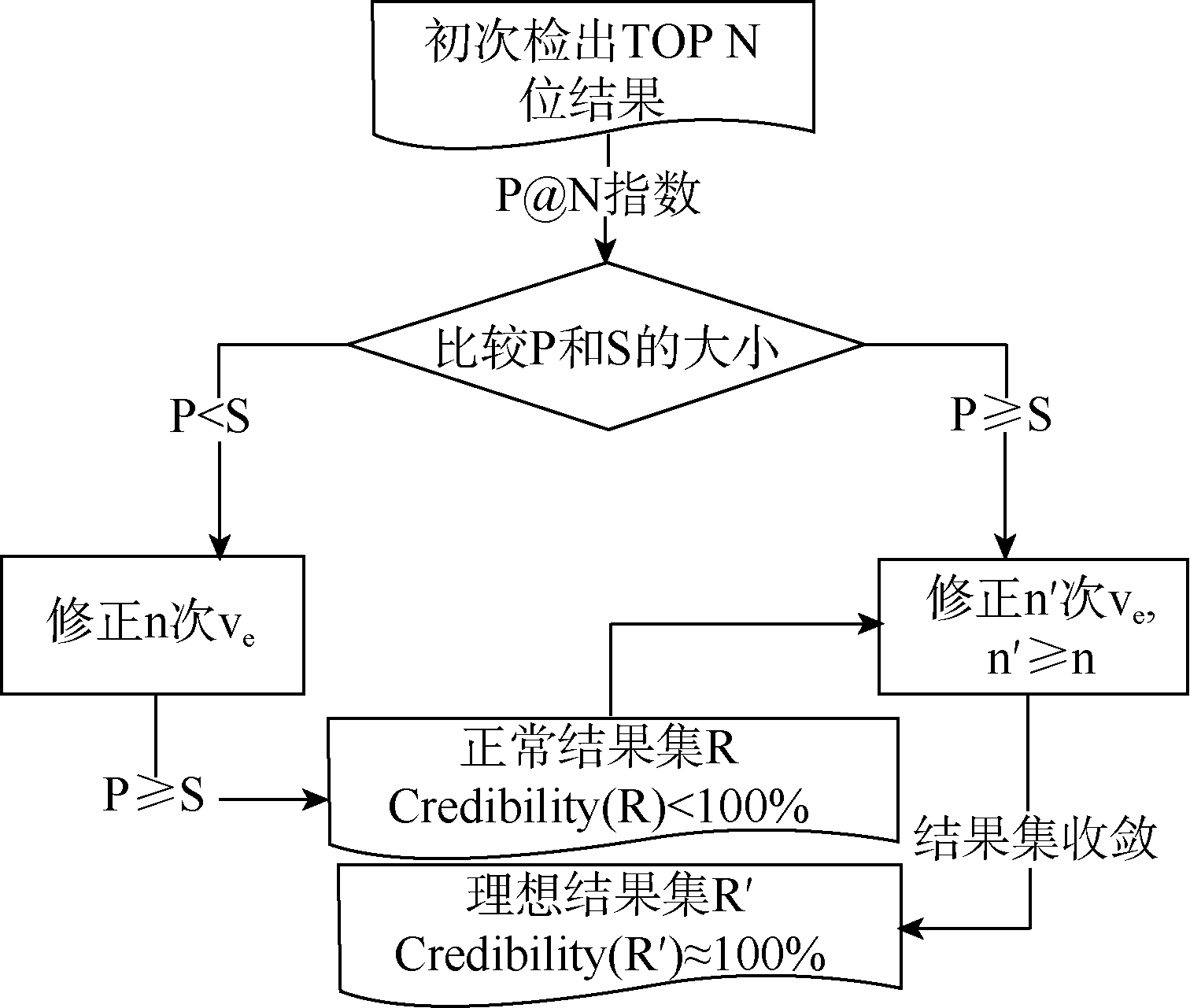 | 图2 后端可信度评测过程 |
(1) 前端可信度评测方法
前端可信度评测主要通过两种方法: 实验法和专家法。实验法步骤主要包括: 构建专家检索平台; 选取标准专家数据集、评测指标(常用指标为P@N、MAP);设立对照组; 通过专家检索平台测试数据集, 并对照分析。
实验法组织的可信度评测建立在过往检索算法(对照组)的基础之上, 不以用户需求满意度为主测评指标, 用户主导性不强, 但评测过程自动化程度较高。专家法则通过问卷、小组讨论等形式, 由领域专家对检索结果进行人工评审。领域专家只是检索用户的一小部分子集, 他们的评审意见将对修正专家检索结果起到关键作用, 但可信度评测反馈过程比较慢。一般情况下, 专家检索结果可信度评测以实验法为主, 专家法为辅[ 4, 7]。
(2) 参数分类及其优先级设置
为实现用户自主的专家检索, 笔者对BIM的参数进行了适当改造, 主要体现为:
①参数分类
前端可信度评测机制需要关联两类参数: 系统预定义参数和用户自定义参数。系统预定义参数属于系统全局变量, 其值选取要基于相应的训练文本集, 且不随用户的变化而变化。用户自定义参数属于局部变量, 仅作用于用户当前检索。
②参数优先级设置
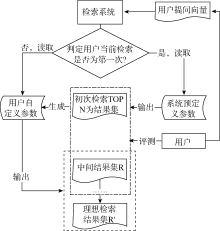
前端可信度评测机制要建立在用户反馈基础之上, 当用户初次检索时, 由于不存在用户反馈信息, 因此需要依据系统自定义参数值来检索。初检后, 用户对检索结果进行定量评价, 完成自定义参数赋值, 之后检索就按照用户自定义值来执行。由两类参数在专家检索中的交互过程可知: 用户自定义参数的优先级要高于系统预定义参数, 即专家检索算法执行时, 检索系统首先判断用户是否自定义了变量值, 如果没有, 则系统根据预定义参数值来获取结果。当对检索结果可信度存在疑问时, 用户可修改预定义值来重新检索。当前检索结束后, 检索系统不会保留用户对系统值的修改, 下一次检索仍然按照系统预定义参数值来执行, 整个过程如图3所示:
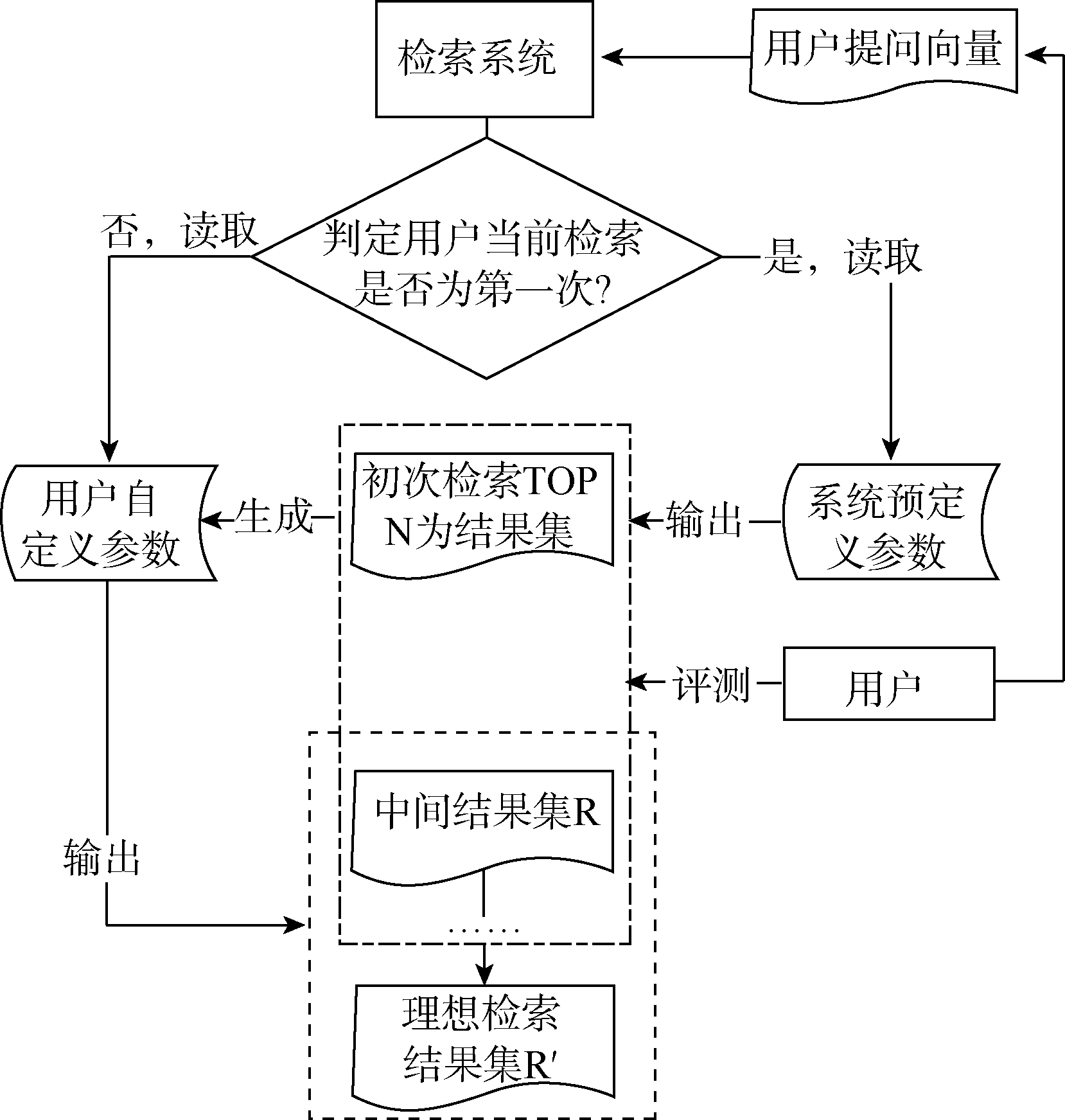 | 图3 前端可信度评测过程 |
(3) 前端可信度评测算法
每一个用户提问向量q都对应一个理想的专家集合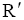
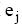
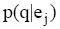
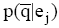
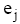
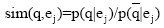 | (3) |
为了保证专家检索的用户自定义功能更具操作性, 公式(3)通过逐级推导和对数运算[ 20], 最终可得到公式(4):
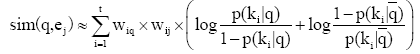 | (4) |
其中, 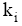
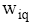
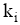
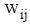
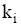
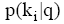
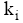
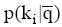
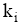
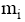
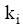
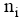
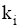
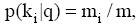
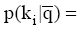
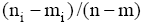
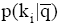

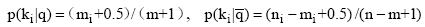
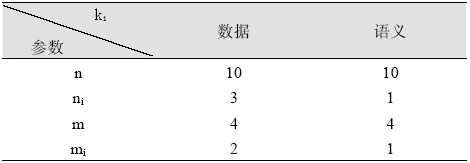
评测过程要基于用户反馈, 因此评测时间包括两部分: 系统检索时间和用户评测时间。两者相比, 用户评测时间对评测效率影响更大, 所以评测过程对q提出一定要求, 一般情况下, q中的关键词数量不宜太多, 3个为宜。由公式(4)可知, 单个关键词至少需要用户设置2个(n和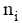
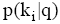
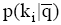
后端可信度评测机制通过修正专家特征向量目长来实现用户对检索过程的控制, 目长l是用户可定义的变量; 前端可信度评测机制则更加直接, 在q解析的基础上, 用户对与关键词相关的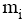
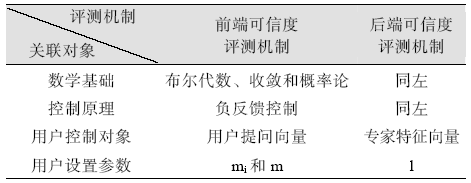
| 表1 前后端可信度评测机制异同点 |
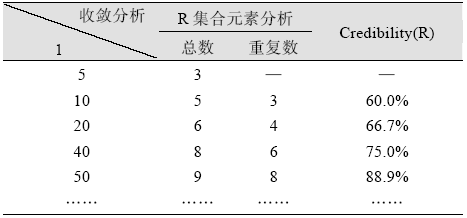
笔者以CNKI为学术数据库, 从管理类、经济类、图情类和计算机类中分别选择IF排名前11的期刊为知识源。根据文献生产者分布的一般规律, 可推知专家应该是该主题领域发文量较高的群体, 因此笔者选择各领域发文量最高的前10位作者作为专家(图情类为20), 采用这种方式构建的候选专家集合虽不够完备, 但易于实现。按照2.3节信息组织方法获取专家特征向量(初始目长l=5), 计算机类专家特征如表2所示:
| 表2 计算机类专家特征 |
围绕所有专家特征信息, 笔者以“q=模糊*语义*检索”对后端可信度评测机制进行实例说明, 其结果如表3所示:
| 表3 后端可信度评测实例分析结果[ 21] |
由表3可知, 一方面, 随着目长的不断增加, 专家信息趋于完备, 检索结果集R内的元素虽每一次都在变动, 但相邻两次结果集的交集越来越大, 这些在连续多次检索结果中都出现的元素具有较高的可信度。另一方面, 目长也不能无限增加, 否则将延迟系统处理效率。因此后端可信度评测不一定要R可信度为100%, 只要连续多次R趋于收敛即可。
与此同时, 为了简便起见, 笔者以“q=数据*语义”为提问式, 以表3为专家集合进行前端可信度评测实验。其评测中系统预定义参数需要训练集才能确定, 在此笔者假定表3中10位专家是初次检索按照相关度倒序输出结果, 对上述结果进行相关性评价, XYG、SSZ、SBL和SCY是与查询q相关的文档, 则用户自定义参数值如表4所示:
| 表4 用户定义参数值 |
则 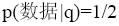
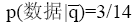
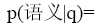
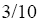
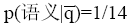
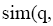
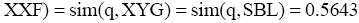
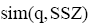
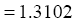
此外, 还要注意, 为了易于展现评测过程, 本文只选取部分作者作为候选专家, 这本身对可信度评测具有一定影响, 主要表现在用户提问与专家特征匹配方面。为了降低这种影响, 实验采用的检索提问和专家特征被限定在同一个主题领域, 即使如此, 由于初检时缺乏词表控制, 还是有可能出现不能匹配的问题, 因此用户提问要具有相对完备的信息。初检后, 用户判断将行使词表职能, 这也是前段评测两类参数设计的原因。随着专家集合的不断增大和词表控制系统的引入, 上述影响将逐步减弱, 但与此同时噪声信息也将增多, 因此结合前后端可信度评测机制构建学科关联性强的领域专家检索系统更为实用。
在实际的专家检索系统中, 需要根据实际情况来有机协调两种机制。第2.2节提到专家信息组织有4种识别方法, 后端可信度评测机制与这些识别方法有很大关系, 专家信息组织越好, 后端可信度评测机制发挥的空间越小。基于学术资源的专家识别效果要优于其他方法, 基于网络资源或综合多种资源获取的专家信息可能存在更多噪声和冲突信息, 后端可信度评测机制更适用。相比后端, 前端可信度评测机制更易理解, 用户不用关心专家信息组织方法, 而只关注检索结果与提问的相关程度, 并且用户提问被解析成多个检索词, 更易进行定量化评价。但此时需要注意控制用户提问的长度和检索结果集评价的数量。
脱离了实际系统, 前后端可信度评测机制无从比较。无论哪一种评测机制都不能应用于初次检索, 在对初检结果进行可信度评价之后, 系统才能按照用户要求开启下一轮检索。因此, 下一步笔者将关注如何根据训练集获取系统预定义参数值。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|