

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
网络“水军”探测方法研究*
[王烁1 , 徐健1  , 刘颖
, 刘颖2 ]
, 刘颖|
|


作者贡献声明:
徐健:提出研究思路, 设计研究方案;
王烁, 刘颖:进行实验; 采集、清洗和分析数据;
王烁, 徐健, 刘颖:论文起草;
徐健:论文最终版本修订。
【目的】针对网络“水军”所引发的网络信息失真问题, 提出“水军”探测方法, 从宏观上探测出“水军”。 【应用背景】对网络上电影、音乐、书籍等的在线评分进行统计分析, 识别出存在“水军”刷分现象的对象。【方法】从宏观上提出基于正态分布拟合的静态探测方法及基于时间序列法的动态探测方法进行“水军”探测, 并设计反映某一天评论数量相对于总体情况波动的“水军”强度指标。【结果】对“豆瓣电影网”2012年的近千部电影进行探测, 将结果与部分媒体曝光的存在“水军”情况的电影进行相互印证, 证明上述方法的探测效果。【结论】“水军”静态及动态探测相结合的方法可以对网络上存在的“水军”现象进行探测, 但也存在评分数据量不足影响探测效果的局限等。
[Objective] The online “water army” causes the distortion of network information. The paper proposes two methods to detect water army. [Context] Use the methods to detect the “water army” existed on movie website, e-commerce website and so on. [Methods] The paper proposes static and dynamic methods to detect water army, and designs an intensity index to show the fluctuations of the number of reviews relative to the overall in one day. [Results] The paper uses mining technology to collect rating data of Douban movie site, then analyses the ratings to identify the “water army”, which verifies the effectiveness of two detection methods. [Conclusions] The combination of the static and dynamic detection methods can detect the existence of “water army” phenomenon effectively. But it also has some limitations, for example, the insufficient rating data affects the detection.
在信息时代的今天, 网络成为人们主要的信息来源, 而面对海量的信息, 人们本来就很难分辨哪些是真实的信息, 加上网络“水军”的影响, 网民们将更难捕获到真实的网络信息。网络“水军”是指受雇于幕后炒作者, 为他人在各大论坛、评论网等发帖、回帖、评分等, 以达到“造势”目的的网络人员[ 1]。有关网络“水军”的报道频繁见于报端。近期新华网有报道《三星“水军”营销遭曝光: 诋毁对手被罚千万台币》[ 2], 此外, 2012年末, 《一九四二》和《王的盛宴》两部大片的竞争, 片方正式向记者媒体公开了利用“水军”炒作的事实, 电影业利用“水军”炒作也成了公开的秘密。网络“水军”泛滥正在损害着互联网的公信力。此外, 网络“水军”的存在, 使得网络挖掘得到的信息正确性得不到保障, 这阻碍了网络评论等相关研究的进展。而目前又较少见到“水军”探测的相关技术, 所以本文从静态和动态两方面提出了“水军”探测方法, 静态方面分析网络评论或评分数量总体波动情况, 动态方面用时间序列分析法分析网络评论或评分随时间的波动情况, 以期较好地解决上述问题。
关于“水军”的网络议论较多, 而相关学术研究相对较少, 与“水军”探测比较密切相关的领域是网络垃圾探测和网络评论过滤。
在网络垃圾探测方面, 王淑敏等[ 3]提出通过基于社交蜜罐技术的分类器, 反复探测垃圾信息发送者的信息并加以限制, 能够有效地减少垃圾信息的数量; 隆承志等[ 4]在垃圾邮件过滤方面提出了基于特征共享的垃圾邮件管理系统, 实现对垃圾邮件特征的全网同步共享, 可以有效提升垃圾邮件防范的实时性, 提高垃圾邮件过滤效果。网络垃圾探测与“水军”探测都致力于识别出网络中的异常信息, 但是它们的目的、方法都有所不同。网络垃圾探测利用文字信息的特征剔除虚假、反动、色情信息及广告等, 还原一个干净的网络; 而“水军”是模拟正常用户制造大量伪造信息, 这些信息具有高仿真性, 不同于一般网络垃圾, 特别是网络评分方面, 没有文字特征, 传统的网络垃圾探测方法不适用于探测“水军”情况。
在评论过滤方面, 国内外都有许多针对网络用户评论的有用性的研究。Chen 和Tseng[ 5]提出了评价在线商品评论质量的9 个维度, 并构造多类支持向量机模型对在线评论进行分类, 从而区分高质量的评论; Liu等[ 6]提出根据领域知识对评论进行特征提取, 从而获得信息价值高的评论集合; 苏雪佳[ 7]从评论者、评论阅读者、评论本身、评论发表时间4个维度来构建在线评论有用性影响因素指标, 分析在线评论有用性的具体影响因素等; 江海洋[ 8]提出将用户评论中被用户关注的层面发掘出来并评分, 然后机器学习得出用户的偏好, 最后根据用户的偏好预测其他用户评论的分数并产生推荐的协同过滤方法。由上述研究可以看出, 评论过滤的方法主要是根据评论的一些相关信息如时间、地点、评论者等制定相关维度进行筛选, 或根据评论本身内容进行分类、特征提取获取信息价值高的评论。评论过滤和“水军”探测两者存在不同: 目的上, “水军”探测是为了识别出存在“水军”现象的对象, 评论过滤更多的是作为意见挖掘等领域的一个步骤, 来达到数据筛选的目的; 手段上, 评论过滤更多的是基于评论的各种相关信息进行过滤, 而“水军”探测是对网络“水军”的一个宏观层面上的探测, 不针对具体的某个评论。另一方面, 评论过滤旨在剔除信息价值低的评论, 保留其他高信息价值的信息以供研究分析, 而“水军”刷评论有人为评论或机器自动评论两种, 但评论内容和普通用户评论几乎没差别, 这些信息也蕴含有信息价值。
综上所述, 目前较少有直接针对“水军”的研究, 现有研究也只是停留在网络热议层面, 而较少涉及“水军”探测方法和指标的深入研究。本文针对上述情况, 对网络评论的正常规律和“水军”出现的特征进行分析, 提出了“水军”探测方法, 旨在利用统计学和信息分析的手段, 实现对网络“水军”的有效探测。
网络“水军”探测可从静态分析和动态分析两个方面进行, 静态方法主要利用正态分布拟合法进行探测, 动态方法主要用时间序列法进行探测。这两种方法都是在深入分析正常的评论情况及“水军”出现时引发的数据异常波动后提出的。
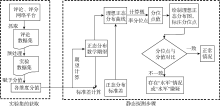
“在自然现象和社会现象中, 大量随机变量都服从或近似服从正态分布”[ 9], 而网络评论和评分的统计分析, 属于社会学统计分析, 经过前期观察, 其数量按差评到好评的分布规律也符合正态分布。然而, 受到“水军”干扰的网络评论数量, 会出现违反正态分布的情况。这是由于“水军”具有“倾向性明确”的特点, 要么恶意拉低评分, 让有查看欲望的人看到评分、评论后止步; 要么一味好评拉高评分, 吸引更多人前去查看。所以, 正态分布规律之外的情况就有可能是“水军”造成的波动。针对这种“水军”导致的异常波动, 本文提出基于正态分布的静态探测方法, 对网络评论和评分的倾向性进行正态分布拟合, 筛选出不符合正态分布的情况。静态方法探测步骤如图1所示:
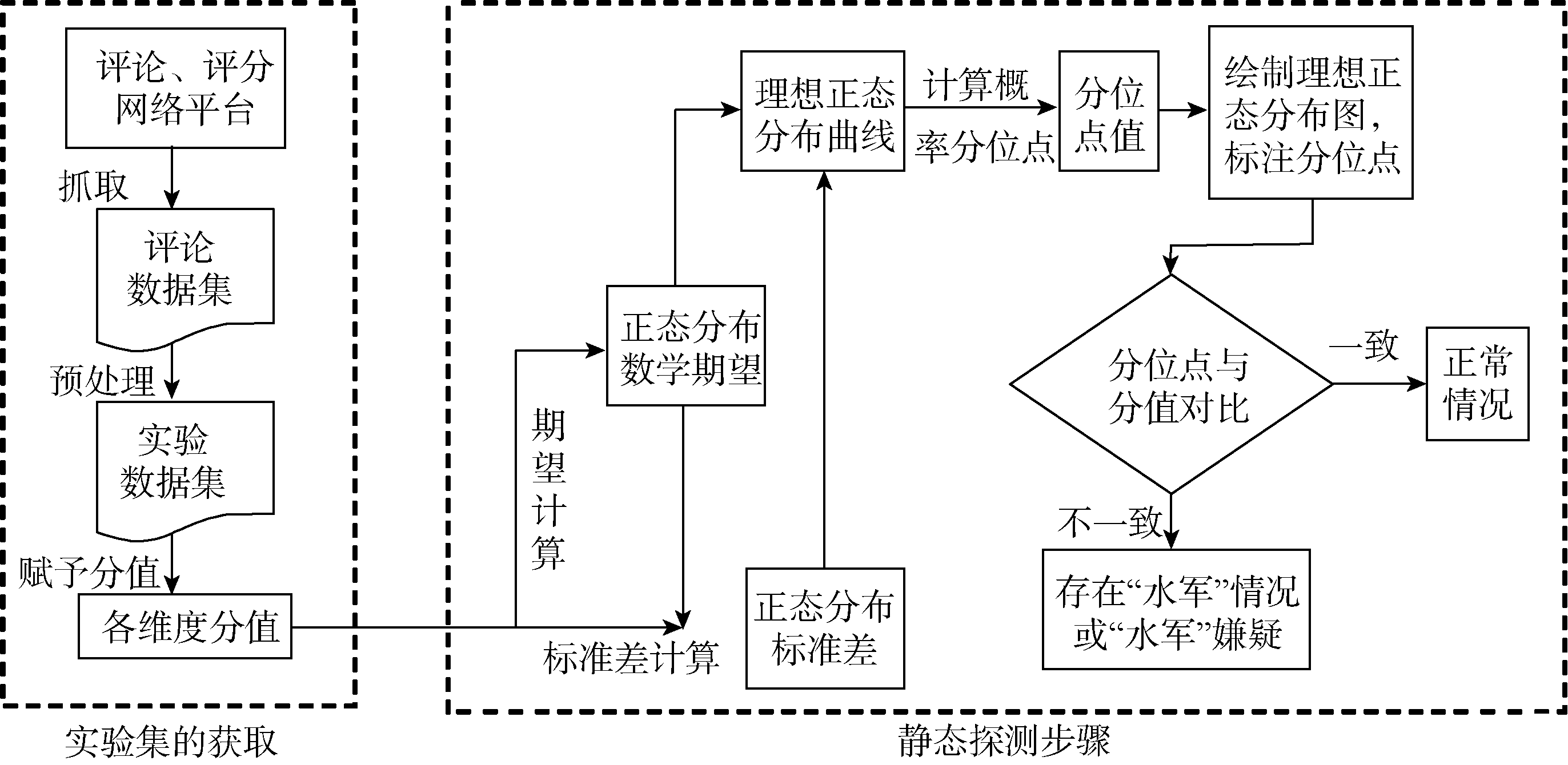 | 图1 静态方法探测步骤 |
静态探测方法的具体探测步骤如下:
(1) 将每个评分等级从差评到好评依次以从1开始递增1的方式赋予分值。
(2) 根据每个等级的分值及其数量的比例, 计算正态分布的数学期望μ[ 9]:
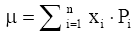 | (1) |
其中, xi代表各等级分值, Pi代表各等级评分或评论数占总数的百分比。
(3) 利用计算得到的数学期望, 计算标准差σ[ 9]:
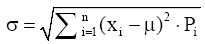 | (2) |
其中, xi, Pi, μ的意义与公式(1)相同。
(4) 在计算出数学期望μ和标准差σ的前提下, 得到正态分布函数[ 9]:
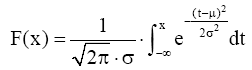 | (3) |
其中, μ为正态分布的数学期望, σ为正态分布的标准差。
(5) 将实际的评分或评论数占总数的比例按等级从低到高累加:
 | (4) |
其中, Pi代表各等级评分或评论数占总数的百分比, n为自然数。
联立公式(3)、公式(4)可以求得各评分比例在理想正态分布函数下的分位点xi, 如下:
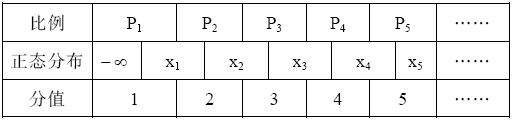 |
Pi代表各等级评分或评论数占总数的百分比, xi是通过上述计算得到的、在理想正态分布情况下各比例Pi的分位点, 分值是静态方法步骤(1)中对评论或评分由差评到好评依次赋予的分值。根据正态分布规律, 原始拟定的分值应该和正态分布分位点的范围是一一对应的。例如: 1分落在- 
静态探测方法是基于评论总数量进行的总体探测, 而动态探测方法是根据评论或评分随时间的变化情况对“水军”行为进行探测, 本文采用时间序列分析法。时间序列分析法[ 10]是通过对历史数据变化的分析来总结事物规律, 评价事物现状和估计事物未来变化的方法。
基于评论时间序列上的“水军”探测可以从每种评分的比例及随时间的变化趋势入手, 根据各种评分的数量分别绘制曲线, 在基数足够大的情况下, 各种评分的比例会一直稳定在一个值附近, 也就是说每种评分的概率是稳定的, 随着时间变化, 其数量变化应该一致。一旦某种评分出现与其他评分明显不同的数量变化趋势, 便可以识别到“水军”活动。
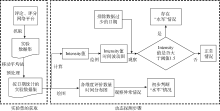
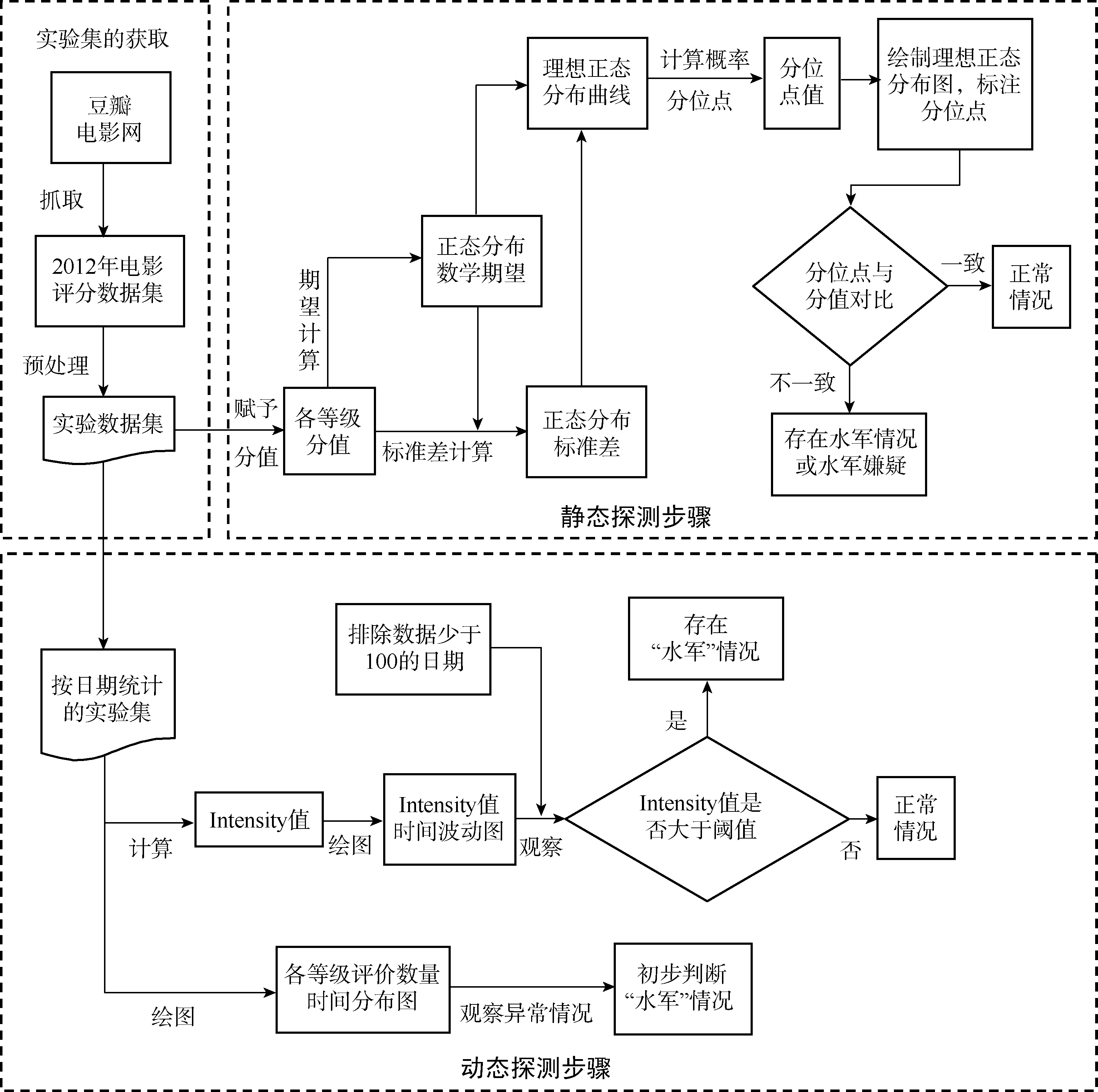
动态方法探测步骤如图2所示。动态探测方法的具体步骤如下:
 | 图2 动态方法探测步骤 |
(1) 数据预处理
根据初步分析, 时间分析法要排除一些因素的影响, 例如周末、节假日、舆论事件等, 之后得到的时间曲线才是适用于分析的曲线。本文用移动平均法进行曲线修匀。移动平均法[ 10]的基本方法是每次在时间序列上移动一步, 求n个数据的平均值, 这样的处理可以对原始数据进行修匀, 消除样本序列随机成分的干扰, 突出序列本身的固有规律, n是每个时间段内的数据个数, 称为移平跨度。计算公式[ 10]如下:
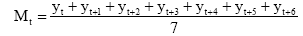 | (5) |
其中, yt表示第t天的某种类型评论或评分数, Mt表示修正后当天的数值。由于消除的是周末数据波动的干扰, 所以n值选为7, 即一周的天数, 这样修匀后, 数据波动基本不受“周末”这一因素的影响。
(2) 初步数据分析
根据步骤(1)得到的数据, 绘制时间- 数量波动图, 观察数据波动异常情况。理论上, 时间轴上每个时间段内每种评论、评分占总评分的比例应该接近于整个时间段的平均比例。一旦发现某段时间内某种评论或评分的比例远超过正常值, 则可以初步断定该评论或评分存在“水军”情况。
(3) 计算“水军”强度指标
为了更准确地判别“水军”情况, 本文提出用于计算某一天“水军”强度的指标Intensityi, 定义如下:
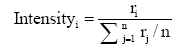 | (6) |
其中, n表示样本所选取的n天, ri、rj分别表示第i天、第j天某一分值的评分数量占当天评分总数的百分比。此指标反映了某一天的评论数量相对于总体的波动。若是某一天的“水军”强度Intensity值超过阈值, 则有明显的刷分情况。该指标在不同领域有不同的阈值, 且其探测效果受限于评分的数据量, 一旦数据量过小, 则容易出现较大误差。
本实验通过收集豆瓣电影网[ 11]的数据, 利用静态、动态方法对部分电影进行“水军”探测, 通过实验情况与媒体曝光“水军”刷分情况相互印证, 证明本文提出的方法具有可行性和准确性。实验步骤如图3所示。
本实验选用豆瓣电影网[ 11]2012年的1 000部电影作为分析对象, 实验目标是从大量电影中探测出存在“水军”情况的电影。
利用Java编程, 对豆瓣网页进行抓取, 并分析HTML结构, 获取每部电影的评分情况(包括平均评分、评分总数量及“1星- 很差”至“5星-力荐”5个评分等级各自的评分百分比), 并将评分情况存入数据库中; 以及对《王的盛宴》、《一九四二》、《青春期3》等若干部电影的短评内容、评价时间、评分等信息进行抓取并存入数据库中。最终得到的实验集包括2012年豆瓣电影网1 000部电影评论总数、各个等级的评分数据以及若干部电影的短评内容、评价时间、评分等信息。数据库部分数据展示如表2所示。
| 表2 实验集部分电影评分数据 |
本文对实验集中2012年评分数量较多的900多部电影进行静态分析, 步骤如下:
(1) 由于豆瓣影片的评分从“1星很差”至“5星力荐”分成5个等级, 根据静态方法的步骤, 先分别对1星到5星的评分赋予1到5的分值。
(2) 利用统计工具Excel的函数功能, 根据公式(1)、公式(2)计算正态分布的数学期望和标准差, 绘制理想的正态分布图。
(3) 利用Excel中的函数功能, 根据各评分的比例计算理想的正态分布分位点, 再与实际的分值进行比较。
部分电影的静态探测分位点结果如表3所示。
| 表3 部分电影静态探测分位点结果 |
通过对900多部电影静态探测结果的观察, 对静态探测结果大致分为以下三种类型:
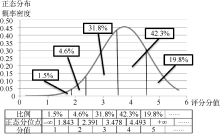
(1) 正常分布型: 范例电影——《人再囧途之泰囧》
由图4可见, 《人再囧途之泰囧》的豆瓣评分情况是符合正态分布的, 每个分值都落在理想正态分布的概率分位点之间。即根据理想的正态分布, 有1.5%的评分者评分在0到1.843之间, 虽然网络评分的分值是不连续的, 但本文在计算正态分布函数前规定了最差评的“1星很差”为“1分”, 即可以理解为评分在0到1.843之间的评分者都选择了1分的评价, 所以实际评分为1星的比例符合正态分布; 同理, 根据理想正态分布, 有4.6%的评分者评分在1.843到2.391之间, 而“2星较差”被规定为“2分”, “2分”落在1.843到2.391之间, 且接近其中值, 所以2星评分也符合正态分布; 同理, 3星、4星、5星都符合正态分布。所以, 《人再囧途之泰囧》的豆瓣打分情况总体上符合正态分布。
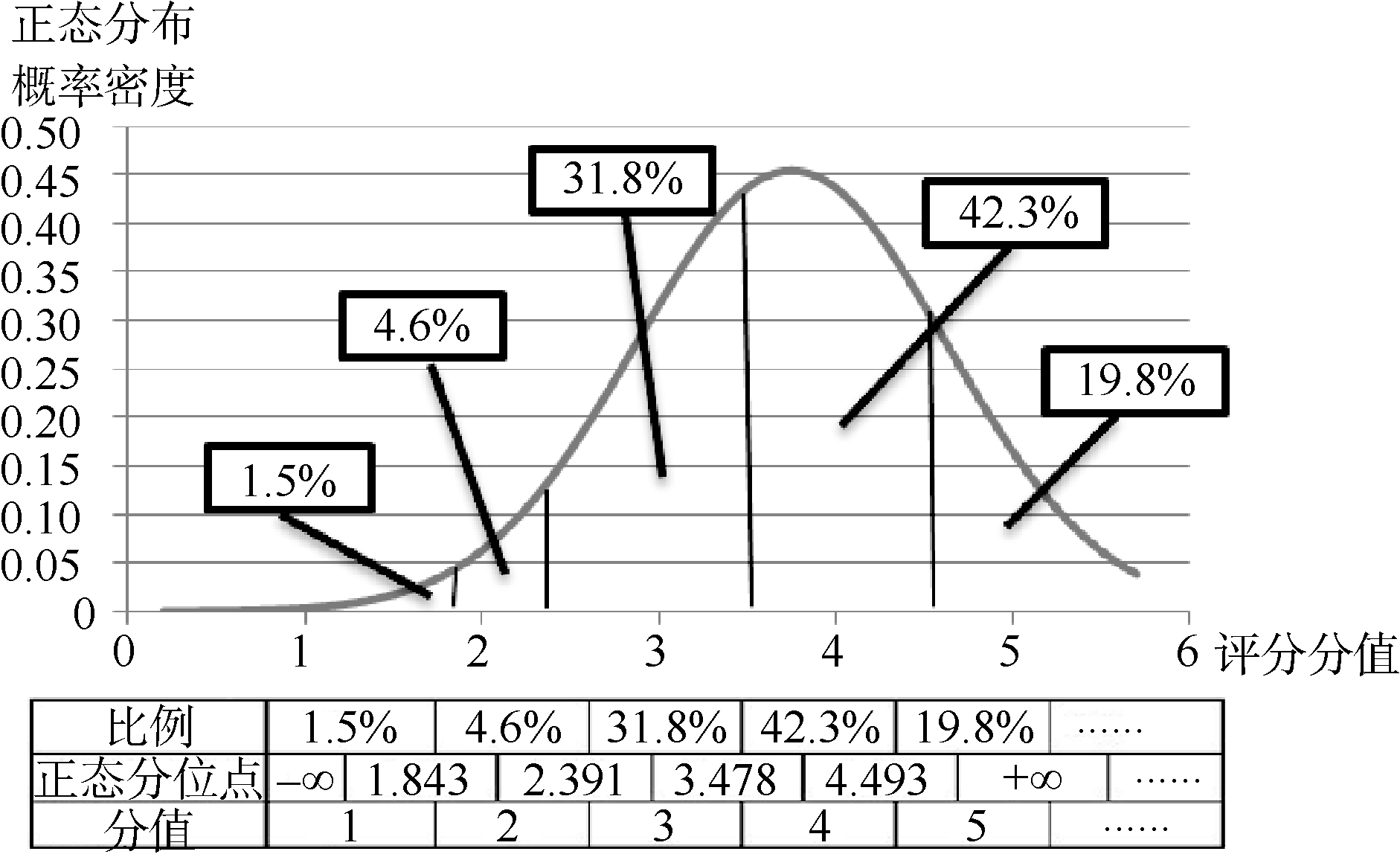 | 图4 《人再囧途之泰囧》电影评分正态拟合图 |
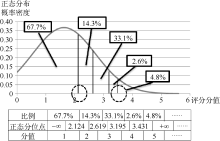
(2) “水军”影响型: 范例电影——《一九四二》
从图5可知, 《一九四二》的评分情况大致符合正态分布, 但如虚线圈所标注位置所示, “1星很差”的上分位点为1.944, 这个值相当接近于2, 所以“1星”评分存在较大的刷分嫌疑, 但由于《一九四二》评分数量达到94 504条之多, 对刷分情况有修复作用, 因此上分位点值才不会明显地超出2。
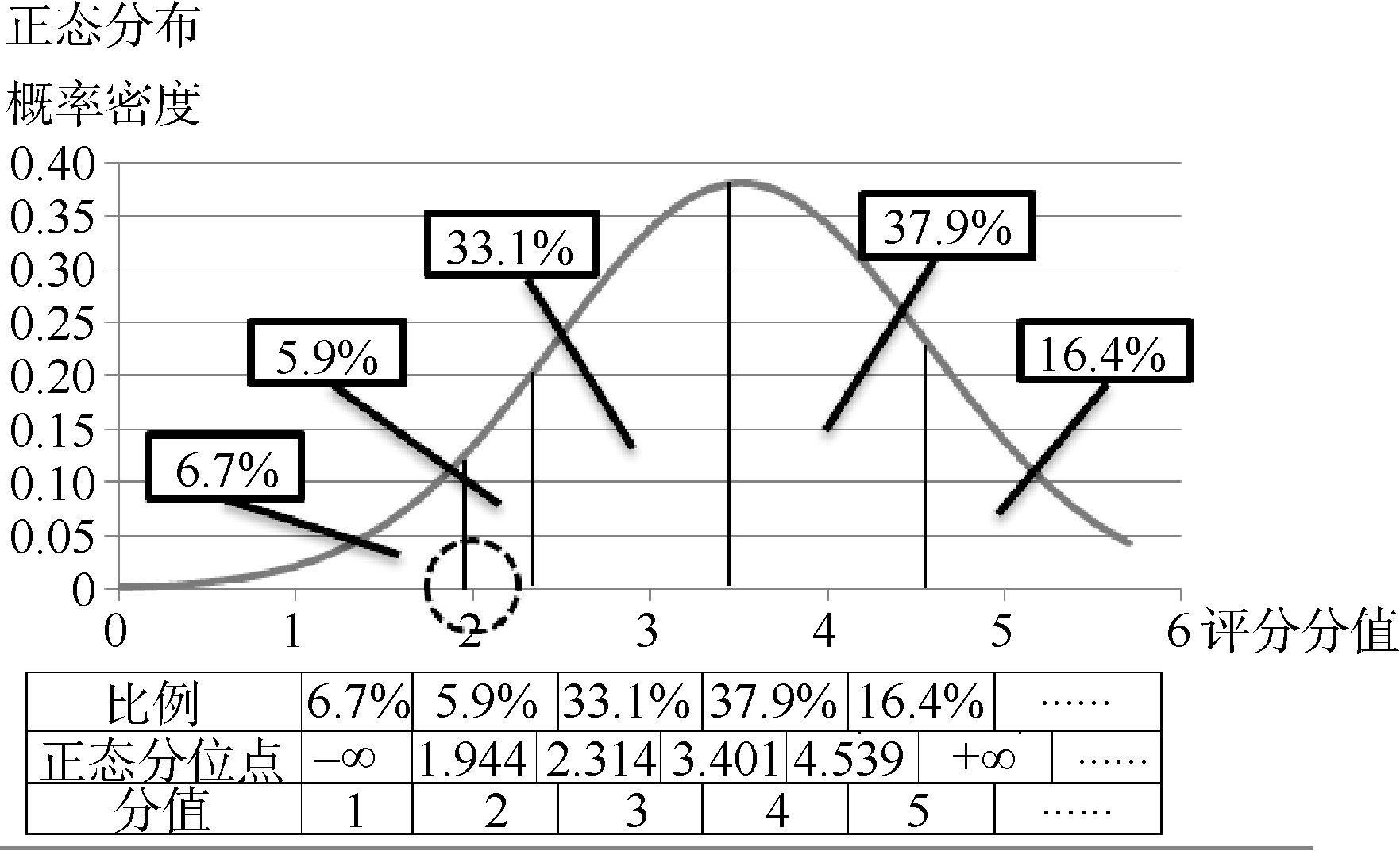 | 图5 《一九四二》电影评分正态拟合图 |
(3) “水军”情况明显型: 范例电影——《快乐到家》
观察图6可知, 电影《快乐到家》的“1星很差”评分的上分位点大于2、“5星推荐”的下分位点小于4, 所以这两个评分都存在刷分的情况。
 | 图6 《快乐到家》电影评分正态拟合图 |
对豆瓣的电影评分进行研究发现, 只有短评的评分情况可以获取到每个评论的日期, 所以本实验所采用的数据是豆瓣电影短评的评分数据。
(1) 评论数量波动情况
先根据公式(5)对数据进行修匀的预处理, 每天的评分数等于从当天算起连续一个星期的评分数量的平均值。然后对每种评分的数据根据时间变化绘图, 如图7所示。
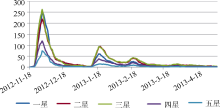
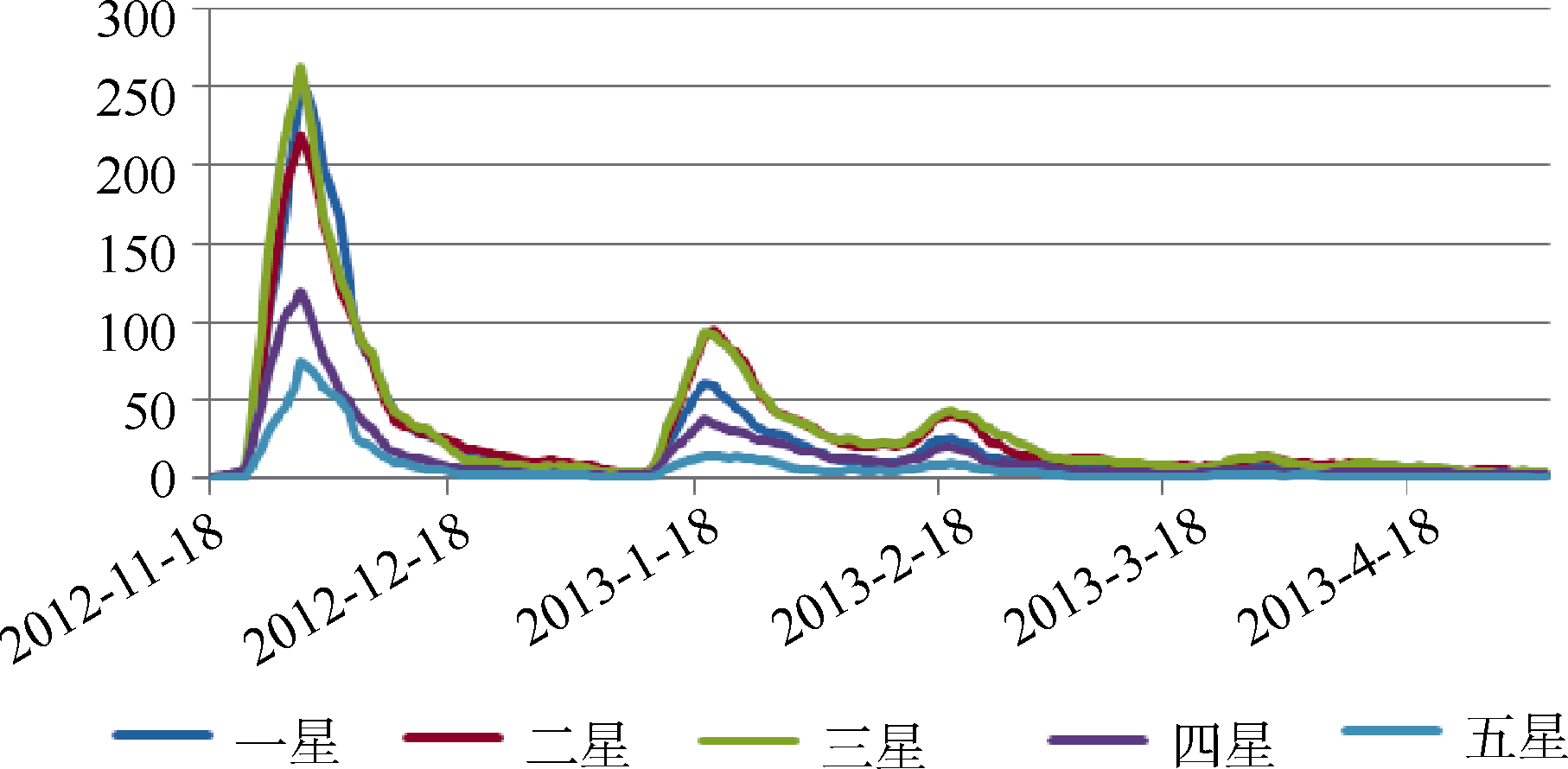 | 图7 《王的盛宴》各评分随时间的变化趋势图 |
理论上, 每个时间段内每种评分占总评分的比例应该接近于全部时间总评分数量的比例, 即静态探测方法中从网页上直接获得的分数比例。所以一旦识别到某一时间段内, 评分的比例与总体评分比例有较大差异, 则可以探测出“水军”情况。通过观察可以发现, 影片刚上映时, 明显存在刷1星差评的现象。1星与3星的评分数量相近, 甚至超过3星评分的数量, 而在后续的曲线中, 都是2星、3星最多, 1星次之, 而且1星评分数量大概为2星、3星评分数的一半, 由此可以判定在上映初期存在“水军”情况。
(2) “水军”指标Intensity值
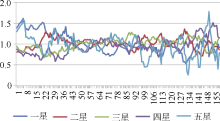
通过上述方法中的公式(6), 计算电影《王的盛宴》的Intensity值并分析, 如图8所示:
 | 图8 电影《王的盛宴》的Intensity值的时间序列图 |
此处选取n=1为影片上映日2012年11月29日, 经过实验总结, 每天的评分总数量超过100条时, 此指标更加准确。所以, 分析时只选择前半段曲线(2013年2月25日之前), 因为后半段曲线评分数量较少, 误差较大。2012年12月20日至2013年1月18日期间, 由于每天的评分总数量不及100, 也不列入观察范围。即只考虑n=1至22, n=50至88范围内的曲线。观察曲线可以得出, 在开始上映后的前7天里, 5星评分和1星评分的强度都在1.5左右, 随后1星评分强度锐减, 最终在1左右波动, 5星评分则持续了21天才开始锐减, 最终也是平稳波动在1附近。而2星、3星、4星的比例, 一开始波动于0.75左右, 最后也是稳定波动于1, 一开始这几种中间等级评分强度较低, 可以解释为: 由于5星和1星评分数量被“水军”刷高, 所以导致中间等级的评分的Intensity值相对降低。
对于媒体曝光的存在“水军”情况的电影《一九四二》和《王的盛宴》, 用静态方法分析《一九四二》的评分情况, 其属于“水军”嫌疑类型, 用动态方法探测则可以探测出明显的“水军”情况; 《王的盛宴》用静态方法探测是符合正态分布规律的, 但在动态方法探测时探测到明显的“水军”情况, 这说明总体评分的“水军”情况随着时间推移、评论数量变多, 其“水军”造成的违反正态分布情况会慢慢被修复, 甚至几乎和正常情况无较大差别, 但是在动态方法探测下, 其“水军”情况还是可以被探测。所以, 这更加印证了上文, 探测“水军”情况应该将静态方法和动态方法有机结合, 静态方法做粗略的探测, 然后动态方法进一步发现并确认“水军”情况以及确定“水军”强度。
根据实验可知, 静态方法、动态方法从不同角度探测“水军”情况, 都能取得良好的探测效果, 但也有一定的局限, 各自的优势和劣势如表4所示。
| 表4 静态方法与动态方法的对比 |
综上所述, 静态方法与动态方法各有优劣, 探测“水军”情况应该将两者有机结合, 静态方法做粗略的探测, 找到存在“水军”嫌疑的电影; 动态方法进一步发现并计算“水军”强度, 以此探测刷差评或者刷好评的“水军”情况, 这样两种方法可以互相补充, 弥补各自的误差, 达到更好的探测效果。
本文通过对网络评论、评分数量在正常情况下的规律分析及出现“水军”情况时的异常波动分析, 提出了拟合正态分布的静态探测方法及根据时间序列进行“水军”探测的动态探测方法, 并提出静态方法的具体拟合计算流程及动态方法的“水军”强度指标。通过相关实验及结果分析证明上述方法是有效的。但是, 这两种方法都还存在一些局限, 例如数据量过少可能会影响探测结果, 如未来能将该方法应用于更大规模的数据集, 应能得到更好的效果。此外, 若结合评论内容进行更深入分析, 则可能得到更好的探测效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|