
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于大众标注的层次信息可视化算法研究
[杨如意 , 刘东苏]
, 刘东苏]
, 刘东苏]
|
|


作者贡献声明:
杨如意, 刘东苏: 提出研究思路, 设计研究方案;
杨如意: 采集、分析数据, 进行实验, 起草论文;
杨如意, 刘东苏: 论文最终版本修订。
【目的】为了更好地分析大众标注的语义关系, 以层次可视化的方式增强用户感知。【应用背景】大众标注可以从普通用户的角度很好地反映网络资源的意义。层次信息可视化技术作为一种有效的表现抽象信息的工具, 被广泛应用于辅助用户认知和分析层次数据集。【方法】提出五元组描述大众标注的语义的方法, 借用归类方法使大众标注具有层次关系, 基于层次结构提出信息可视化方法, 用于显示大众标注集。【结果】实验表明, 该方法可以清晰直观地揭示大众标注的层次关系, 改善平面布局, 而其他语义关系存储在大众标注节点中, 不直接干扰用户感知。【结论】该方法简单有效, 能够从优化整体布局的角度可视化层次信息, 增强用户感知能力。
[Objective] Hierarchy visualization is an intuitional way to analyze semantic relations between Folksonomies by enhancing users’ cognition. [Context] Folksonomy reflects the meaning of Web resources well from the perspective of the common users. Hierarchy information visualization technology, as a precise tool of representing abstract information, is widely used to assist users to cognize and analyze hierarchy data set. [Methods] Firstly, a five-tuple method is improved to describe the semantics of Folksonomy. Secondly, the paper uses an existing classification to make the Folksonomies have hierarchy relations. At last, it puts forward an information visualization algorithm to display the Folksonomy set based on hierarchy structure. [Results] Experiments show that it reveals represents hierarchy relations of Folksonomies clearly and intuitively, improving the layout effectively. Other semantic relationships are stored in Folksonomy node for less influence on users’ cognition. [Conclusions] It is proved to be an effective and simple way to visualize hierarchy information from the perspective of optimizing the overall layout and enhance the ability of user cognition.
大众标注(Social Tagging 或Folksonomy)是网络资源的利用者为了便于自己或他人获取和利用由自己或其他人创建的某一数字资源, 而对该资源赋予标签的过程或结果[ 1]。大众这个词强调了普通用户可以自由地对网络资源添加标注, 而不是用事先定义好的相关领域的Ontology, 所以大众标注降低了语义Web应用的门槛。
信息可视化(Information Visualization)作为辅助管理信息的一种有效工具, 在信息检索(Information Retrieval, IR)、数字图书馆(Digital Library, DL)、人机交互(Human-Computer Interaction, HCI)等领域被广泛应用, 有助于用户感知信息、分析信息, 避免在信息中迷航(Disorientation)[ 2]。最基本地, 可视化技术使用图来呈现数据或概念之间的关系[ 3]。层次信息作为一种最常见的抽象信息, 常常用于描述计算机文件目录、公司组织结构、图书分类等。Reingold 和 Tilford 提出的层次树布局方法将聚焦节点放在最上方, 子节点依次放到父节点的下方, 形成层次树(Hierarchy Tree)[ 4]。但对于大型层次结构, 这种表示很快会因横向(每层节点个数)和纵向(层次结构的层数)扩展的比例不一致而导致层次结构分支拥挤交织, 甚至容纳不了全部信息[ 2]。
本文对大众标注采用五元组的表示方法来记录标签的语义信息, 然后按照一定的归类方法, 使得所有标签具有层次关系, 最后提出基于层次结构的可视化算法, 优化标签的平面布局, 增强直观性。
标签本体(Tag Ontology)是利用本体的概念对用户的标注行为进行明确的规范化说明, 一般采用n元组的形式来描述标注行为, 较为广泛的应用有: Tag Ontology、MOAT(Meaning Of A Tag)、以及SCOT(Social Semantic Cloud Of Tags)[ 5]。
层次信息可视化技术被广泛应用于辅助理解和分析层次结构数据集。人们在对层次信息可视化进行研究的过程中提出了一系列可视化技术。径向树(Radial Tree)[ 6]布局中, 不同层次的节点被配置在若干个半径不同的同心圆上, 根节点绘制在圆心处。子节点直接排布在距离当前节点最近的一个圆环上, 孙子节点则在次近的圆环上。Lamping等[ 7]提出一种基于双曲几何的“焦点+上下文”(Focus+Context)可视化技术。双曲树(Hyperbolic Tree)浏览技术在基于双曲线的圆形平面区域内显示层次结构信息, 根在树的中间向外呈扇形扩展, 当用户选择下游节点时, 该节点被推到中心, 同时放大其视图及细节信息。Shneiderman[ 8]提出一种可以充分利用屏幕空间的层次信息表示模型——树图(Tree-map), 将层次结构映射到一个二维矩形区域, 通过嵌套矩形框表现层次关系, 充分利用整个可视空间。
以上几种可视化方法在空间拓扑上缺乏层次结构直观性, 不能最优化利用有限的可视空间, 节点失去的细节信息较多, 各分支之间的穿越机制亦较难实现。为此, 本文提出一种改进平面布局的层次信息可视化算法, 基于大众标注的五元组表示模型, 以类似树形结构的方式表现标签之间的语义关系。
目前, 对于大多数专家系统, 普遍采用构建一个本体库来进行语义标注和语义检索[ 9]。由于构建领域本体工作量巨大, 内容复杂, 本文提出用五元组来简单描述标签的语义。
通常情况下, 大众标注的语义表示主要关注以下三个维度: 用户(user)、标签(tag)、资源(resource)[ 9]。用户是指该标签的创建者或者标注者, 资源是指用其标识的资源, 通常指代一个URL。这三个维度提取了大众标注的主要语义特征。
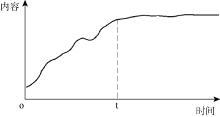
为了可视化地表现层次关系, 本文对大众标注添加了一个额外的属性: 层次(level)。层次指该标签在整个标签集中所处的层次, 是经过分类或者聚类后才表现出来的一个属性。此外, 由于一个标签在创建之后, 还会有其他用户对其修改或者添加标注, 这样就导致了标签语义的改变。这种变化可以形式化地表示成如图1所示, 创建的标签内容首先经历快速上升阶段(比如维基百科中的词条), 然后在一个时间拐点t处趋于稳定, 本文所研究的就是这种趋于稳定状态的大众标注, 所以时间维度刻画出一个标签的语义稳定性。
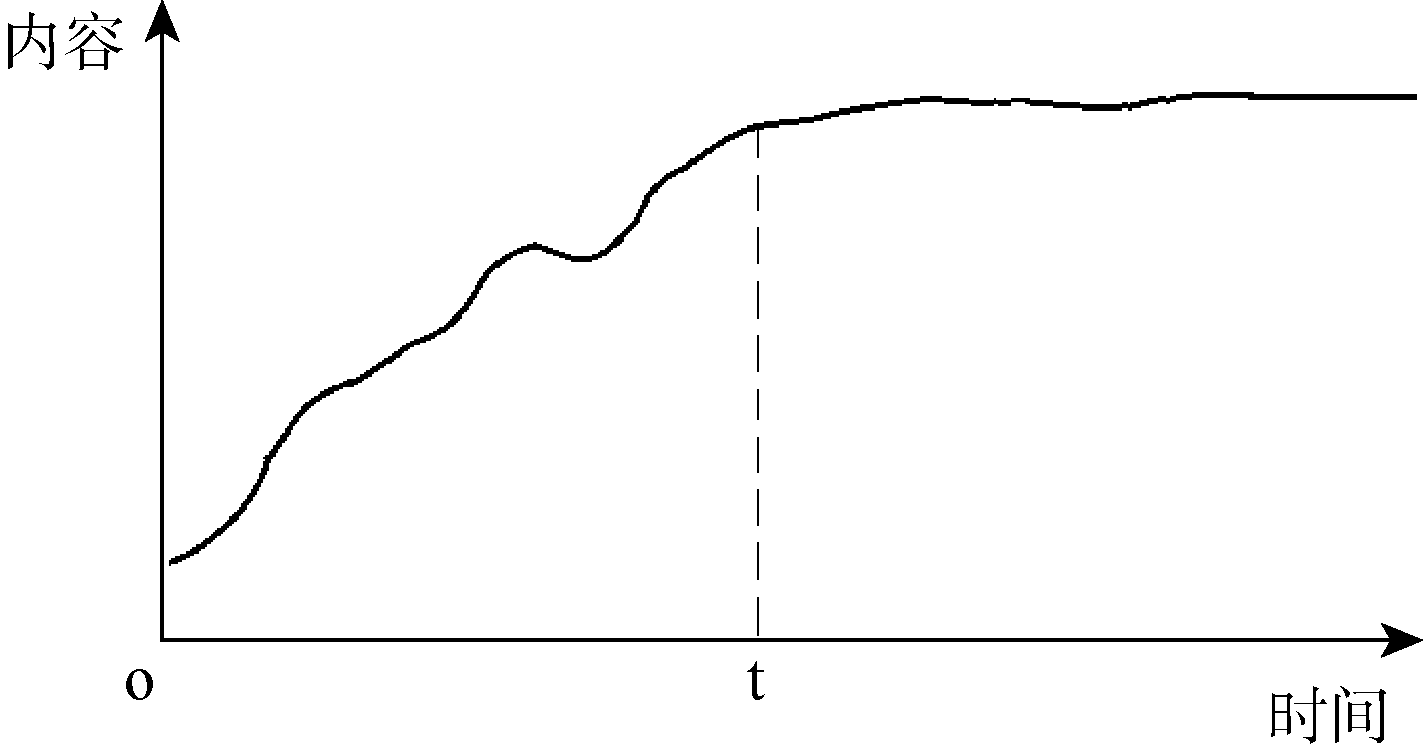 | 图 1 标签内容的变化 |
由此, 一个大众标注就可以被抽象成一个五元组: {user, tag, resource, time, level}。
Sanderson等[ 10]提出了一个简单的统计模型: X包含Y, 当且仅当P(X|Y)≥0.8, P(Y|X)<1。这个模型被用来归类从文档中提取的概念术语。基于这个模型, 文献[11]提出了一个归类算法用于实现层次树的构建和剪裁: 先判断标签与集合中其他标签的包含关系, 如包含对(Tx,Ty)表示Tx包含Ty, 然后根据包含关系添加从Tx到Ty的边, 构成有向无环图, 最后对图进行剪裁消除重复的标签, 这种剪裁消除了标签多重继承的情况。
经过裁剪后的图中包含许多树, 每棵树中的节点(标签)可以看成一个领域中的关键字或者概念的集合, 并且给出了这些概念之间的包含关系。这样的树可以认为是某个领域的本体, 这个本体不是由该领域的专家来构建的, 而是由Internet中的许多用户对资源的注释来决定的。
在层次可视化中, 把标签的层次关系视为包含关系, 即有父节点和子节点。将父节点定位在平面中央, 子节点均匀分布在以父节点为圆心的一定半径的圆周上, 连接父节点和子节点, 重复上述方法直至所有节点均绘制完成。基于这个核心思想, 同时考虑优化整体平面布局, 给出如下的数学模型, 使用到的通用符号的含义如表1所示:
| 表1 通用的符号 |
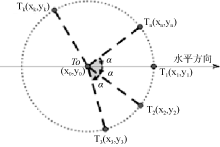
(1) 确定根节点和第一层节点的坐标
如图2所示, 根节点T0坐标为(x0,y0)且已知, 共有n个子节点。定位根节点的第一个子节点位置在T1处, T0T1的连线和水平方向平行, 子节点将根节点所在的圆均分, 均分角为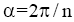
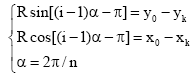
 | 图2 根节点及第一层节点分布 |
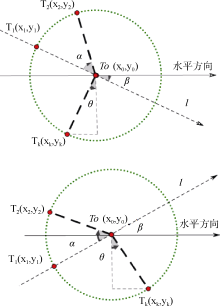
(2) 确定第二层及后面层次的节点坐标
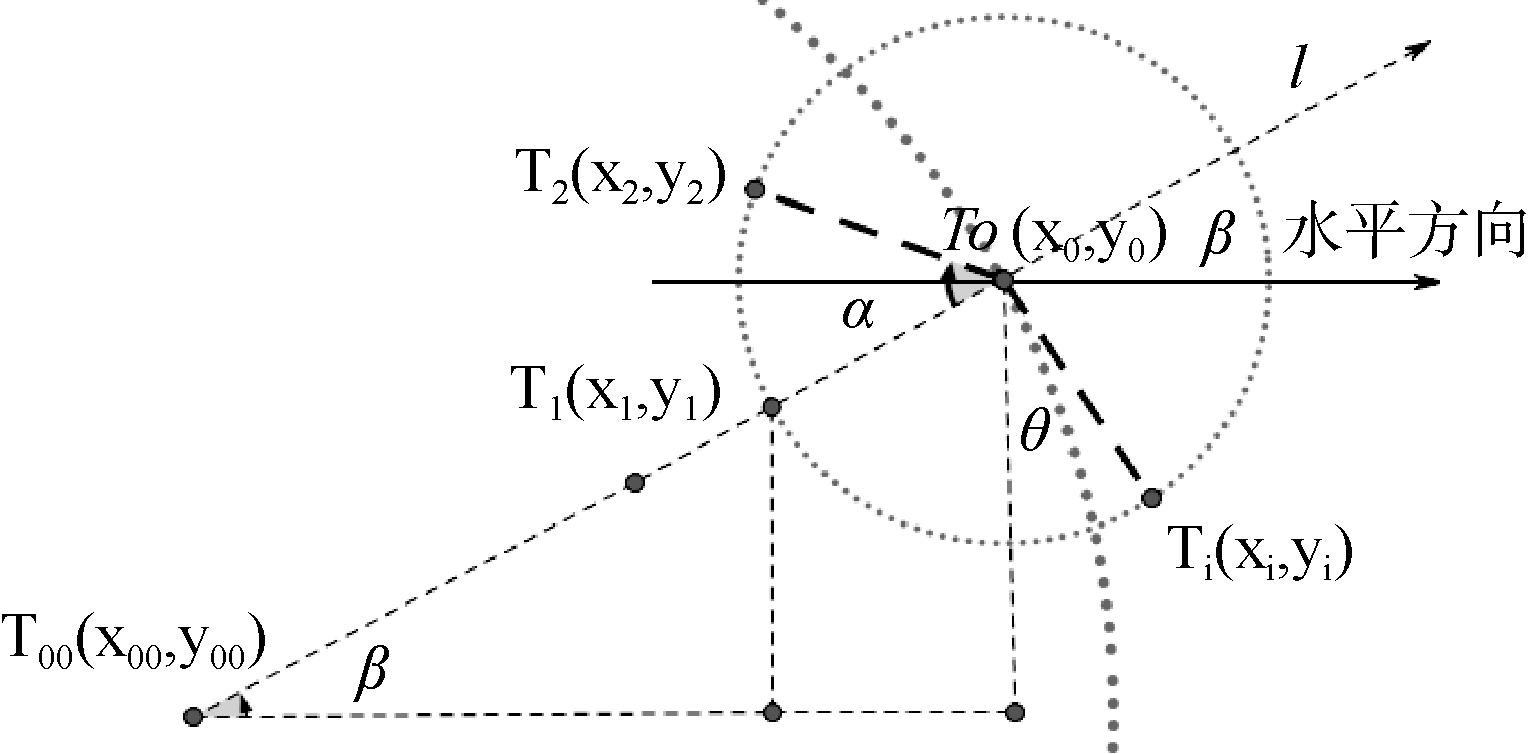
如图3所示, 节点T0(x0,y0)是具有父节点和子节点的节点, 其中射线 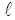
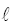
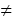
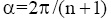
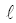
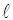
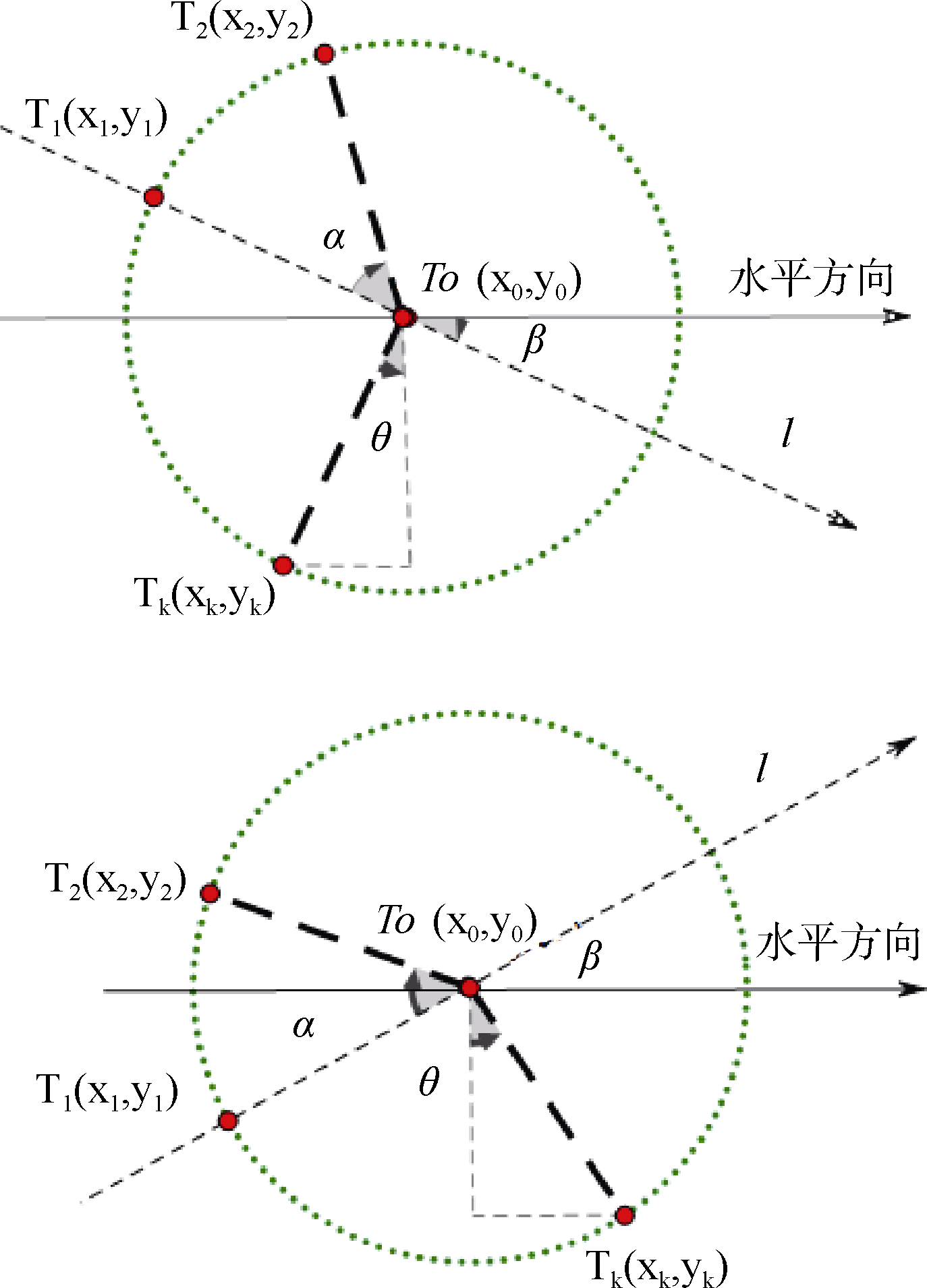 | 图3 第二层及后面层次的节点分布 |
那么对于任意的子节点Tk(xk,yk)(k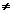
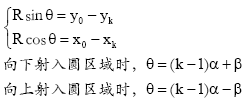
由于R的取值根据显示平面大小自主设定, 所以只需确定β值, 就可以从根节点的坐标推导出第一层节点、第二层节点等所有节点的坐标。
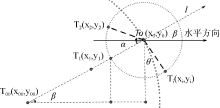
(3) 确定入射角β的值
如图4所示, T00(x00,y00)是T0的父节点, T0和T00均在 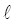
由几何方法可得:
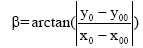
算法的伪代码如下:
算法 1: 基于层次结构的可视化算法
Input: a set of hierarchy nodes
Output: coordinator of all nodes
① FOR each Node
② IF (Node.level = =1)
③ compute x(abscissa of Node),y(ordinate of Node) using root node’s coordinator
④ Node.x←x
⑤ Node.y←y
⑥ ELSE
⑦ compute x(abscissa of Node),y(ordinate of Node) using upper level node’s coordinator
⑧ Node.x←x
⑨ Node.y←y
⑩ END FOR
本算法的运行时间主要在于执行⑦、⑧、⑨三步, 时间复杂度为O(n2), n为节点数量。相比于Hyperbolic Tree[ 7], 复杂度低; 相比于Radial Tree[ 6], 效果更加直观, 空间利用率高。
本算法的不足之处在于采用文献[11]的剪裁方法, 消除了标签多继承的现象, 表现为单继承的形式, 暂时不能满足跨层级、多继承的要求。
(4) 可视化效果
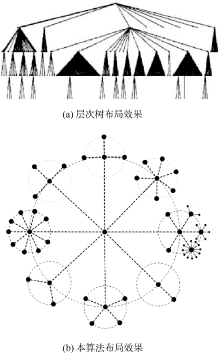
如图5所示, 对比层次树[ 4], 本算法的平面布局效果更加美观简洁。用户在信息空间内导航时,主要依赖全局上下文定位自己的位置[ 12]。本方法的可视化结果可以辅助用户迅速获取自己的位置及相邻的上下文环境, 更加直观地显示了大众标注集的层次结构, 能够迅速认知不同标签之间的包含关系。
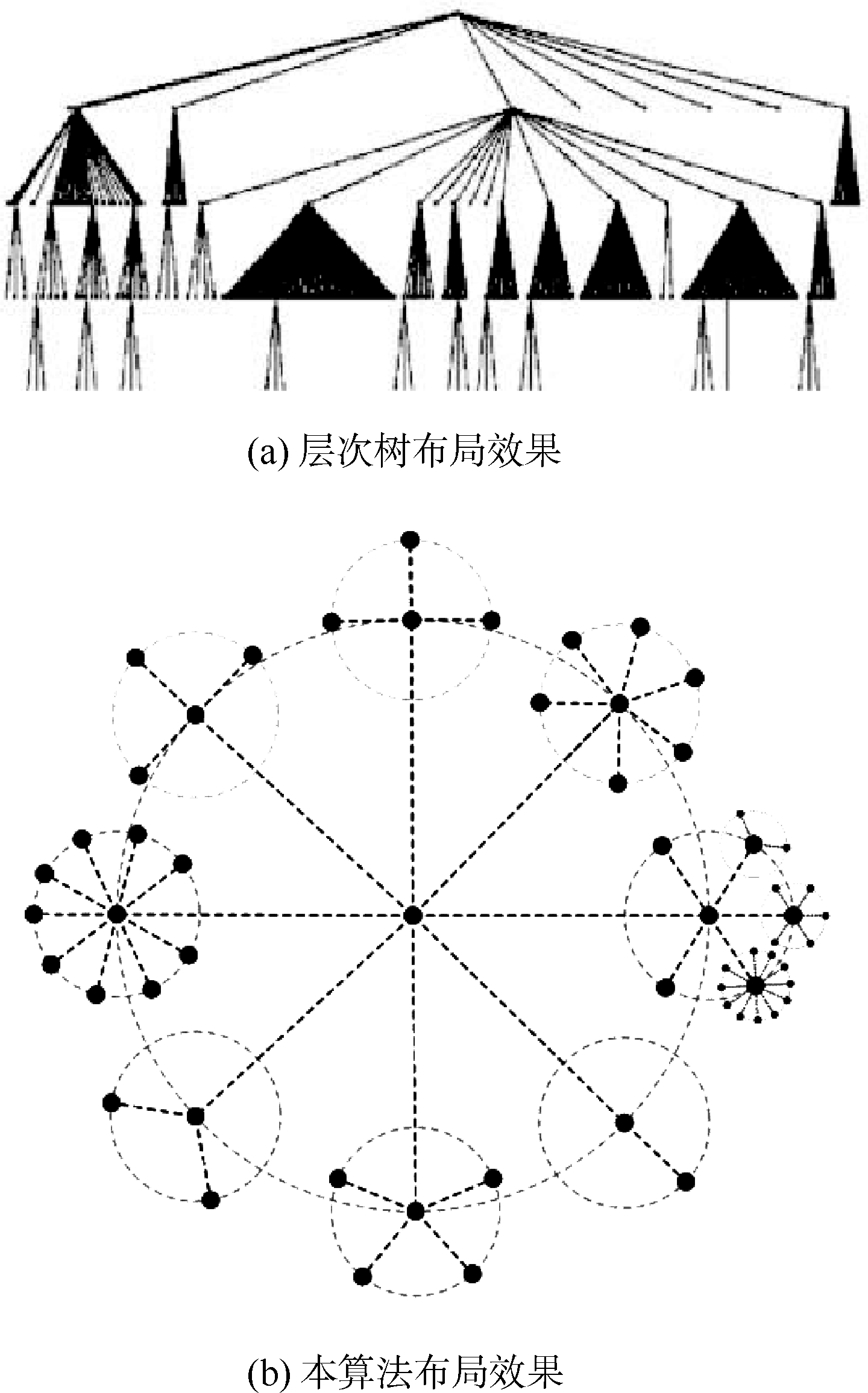 | 图5 显示效果对比 |
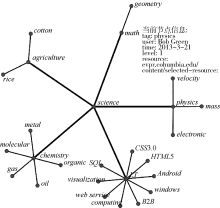
设计一个大众标注可视化分析系统, 标签的数据均为虚构, 将本算法应用于某个大众标注集, 得到的可视化效果如图6所示。
每个标签以节点形式存在, 并储存五元组的所有属性值。用户直接可见的是标签的tag属性和level属性, user、resource和time属性之所以没有在效果图中直接可见是为了保持整体简洁, 避免过多的文字影响用户感知, 当用户聚焦于某个节点时, 才会显示全部语义信息, 如图6所示, 用户聚焦于节点physics时, 五元组的所有信息在其上方显示, 以一种交互方式弥补本算法语义表示的不足。
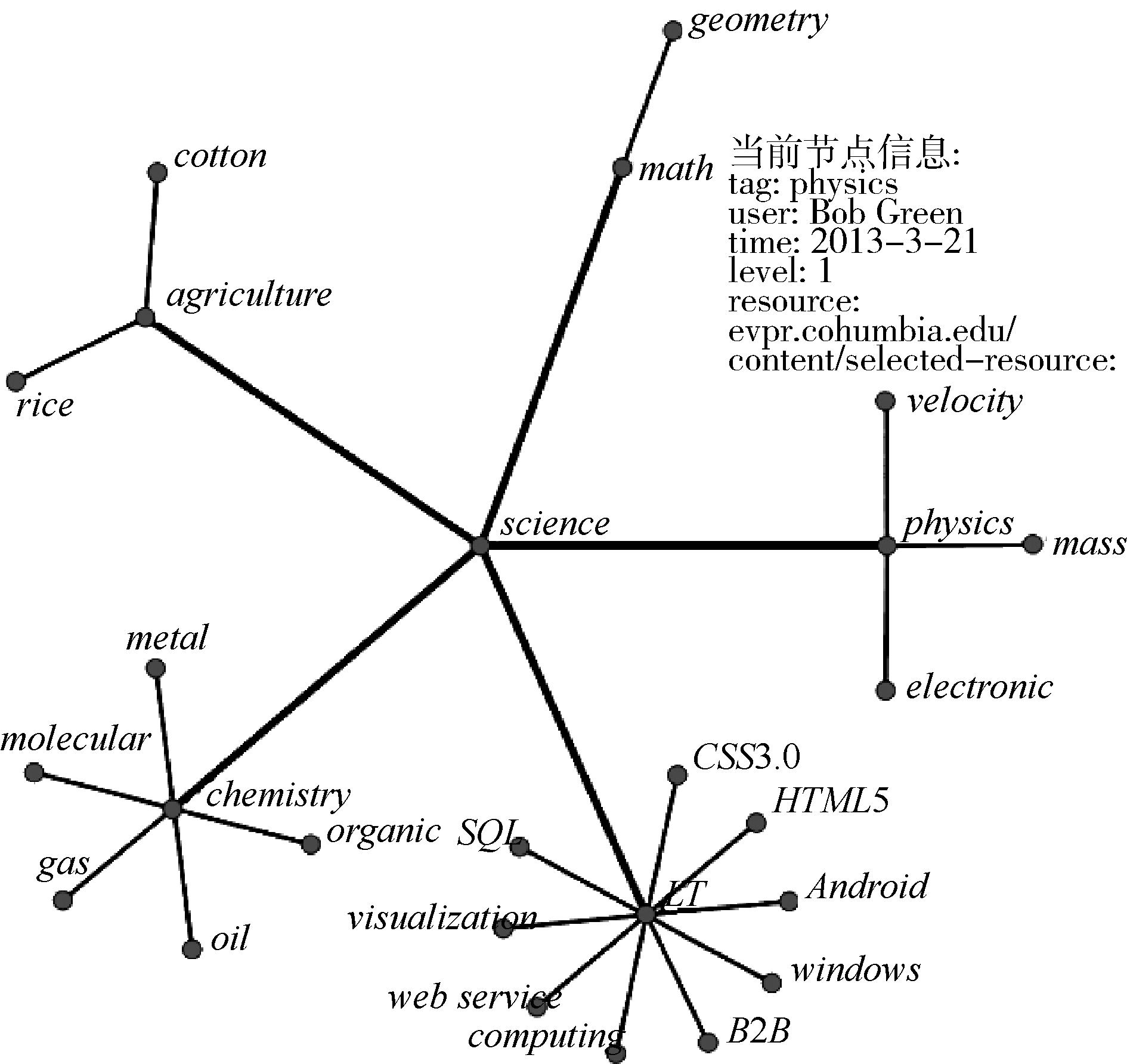 | 图6 大众标注层次可视化效果 |
本文首先对标签进行了五元组的语义表示, 然后利用归类方法使得标签之间产生层次关系, 基于基层结构的标签集, 提出一种布局算法对标签进行可视化表示。可视化结果有助于用户快速定位自己的位置, 增强对大众标注集整体结构的认知。
本文在以下三个方面值得进一步研究:
(1) 显示层次。从图5可以看到, 当显示层次达到第4层时, 用户感知信息已经变得困难。今后可以继续改进, 使节点具备自适应性[ 12], 当用户聚焦于某个节点时, 动态地布局该节点到显示区域中央作为根节点, 再分布其子节点、孙子节点于周围, 那么随着用户的聚焦点变化可以进入到更深层次当中。
(2) 细节显示能力。调整物体大小的能力和细节的显示程度, 是数据可视化的一项重要特性[ 13]。如果可以放大局部细节信息, 聚焦并放大用户感兴趣的区域, 不仅显著改善用户体验, 而且有助于用户进行深入的数据分析。
(3) 跨层次、多继承机制。社会化标注系统中, 知识关联关系中有较多的“跨层次”、“多继承”的关系, 这种关系会打破本算法的规则化布局, 为此, 探索“跨层次”、“多继承”的布局算法, 有利于更好地解决大众标注的可视化问题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|