
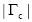
{kind=link}
{kind=link}
{kind=link}
利用主题标引进行查询重排序*
[毛进1  , 李纲
, 李纲1 , 操玉杰2 ]
, 李纲|
|


作者贡献声明:
毛进:设计研究方案,进行实验;
李纲:提出研究思路,起草论文;
操玉杰:参与研究方案设计,论文最终版修订。
【目的】在伪相关反馈过程中,利用主题标引对查询结果进行重排序。【方法】借助语言模型方法,挖掘主题词与用户查询关系,将用户查询表达为主题词的概率分布,并建立主题词语言模型,进而判断主题词在文档中的权重。在此基础上,重新计算初次查询结果文档分值,进行查询重排序。【结果】本文方法能够较好地为主题词建立语言模型表示,挖掘得到主题词在文档中的权重,重排序结果相较于初次检索具有普遍性能提升。【局限】未比较挖掘主题词与文档关系的不同方法;未在不同规模、不同语言数据集中实验。【结论】挖掘主题词与用户查询关系、主题词与文档关系,进行查询重排序,能够提升查询精确度。
[Objective] This paper tries to re-rank search results with the help of subject indexing in the process of pseudo feedback. [Methods] User queries are represented with probability distributions over subject terms by mining the user query and subject term association in the manner of language modeling. The weights of subject terms in documents are calculated by incorporating the generative language models for subject terms. Then re-calculate the score of search documents in the first retrieval and re-rank the documents according to their scores. [Results] The proposed method constructs the generative langauge models for subject terms and mines weights of subject terms in documents appropriately. The re-rank results are pervasively improved over the initial retieval. [Limitations] Different methods of mining the associations between subject terms and documents are not compared. This approach doesn’t test the datasets with different scales or in different languages. [Conclusions] The re-rank approach can improve the retrieval precision, which exploits the associations between user queries, documents and subject terms.
图书情报机构中,大量信息资源以自然语言文本形式存在。自然语言文本中的词汇具有自由性、随意性等特征,同一个概念往往存在多种词汇表达,这给信息检索带来不便。为避免自然语言的这种不确定性,主题标引借助受控词表中的规范主题词在概念层面对信息资源进行标注,用户亦可通过主题词检索信息。通过概念层面匹配,主题标引期望解决用户查询用词与信息资源中词汇的不匹配问题[ 1]。作为一种重要的信息组织方式,主题标引不仅在传统图书馆领域起到重要作用,随着计算机的应用,主题标引也在机读记录和文献数据库中得到更为深入的发展。主题标引已成为众多数据库管理中一种必不可少的工作,其中最具代表、最为成功的应用是PubMed数据库[ 2]。在该数据库中,专业标引人员付出大量努力利用医学主题词(MeSH)对文献进行主题标引,并整合到数据库检索系统之中。在人工主题标引之外,自动主题标引的应用与发展使得部分主题标引工作可交由计算机自动完成,使得主题标引数据更易获取。在主题标引数据越来越丰富的背景下,尝试利用主题标引来优化信息检索过程,提升用户检索的满意度,将有助于用户更好地获取信息资源。目前利用主题标引提升信息检索效果的方式主要有:借助主题词进行查询扩展[ 3],增加主题词在检索模型中的权重[ 4],将主题词视为概念并融入到文档或用户查询的表示模型中[ 5, 6, 7]等。与前述研究不同,本文通过挖掘主题词与普通词项、主题词与文档之间的关系,借助语言模型方法,提出一种利用主题词对检索结果进行重排序的方法,提升检索系统精确度。
观察用户使用检索系统,发现用户一般不会浏览所有查询结果,而更多地关注查询结果的靠前部分[ 8]。改进检索系统查询结果排序,使其更满足用户信息需求,有助于提升用户满意度。查询重排序的一般过程为:在检索系统初次返回的查询结果基础上,对查询结果进行重新排序,使得与用户查询相关的文档排序更靠前,并且该过程无须执行二次检索。
影响查询重排序的原因或重排序的准则来自于多个方面,其中最为重要的是通过查询重排序,提升查询结果的精确度。由于用户对检索主题的熟悉程度不同,用户查询词或多或少存在着一定的模糊性,对检索结果进行重排序,使检索结果的靠前部分包含多个主题,以使用户理解和选择主题,帮助用户找到所需信息[ 9]。根据检索结果的多样性(Diversity)[ 9]或新颖性(Novelty)[ 10]进行查询重排,即是按照结果文档所从属的主题进行查询重排序。另一方面,在部分检索场景中,用户希望先掌握检索目标的概貌,然后再利用更加专指的查询词进行检索,此时可根据文档的一般性(Generality)[ 11]进行查询重排序,将讲述主题概貌的文档置前。
建立新的结果文档排序规则,是实施查询重排序的重要环节。现有研究主要利用相关反馈信息、文档上下文等信息来构建新规则。其中,相关反馈信息包括:检索结果的点击信息、文档发布时间、浏览历史、查询日志等隐式反馈信息[ 12],以及相关反馈或伪相关反馈信息。伪相关反馈应用较多,部分研究在伪相关反馈基础上,进一步从伪相关文档集合中挖掘出相关文档。Sakai等利用选择性抽样策略进一步筛选出相关文档进行查询重排序[ 13]。周博等通过计算文档与伪相关反馈信息中的相关文档与不相关文档的相似度,组合得到文档的查询分值,从而对查询文档重新排序[ 14]。原福永等则通过计算文档与伪相关反馈文档集合中其他文档的相似度,并整合文档与查询词的相似度,以最终相似度大小对文档排序,呈现给用户[ 15]。Diaz认为相似的文档应当拥有相似的分值,根据这种思想,运用KNN聚类算法在整个语料库中寻找文档的邻近文档,构建语料库的图结构表示,进而调节查询结果文档中的相似文档分值,重新计算文档分值,以此排序检索结果[ 16]。Kurland进一步通过查询结果文档进行聚类,将相关文档和不相关文档、不同主题的文档进行聚类,在伪相关反馈文档中聚集在一起的文档可能是相关文档,而孤立的文档可能为非相关文档,进而通过相关文档所属聚类信息来构建查询语言模型,利用语言模型方法对查询结果文档进行重排序[ 17]。
另一方面,文档上下文信息也可用于衡量文档本身的重要性,Google等搜索引擎在初次查询结果的基础上,利用网页链接关系、锚点文本等信息对查询结果进行重排序,提升检索效果[ 18]。Krestel等通过将文档标题等信息链接到维基百科上,利用外部知识资源识别文档主题,作为文档多样性评分,将其与文档原始检索评分进行整合,对检索结果重排序[ 9]。文档中所标引的主题词也可以理解为上下文信息,在某种程度上揭示文档主题,可作为查询重排序的依据。Kamps将主题词作为文档特征,建立文档的向量空间模型,挖掘伪相关反馈文档中的主题词,利用降维技术提取出核心主题词,建立用户查询的主题词向量模型,进而计算用户查询的主题词向量与每个查询结果文档的主题词向量的距离,以此重排序[ 19]。Yin等构建两个维度的上下文信息:医学主题词和文档关键词,组合两个维度的上下文信息后,在向量空间模型基础上计算文档与查询的相关度概率值,以此排序[ 12]。与这些研究类似,本文在伪相关反馈过程中,通过文档中标注的主题词来进行查询重排,不同的是本文在语言模型基础上利用主题词概率分布来表示用户查询,结合主题词与文档的相关性进行查询重排。
首先从伪相关文档中发现主题词,计算主题词与用户查询的相关性大小,并利用主题词概率分布来表示用户查询,即用户查询的主题词语言模型。在语料库中,通过挖掘主题词与普通词项在文档层次的共现关系,利用普通词项为主题词建立语言模型,进而计算文档中所标注的主题词与文档的相关度,得到文档中主题词的权重。最后,利用查询结果文档中主题词权重,将用户查询的主题词语言模型,转化为查询文档最终分值,并以此将初次检索的结果文档集进行重排序。
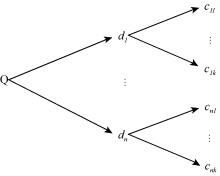
在基于语言模型的信息检索中,查询相关性模型通过伪相关文档挖掘用户需求,以语言模型方式对用户查询建立概率分布模型。与查询相关性模型类似,本文利用伪相关文档挖掘用户信息需求。不同于以往研究中以词项来表征用户查询需求,笔者认为用户查询可以用主题标引的概念来表示,即利用文档中赋予的主题词来表示用户需求,即以主题词作为语言模型的基本单元,来表示用户查询。图1展示了从伪相关文档中得到主题词集合的过程,其中Q为用户查询, 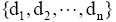
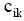
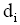
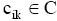
 | 图1 用户查询的主题词表示 |
类似于一元语言模型以词的概率分布来表示文档,也可利用主题词的概率分布来表示用户查询,即采用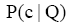
(1) 统计伪相关文档集合中主题词的频次,得到主题词及其频次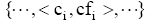
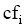
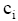
(2) 利用最大似然估计法计算主题词概率:
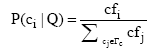
其中, 
在图书情报领域,主题词常常被理解为概念,自然语言文本中的普通词项,根据其语义可以映射为主题词。从语义关联和语义层次关系出发,一些人工知识资源,如中文语言的HowNet、英文语言的WordNet、医学主题词表(MeSH)等,通过同义词、近义词、上位词、下位词、概念词项等形式,一方面体现主题词之间的概念关系,另一方面也能实现普通词项与主题词之间的映射。根据这种显式的语义映射,可以寻找到主题词所关联的普通词项集合,用普通词项集合来表示主题词。进一步扩展,可以借助文本挖掘方法,从主题词与普通词项在文档层次的共现关系,来识别出与主题词存在联系的普通词集合,并量化表达。此种方法所发现的普通词项与主题词之间的隐式联系,不同于人工知识资源中显式的语义关联。
根据概率论原理,可以采用语言模型来表示主题词,即将主题词表示为普通词项的条件概论分布: 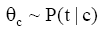
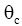
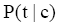
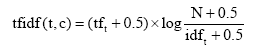
其中, 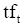
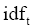
经过标准化处理后,得到:
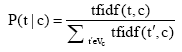
其中, 
在现有的主题标引系统中,标引人员对文档赋以主题词进行主题标引时,缺乏体现不同主题词重要性的机制,以反映主题词与文档的相关度。美国国家医学图书馆NLM(National Library of Medicine)所采取的方式是通过添加“*”符号来区分文档的不同级别主题词[ 21],标有“*”符号的主题词相较于无该符号标识的主题词而言对该文档更为重要,是主要的标引词,其不足在于它只有级别之分,而没有从定量的角度反映主题词与文档的相关性大小。概率模型在自动标引和文本检索中的成功应用,给主题标引带来新的启示:在人工主题标引中引入概率,通过概率大小来表示文档中主题词的权重[ 22]。相较于以往的标引机制而言,给标引词赋以权重的加权标引机制,不仅应该受到标引人员的重视,同时还应该整合到系统功能之中[ 23]。在信息检索领域,通过引入加权标引机制,主题标引的穷尽性、专指性等特征将对检索的有效性造成影响[ 24]。
在人工主题标引过程中,标引人员一般根据文档的某些特征或者模式来选择主题词[ 25],其中关键词往往是标引人员参考的重要线索[ 26]。简单来讲,标引人员通过识别文档中的主题性词项作为依据选择用于标引的主题词。因此,带权重的普通词项可作为文档与主题词之间的纽带,挖掘文档与普通词项、主题词与普通词项之间的关系,则可以推测出主题词与文档的相关性权重。
根据语言模型方法,将文档视为由普通词项构建的语言模型 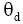
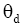
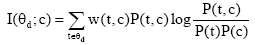
其中,t是文档中词项,c是文档主题词, 
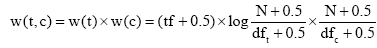
其中,tf是文档中词项t的频次,N是语料库中文档总量, 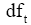
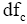
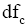
而针对 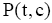
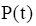
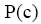

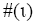
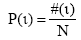
通过以上计算步骤,即得到主题词c与文档d的加权互信息权重,进而对文档中所有主题词进行标准化处理,计算得到最终的主题词c在文档d中的权重值 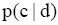

该权重值代表主题词在多大程度上与文档主题相关。
本文所解决的核心问题是在检索系统初次检索结果基础之上,利用少数伪相关反馈文档构建用户查询的主题词表示,进而利用主题词在文档中的权重重新计算检索结果文档的分值。若某主题词在用户查询的主题词语言模型中的概率越大,而且该主题词在文档中的权重越高,那么该文档与用户查询的相关度则越大。检索结果文档的最终分值汇集该文档所有主题词的信息。其计算过程如下:
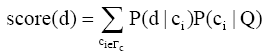
利用贝叶斯理论,得到:
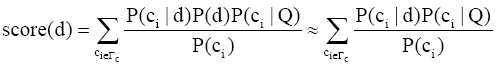
其中, 

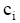
通过以上公式计算的结果,即得到检索结果文档新的分值,根据该分值从大到小将检索结果文档排序,实现检索结果的重排序。
实验中选择常用于医学信息检索研究的Ohsumed数据集[ 28],共收集1987-1991年的348 566篇文献的元数据信息,分别是标题、标引词、作者、出版类型、摘要、期刊来源及文档标识符等,其中主题标引所使用的受控词表为医学主题词表(MeSH)。从数据集特征来看,该数据集适用于本文研究实验。Ohsumed数据集中共包括106个查询,并含有确定相关文档和可能相关文档数据,实验中将两者合并视为相关文档,用以进行精确度计算。设置实验参数时,用于表示主题词的语言模型中的词项数量上限设置为1 000,伪相关反馈文档数量N取值为1-10,用于表示用户查询的主题词数量 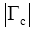
实验中精确度指标采用P@N[ 20]:

其中, 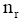
采用语言模型检索工具Lemur[ 29]对数据集建立索引,索引过程中使用其自带的Krovetz词干提取方法,并根据标准信用词表,去除418个停用词。运用Java语言编程实现算法,进行分析。实验初次检索采用查询似然模型,将查询重排序结果与其结果进行对比。
主题词的语言模型反映主题词与普通词项之间的语义关联程度,并以概率方式进行量化表达。主题词的语言模型,通过将主题词所标注的文档子集当作主题词的语言文本表示,从而进行计算。表1呈现了启发式方法与最大似然估计方法下“Liver Circulation”(肝循环)和“Ascitic Fluid”(腹水)两个主题词的语言模型权重排在前10位的词项。
| 表1 主题词的语言模型示例 |
观察发现,两种方法都能将主题词自身所包含的词项赋予较高概率,但是启发式方法能够降低高频词的概率,提升与主题词存在较强语义关联的词项概率。启发式方法为“Liver Circulation”寻找到“vein”(静脉)、“cirrhosis”(硬化)、“pressure”(血压)等与肝循环存在较强关联的词项,为“Ascitic Fluid”找到“peritoneal” (腹膜的)等与腹水相关的词项;而“patient”、“article”和“journal”等在该数据集中出现频次较高的词项的权重则较低。
通过以上分析发现,启发式方法能够较好地挖掘普通词项与主题词之间的语义关联,并以概率体现关联强度。正确计算普通词与主题词之间的语义关联强度,为文档中主题词权重计算,打下较好的基础,直接影响最终结果。
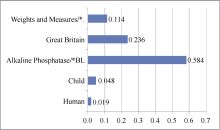
文档主题词权重计算尝试区分不同主题词与文档主题的相关性。图2列出PubMedID为90149307的文档的所有主题词权重。从该例中可以发现,带有“*”标号的主要主题词项权重较高,而“Human”和“Child”等在语料库中广泛存在的主题词则被赋予较小的权重。“Great Britain”权重也较高,但由于该主题词是地理意义的词,未被识别为文档的主要主题词。由此发现,本文主题词权重计算方法与人工标引过程对主题词地位的区分存在一定的契合度,能够较好地区分不同主题词的权重大小,从而保证后续文档重排序计算。
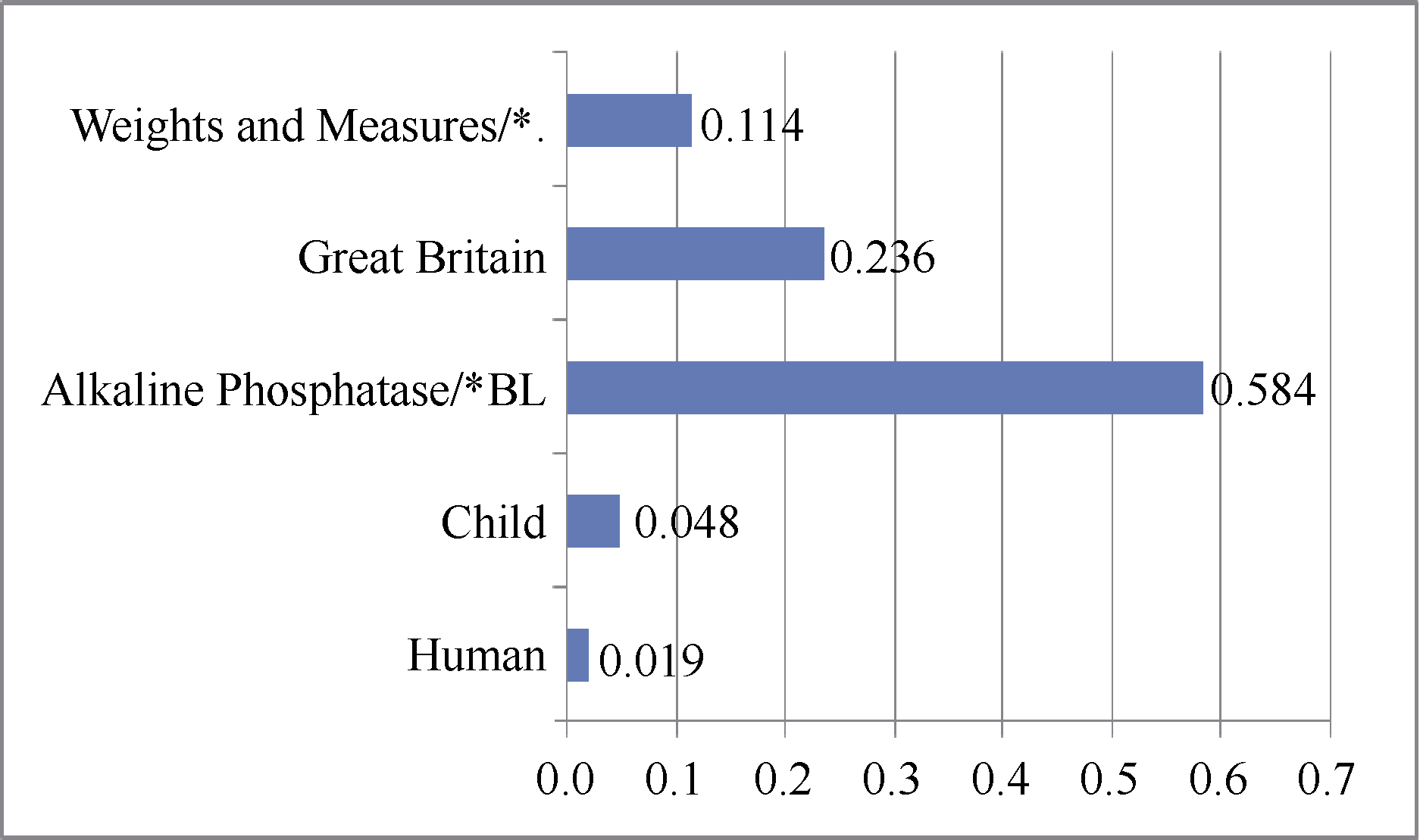 | 图2 文档主题词权重示例 |
通过实验结果分析发现,当N=5、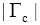
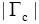
| 表2 重排序结果与查询似然模型结果的对比 |
为了更为细致地观察不同查询的重排序情况,图3列出了所有106个查询的重排序结果相对于初始检索的P@15值变化比例,其参数设置为N=6、 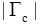
 | 图3 106个查询的P@15值变化比例 |
本文利用文档中标注的主题词,在语言模型基础上,通过挖掘伪相关反馈文档,将用户查询表达为主题词语言模型。通过主题词与普通词项在文档层次的共现关系,发现主题词与普通词项之间的联系,以此判断主题词与文档内容的主题相关性权重,区分不同主题词对文档的主题贡献度。进而结合以上两方面,对初次查询结果进行重排序,提升检索性能。结合本文方法和实验,有如下讨论:
(1) 本文方法不仅可用于主题标引环境,在社会化标注环境中,用户对信息资源赋予的社会化标签,也能从一定程度上揭示主题概念。结合社会化标注环境特征,修改和优化本方法,可将本方法用于社会化标注环境中的信息检索;
(2) 本文方法是一种形式化的语言模型方法,与具体语言环境无关,适用于包括英文、中文在内的各种语言环境,研究在多语言和跨语言环境中概念与词项、概念与文本间的关系,可进一步扩展本文方法的应用场景;
(3) 实验过程中,伪相关反馈文档数量N,表征用户信息需求的主题词数量 
(4) 本文采用加权互信息来计算主题词与文档之间的关系,是否存在其他更为合适的方法将会在未来进一步探索;
(5) 本文方法是一种利用主题词提升信息检索效果的方法,其核心在于量化文档中主题词的权重值。除查询重排序之外,是否能将主题标引应用于信息检索的其他过程,特别是量化文档中主题词的权重是否能用来改进信息检索,将是未来的研究方向之一。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|