



{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合LDA与TextRank的关键词抽取研究*
[顾益军1 , 夏天2, 3  ]
]
]
|
|


作者贡献声明:
顾益军: 共同提出研究思路, 共同设计研究方案, 共同起草论文, 负责最终版本修订;
夏天: 共同提出研究思路, 共同设计研究方案, 共同起草论文, 负责数据收集和实验。
【目的】通过将单一文档内部的结构信息和文档整体的主题信息融合到一起进行关键词抽取。【方法】利用LDA对文档集进行主题建模和候选关键词的主题影响力计算, 进而对TextRank算法进行改进, 将候选关键词的重要性按照主题影响力和邻接关系进行非均匀传递, 并构建新的概率转移矩阵用于词图迭代计算和关键词抽取。【结果】实现LDA与TextRank的有效融合, 当数据集呈现较强的主题分布时, 可以显著改善关键词抽取效果。【局限】融合方法需要进行代价较高的多文档主题分析。【结论】关键词既与文档本身相关, 也与文档所在的文档集合相关, 二者结合是改进关键词抽取结果的有效途径。
[Objective] Realize keyword extraction through the merger of the internal structure information of single document and the topic information among documents. [Methods] LDA is used for topic modeling and influence calculation of candidate keywords, then, the TextRank algorithm is improved and the importance of the candidate words is uneven transferred by topic influences and word adjacency relations. Furthermore, the probability transition matrix for iterative calculation is built and used to extract keywords. [Results] The effective combination of LDA and TextRank is achieved, and the keyword extraction results are improved significantly when the data set presents strong topic distribution. [Limitations] High-cost multi-document topic analysis is required for combination method. [Conclusions] Document keywords are associated with document itself and the related documents collection, combination of these two aspects is an effective way to improve the results of keyword extraction.
关键词抽取是指从给定文本中快速获取有意义的词或短语的过程, 在信息检索、自动摘要、知识发现与挖掘等领域发挥着重要作用, 更是图书情报领域实现自动标引的关键方法。
完整的关键词抽取一般分为两个步骤: 候选关键词选取和从候选关键词中推荐关键词, 候选关键词的选取可以结合词性和N元词串实现, 相对较为简单, 因此, 如何从众多的候选关键词中挑选出目标关键词, 成为关键词抽取的关键。关键词抽取既可以通过统计方法获取, 也可以利用词图方法计算得到, 其中以TextRank[ 1]为典型代表的基于词图的无监督关键词抽取方法应用效果较好, 引起了研究领域的广泛关注。
TextRank及其改进算法[ 2]仅利用了文档本身的信息, 文档中每个词语的重要性默认会被均匀传递到所有相邻节点, 为了能够充分利用文档本身的信息和文档集合所提供的外部主题信息, 本文将LDA与TextRank融合到一起, 通过LDA预先统计学习候选词语的主题重要性, 进而对TextRank算法进行改进, 将候选词语节点的重要性按照主题分布进行非均匀转移, 通过迭代计算为每个候选词语进行重要性赋值, 并通过排序输出关键词抽取结果, 取得了较为理想的实验结果。
根据是否需要标注训练语料, 可以把关键词抽取方法分为两大类: 有监督关键词抽取和无监督关键词抽取。典型的有监督抽取方法把关键词抽取看作是一个是否为关键词的二分类问题[ 3, 4], 这种方法能够利用更多的已有信息, 效果相对较好, 但由于需要事先标注高质量的训练数据, 人工预处理的代价较高。因此, 现有的关键词抽取研究主要集中在无监督关键词抽取方面, 主流方法又可归纳为三种: 基于TF-IDF统计特征的关键词抽取、基于主题模型的关键词抽取和基于词图模型的关键词抽取。
基于TF-IDF统计特征进行关键词抽取简单易行, 但这种方法忽略了重要的低频词语和文档内部的主题分布语义特征, 因此, 基于LDA[ 5]隐含主题模型的关键词抽取方法在近年来得到了人们的重视[ 6, 7, 8]。LDA的主题模型需要对数据进行训练得到, 关键词抽取的效果与训练数据的主题分布关系密切。
词图模型把文档看作是由词组成的网络, 以PageRank[ 9]链接分析理论为基础对词语的重要性进行迭代计算, 无需数据集训练处理, 仅利用文档本身的信息即可实现候选关键词重要性计算和关键词抽取, 成为目前无监督关键词抽取的主流方法。Litvak和Last将链接分析的另一方法HITS[ 10]应用于候选关键词排序, 在关键词抽取性能上与TextRank表现相似[ 11]。同时, TextRank比HITS更为简洁和易于处理, 因此本文采用TextRank作为词图计算的基本算法。文献[2]在TextRank基础上, 分析提出了词语本身的重要性差异会影响相邻节点的影响力传递结果, 并通过分析影响词语重要性的主要因素, 提出从词语的覆盖影响力、位置影响力和频度影响力三个方面加权计算邻接词语所传递的影响力, 结果表明根据位置对词语进行加权处理可以有效提高关键词抽取效果。文献[6]直接应用LDA模型进行主题词抽取, 不能满足单文档抽取要求; 文献[7]利用主题模型计算词语的主题特征, 进而用装袋决策树方法构建关键词抽取分类模型, 同样需要对多个文档进行统计处理。相比而言, 文献[8]对关键词抽取问题进行了比较系统的研究, 综合利用隐含主题模型和PageRank算法实现了关键词抽取, 和本文研究更为接近。
文献[2]在衡量词语重要性时, 采用的是相对简单的经验赋值方法, 例如, 对于在标题中出现的词语赋予较高的权重, 实际上, 词语的重要性与其主题密切关联, 并可以通过对文档集合的主题学习获取。文献[8]利用主题信息对PageRank的随机跳转概率进行变更, 在计算不同主题的PageRank结果后, 合并排序输出关键词。与以上方法不同, 本文保持了PageRank的均匀随机跳转假设, 采用LDA隐含主题分析计算词语的整体影响力, 结合词语之间的邻接关系用于TextRank中概率转移矩阵的计算, 以较为简洁的方式改善了关键词抽取效果。
LDA(Latent Dirichlet Allocation)于2003年首次由Blei等[ 5]提出并用于文档主题建模。在LDA中, 每篇文档被表示为K个隐含主题的混合分布, 而每个主题又是在W个词语上的多项分布, 其概率图如图1所示:
 | 图1 隐含主题模型LDA的概率图表示[12] |
其中, ϕ表示LDA中主题-词语的概率分布, θ表示文档-主题的概率分布, α和β分别表示θ和ϕ所服从的Dirichlet先验分布的超参数, 空心圆圈表示隐含变量, 实心圆圈表示可观察到的变量, 即词语。
对于文档d中的词语w来说, 令 


 | (1) |
LDA需要推断出两个参数, 即每篇文档的“文档-主题”分布 

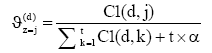 | (2) |
 | (3) |
其中, 

根据链接分析理论, 可以把关键词抽取问题转换为构成文档词语的重要性排序问题, 词语的重要性则可以通过文档本身内部词语之间的结构关系推举产生。为构建具有相互联系的候选关键词图, 基于文献[2], 笔者对文本按照句子分割, 进行分词和词性标注, 并保留切分后的名词、动词、形容词等重要词语, 作为词图的节点, 根据词语的相邻关系构建词图的边, 形成候选关键词图。
TextRank的基本思想是一个节点的重要性取决于有多少个相邻节点指向, 令V表示节点集, E表示边集, 


 | (4) |
其中, 
传统TextRank中每个节点的重要性会根据迭代计算不断改变, 为把词语的主题影响力纳入到计算过程中, 将任一词图节点的关键属性分为两部分, 一部分为节点的当前重要性分值, 代表节点在文档内部结构中的权威性, 默认值为1, 并在迭代过程中按照相邻节点的分值进行调整, 记为
; 另一部分为节点本身的主题影响力分值, 通过公式(1)计算得到, 代表文档外部信息在节点上的重要性, 在词图计算过程中保持不变, 记为
。例如, 图2为由{A, B, C, D, E, F}6个节点组成的候选关键词图, 圆圈的左半部分表示节点的名称, 右上部分表示节点的重要性, 右下部分表示节点的影响力, 影响力一旦由主题分析确定, 就不再改变。
 | 图2 候选关键词图示例 |
在图2中, 传统算法会由节点A以相等概率向另外5个节点跳转, 即各有20%的概率分别到达B节点至F节点。然而, 更为合理的方式应是按照节点的影响力和节点之间的投票结果综合得分进行跳转, 即向高影响力节点转移的概率要高于向低影响力节点转移的概率, 为此, 定义新的节点重要性迭代计算公式如下:
 | (5) |
其中, 



仍以图2为例, 在新的计算方式下, 节点A向节点B新的转移概率变为:

假设文档d共包含 n个候选关键词, 即候选关键词图由n个节点组成, 则所有节点的初始分值向量定义如下:

为迭代计算需要, 需构建词语之间的概率转移矩阵M:
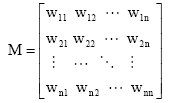
其中, 元素 



 | (6) |
在计算得到引入主题影响力的概率转移矩阵M之后, 令 
 | (7) |
其中, e为一个所有分量为1、维数为n的向量。通过公式(7)进行迭代计算, 当两次迭代运算的结果差异较小时计算结束, 此时, 进一步对向量B的分量进行降序排序, 选择最前面指定数量的节点所对应的词语作为关键词输出结果。
简要说来, 整个融合过程分为两步: 基于LDA主题模型对文档集合进行文本建模, 利用公式(1)实现词语的主题影响力计算; 把主题影响力带入公式(6), 通过迭代计算实现节点的重要性计算, 进而得到词语的重要性列表和关键词抽取结果。
本文所提算法采用Java1.6予以实现, 并选取公开的互联网网页作为测试文档, 与学术文献类文档不同, 网页文档虽容易获取, 但语言规范性相对较弱, 因此, 关键词抽取的难度更大。为测试算法效果, 实验采用文献[2]中所使用的通过链接自动抽取[ 13]和正文自动抽取[ 14]所构建的数据集, 共由1 000篇网页文档组成。并定义准确率P、召回率R和宏平均F值如下:

其中, KA表示数据集本身提供的关键词集合, KB表示自动提取的关键词集合。
实验中使用开源的分词和词性标注工具ANSJ[ 15]和机器学习包Mallet[ 16], 并通过停用词表和词性过滤形成候选词关键词集合, 过滤的词性集合为{代词, 量词, 数词, 介词, 方位词, 副词, 时间词, 标点符号}, 同时, 实验中针对数据集手工添加形成的停用词表集合为{记者, 报道, 搜狐, 时间, 体育讯, 虽然, 责任编辑, 编辑, 直接, 可能}。实验对比了三种不同的方法, 分别是:
(1) LDA+TextRank: 本文提出的通过LDA计算词语影响力, 进而通过TextRank抽取关键词的方法;
(2) TextRank: 基于PageRank原理的传统TextRank方法;
(3) LDA: 通过本文所给出的基于LDA计算词语影响力的方法, 按照词语影响力高低抽取关键词。
实验中,, 每种方法抽取前5个词语构成关键词抽取结果, TextRank迭代终止条件为两次迭代结果的差异值小于等于0.005, 或者迭代次数超过20。LDA中, 设Gibbs抽样的主题数目为k, 则超参数
,
, 迭代次数为1 500。当主题数目k从2到180变化时, 三种方法的抽取结果如图3所示:
 | 图3 不同方法的关键词抽取结果对比 |
从图3中看出, TextRank算法仅使用文档本身的信息即可实现关键词抽取, 因此其结果和主题数量无关; 方法1在主题数量超过30之后, 优于TextRank方法和LDA方法; 方法3抽取结果不够稳定, 并且在主题数量较少时, 效果较差。但三种方法在该数据集下的抽取结果总体差异不大, 其F值平均分别为28.24%、27.39%、25.61%, 总体而言, 方法1效果略优于其他方法。
由于该数据集的主题较为分散, 为测试在主题性较强的情况下, 三种方法在关键词抽取方面的差异, 实验进一步挑选了文献[17]中所提供的文档集进行测试, 该文档集共有953篇文档组成, 但未提供关键词列表, 实验中主题数量取值为10, 其他参数同上。为考察方法差异, 将不同方法之间所抽取的关键词结果进行集合比对, 任意两种方法抽取结果中共现的词语数量分布情况如图4所示:
 | 图4 不同方法抽取结果的词语共现情况 |
图4中, 折线后部分线段占得比重越高, 则说明两种方法共现词语的数量越多, 算法越接近。其中, 方法1和方法2的对比结果里, 5个关键词中有3个、4个和5个相同词语的文档数量分别为315、435和96, 三者占文档总数量的88.77%, 反映出方法1在很大程度上保留了TextRank可以充分利用文档本身结构信息的特点。方法1和方法3中, 共现词语数量为3、4、5的文档数量分别为314、179和47, 共计56.67%, 说明方法1在一定程度上利用了文档集合的主题信息。而方法2和方法3的折线分布呈先凸后凹形状, 二者之间存在明显差异。
另外, 为观察本文所提方法与TextRank和LDA方法的差异, 把有显著差异的抽取结果, 即抽取结果完全不同或仅有一个词语相同的情况, 按文档编号顺序将前5组结果列于表1和表2之中。
| 表1 方法1与方法2抽取结果对比 |
| 表2 方法1与方法3抽取结果对比 |
从对比列表中可以看出, TextRank无法利用文档整体的信息, 对于部分主题标识性强的词语, 往往难以出现在抽取结果中; 而单纯的LDA方法又无法充分利用文档内部的结构信息, 主题性词语经常占据抽取结果的主要部分。 LDA+TextRank方法综合利用了文档的内部和外部信息, 效果相对较好, 但抽取结果中依然出现了“以及”、“来源”等不适宜作为关键词的词语, 该问题一方面和数据集包含噪音数据有关, 另一方面和词法分析有关, 可以通过词性过滤和完善停用词表解决。
文档本身的结构组成和文档之间所蕴含的主题信息是关键词抽取的重要依据。本文基于LDA主题分析方法预先计算词语的主题影响力, 进而改进TextRank算法的词语重要性迭代计算公式, 把词语主题影响力纳入到概率转移矩阵的构建过程中, 通过迭代计算实现候选关键词的排序和关键词抽取, 进而在主题分布不明显和具有明显主题特征的两组数据集上分别进行了实验和对比分析。
实验结果表明, 当主题分布不明显时, 本文所提方法略优于TextRank和LDA方法, 当数据集呈现出较强的主题分布特性时, 融合LDA与TextRank能够取得更为理想的关键词抽取结果。同时, 词法分析的准确率对关键词抽取结果也有较大影响, 因此, 进一步优化词表的构造与更新, 并为词表中的词条设置不同的权重以提高关键词抽取效果, 将是本研究的后续工作之一。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|