


{kind=link}
{kind=link}
{kind=link}
利用双语词典检索英汉跨语言剽窃文档对应内容*
[秦颖 ]
]
]
|
|


【目的】在英汉跨语言剽窃文档中检索翻译对应内容。【方法】基于双语词典进行相似分析, 合并整理词典以提高词语级匹配的准确率和效率, 利用整体词频分布、匹配位置特征等解决歧义和多重匹配问题, 根据词的对应情况、词的位置信息等综合加权计算句子及段落的相似度。【结果】在真实翻译语料上的实验结果表明, 检索的准确率为0.841, 召回率为0.748。【局限】未登录词的翻译关系不易根据词典判定。【结论】基于双语词典检索跨语言相似内容的方法简单易行, 适用面广。
[Objective] Translation correspondence in English-Chinese cross-lingual plagiarism documents is studied. [Methods] Similarity analysis is taken according to bilingual lexicons. To improve the precision and efficiency of corresponding words recognition, this study merges and sorts several bilingual lexicons. As to the problems of disambiguation and multiple matching, the paper proposes a method which applies word distribution and matching location to select the proper translation items. Similarities between sentences and paragraphs are defined on the stratified complex features such as word matching category, position of words and so on. [Results] Experiments on real translation documents show that precision and recall of retrieval reach 0.841 and 0.748 respectively. [Limitations] Out of Vocabulary (OOV) correspondence is still hard to judge by lexicons. [Conclusions] The approach of cross-lingual similarity detection based on bilingual lexicons is easy to implement and has a wide range of application.
互联网和信息技术的发展让人们更及时、准确、全面地获取信息, 同时, 学术不端行为——剽窃凸显, 成为全球化的问题。检测剽窃成为图书情报领域一个重要的研究课题。
Alzahrani等[ 1]将剽窃形式大致分为两类: 一种称为字面剽窃(Literal Plagiarism), 主要在同种语言之间发生, 基本属于“复制-粘贴”式抄袭; 另一种称为智能剽窃(Intelligent Plagiarism), 主要有通过重述、总结等改变原创的抄袭、翻译剽窃及思想观点剽窃等。其中, 单语剽窃文本的检测研究相对较多, 目前已有商用的检测产品, 也有在线的免费服务(, 如WCopyFind ( http://plagiarism.bloomfieldmedia.com/z-wordpress/)、Turnitin ( http://turnitin.com/zh_hans/us-categories/home/ home)、CopyTracker ( http://copytracker.unige.ch/cts. php?action=index)、CrossCheck ( http://www.crossref.org/ crosscheck/)等)。但这些工具对跨语言剽窃(又称翻译剽窃)文档都无能为力, 要检索翻译剽窃文档对应的内容, 目前可利用的资源有双语词典、语料库等, 资源有限。
跨语言剽窃文档, 基本没有语言形式上的可比性, 自动检测十分困难, 研究开展得很少, 尚没有公开实用的软件问世[ 1, 2]。尽管跨语言剽窃文档和原创文档的主要含义和思想相似, 但不一定构成常规意义上的翻译关系。因为通常翻译要求首先忠实于原文, 但剽窃文档可以只是部分内容翻译或者不完全翻译、不准确翻译, 这更为自动检测增加了难度。
如何检测跨语言剽窃, Periera等[ 3]提出了一个实现框架, 包括候选文档检索、详细内容查找和后处理三步。第一步属于跨语言信息检索, 第二步通过和候选文档比较, 确定相似对应内容的位置, 本文关注的正是这一步内容。
已开展的相关研究有: Barrón-Cedeno等[ 4]基于语料用统计语言模型训练了一个判别是否构成翻译关系的识别系统, 来检测英语到西班牙语跨语言相似的句子。但由于平行语料的缺乏, 限制了该方法的应用。机器翻译中的双语对齐[ 5]也和本研究有相近之处。双语对齐的任务是确定源语和目的语在段落、句子甚至短语、词语级的对应关系。前提是给定文档已认定构成翻译关系[ 6]。翻译剽窃对应内容检索并未约定基于翻译相似的内容一定存在, 相应内容的位置也不确定, 更由于剽窃文档不是正常的翻译, 翻译时不受忠实性的约束, 或者只是部分进行了翻译剽窃, 因此难以利用双语对齐的思想和方法对齐相应的内容。实际上, 翻译剽窃检测的主要目的是发现相似, 并不要求作对齐。
求解跨语言相似, 常用的方法是利用双语平行语料[ 4]和借助双语词典[ 7]。本文采取基于双语词典的方法, 不会因平行语料缺乏无法训练模型而无法求解。另外, 翻译中一个源语言词往往有多种合理的译法, 而词典提供的义项尽管是静态语义, 但比平行语料中确定单一的译文还是要丰富得多。为适用于不同领域, 将双语词典分为基本词典和用户词典(或领域词典)两类。基于双语词典进行词一级的翻译对应检索, 进而计算出句子和段落一级的相似。词典的规模、义项的多少及歧义问题是基于词典检索的三个关键问题。在跨语言剽窃文档对应内容检索中, 做了以下改进:
(1) 合并词典及整理义项, 以提高匹配的效率和准确率。
(2) 针对和词典义项匹配时的歧义问题和多重匹配问题, 提出了利用整体词频分布、匹配位置特征等进行义项选择的方法。
(3) 综合各种特征, 分层加权计算句子相似度, 特征包括词的位置、词的匹配相似度、不同匹配程度等。
双语词典提供了词语级的翻译知识, 自然也就成为最常用的语义知识库。词典的质量和规模是跨语言相似的关键。根据翻译方向一般会有两部词典, 比如英汉词典和汉英词典, 而且不同领域需求的词典规模也不同。部分机读词典源于普通词典, 而面向人的词典有诸多不适合机读的特性, 例如会用one’s、somebody、something、oneself等模糊地表示一类代词和名词; 用“…”表示译词中间允许有其他不定的若干字词等。如果有多个翻译义项, 各义项的翻译概率相等, 匹配时只能依次盲目搜索。这是基于词典的方法和基于平行语料的方法的根本区别。数据稀疏和多义歧义问题更是困扰该方法的主要难题[ 8]。
扩大双语词典的规模和丰富翻译义项对减小数据稀疏问题有利。为此, 首先对已有的多个双语词典做了合并, 将不确定内容作为翻译模式。检索词语翻译对应关系时, 通常依次将义项和目标位置的所有内容进行匹配。合并后的词义项明显增多, 但也降低了检索效率。由于排在前面的义项有较高的优先权, 只有将最常用义项排在前面, 才能提高效率。因此在词典合并后, 不能简单地将各义项组合在一起, 要进行整理。在没有学习语料的情况下, 无法得到各个义项的翻译概率。通过研究发现多个翻译义项间有一定的关系, 可以根据各义项之间的共有特征来判断某义项的常用性。
下面以英汉词典为例说明整理汉语翻译义项的方法。整理汉英词典的方法类似, 只是基本考虑单位不是汉字而是英文单词。
整理汉语义项的依据是: 汉字绝大多数都有其基本义, 词义和组成词的字义密切相关。如果汉语译文中某个字是高频发生的, 则其可能携带了译文的核心常用语义。比如: aback有6个汉语义项: 向后、朝后地、船顶风、向后地、突然地、逆帆, 其中多个义项中都含有“后”字, 而这也是该词的主要语义要素。据此对汉语义项计算得分并排序。义项的计分方法为:
设某词条的义项数为m, 某义项Xi由 
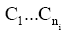
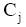

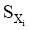
 | (1) |
显然 
另外, 根据公式(1), 相同条件下, 字数多( 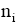
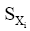
通过整理词典增大了词典规模, 减小了数据稀疏, 又提升了机械匹配的效率和准确率。
基于词典义项在目标文档中检索对应译文时, 根据待查词是否收录在词典中分为词典词和未登录词两类。词典词的译文在检索时又有两种情况: 有匹配内容和无匹配内容。有匹配内容时又可以分为唯一匹配、多个匹配两种情况, 多个匹配时就需要歧义消解选择某一个义项; 无匹配内容可能是由于义项收录不全, 也可能确实没有对应译文, 通过扩充词典义项可以解决部分问题。对于未登录词, 有可能是普通词, 也可能是新词和专名等, 扩充词典规模只适用于普通词汇, 未登录词和新词等是无法尽收的。还有一部分词无需根据词典译文查找翻译对应, 它们是未经翻译的数字或者源文的原词。基于词典判断词一级翻译对应的各种情况如图1所示:
 | 图1 基于词典判断各类词语翻译对应的各种情况 |
由于翻译不是词到词的对译, 基于词典求翻译相似还有Vocabulary Gap等其他问题[ 8]。求跨语言相似度时, 词典词根据义项匹配情况判断翻译关系, 未登录词则需要其他特征判断翻译相似。句子相似度通常根据词语相似度之和与句子长度之比计算。未被翻译的词可以直接在目标文档中查找, 不需要检索词典, 计算相似度时将其放在词典词一类中处理。
词的翻译相似度根据词典义项和目标串的匹配程度计算。完全匹配时记1; 部分匹配时, 计算词典译文和目标串的Dice系数[ 7]再乘以一个小于1的系数, 因为部分匹配有意义偏差; 无匹配内容的记0。即词典词wi词典译文的匹配相似度为:
 | (2) |
同时注意到, 如果出现连续匹配的情况, 句子间的相似度应该比分散位置的匹配更高些。因此加入匹配位置因素, 为连续匹配上的词的相似度增加位置得分, 实现两层加权计算相似。设两次匹配源文词距和译文词距之间为随机变量, 设源文前一次匹配的位置为 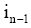
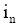
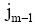

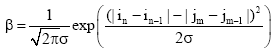 | (3) |
其中, 实验中取经验值 
那么, 总词数为T的原文句子和目标句基于词典词的相似度为:
 | (4) |
其中, 
对于未译词首先要进行识别。比如利用数字和英文单词的识别模块识别出汉语文档中可能的未译词, 到英文文档中直接检索, 而不再通过词典得到英文翻译义项。但是未译词的匹配只有完全匹配才计分。英文词未作词形还原。其他计算方法同上。
(1) 位置临近原则消歧
一般构成翻译关系的句子中, 源文邻近的词在译文中译词也容易相邻。当多个义项在句中多处有匹配时, 如果构成翻译关系, 和前一个已匹配义项距离最近的义项的概率最高, 以此作为消歧的原则。设某词的义项在目标句中匹配词为A, 该词相邻词的义项在目标句中有3处匹配位置: B1、B2和B3, 如图2所示。假设翻译关系成立, 两词的译文也应相邻, 那么图2中选择B1译文作为匹配的翻译。位置邻近原则可用作多义歧义消解。
 | 图2 多义多重匹配歧义及消解 |
(2) 翻译对应词词频分布相似原则消歧
如果两篇文档为翻译关系, 则其关键词的分布也存在相似性。其语言学的理论依据是: 一个词在一篇文章的词义往往是单一的, 其译文也相似。Yarowsky等[ 9]在词义消歧研究中就利用了这个假设, 并收到了很好的效果。根据语料统计数据, 中英文对译的高频词词频之比均值为1.45, 标准差为0.624。也就是说, 如果在一篇英文中某词出现了10次, 那么其95%汉语译词的出现次数在2-27次之间, 在此词频区间之外的词成为其译词的可能性很小。这是利用文档级词频分布的特征来消歧的依据, 以确定多义词的义项选择。
利用词频的对应关系判断翻译关系也存在很多细节问题, 以英译汉为例, 主要有:
①不同词性的英文词翻译为汉语后, 其译词可能是同一个, 比如, Evaporate和Evaporation都译为“蒸发”, 因此统计词频前需要做英文的词形还原处理。
②同一个英文词反复出现时, 译文中为避免重复, 可能会以同义词替代, 这造成了对译词的词频不等同。发现和判定同义的译词是否来源于某个源文词有诸多困难, 目前还未能考虑。
③对应关系不完全是词到词的对应, 可能是词组到词组, 因此在词一级词频的对应关系可能不存在, 这一点也是利用词频分布相似原则消歧不能解决的。
文档词频分布相似原则在文档级适用。实验表明, 该方法在句子级和低频词的消歧效果不好, 但对于文档高频关键词的消歧有时也能起到很好的作用。
实验语料部分来自北京外国语大学英汉双语语料库非文学领域数据, 部分是真实翻译剽窃文档, 均是人工翻译的文本。其中, 英译汉语料145篇, 英汉翻译剽窃文档9篇, 共40.5万字。这里并未利用文档的分类、摘要及参考文献等信息, 因为这些信息并非存在于所有剽窃文档中。
通过对154篇英汉译文及翻译剽窃文档的测试, 系统候选文档检索返回了84篇, 其中排名第一位的文档是相应的翻译文档的有73篇, 另各有1篇正确的翻译文档排在第二和第三位, 因此, top1的召回率为0.474, 准确率为0.869, F1值为0.613; top3的召回率为0.487, 准确率为0.893, F1值为0.630。翻译对应内容检索基于候选文档检索结果进行。
关于词典, 合并了LDC英汉词典2.0版和修订的哈尔滨工业大学计算机学院的英汉词典EC-dic以扩大词典规模, 得到Merged EC, 并对它进行了整理。表1为词典规模的信息。检索系统允许使用用户领域词典。下面的实验结果基于基本词典进行, 未加入用户词典。
| 表1 实验基本词典的信息 |
检索的语言粒度可以是句子或段落, 以实际文档的自然段落为单位计算相似度。
基于英汉和汉英词典, 对每个候选段落根据相似度计算公式(2)计算出两个相似度, 取数值较大者作为最终的相似值。计算所有目标文档段落的相似度得分并排序。相似度最高的并大于设定阈值的, 标记为翻译对应内容。无大于阈值得分的内容, 则认为无翻译对应。
另外, 相似度和句长及段长有关, 因为词语匹配度相同时, 固定阈值的方法对于短句有利。比如两个词构成的标题句, 如果一个词的译文有匹配, 则相似度就可达50%, 这和常规认识差别较大, 而且句子越短, 内容相似的概率越大, 但剽窃的可能性越小。因此对于6个词以下和以上的句子相似度分别设定了输出的阈值, 前者的阈值大于后者。
在实验语料上, 经过人工评定, 翻译对应段检索的准确率为0.841, 召回率为0.748, F1值为0.792, 达到了较好的性能。剽窃检索系统界面如图3所示。
目前的问题主要是短句的翻译对应检索召回率很低, 准确率也较低。未登录词翻译对应检索也是一个尚未解决的问题。
 | 图3 跨语言剽窃文档识别系统界面 |
本文基于双语词典实现英汉跨语言剽窃文档对应内容的检索和定位。首先对双语词典的规模进行扩充, 并对合并后的义项进行排序整理。匹配时优先匹配最常用义项, 提高了效率。这种方法对于通用语料的效果较好, 但学术文献的有些专业词汇由于语义的特殊性可能被排到更后的位置, 因此会降低匹配效率。下一步将研究领域词典的译项排序问题, 以更好地检索学术文献。
本文利用位置临近原则和文档词频分布信息消解匹配中多义歧义, 并将词语的匹配程度、匹配位置融入句子相似度计算。在实际剽窃语料和人工译文上得到了较高的检索性能。
基于词典求跨语言文档相似, 未登录词不能依据词典判断翻译对应, 下一步将研究未登录词的相似度计算方法。另外, 不同词对句子意义的贡献不同, 如何确定词的权重并融入句子的相似度计算中, 也是需要解决的问题。
英译汉和汉译英的过程差别很大, 英汉词典和汉英词典也十分不同, 本文中词典整理的方法可适用于两种词典, 但相似计算公式相关参数及多义消歧的经验值等, 在进行汉译英剽窃文档检测中有待进一步确认。
(致谢: 本研究得到北京外国语大学中国外语教育研究中心的资助。感谢评审专家的指导和建议。)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|