

{kind=link}
{kind=link}
复杂产品设计知识智能检索研究
引用本文
马绪凯, 丁晟春. 复杂产品设计知识智能检索研究. 现代图书情报技术, 2014, 30(9): 44-50
Ma Xukai, Ding Shengchun. Research on Intelligent Retrieval of Complex Product Design Knowledge. New Technology of Library and Information Service, 2014, 30(9): 44-50
Permissions
Ma Xukai, Ding Shengchun. Research on Intelligent Retrieval of Complex Product Design Knowledge. New Technology of Library and Information Service, 2014, 30(9): 44-50
Copyright©2014, 《现代图书情报技术》编辑部
复杂产品设计知识智能检索研究
作者贡献声明:
马绪凯: 提出研究思路, 设计研究方案, 完成实验, 起草撰写论文; 丁晟春: 提出研究课题, 修改论文框架、修订论文。
摘要
【目的】快速、准确获取产品设计知识, 以满足复杂产品设计过程中的知识需求。【方法】以本体作为知识表示模型, 对产品设计知识进行组织、表示。利用贝叶斯算法识别设计人员检索问句类型, 减少候选问题集的范围。基于TF(Term Frequency)及余弦相似性度量检索问句与候选问题集的关键词相似度, 基于问句的词形与句长计算检索问句与候选问题集的句法相似度。【结果】利用该方法在国防领域身管产品设计知识上进行测试, 实验结果查准率为91.3%, 查全率为86.2%, 查准率优于其他算法。【局限】检索结果依赖于候选问题集的数量, 在大规模问题集的情况下, 相似度算法运算量很大, 需进一步优化。【结论】测试结果表明该方法在复杂产品设计知识检索中是有效的, 对问句类型识别、问句相似度计算具有积极意义。
关键词:
复杂产品; 本体; 知识表示; 相似度; 知识检索; 身管
中图分类号:TP391
Research on Intelligent Retrieval of Complex Product Design Knowledge
Abstract
[Objective] Product design knowledge is obtained as fast and accurate as possible in order to meet complex product design process needs.[Methods] Use Ontology as knowledge representation model to organize and represent product design knowledge so as to provide a common understand of product design knowledge. Use Bayesian algorithm to identify the type of retrieval questions in order to reduce the scope of the candidate questions calculate keywords similarity between retrieval question and candidate questions based on TF and cosine similarity, calculate syntax similarity based on word forms and sentence length of retrieval question.[Results] Test result shows that accuracy rate is 91.3%, the recall rate is 86.2%, and accuracy rate better than other algorithms.[Limitations] Search result depends on the number of candidate questions. For large-scale data, complexity of similarity algorithm is very high, and the algorithm needs further optimization.[Conclusions] The method is effective and has a positive significance for identifying the type of questions and similarity computation.
Keyword:
Complex product; Ontology; Knowledge representation; Similarity; Knowledge retrieval; Barrel
1 引 言
复杂产品是指客户需求复杂、产品组成复杂、设计技术复杂的一类产品, 如航天器、飞机、汽车、船舶、武器系统等, 复杂产品研制是一个继承与重用设计知识的过程, 而设计知识往往散落和隐含在科学原理、技术标准、产品实例、产品部件设计参数、专家经验性知识、三维模型之中。复杂产品设计过程涉及到产品设计流程知识、部件知识、设计流程参数、产品实例及其属性值, 而这些过程知识相互联系, 形成一个复杂的知识网。现有的企业知识管理系统主要是面向企业管理, 是事务性的业务知识管理, 难以支持复杂产品设计过程[ 1]。因此, 有必要对产品设计知识进行分析和组织。本体自从被引入到人工智能领域, 就自然而然地成为一种重要的知识组织模型和工具[ 2]。而智能检索的目标是为用户提供既简洁又准确的信息, 尽可能保证较高的查全率和查准率。本体能够描述特定领域概念之间的关系, 提供对领域知识的共同理解。因此, 本文将本体作为产品设计知识建模与表示工具, 提出复杂产品设计知识智能检索方法。
2 相关工作
本体作为一种有效表现概念层次结构和语义的理论和方法, 被广泛应用于计算机科学和信息管理领域, 并且被成功应用于构建新的智能检索系统。2009年, Jin等[ 3]提出基于本体的OWL产品设计知识检索模型; 2011年, Chen等[ 4]提出基于规则和本体的产品设计知识方法, 两者都能有效提供产品设计开发知识需求, 但都存在知识模型经常变动等问题。贾雪峰等[ 5]利用本体中语义概念关系及语义扩展机制对查询关键词进行概念扩展, 进而计算相似度返回检索结果。孟红伟等[ 6]利用领域本体进行查询处理与语义扩展, 通过查询关键词与领域概念的相关度计算进行检索。曹灵莉等[ 7]基于本体对产品绿色设计知识进行表示, 通过语义检索和文本相似度匹配, 实现绿色设计知识检索。但部分研究[ 5, 6, 7]基本思想都是以关键词为检索对象, 通过关键词的相似度计算获取结果。而设计人员的检索需求往往是复杂的, 关键词难以表达检索意图, 可能无法以几个关键词的简单组合表述清楚。因此, 检索效果很难达到设计人员的需求。然而以自然语言问句方式进行检索时, 不需要设计人员把问题分解成关键词, 可以提高检索结果与检索意图的匹配度。Wang等[ 8]提出基于问句的语法结构计算问句的相似度, 将问句作为一个整体进行计算, 但准确率偏低。董自涛等[ 9]基于编辑距离算法计算句子间相似度, 但其相似度局限在句子词汇计算上, 精度不高。Moreda等[ 10]提出基于知网计算问句与问题集的相似度, 但知网收录的词汇数量有限, 特定领域内词汇更少, 在相似度计算方面具有局限性。张亮等[ 11]基于向量空间模型计算句子间相似度, 将问句与问题库逐一进行计算, 运算量大, 时间复杂度大。
针对上述不足, 本文提出复杂产品设计知识智能检索方法: 利用本体对产品设计知识进行建模。通过贝叶斯算法识别设计人员检索问句类型, 减少候选问题集的范围和算法运算量, 提高检索效率; 依据TF及余弦相似性度量问句与候选问题集的关键词相似度, 基于问句的词形与句长计算问句与候选问题集的句法相似度, 综合两相似度值获取问句相似度, 从而在本体中获取匹配的答案返回给设计人员。
3 复杂产品设计知识智能检索方法
本文提出的复杂产品设计知识智能检索方法如图1所示:
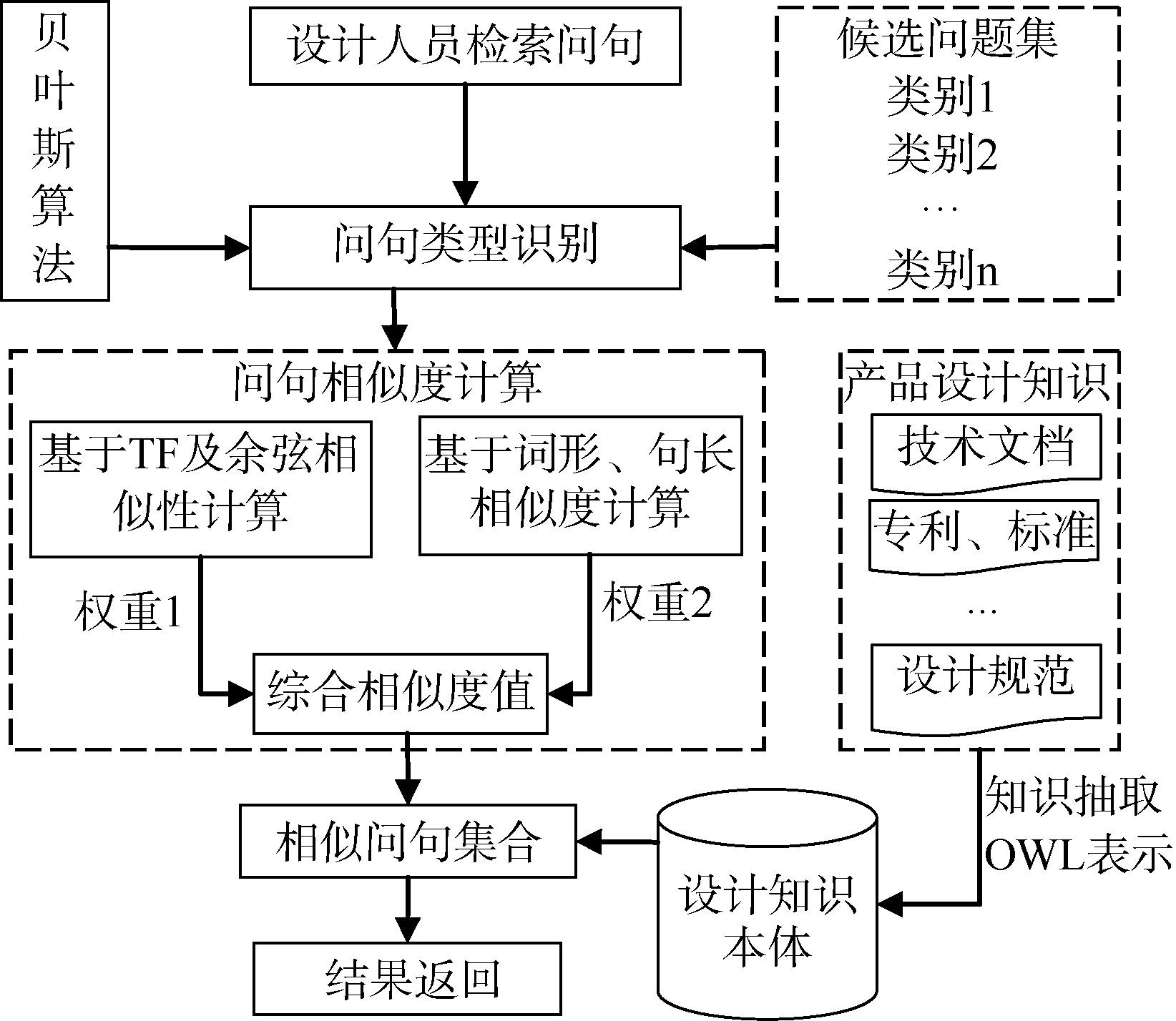 | 图1 复杂产品设计知识智能检索方法 |
其基本思想为:
(1) 复杂产品设计知识大多为非结构化信息, 难以有效利用, 通过对这些信息进行抽取, 并以OWL本体语义进行表示, 形成产品设计知识本体, 而本体的作用就是在特定的产品设计领域, 存储产品设计相关的概念、属性、实例以及相关资源, 便于知识重用;
(2) 为提高检索的效率, 针对设计人员的检索问句倾向构建候选问题集, 依据实际情况对问题集进行分类, 在不同的类目中填充候选问句;
(3) 依据TF及余弦相似性计算问句与候选问题集关键词相似度, 基于词形、句长相似度计算问句与候选问题的句法相似度, 并综合两个相似度值实现问句匹配;
(4) 获得相似问句集合, 遍历集合逐次从本体中将对应的知识返回。
3.1 复杂产品设计知识表示
复杂产品设计知识一般存储在不同领域和来源的半结构甚至非结构化的文档中, 产品不同组成部分的相关知识的关系复杂, 使得产品设计基于已有知识的重用存在困难[ 12]。因此, 对产品以及设计领域中的非结构化、半结构化的知识进行结构化的有效表示, 以促进知识的共享和重用, 是产品设计知识表示的一个关键环节。
(1) 知识的获取
知识的获取就是将已有的产品设计知识, 包括经验、事实、规则、实例等从文档或繁杂的知识数据库中总结和提取出来, 并转换成一定的形式。产品设计中所需知识来自多学科、多领域, 且存储方式异构。这些知识存储于专业书籍、技术文档报告、电子表格、设计图纸以及设计人员的头脑中。因此, 需要深入分析产品设计知识的概念, 确定所要获取的知识。本文结合身管设计知识可能涉及的设计规范、手册等, 归纳出5类设计知识, 即描述性知识, 如身管的功能、结构、行为等属性特征; 判断性知识, 如身管设计中的逻辑关系(因果、条件关系); 过程性知识, 如身管设计的设计阶段、操作以及技术路线; 计算性知识, 如身管的计算公式、函数; 手册知识, 如身管设计的各种标准或文档、图表等。对获取的知识进行再加工和细化, 为设计知识的本体表示奠定基础。
(2) 基于OWL的设计知识表示
由于复杂产品结构、功能概念繁多, 属性类型多样, 不同概念间存在约束。而本体表示语言具有高度结构化, 能准确地表示出知识之间的联系, 且语义具有互操作性, 可以实现知识共享和交换。相对于其他本体描述语言, OWL具有更强的语义描述功能。本文依托课题组前期已经构建完成的用于自行火炮多学科优化设计的自行火炮设计本体, 本体中包括2 406个类, 728个实例, 203个属性。选取其中的身管部件, 以本体编辑工具Protégé构建身管设计本体的OWL片段为例, 说明产品设计本体表示的最终结果。
上述OWL片段表示身管设计本体中“身管应力公式”与“身管工程计算”的父子类关系, “烧蚀寿命终止标准”与“身管技术标准”的实例归属关系。图2是身管知识表示本体可视化效果图:
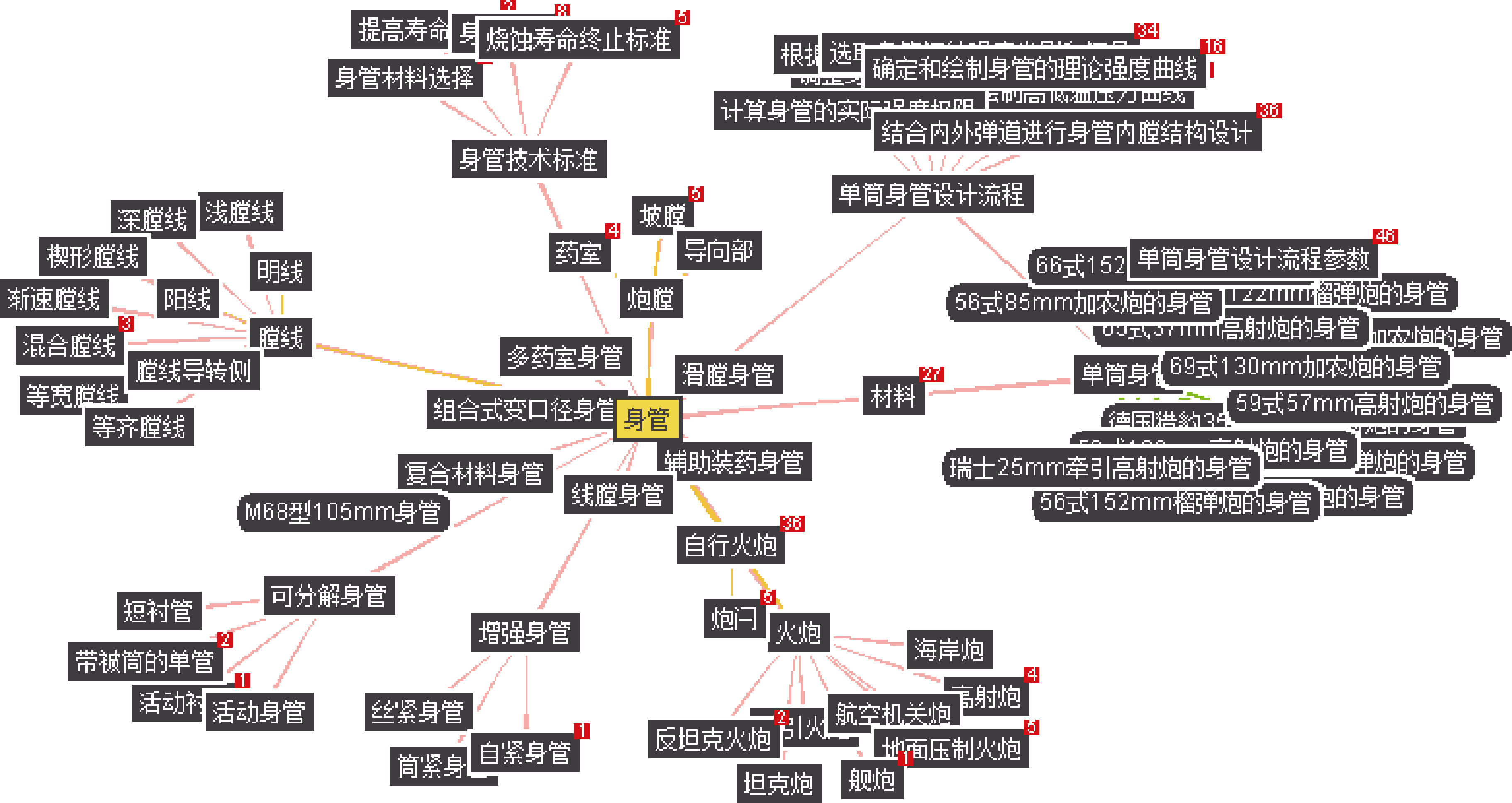 | 图2 身管知识表示本体可视化展示 |
3.2 候选问题集构建
候选问题集是把设计人员可能提出的常见问题组织在一起, 目的是使后续的相似度计算等较复杂的过程都在候选问题集这个相对较小的范围内进行。智能检索技术的核心就是快速地比较设计人员的检索问题与候选问题集中的问句, 进而选定与其最相似的问题。如果存在相似问题, 则将本体中对应的答案作为结果返回。这个过程可以用两个映射表示:f1:Q1→Q2,f2:Q2→O。其中,Q1为设计人员检索问题,Q2为候选问题集中的问题,O为本体中对应的知识集合。
复杂产品设计人员在设计过程中检索问题有泛有细, 如“单筒身管的属性有什么?”、“自紧身管的实例有什么?”等属于比较泛的问题; 而“膛压点到炮口部安全系数为多少?”、“炮口部左区间的取值是什么?”这样的问题则属于细化的问题。根据产品设计人员的实际需求以及产品设计本体将问题候选集分为4类, 如表1所示:
| 表1 候选问题集分类表 |
在问句相似度计算时可以先识别问句的类型, 减少待匹配候选问题的数量, 提高检索的效率; 便于候选问题集的维护与更新。在收集候选问题集时, 首先针对问题集的4种类型获得设计人员在实际检索中的提问方式, 并根据设计人员在实际操作中问句倾向, 对候选问题集进行填充; 其次, 以设计人员的常用提问方式为出发点, 对每种类型的检索问句方式进行扩充, 如设计人员对类别C1的提问倾向为“身管有什么优点?”, 以此为模板进行“身管的优点是什么”、“身管有哪些优点”扩充, 丰富候选问题集, 提高问句匹配的准确度。本文使用的候选问题集库来源于三方面: 课题组在构建自行火炮本体过程中根据已有的类、实例以及属性对不同问题类别进行填充; 在设计人员检索过程中, 获取检索问句并根据问句的类型自动加载到问题集中; 在本体维护与更新过程中, 对新添加的类或实例构建问句, 人工填充到问题集中。当前候选问题集中类别C1包含7 749条问句, C2包含557条问句, C3包含2 300条问句, C4包含2 228条问句。
3.3 问句相似度计算
(1) 问句类型识别
分析问句的类型可以减少候选问题集的范围, 在问题集中找到和设计人员问句相匹配的问题就更加快速高效, 从而提高检索的速度和准确性。问句类型的识别方法有基于规则的算法和基于机器学习的算法[ 13], 而基于机器学习的方法通用、易扩展, 不需要像基于规则的算法构建各种规则, 所以采用基于机器学习的贝叶斯算法进行问句分类。
贝叶斯算法根据已知两个事件的条件概率得到这两个事件交换后的概率, 也就是在已知P(A|B)的情况下如何求得P(B|A)。条件概率P(A|B)表示事件B已经发生的前提下, 事件A发生的概率, 求解公式如下:
P(A|B)=P(AB)/P(B) (1)
同理:
P(B|A)=P(AB)/P(A) (2)
由公式(1)和公式(2)得出贝叶斯分类思想的基础公式:
| (3) |
在本文中, 应用贝叶斯算法则是对于待分类的问句S, 求解S出现的条件下属于类别Ci(i=1,2,3,4)的概率P(Ci), 则问句S归属于最大的P(Ci)所对应的类别Ci。具体步骤如下:
①以候选问题集中的4个类别中问句作为训练样本, 对问句S进行训练;
②设定类别集合C={C1 , C2 , C3 , C4}, 对应候选问题集中的4个类别;
③现在的需求是根据设计人员输入的问句S判断S所属的类型是什么, 即求解P(Ci|S), 选择其中最大P(Ci|S)所对应的Ci, 则认为问题S的类别最可能是Ci。根据贝叶斯公式(3)可知:
| (4) |
由于分母P(S)为问句S出现的概率, 它是个常数, 所以只需要求解分子P(S|Ci)P(Ci)即可, 其中P(Ci)是问题类别Ci出现的概率, 它是可以求解的, 设候选问题集中Ci的问句个数为Ni, 则:
| (5) |
因此, 求解P(Ci|S)的关键在于求解P(S|Ci), 又因为问句S的各个关键词是条件独立的(各个关键词出现与否互不影响), 所以有:
| (6) |
④最后求P(wj|Ci), 它表示问句类别为Ci时关键词wj出现的概率, 设wordNj为候选问题集中类别为Ci时关键词wj出现的次数, wordN为候选问题集中问题类别为Ci时所有关键词出现的次数, 则:
| (7) |
问句S类型得到解决。
(2) 问句关键词相似度计算
利用贝叶斯算法确定设计人员问句S的类别后, 接下来是利用具体的相似度算法将问句S与候选问题集中对应类别中的问句逐一进行相似度计算。返回相似度较大的候选问题集中的问句对应本体中的答案。本文基于TF[ 14]及余弦相似性度量检索问句与候选问题集的关键词相似度, 基于问句的词形与句长计算检索问句与候选问题集的句法相似度, 综合两个相似度值计算句子相似度。下面以问句S与候选问题集中的问句Q为例阐述问句相似度计算。
S: 56式152 mm榴弹炮的身管的初速是多少?
Q: 59式152 mm加农炮的身管的初速?
①对问句S和Q进行分词处理。由于ICTCLAS分词系统效率高而且可以加载本地关键词词库, 准确度高[ 15], 所以选用ICTCLAS加载本地关键词库(词库来源于身管设计本体中的类、实例、属性, 利用本体操作工具Jena获取), 最终获得的S、Q分词结果如下(未对分词结果进行停用词处理, 实际中需要去除停用词):
S: 56|式|152 mm|榴弹炮|的|身|管|的|初速|是|多少|?
Q: 59|式|152 mm|加农炮|的|身|管|的|初速|?
②列出分词后出现的所有词汇, 词汇之间以逗号分开, 具体如下:
[56,式,152 mm,榴弹炮,的,身,管,初速,是,多少,?,59,加农炮]
③计算词频TF, 统计问句S与Q中词汇在步骤②中的词频, 词汇与数量之间以空格分开, 具体如下:
S: 56 1, 式 1, 152 mm 1, 榴弹炮 1, 的2, 身 1, 管 1,初速 1, 是 1, 多少 1, ?1, 59 0, 加农炮 0
Q: 56 0, 式 1, 152mm 1, 榴弹炮 0, 的2, 身 1, 管 1, 初速 1, 是 0, 多少 0, ?1, 59 1, 加农炮 1
④根据问句中每个词汇对应的数量, 列出问句S与Q的词频TF向量:
S: [1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 0, 0]
Q: [0, 1, 1, 0, 2, 1, 1, 1, 0, 0, 1, 1, 1]
⑤将问句S与Q表示成向量, 那么向量之间就会形成一个夹角, 因此, 可以通过夹角
| (8) |
余弦的这种方法对n 维向量也是成立的, 所以可以得到问句S与Q的相似度如下。
计算出问句S与Q的相似度cos(S,Q)为0.77。
(3) 问句句法相似度计算
基于TF及余弦相似性算法只考虑问句关键词的匹配以及权重, 而没有考虑问句中词与词之间的关联, 为了弥补这个不足, 在问句相似度计算中, 引入基于问句的词形与句长的句法相似度算法。
①词形相似度
Wordsim(S,Q)表示问句S与Q中词的相似度, 从组成句子的词及词性上计算句子在形态上的相似度, 计算公式为:
| (9) |
其中, Word(S)、Word(Q)分别表示句子S与Q中关键词出现的频次,SameWord(S,Q)表示S与Q相同关键词出现的频次。
②句长相似度
从问句长度上计算句子相似度, 句长相似度计算公式为:
| (10) |
其中,Len(S)和Len(Q)分别表示问句S与Q的关键词个数, 如Len(S)=12,Len(Q)=10,Lensim(S,Q)=0.91。
在问句相似度计算中, 其他需要考虑的因素还有次序、关键词之间的距离等。在本文产品设计知识检索中, 复杂问句较少, 因此忽略了这些因素。综合关键词相似度与句法相似度, 定义问句S与Q的相似度为:
| (11) |
考虑到算法在复杂产品设计知识检索中的实际应用, 规定, β1 ≥ 0.7 ≥ β2 ≥ β3,且β1 + β2 + β3 = 1。
4 实 验
4.1 评价指标
从查准率和查全率两个方面对复杂产品设计知识智能检索方法评估与分析。查准率是查询出的准确答案个数与查询出的所有答案个数的比值,公式如下:
| (12) |
查全率是查询出的准确答案个数与候选问题集中所有准确答案个数的比值, 公式如下:
| (13) |
4.2 数据介绍
(1) 本 体
构建身管产品设计本体的概念、实例、实例值等元数据来源于现有的书籍、设计规范、手册以及领域专家提供的设计信息。设计资源利用已有数据, 数据属性以及对象属性根据身管产品自行定义, 如数据属性hasDefinition(定义)、对象属性hasDesignProcess(设计流程), 利用Protégé构建身管本体, 得到类861个, 实例557个, 属性132个, 本体关联设计资源文档711篇, 视频206个, 图片1 056张, 公式327个。
(2) 候选问题集
候选问题集采用已有的数据作为训练集, 通过人工方式组织80条检索问句, 每个类别Ci(i=1,2,3,4)各20条作为测试集, 如表2所示:
| 表2 候选问题集训练集与测试集数量 |
4.3 结果与分析
分别利用问句关键词相似度算法与综合相似度算法, 根据本文提出的方法进行验证。首先确定算法中系数值,β
| 表3 实验结果 |
通过系统测试结果可以发现, 综合相似度算法要优于单纯问句关键词相似度算法, 主要是因为基于TF及余弦相似性算法主要针对关键词为单位进行相似度计算, 忽略了问句作为一个整体的影响, 这也印证了本文在算法设计上的初衷。同时可以看到应用本文的算法可以获得较好的查准率与查全率, 准确率比张亮等[ 11]研究中算法高出2.3%, 满足了在复杂产品设计知识检索中的需要。
5 结 语
针对当前复杂产品设计过程中不能快速、准确获取产品设计知识的问题, 本文进行产品设计知识智能检索技术研究。利用本体OWL语言对产品设计过程中涉及到的知识进行结构化、形式化表示。为提高检索效率与准确度进行候选问题集的分类构建, 综合利用TF及余弦相似性算法和基于词形与句长的相似度算法对检索问句和候选问题集进行相似度计算, 使得检索系统在查准率与查全率两方面获得很好的评测结果。为实现本文检索方法的广泛使用, 将对如下问题展开深入研究: 研究本体的分析方法和表示形式; 进一步扩展本体的检索能力; 研究如何自动实现候选问题集的扩充, 细化问题集的分类。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|