
{kind=link}
{kind=link}
{kind=link}
基于社会标签的中文图书自动分类研究
[何琳1  , 万健
, 万健2 , 何娟1 , 郭诗云1 ]
, 万健|
|


作者贡献声明:
何琳: 提出研究思路, 设计研究方案, 修订论文; 万健: 提出研究思路, 修改论文; 何娟: 采集、清洗和分析数据, 起草论文; 郭诗云: 采集数据及数据测试。
【目的】通过对社会标签的规范控制, 提高社会标签质量, 提升其在文本自动分类中的能力。【方法】提出一种“内核受控, 外壳非控”的分类模型, 通过建立“社会标签-主题词”概念空间, 实现利用主题词对标签词的规范控制。【结果】实验结果表明本文提出的基于社会标签的中文图书自动分类方法在综合考虑成本、效率和效果的前提下, 具有较强的可行性。【局限】数据获取数量有待进一步增加, 同时“社会标签-主题词”概念空间中概念之间深层次语义关系的识别还有待完善。【结论】为提高社会标签质量、提升其文本自动分类能力, 提供一种可行方案。
[Objective] The paper aims to improve the ability of automatic text classification of social tagging by controlling the relation and quality of social tagging.[Methods] A classification model called “core controlled, shell uncontrolled” is constructed based on the control of a concept space called Social tagging-Keyword in order to realize the regulation control of social tagging based on subject headings.[Results] The validity tests show that this new method has a better performance on the text classification based on social tagging in consideration of efficiency and the cost.[Limitations] The data used for concept space is not as much as possible due to the restriction of the Website. Also, the concept space is lack of deep semantic relations which would be richer in the future.[Conclusions] This study proposes a feasible solution for improving the quality of social tags and the capacity of automatic text classification.
社会标签类似于传统信息资源组织中的关键词或元数据, 其产生于网络环境, 创建于大众用户, 其中蕴含了丰富的语义信息, 将其运用到网络信息资源的组织中具有一定的现实意义。然而由于社会标签在被添加时过度自由与随意, 使得社会标签的质量良莠不齐, 如缺乏语义层次, 同义、近义关系频现, 标签词间关系不明确等。这些都影响社会标签在文本分类应用中的效果。因此, 本文在对中文图书标签的特征进行分析的基础上, 借鉴情报语言学原理提出一种基于社会标签的“内核受控, 外壳非控”的中文图书自动分类模式, 即通过建立社会标签-主题词的概念空间模型, 实现利用主题词对社会标签进行规范控制, 基于转换后的主题词对中文图书进行自动分类, 进而提升基于社会标签的信息组织能力。
自从社会标签产生以来, 研究人员就试图将这种“用户产生的标引词”用于文本分类之中, 围绕社会标签的规范控制以及社会标签应用于文本自动分类开展研究。
目前, 对社会标签进行规范控制处理的研究大致可以分为两个方面: 挖掘社会标签内部的语义关系; 将社会标签与传统的知识组织系统进行融合。
(1) 社会标签的语义关系挖掘
通过挖掘社会标签的语义关系实现对社会标签的规范控制, 主要思想是通过聚类或社会网络分析等方法, 建立社会标签之间的等级层次关系, 将社会标签原本扁平化结构改造成为类似于传统知识组织系统的、具有上下位类关系的等级层次结构。如曹高辉等[ 1]在Begelman等[ 2]的谱平分聚类方法和Heymann等[ 3]的图论聚类思想上进行扩展, 提出基于凝聚式的社会标签层次聚类算法。Christiaens[ 4]通过聚类的方法层级化社会标签的表现形式。通过社会网络分析, 易明等[ 5]对标签共现网络中的点、线、密度和中心性等指标进行分析。李亚婷等[ 6]进行基于社会标签共现的社会网络分析研究。
(2) 社会标签与传统知识组织系统的融合
融合方法的主要思路是利用规范的受控词汇对不规范的社会标签词进行约束, 从而提高社会标签的质量。如任家乐等[ 7]实现了美味书签网站中的社会标签与OPAC数据库中的主题词之间的兼容互换。但这只是简单地通过链接的方式实现两者之间的交互访问, 并没有真正意义上实现用受控词约束标签词。类似的研究还有Quintarelli等[ 8]在其自主创建的FaceTag网站上建立了社会标签与受控词汇的交互式链接。
Munk等[ 9]指出, 社会标签的本质是用户自主创造的、描述性的元数据在文本的标注和分类中的应用。这表明社会标签的一个具体应用是用于文本的自动分类。基于社会标签的自动分类研究, 主要集中在以下两个方面:
(1) 社会标签用于自动分类的有效性验证研究
社会标签产生于网络环境, 能够体现网络环境下信息资源的特点。因此, 从理论上讲, 将社会标签应用于网络信息资源的自动分类具有可行性。已有学者对其进行实证研究, 如Berendt等[ 10]以博文为研究对象, 比较以社会标签、文章标题和文章主体作为特征词的分类效果, 发现将社会标签和文章主体相结合作为特征词的分类精度优于只以其中任意一个类型的词汇作为特征词的分类精度。类似的研究还有Sun等[ 11]对比了基于社会标签、社会标签结合博文摘要以及博文摘要三者的分类结果。最终指出, 基于社会标签结合博文摘要的分类精度最高, 而基于社会标签的分类效果也比基于博文摘要的分类效果要好。与上述两者以博文为研究对象不同, Razikin等[ 12]以网页作为分类对象, 利用美味书签中的社会标签对网页进行分类。实验分成两组, 一组只使用网页上的文档词汇; 另一组则加上社会标签, 实验结果发现并不是所有的社会标签都适用于资源的发现。
(2) 基于社会标签的自动分类算法改进研究
丛鲁丽[ 13]将社会标签应用到中文博客的分类中, 提出一种基于社会标签的新型分类算法, 该算法以支持向量机分类算法为基础, 用于判断社会标签是否适合于对某个信息资源进行标注。另外, 李劲等[ 14]也提出基于社会标签质量的文本分类模型框架, 研究出一种基于社会标签的文本分类改进算法以提高网页分类的效果。虽然社会标签在灵活性上要远远优于传统的知识组织系统, 但从目前的实践来看, 社会标签在文本自动分类中的应用效果还不是十分理想。
以上研究表明, 社会标签虽然是用户对网络信息资源的一种分类或标引, 但其中蕴含丰富的语义信息, 因此将社会标签应用到文本分类中具有可行性。目前已有学者进行基于社会标签的自动分类研究, 但普遍发现分类效果并非十分理想。究其原因主要在于社会标签产生于网络环境, 相比于传统的信息组织系统, 社会标签表现出更多的随意性与自由性, 缺乏统一的标准与规范控制, 从而导致大量垃圾标签的滋生, 影响其在分类应用中的效率。因此, 利用情报语言学原理, 对社会标签间的语义关系进行控制, 过滤大量无关标签, 可以提高社会标签的质量, 进而提升基于社会标签的文本分类的效果。
在进行基于社会标签的中文图书自动分类模式设计之前, 需要分析中文图书社会标签的特征, 以便有针对性地制定合理的规范控制方案, 提高中文图书的自动分类效果。
本文从豆瓣网搜集4 636本经济管理类图书, 共计32 885个社会标签, 对其进行特征分析。通过联机公共目录查询系统(Online Public Access Catalogue, OPAC), 检索出4 636本书对应的MARC数据, 获取其中的主题词记录进行主题词特征分析。对比分析所依据的关键词数据主要来自于中国知网(CNKI)数据库中“经济与科学管理”类目下的论文关键词数据集。
对比分析依据的主题词和关键词数据较为规范, 标签词数据质量较差, 中文标签中夹杂英文、日文、法文等字符, 简体、繁体编码混杂, 同时又含有大量无实际意义的符号。因此, 必须对这些混乱的标签词进行预处理, 以达到格式和编码上的统一, 从而方便后续的特征分析。具体的预处理包括外文字符的处理、去除多余符号、半角及全角转换、汉字编码转换以及垃圾标签的清除等工作。
(1) 社会标签词长分布
绝大部分社会标签的长度与大部分关键词一样, 词长在2-4个字符之间, 占所有社会标签的89.60%。这表明网络用户习惯于选择较为简练的词汇描述和组织某一信息资源。因此在一定意义上, 社会标签可以被视为一种特殊形式的关键词。社会标签与关键词词长分布的对比数据如表1所示:
| 表1 社会标签与关键词词长分布对比 |
(2) 社会标签使用量分布
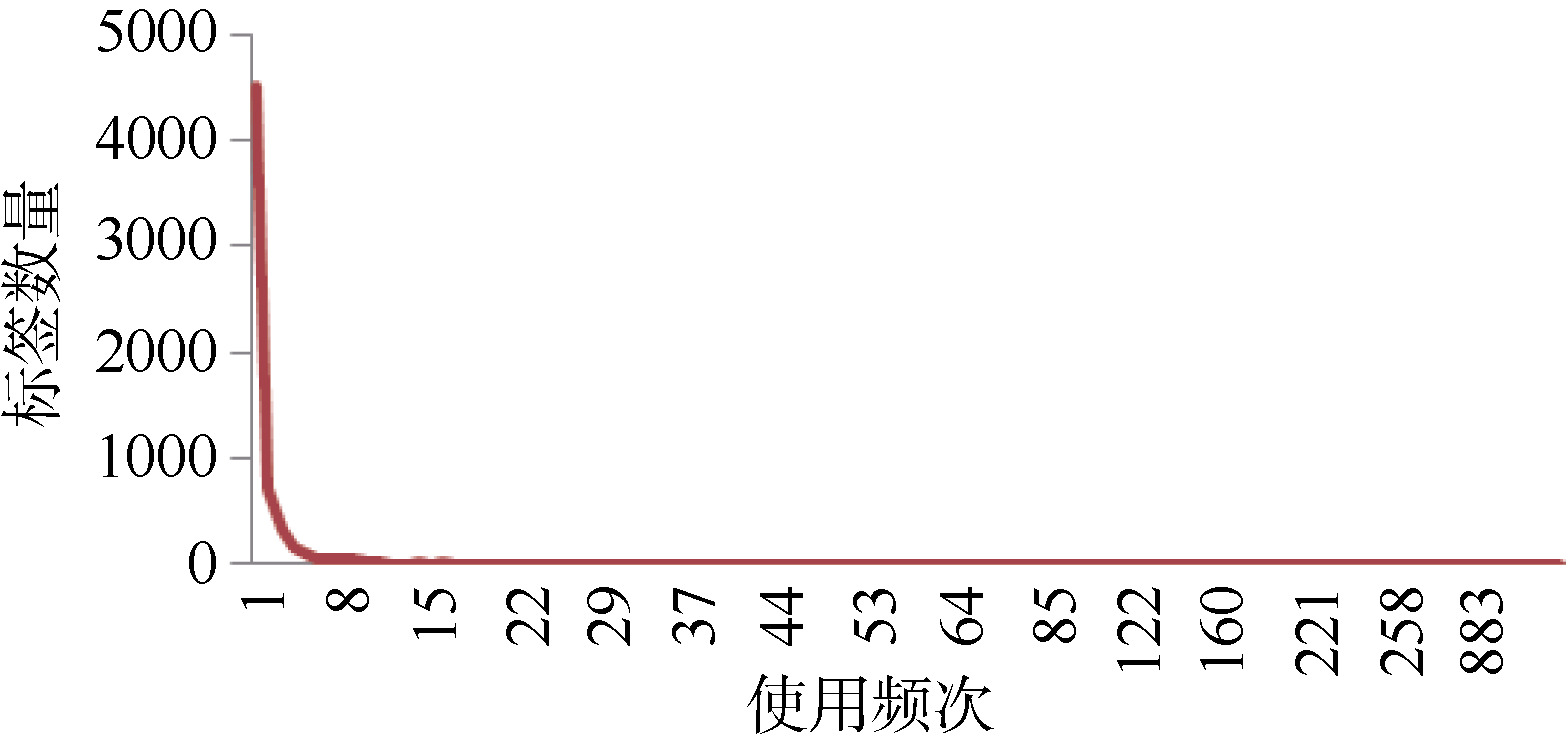 | 图1 社会标签使用量分布 |
如图1所示, 社会标签的使用量在分布上存在很明显的长尾效应, 其中存在着大量的低频标签词, 造成这一现象的主要原因是由于不同学科背景的大众用户的参与导致多样性的词汇大量滋生, 产生大量低频生僻冗余的标签。
(3) 社会标签的词频分布
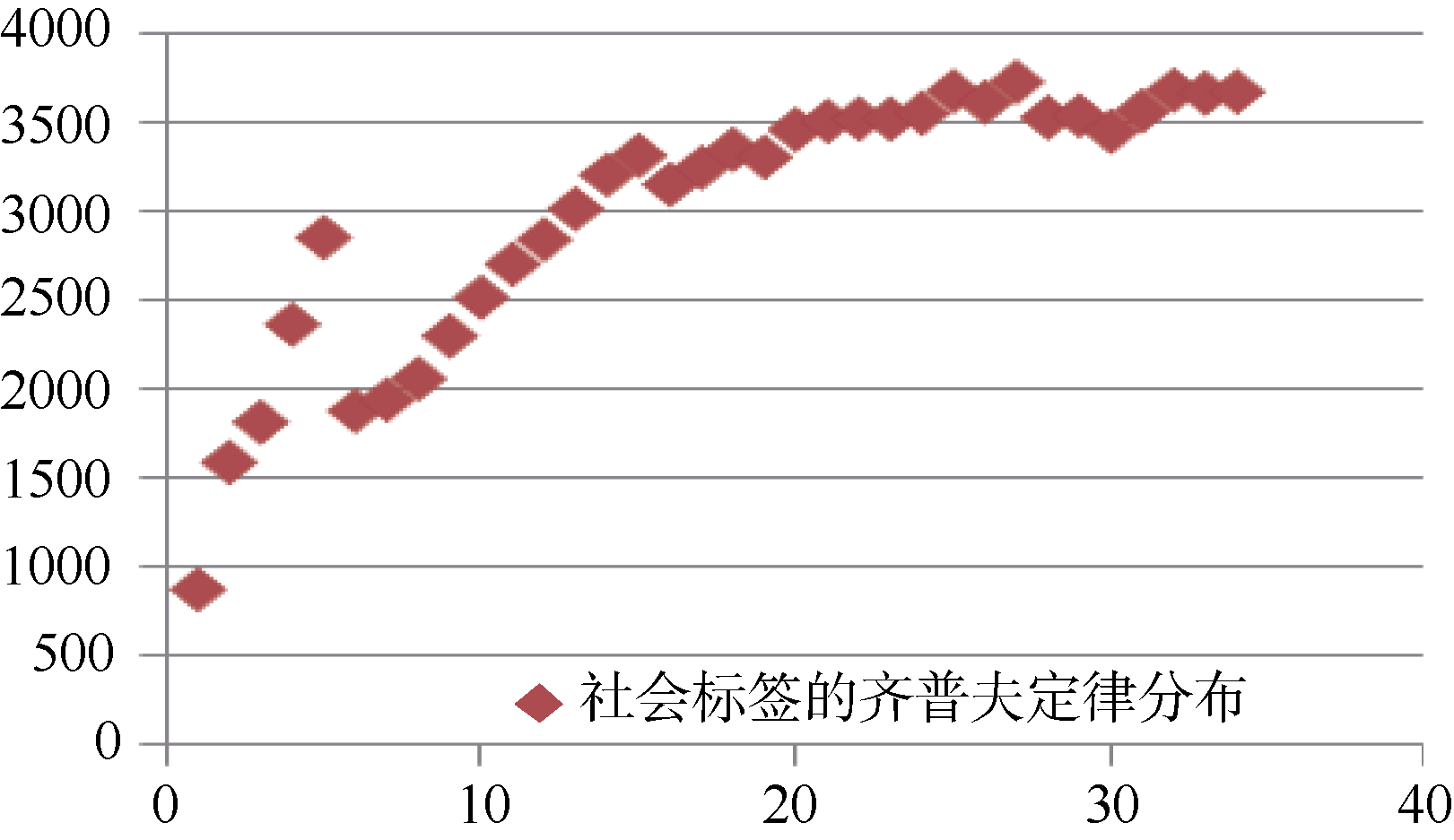 | 图2 社会标签的齐普夫定律分布 |
如图2所示, 横纵坐标分别代表标签词的等级编号及标签词的词频, 其乘积接近常数, 因此, 社会标签里的词频分布基本符合齐普夫定律。社会标签同关键词类似, 也具有自然语言的一般特性。因此, 可以将自然语言处理的方法运用到社会标签的处理中。
(4) 社会标签与主题词的对比
通过中文图书的ISBN号, 获取图书在OPAC数据库中的分类号及主题词, 对两者的收词量、平均词长、类平均标引深度以及完全匹配率等4项评价指标进行对比, 如表2 所示:
| 表2 社会标签与主题词的对比[ 7] |
(5) 社会标签特征分析小结
从上述对社会标签的特征分析中可以发现, 社会标签主要存在以下问题:
①社会标签的数量庞大, 种类繁多, 形式多样;
②社会标签的长度不一, 短则一个汉字, 长则没有限制;
③社会标签的使用存在很强的长尾效应。
因此, 社会标签作为一种对信息资源进行组织的新生代工具, 还存在很多不完善的地方。如较多的低频标签的出现, 会导致社会标签在实际分类应用中的训练维度过大, 进而影响分类的效率。但通过分析社会标签词长以及词频分布的情况可以发现, 社会标签与关键词十分类似, 长度同样集中在2-4个字符之间, 并且符合齐普夫定律, 表明社会标签可以被划为自然语言的范畴, 利用自然语言处理的方法对其进行分析处理。
另外, 通过对比发现, 虽然社会标签存在语义关系混乱、质量参差不齐等问题, 但社会标签也具有规模完备、检索入口丰富等优势, 在信息组织方面具有很强的潜力。主题词经过专家筛选具有高度的权威性, 尝试用主题词对社会标签进行规范不失为一种很好的方法, 但社会标签与主题词的匹配程度十分低下, 因此不能简单地用字面匹配的方法对社会标签加以约束, 需要寻求新的方法, 如通过统计方法建立社会标签到主题词的映射关系, 从而达到规范社会标签的目的。
通过对社会标签的特征分析可以看出, 社会标签作为一种新型信息组织工具, 在使用上具有很大的灵活性, 但同时也存在很多不足之处, 需要对其进行改进, 防止分类中混入过多垃圾标签而影响分类效果。
为了继续保留用户标注信息资源的便利, 在设计分类模型时需要考虑用户的需求, 做到以用户为中心, 延续用户原有使用规则的前提下, 在后台控制社会标签的质量。因此, 本文根据情报语言学的原理, 结合中文图书社会标签的特点, 提出一种“内核受控, 外壳非控”的自动分类模式, 如图3所示:
 | 图3 “内核受控, 外壳非控”的分类模式示意图 |
该分类模式的主要分类步骤如下:
(1) 在网络上利用爬虫软件获取原始图书的社会标签数据集合;
(2) 采用统计方法构建“标签词-主题词”概念空间, 作为社会标签规范控制的核心, 将社会标签进行规范化表示, 即对社会标签进行受控标引;
(3) 分类器的构建及分类算法: 学习过程: 选择适合的分类算法, 将中文图书的主题词进行分类训练, 得到主题词与类目的约束函数; 分类过程: 通过特征选择过滤中文图书的垃圾标签, 将特征标签与概念空间进行匹配, 得到社会标签的主题标引结果, 将匹配后的主题词输入分类器得到分类结果。
在“内核受控, 外壳非控”的分类模式中, 关键问题是社会标签的规范控制处理[ 15]。概念空间(Concept Space)是由情报学权威专家萨尔顿首先提出的, 指某一领域中概念的集合及这些概念之间的语义关联度[ 16]。构建概念空间的关键点在于计算词与词之间的相关度, 通过一定的关联算法计算出两者之间的相关性系数, 进而得出两者之间的关联关系。常用的关联算法主要有互信息、Dice测度、Jaccard系数等。本文选取Dice测度作为构建社会标签-主题词概念空间的主要关联算法, 原因在于Dice测度公式中各测度因素设置较为合理, 可以有效克服“零概率事件”和低频现象。
因此, 本文选取中文图书的社会标签与主题词数据, 运用Dice测度关联算法构建“社会标签-主题词”概念空间, 从而挖掘社会标签到主题词的最佳关联映射关系, 达到用主题词规范控制社会标签的目的。
面向中文图书社会标签的自动分类分为两个过程, 首先对图书标签进行规范控制处理, 然后再选择分类算法, 进行分类器的训练与测试。根据情报语言学原理, 概念间存在等值对应、近似对应、包含对应等关系, 一个类目概念可由若干个社会标签组配表达, 如下所示:
| (1) |
在主题描述上, 一个类目由n个标签词Social-Tagging组配来表达, association表示某个社会标签对表达主题概念的贡献, n表示社会标签个数。本文采用概念空间的Dice值表示社会标签与相关主题词的相关程度。
由于社会标签被映射到主题词上, 直接以主题词作为训练集数据的来源, 在一定程度上可以起到降低维度, 提高分类精度的作用。利用分类算法, 训练主题词与类目体系之间的约束函数, 即分类器。对中文图书进行分类时, 首先对中文图书社会标签进行特征选择, 将选择后的社会标签利用公式(1)进行概念转换, 得到由主题词表示的受控标引结果, 进而利用训练好的分类器将主题词信息进行文本分类。该算法能够有效利用社会标签对文本进行组织, 不仅可以规范社会标签的使用, 而且可以利用用户产生的社会标签对文本进行有效组织, 减少人工标引所带来的巨大成本。
本文从豆瓣网中获取了4 636本中文经济管理类图书的书名、责任者、ISBN号、出版信息、出版日期、文摘以及豆瓣成员常用标签等信息。通过ISBN在OPAC数据中获取这些中文图书的主题词数据, 其中300条用于测试, 其余用于图书标签概念空间的构建。
4 336本中文图书共包含27 197个社会标签, 其中不重复的社会标签有3 143个, 与其对应的主题词有8 601个, 不重复的主题词数量为784个。用Dice测度算法计算社会标签与主题词之间的相似度, 计算公式如下所示:
| (2) |
其中,
| 表3 中文图书社会标签概念空间部分样例 |
在分类试验中, 本文利用LibSVM软件, 采用SVM算法对中文图书社会标签进行自动分类, 用传统的准确率(P值)、召回率(R值)和F值作为评价指标, 具体的分类结果如表4所示:
| 表4 基于社会标签的中文图书自动分类结果 |
从上述结果可以看出, 三部分数据的自动分类效果由高到低分别是: 基于主题词的自动分类、基于规范控制后的社会标签自动分类、基于规范控制前的社会标签自动分类, 这样的结果符合一般假设。主要原因有以下三点:
(1) 主题词来自于《汉语主题词表》, 具有很强的规范性、严谨性和权威性。在文本分类中具有明显的优势, 然而主题标引费时费力, 成本高, 速度慢, 且与用户的自然语言匹配度较低, 难以满足目前海量增长的信息资源管理的需要。
(2) 社会标签具有类型多样、语义混乱等问题, 相比于受控的主题词而言, 社会标签在形成上虽然更为简单方便, 但它缺乏逻辑严谨性, 从而其分类效果较低。
(3) 经过规范控制后的社会标签在中文图书自动分类中效果虽然不及主题词, 但是相比于完全无控制有了较大的提高, 而利用概念空间规范后的社会标签成本小, 速度快。
总体来说, 受控标引虽然具有较高的质量, 但受控词检索入口少, 标引成本极高, 社会标签词直接反映了用户的查询特征, 如“80后”被大量使用, 受控词表中无直接对应的主题词。因此, 最佳的方式是将两者结合起来, 一方面, 充分利用用户的群体智慧, 使其加入到信息资源的组织中来, 以节省专业人员的时间和精力; 另一方面, 也需要通过一定的规范措施, 提高社会标签的标引质量, 加强其自动分类能力。因此, 考虑到成本、效率及效果三方面的因素, 经过规范控制的社会标签用于文本分类是尚佳选择。
本文根据中文图书社会标签的特点, 通过建立“社会标签-主题词”的概念空间模型, 即实现用主题词对社会标签进行规范控制, 设计了一种“内核受控, 外壳非控”的基于社会标签的中文图书自动分类模式, 并通过实验验证了该方法的合理性和可行性。但由于时间和条件的关系, 研究还存在一些不足, 如研究数据收集不充分。本文的社会标签数据源自豆瓣网的经济管理类中文图书, 由于网站的限制, 获取的社会标签和中文图书的数量有限, 所以可能造成实验结果的片面性。目前构建的“社会标签-主题词”的概念空间仅实现了社会标签与主题词的关联映射, 没有进行更深层次的社会标签间的语义关系识别, 如用、代、属、分、参等关系, 从而导致构建的概念空间缺乏深层的语义信息。因此, 在未来的研究中, 将在全面收集数据的基础上, 通过参考《中国分类主题词表》中主题词之间的用、代、属、分、参等关系, 使用多种关联算法构建更具层次性和系统性的“社会标签-主题词”概念空间, 同时利用集成分类器发现适用于基于社会标签的最佳自动分类算法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|