
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
主题相关的虚拟读者社区推荐方法研究
[洪亮 , 冉从敬]
, 冉从敬]
, 冉从敬]
|
|


作者贡献声明:
洪亮: 提出研究思路, 设计研究方案; 进行实验; 起草论文; 冉从敬: 论文最终版本修订。
【目的】为了帮助读者从海量的虚拟读者社区中选择符合其兴趣的社区。【方法】提出基于主题概率模型的读者社区推荐方法, 通过发现读者社区的隐含主题, 建立起读者与读者社区在不同主题上的联系, 并根据社区和读者的主题相似度进行读者社区推荐。【结果】在真实数据上的实验证明该方法能够有效地发现读者社区的隐含主题, 相比现有的推荐方法, 能够准确地推荐虚拟读者社区。【局限】存在推荐的冷启动问题。【结论】该推荐方法帮助读者准确迅速地找到感兴趣的主题相关虚拟读者社区, 能够促进读者的沟通交流和虚拟读者社区的发展。
[Objective] To help readers select interested communities from massive reader communities.[Methods] This paper proposes virtual reader community recommendation method based on probabilistic topic model, which builds reader-reader and reader-community relations on different topics by finding latent topics of reader communities, and then recommends reader communities by considering topic similarities of both communities and readers.[Results] Experiments on real data prove that the method can effectively find latent topics of reader communities and accurately recommend virtual reader communities compared with existing recommendation methods.[Limitations] Exist cold start problem of recommendation.[Conclusions] This method helps readers accurately and quickly find interested topic-related virtual reader community, promoting the communication of readers and the development of virtual reader communities.
在Web 2.0时代中, 人们不再是一个虚拟世界中简单的个体, 而是自发形成了网络上的虚拟社区。虚拟社区是人们为了分享共同的兴趣爱好或者协同解决某个问题而产生的[ 1]。虚拟社区被定义为一群藉由计算机网络彼此沟通的人, 他们彼此有某种程度的认识、分享某种程度的知识和信息, 从而所形成的团体。
虚拟读者社区(简称读者社区)是一种面向读者的虚拟社区。目前, 网络上活跃着各种类型的读者社区网站, 比如Shelfari、豆瓣网、Facebook、凤凰读书、新浪读书等。这些网站管理着大量的主题相关的读者社区, 吸引了对不同主题图书感兴趣的读者进行在线的沟通、交流和分享[ 2]。举例来说, 豆瓣网中的兴趣小组就是一种典型的读者社区, 每个兴趣小组都有一定的主题, 比如“小说”、“互联网”、“散文”等。每个主题的读者社区中包含着巨大的读者群体, 他们因为对该主题的共同兴趣而加入社区。图书馆可以根据主题对这些读者群体进行阅读推荐, 也可以利用读者社区 平台在线开展信息咨询、文献共享等各种读者服务。然而, 读者社区数量庞大, 以豆瓣网为例, 该网站有271 214个读者社区, 并且数量还在不断地增加。面对如此众多的读者社区, 读者难以选择出真正感兴趣的社区加入。推荐系统作为解决信息过载的重要工具之一[ 3], 可以从海量的读者社区中准确并高效地为读者推荐其感兴趣的社区。本文提出基于主题概率模型的虚拟读者社区推荐方法, 为读者推荐符合其兴趣的读者社区, 能够促进读者社区的发展, 为读者提供更好的服务。
现有的社区推荐方法主要分为基于内容的推荐方法[ 4]和协同过滤方法[ 5]。基于内容的虚拟社区推荐首先计算用户的个人资料与虚拟社区的描述信息之间的相似度, 然后基于相似度进行推荐。Facebook的群组推荐[ 6]通过比较用户个人资料与群组虚拟身份的相似性进行群组推荐, 群组也是一种虚拟社区, 群组虚拟身 份来源于组内大部分成员所具有的个人资料信息。Kim等[ 7]设计了一种基于内容的读者社区推荐方法, 提高了社区推荐的准确性和个性化程度。
协同过滤的方法首先由Goldberg等[ 5]于1992年提出, 其思想是分析类似目标对推荐目标的影响, 通过协同为用户推荐可能感兴趣的对象。协同过滤分为显式和隐式协同过滤, 前者使用关联规则进行协同过滤, 后者使用基于模型的协同过滤挖掘潜在关系进行推荐。Zheng等[ 8]通过Flickr中的潜在标签联系用户和群组, 并利用张量分解的方法推荐用户感兴趣的群组。Chen等[ 9]采用基于隐含狄利克雷分布 (Latent Dirichlet Allocation, LDA)模型的协同过滤方法对Orkut社区系统中的社区进行推荐, 该方法通过挖掘大部分用户共同拥有的社区间关系进行推荐。LDA模型由Blei等[ 10]在2002年首先提出, 通过文档的建模, 对文档进行分类, 并计算相似度。LDA模型认为文档是在一组主题上的分布, 而主题则是由词汇的分布集合表示。一个文档包含多个主题, 一个主题包含多个词汇。陈琼等[ 11]提出基于节点动态属性相似性的网络社区推荐方法, Yu等[ 12]根据用户社区之间的关系设计了新颖性社区推荐方法, 不同于本文所研究的准确性推荐, 新颖性推荐着重提高所推荐社区对用户的新颖性。
由于读者社区有着自身的特征, 现有的社区推荐方法在进行推荐时面临一系列问题:
(1) 现有的推荐方法缺乏对社区的主题的建模。读者社区是主题相关的, 比如小说、传记、社科等, 主题是连接读者和社区的桥梁。读者选择加入社区的原因是被社区的主题或者社区里面的其他读者所吸引。
(2) 现有推荐方法的内在不足。基于内容的推荐方法忽视了读者社区内的社会关系对推荐的影响, 会降低推荐的质量[ 3], 这是因为基于内容的推荐总是基于读者已经参加的社区推测读者的主题偏好, 根据主题偏好推荐相关主题的社区给读者, 这会造成推荐结果集中于读者已经参加的社区的主题, 使得读者视野变得狭窄。协同过滤方法会产生冷启动问题, 即无法为新读者进行社区推荐[ 3], 这是因为当没有收集到足够多的信息时, 协同过滤方法无法为读者和社区之间建立关联。
(3) 现有推荐方法无法度量读者与社区之间的相关度。读者社区推荐的评价应着重考虑读者是否选择加入所推荐的社区, 以及读者兴趣与社区主题的相关度。现有的LDA模型在对读者进行主题挖掘时完全基于二值读者-社区关系, 即读者加入社区, 观察集中对应的值为1, 反之, 值为0。这样的关系描述忽视了读者与社区的关系强度, 挖掘出的主题无法准确描述读者在主题上的概率分布, 以及主题上的社区概率分布。
针对以上问题, 综合虚拟社区推荐的研究现状, 本文提出基于主题概率模型的虚拟读者社区推荐方法, 设计基于LDA的主题概率模型, 发现读者社区的潜在主题, 形成读者-主题-社区的三层体系结构; 利用读者在主题上的概率分布和主题上的社区概率分布度量读者和社区在主题上的相关度, 主题上与读者相关的社区被推荐给读者; 读者在主题上的概率分布作为读者的主题向量, 以不同读者在主题向量上的相似度衡量读者的相似性, 通过相似读者进行社区的协同推荐, 解决了读者社区推荐的局限性问题, 最终的推荐综合考虑读者在主题上相关的社区和主题上相似读者协同推荐的社区, 提高推荐的准确度, 降低了推荐的局限性。
虽然目前读者社区都是存在主题的, 但是读者社区的单一主题难以全面表达社区的所有主题信息。社区内的信息随着读者的不断参与而动态变化, 更进一步导致了单一主题无法表达社区及其参与读者的主题信息迁移。因此, 需要对读者社区的主题进一步挖掘, 发现社区与读者的隐含主题, 更好地描述读者与社区在主题上的关联, 为读者社区的推荐打下基础。
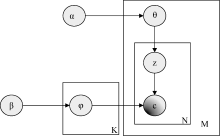
读者社区的主题概率模型采用读者在读者社区内的参与度作为观察集。读者的参与度由读者在社区内发帖和交流的数量表示。主题概率模型的贝叶斯网络图如图1所示:
 | 图1 主题概率模型的贝叶斯网络图 |
其中, α表示社区主题分布的狄利克雷先验参数, β表示读者主题分布的狄利克雷先验参数, θ表示社区的主题分布, 属于狄利克雷分布, z表示社区中读者所对应的主题,φ是一个K×V的马尔科夫矩阵, 其中V为读者的总数, 矩阵中一行表示一个主题的读者分布, 而c表示对应的社区。令U={u1,u2,···,um}表示M个读者集合,C={c1,c2,···,cn}表示N个社区集合,T={T1,T2,···,Tk}表示K个主题集合。图1中阴影部分的c被作为观察集进行求解(即读者在已参与社区中的参与度), 非阴影部分是潜在变量, 箭头表示两个变量间的条件依赖性。
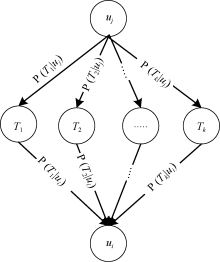
读者社区的主题概率模型中读者是由一组主题的概率分布来描述, 而主题则是由一组社区的概率分布来描述。读者与社区间的主题概率模型如图2所示, 该模型中读者和社区通过主题条件概率联系起来。读者间的主题概率模型如图3所示, 由于每个读者都在主题上拥有相应的概率分布, 因而读者之间也可以由主题联系起来。
 | 图2 读者与社区间的主题概率模型 |
 | 图3 读者间的主题概率模型 |
主题概率模型建立之后, 需要对模型进行求解, 即对参数进行学习。本文采用吉布斯抽样[ 13]对主题概率模型进行求解, 得到具体的读者主题分布θ和主题社区分布φ。
在主题概率模型的基础上, 通过求解主题相似读者的协同, 以及对新读者设置虚拟社区, 对读者进行协同过滤推荐。
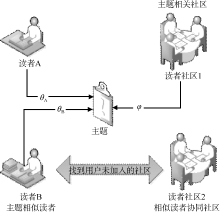
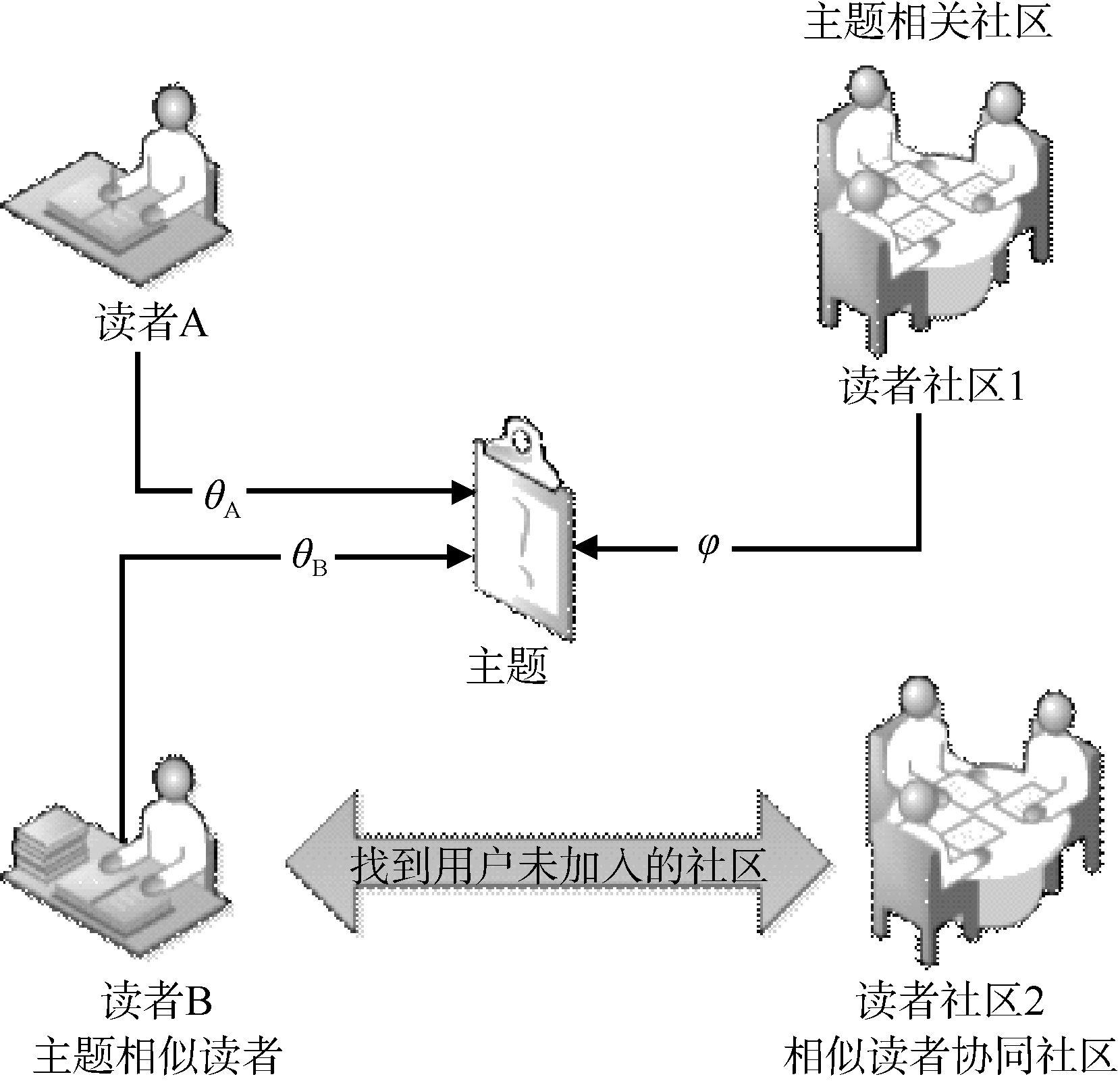 | 图4 基于主题概率模型的读者社区推荐过程 |
图4描述了一个典型的基于主题概率模型的读者社区推荐过程。对于读者A, 通过A在主题上的分布θA和主题上读者社区1的概率分布φ, 得到读者A的主题相关度, 并将读者社区1根据主题相关度值的高低推荐给读者A。通过读者A在主题上的分布θA和读者B在主题上的概率分布θB, 得到读者间的主题相似性, 并从主题相似读者得到读者A并未加入的读者社区2, 因此还应将读者社区2推荐给读者A。具体的读者社区推荐的方法如下:
输入: 读者社区分布矩阵θ; 主题社区分布矩阵φ; 读者加入的社区。
输出: 按照主题相关度排序的读者社区。
(1) 通过读者在主题上的分布值θ和社区上的分布值φ计算出读者在社区上的主题相关度ε, 得到与读者最相关的n个社区。主题相关度 ε的计算公式如下:
其中, K表示主题数目,
(2) 通过不同读者在主题上的分布值
假设有K个主题, 读者A和B的主题向量分别为
(3) 比较步骤(1)和步骤(2)得到的社区, 合并相同的社区, 并根据主题相关度对社区进行排序, 将排序后主题相关度最高的n个社区推荐给读者。
本文选择豆瓣网(http://www.douban.com)的数据进行实验分析。豆瓣网是国内最为知名的读者社区之一, 读者可以在“小组”(即读者社区)内发帖、回帖, 对豆瓣网中的书籍、电影等进行收藏、点评与交流。目前豆瓣网将“小组”分成12个主题, 管理的读者社区数量达到271 214个, 注册用户数量达到7 000多万。本文的数据集包括豆瓣网中12个主题的11 581个社区和1 030 839个用户(即读者)信息。
(1) 比较方法
将本文提出的基于主题概率模型的推荐方法(简称“主题概率”)与基于LDA模型的社区推荐方法[ 9](简称“LDA”)进行比较。基于LDA模型的社区推荐方法通过LDA模型发现用户的潜在行为, 并根据其潜在行为推荐该用户感兴趣的社区。实验首先比较以上两个推荐方法对豆瓣读者社区的主题挖掘效果, 然后比较它们的推荐准确度, 最后对两种方法推荐的局限性进行对比。
(2) 参数设置
根据LDA模型的典型参数配置[ 10], 迭代次数设为1 000, 主题数目设为12, 读者主题分布θ的狄利克雷先验参数α设为0.3, 主题社区分布φ的狄利克雷先验参数β设为0.01。使用LDA模型进行读者社区主题挖掘, 作为观察集的读者社区矩阵, 读者加入的社区, 对应的矩阵值为1, 读者没有加入的社区对应的矩阵值为0。而主题概率模型使用读者在社区中的发帖量度量该读者在某个社区的参与度。
(3) 评价指标
因为社区推荐的最终目的是将读者最感兴趣的多个社区推荐给读者, 因此实验采用Top-N推荐的评价指标。具体来说, 主题挖掘效果使用主题吻合概率进行评测, 主题吻合概率为挖掘出来的主题与读者社区在豆瓣网中所属主题相同的概率, 概率越高说明主题挖掘的准确度越高。推荐准确度分别通过排名累积分布和排名差值进行评测, 排名累积分布表示读者已加入社区在所推荐社区中的排名分布情况, 排名累积分布越小, 说明读者已加入的社区在Top-N推荐列表中排名越靠前, 推荐越准确; 排名差值表示分别使用基于LDA模型的推荐方法和基于主题概率模型的推荐方法得到的读者已经加入的社区排名之差, 负值表示使用LDA模型获得的排名高于主题概率模型得到的排名, 如 -700, 表示基于LDA模型得到的社区排名比基于主题概率模型要高700名; 反之, 正值表示基于主题概率模型获得的排名要高于基于LDA模型得到的排名。
(1) 主题挖掘效果比较
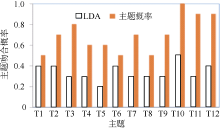
 | 图5 主题挖掘效果比较 |
准确的主题挖掘是高质量读者社区推荐的基础。图5描述了分别使用LDA模型和主题概率模型得到的12个主题T1, T2, …T12下的Top-10个社区。横轴表示通过主题挖掘出的12个主题, 纵轴表示主题下的分布值最高的10个社区主题吻合的概率, 概率值为1表示对应10个社区全部吻合, 概率值为0表示对应10个社区全部来自不同的主题。图5显示了使用主题概率模型的主题吻合概率远高于使用LDA模型得到的主题吻合概率。主题概率模型得到的读者社区来自相同主题的概率最低达到50%, 最高可以达到100%。表明使用本文提出的主题概率模型对社区主题进行挖掘的效果优于LDA模型的效果, 与实际的主题较为吻合。这是因为LDA模型只考虑了二值读者-社区关系, 即读者是否加入社区; 而主题概率模型可以计算读者与社区的主题相关度, 更加符合虚拟读者社区中读者与社区的实际关系。
(2) 推荐准确度比较
为验证推荐的准确度, 随机取出读者已经加入的一个社区和未加入的1 000个社区作为测试集, 获得该读者已加入社区在1 000个未加入社区的排名分布, 比较分别使用LDA模型推荐和基于主题概率模型的排名分布情况。
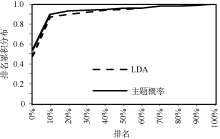
实验对1 000个读者进行测试, 主题相似读者数量设为10。排名分布如图6所示, 使用主题概率模型得到的排名累积分布要高于使用LDA模型得到的排名累积分布, 体现了基于主题概率模型的推荐方法具有较好的推荐准确度, 能够将读者已加入的社区排在推荐列表的前面。主要因为基于主题概率的推荐方法同时根据读者社区的主题相似度和读者的主题相似度进行社区推荐, 而基于LDA的推荐方法仅根据读者和社区的相关性进行推荐。
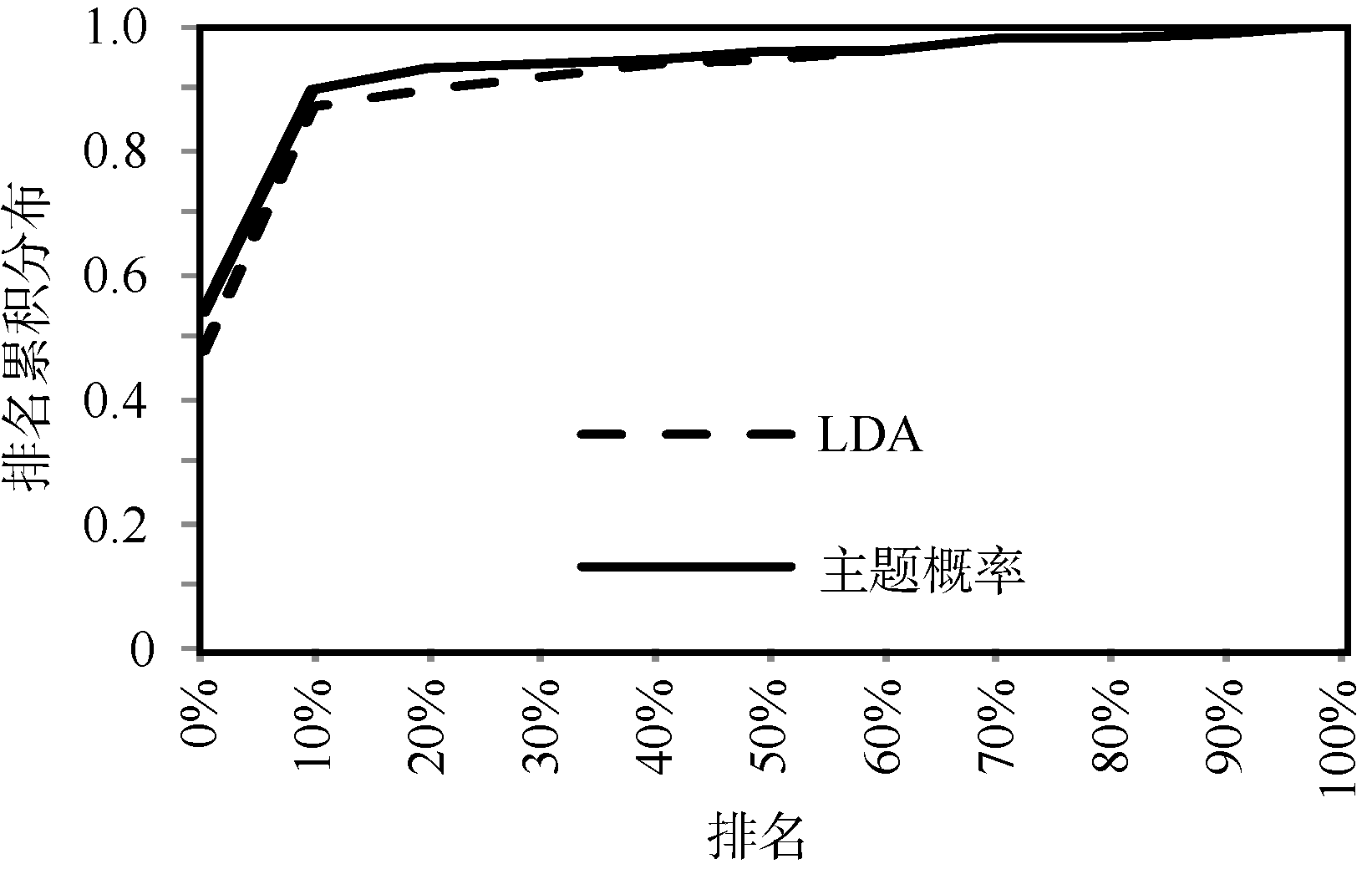 | 图6 排名累积分布比较结果 |
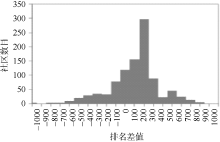
图7是LDA模型和主题概率模型在对1 000个读者得到的排名差值图, 纵轴表示相应的社区数目。可以看出大部分的读者已经加入的读者社区在主题概率中的排名要高于其在LDA中的排名, 说明读者更倾向于加入基于主题概率模型的推荐方法所推荐的虚拟读者社区, 因此本文所提出的方法具有较高的推荐准确度。
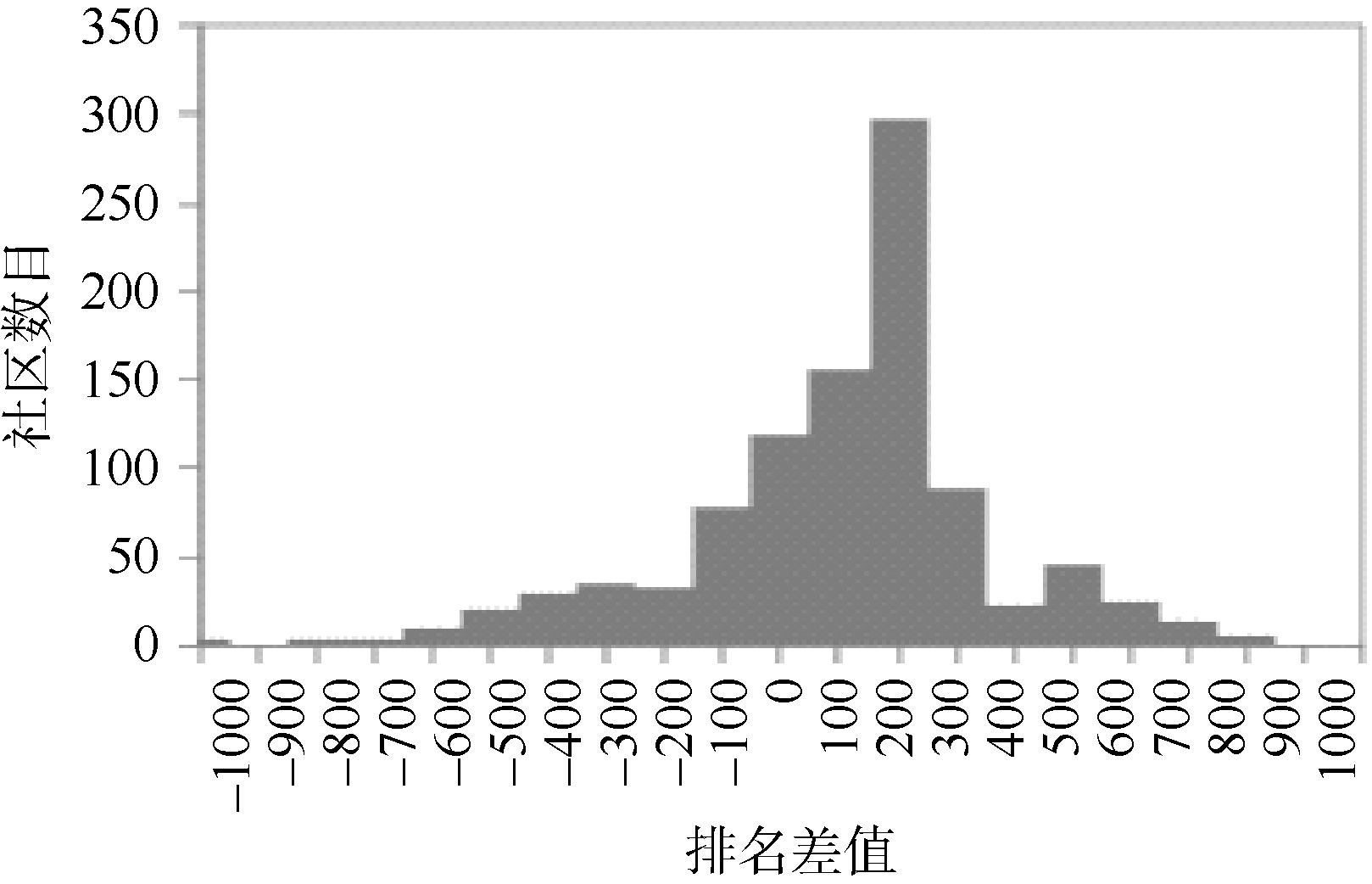 | 图7 排名差值与相应的社区数目 |
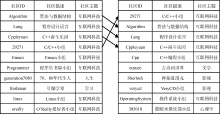
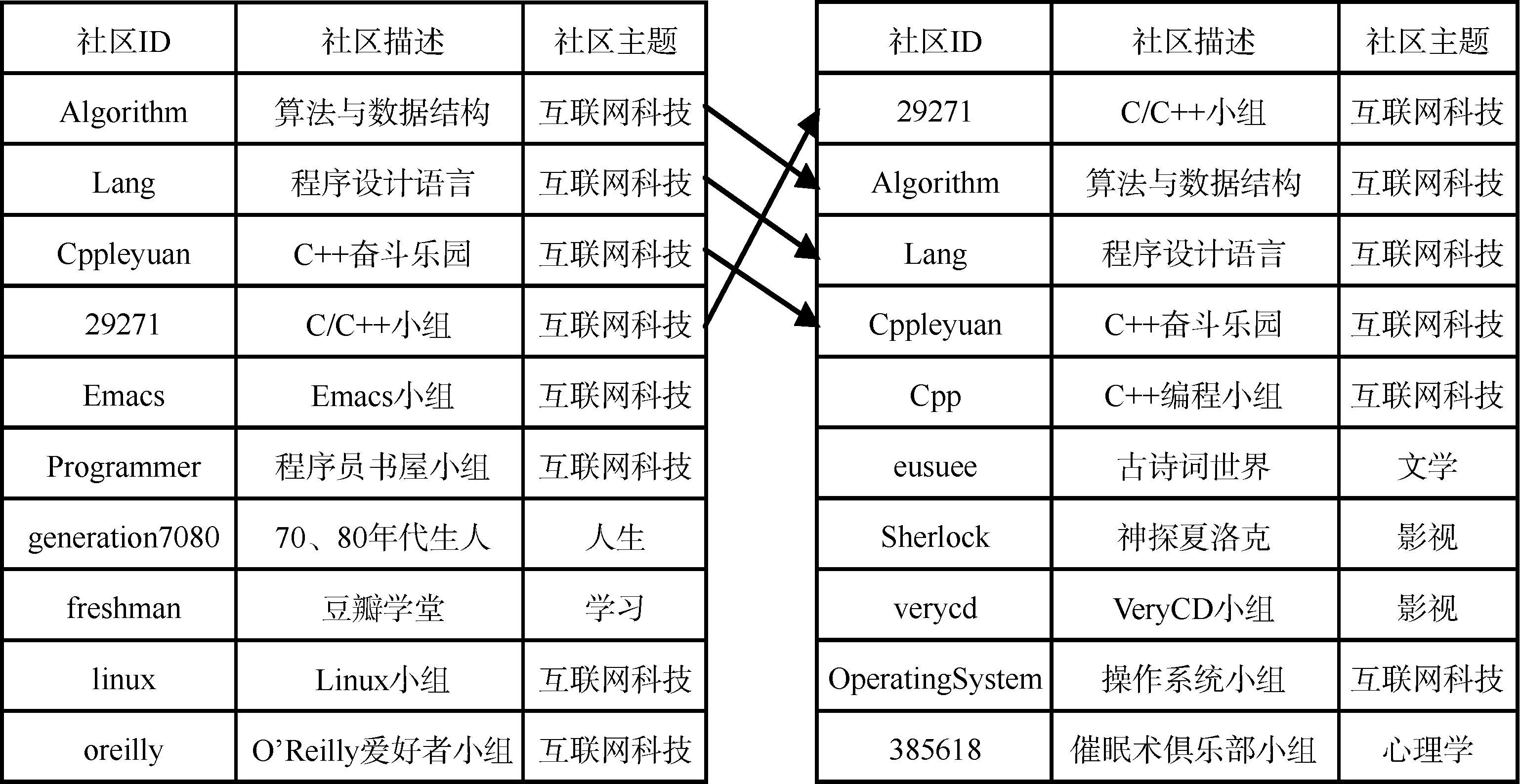 | 图8 两种模型的推荐局限性比较 |
(3) 推荐局限性比较
分别比较使用两种推荐方法产生的推荐结果的局限性。推荐结果所属的主题越集中, 则局限性越强, 反之则局限性较小。
以读者hao123为例, 该读者只加入了一个社区, 该社区ID为CC, 社区描述为C语言小组, 属于“互联网科技”主题。对这个读者分别使用两种推荐方法推荐社区, 结果如图8所示。基于LDA模型推荐的社区大多属于“互联网科技”主题, 说明基于LDA模型的推荐方法没有利用主题相似用户进行协同推荐, 产生的推荐结果具有局限性, 即推荐结果均集中于读者已经加入的社区所属的主题。而使用基于主题概率模型的推荐方法产生的结果中排名较高(即较为符合该读者的兴趣)的社区是与“互联网科技”主题相关的; 除此之外, 该方法还根据与读者hao123具有相似兴趣的读者推荐了其他主题的社区。其他的社区都是根据与读者hao123具有相似兴趣的读者进行协同推荐得到的结果。由此可见, 基于主题概率模型的推荐方法既保证了推荐的准确度, 又较好地降低了推荐的局限性, 提高了推荐的质量。
针对现有推荐方法在推荐读者社区时面临的挑战, 本文提出一种基于主题概率模型的读者社区推荐方法。该方法首先构建主题概率模型, 挖掘读者社区的隐含主题, 利用读者-主题-社区的三层体系结构关联社区的相似性和读者的相似性, 然后在此基础上提出基于主题概率模型的推荐方法, 综合采用社区的主题相似度和读者的主题相似度进行高质量的读者社区推荐。该推荐方法可以帮助读者准确迅速地找到感兴趣的读者社区, 促进了虚拟读者社区的发展。实验结果证明本文提出的基于主题概率模型的虚拟读者社区推荐方法在主题挖掘与推荐的准确度, 以及推荐的局限性等指标上均优于现有的推荐方法, 能够满足工程化实施的要求。
笔者将在下一步的研究中深化用户自身兴趣的建模, 缓解读者社区推荐中存在的冷启动问题, 以期对缺乏历史数据的新用户提供高质量的推荐。同时, 提高大数据环境下推荐方法的效率也将是未来的研究方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|