
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于类平均相似度的文本分类算法
[谭学清, 周通 , 罗琳]
, 罗琳]
, 罗琳]
|
|


作者贡献声明:
谭学清: 提出研究思路, 设计研究方案; 罗琳: 采集和分析实验所需真实数据; 周通: 进行实验, 论文起草, 初稿撰写; 谭学清, 罗琳: 论文审阅和最终版本修订。
【目的】在KNN算法基础上, 提高文本分类的分类性能和分类速度。【方法】提出一种基于类平均相似度的分类算法, 通过计算待分类文本与训练集各类别中所有文本相似度的平均值判断待分类文本的所属类别。【结果】实验表明, 本文方法在复旦、Sogou平衡、非平衡语料上的Macro_F1比KNN分类算法分别提高3.5%、3.2%和3.3%, 分类时间分别为KNN算法的1/22、1/6和1/5。【局限】考虑到KNN算法的时间效率, 实验数据的文本数较少。【结论】相对于KNN, 基于类平均相似度是一种适用于大规模文本分类的实用分类算法。
[Objective] To improve the classification performance and classification speed based on the KNN algorithm.[Methods] This paper proposes a classification algorithm based on the average category similarity, to judge the type of the test text by calculating the mean value of the text similarities of the test text and all texts of each category in the training set.[Results] The experimental results on the Fudan, balanced Sogou and unbalanced Sogou public corpus show that compared with KNN classification algorithm, the Macro_F1 on the two corpora of the method in this paper is increased by 3.5%, 3.2% and 3.3% respectively, the classification speed is 1/22, 1/6 and 1/5 respectively of KNN algorithm.[Limitations] Considering the time efficiency of KNN algorithm, the number of text of the experimental data is few.[Conclusions] It is a kind of practical classification algorithm for large scale text classification contrast with KNN.
互联网的普及和计算机技术的高速发展, 使得电子文档迅速增加, 互联网在给用户带来海量信息的同时, 也给用户查找、过滤和管理这些海量信息带来困难。因此, 文本分类技术的研究引起了人们的持续关注。文本分类是指依据文本的内容, 由计算机根据某种自动分类算法, 把文本划分到预先定义好的类。随着文本信息量的快速增长, 文本自动分类已成为信息检索、知识挖掘和管理等领域的关键技术和研究热点之一。
目前, 关于文本分类的研究已经取得很大的进展, 并提出一系列有效的分类算法, 如KNN(K-Nearest Neighbors)算法[ 1]、朴素贝叶斯算法[ 2]、支持向量机[ 3](Support Vector Machine, SVM)等, 其中应用最广泛的是KNN算法。KNN算法是一种非参数的分类技术, 凭借其在分类过程中的稳定性和实现简单, 成为国内外学者的研究热点, 在基于统计的模式识别中非常有效, 对于未知和非正态分布可以取得较高的分类准确率。
但是KNN算法本质上是一种基于实例的机器学习方法, 在分类过程中也会有一些缺点: 对于大规模的长文本(如Sogou、复旦公开语料库, 其中Sogou文本平均长度为685个字, 复旦文本平均长度为2 772个字), 需对每篇待分类文本与所有训练集文本的相似度进行排序, 分类时间随着训练集文本数和文本长度的增加而平方级增加, 因此KNN算法对大量长文本分类的时间效率非常低; KNN算法的分类性能受训练样本的分布情况影响较大, 算法计算相似度时以样本的特征项权重作为参数, 实际应用中的数据往往是不平衡的, 因此当数据分布出现倾斜时, 大类样本占据密度优势, 其包含的特征项权重值也随之增加, 导致分类效果不理想。
近年来, 国内外学者对文本分类算法做了大量研究, 在经典分类算法的基础上, 提出一些新的分类算法或将其他领域的相关方法应用于文本分类, 取得了一定的成果。其中, 郑凤萍[ 4]针对传统VSM模型在文本特征表示方面的不足, 构造了基于文本特征的模糊VSM模型, 并在此基础上提出了基于RBF网络的文本自动分类方法, 该方法在特征提取时充分考虑了特征项在文档中的位置信息, 构造出模糊特征向量, 使自动分类更接近手工分类方法; 王建会等[ 5]针对KNN算法时间复杂度高、可扩展性差等问题, 提出一种基于互依赖和等效半径的分类算法SECTILE, 该算法可扩展性较好, 且适用于大规模文本分类; 朱靖波等[ 6]提出一种基于内容主题识别算法FIFA的文本分类方法, 该方法主要通过特征识别模块构造文本的主题特征集, 然后采用集聚公式进行主题特征集聚过程, 根据集聚结果中各个主题的权值, 选择权值大的主题作为文本的主题标注; Yigit[ 7]提出一种基于距离-权重的分类算法, 通过人工蜂群算法(ABC)寻找最优权重对文本进行分类; Mejdoub等[ 8]在KNN算法的基础上提出一种图形分类算法, 有效结合使用有监督和无监督方法, 提高分类性能。
在上述研究的基础上, 针对KNN算法在对大规模长文本分类时的分类准确率、时间效率等问题, 本文提出一种基于类平均相似度的分类算法(简称类平均相似度算法), 该方法通过计算待分类文本与训练集各类别文本之间的相似度的平均值而不是对相似度值排序来判断待分类文本所属的类别, 大大降低时间复杂度, 并与KNN分类算法进行比较, 实验结果表明, 类平均相似度算法在提高分类精度的同时, 还能大幅度提高分类速度。
文本表示模型有很多种, 最常用的是向量空间模型(Vector Space Model, VSM)[ 9]。向量空间模型采用特征词作为特征项来表示文本内容, 同时给予每个特征词一定的权重, 以反映特征词表示文本内容的重要程度, 在此基础上采用特定的分类算法对待分类文本进行分类。在向量空间模型中, 每个文本被表示为特征向量:
最常用的特征词的权重计算方法是TF-IDF[ 10], 特征词频率(Term Frequency, TF)是特征词在文本中出现的次数, 反文本频率(Inverse Document Frequency, IDF)的核心思想是在多数文本中出现的特征词不如只在少数文本中出现的特征词重要, 因此IDF能弱化部分高频特征词的重要度。TF-IDF的主要思想为: 特征词在特定的文本中出现的频率越高, 说明它在区分该文本内容属性方面的能力越强(TF); 特征词在文本中出现的范围越广, 说明它区分文本内容的属性越低(IDF)。其公式如下[ 10]:
| (1) |
其中,
在文本表示过程中, 对于文本集中的“非作用词[ 11]” (对文本分类表现力不强的特征词)应将其过滤掉, 以提高分类效果, 同时降低特征向量的维度。特征选择就是通过构造一个特征评估函数, 计算每个特征词的函数值, 并根据该函数值选择具有代表性的特征子集作为文本表示的特征项, 特征选择的关键是特征评估函数的构造。
目前常用且效果较好的特征选择方法主要有卡方统计[ 12](Chi Square Statistic, CHI)、信息增益[ 13](Infor-mation Gain, IG)和互信息[ 14](Mutual Information, MI)。公开语料库上的实验结果和相关研究表明采用CHI分类效果最好[ 15], 且在实验过程中无需因训练集文本的增加而调整特征阈值的大小。
KNN分类算法的基本思想是: 对于一个待分类文本, 计算其与训练集所有文本的相似度, 并对计算结果排序, 考虑其中最相似(或距离最小)的K个文本, 根据这K个文本所属类别判断该待分类文本所属类别。KNN算法的关键在于K值的确定, 目前关于K值的确定还没有一个很好的方法, 一般先给定一个初始值, 再根据实验结果调整K值。另外, 也可以采用动态K值, 每个类别的K值为训练集中该类别的文本数, 对每个类别, 统计与待分类文本最相似的K个文本中属于该类别的文本数所占比例, 比例最高的类即为该待分类文本所属类别。
本文提出的类平均相似度分类算法来源于聚类密度的概念[ 16],聚类密度的基本思想是: 在文本分类中, 某一类别文本的密度, 可用该类别中每对文本之间的平均相似度表示[ 16]。
| (2) |
其中,
| (3) |
其中,
通过比较待分类文本在不同类别下的平均相似度便可以找到最适合该待分类文本的类别, 在此基础上, 本文提出一种基于类平均相似度的分类算法, 算法的基本思想是: 根据传统向量空间模型, 文本被表示为特征空间上的加权特征向量, 即
类平均相似度算法的具体步骤如下:
(1) 对待分类文本d, 经过分词、过滤、初步统计等处理, 将其表示为特征空间上的向量;
(2) 计算该待分类文本与训练集类别Ci中每篇文本的相似度, 相似度计算采用余弦相似度, 如公式(2)所示;
(3) 计算训练集类别Ci下所有文本相似度的平均值, 计算公式为:
| (4) |
其中,
(4) 比较待分类文本与各类别的相似度, 将相似度最大的类别分配给该待分类文本。
类平均相似度算法是一种简单、稳定、有效的分类算法, 相比于KNN算法有很大优势: KNN算法需对每篇待分类文本与训练集所有文本的相似度进行排序, 时间复杂度高而导致分类效率低, 而类平均相似度算法无需对各文本相似度进行排序, 因此时间效率高; KNN算法需事先确定K值, K值的选择直接影响分类结果, 对不同的实验材料需通过反复试验以确定最优K值, 而类平均相似度算法无需事先设定K值, 保证分类结果的稳定性; 两种分类算法分类结果都会受数据分布的影响, KNN算法受实验数据的分布影响较大。
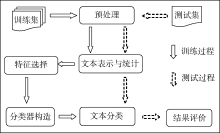
本文针对KNN分类算法存在的分类准确率不理想、时间效率低等问题, 在传统向量空间模型的基础上, 提出一种适用于长文本分类的基于类平均相似度的文本分类新算法。分类框架如图1所示:
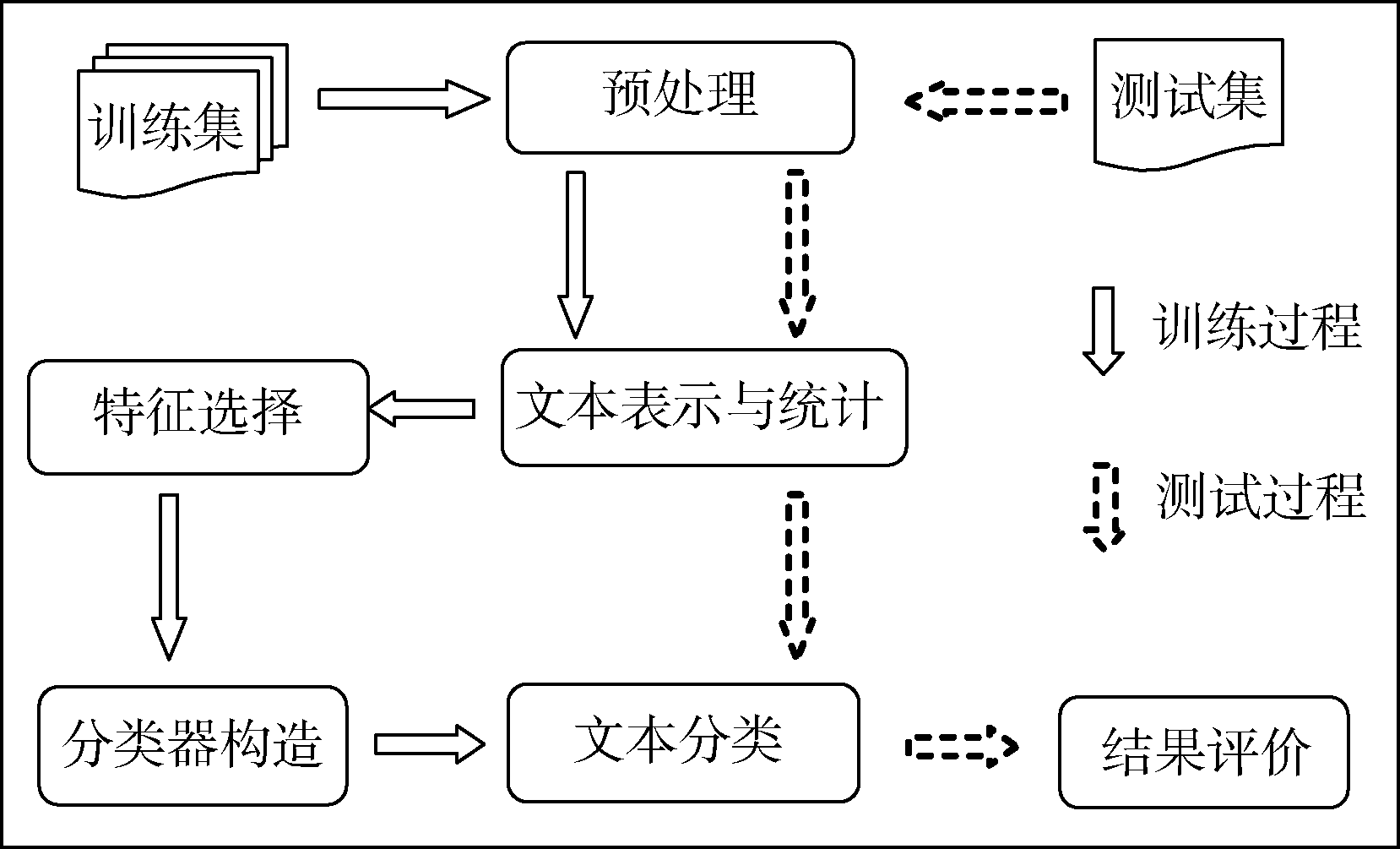 | 图1 基于类平均相似度的文本分类系统框架 |
文本分类包括训练过程和测试过程, 训练过程是指通过给定类别的训练集数据和分类模型, 生成相应的文本分类器, 包括预处理、文本表示、特征选择(或特征提取)和分类器构造等过程; 测试过程则是利用训练过程生成的文本分类器对测试集文本(或待分类文本)分配类别号, 进行分类, 包括预处理、文本表示、文本分类、结果评价等过程。具体分类步骤如下:
(1) 训练过程
①预处理。包括分词和过滤, 本文采用中国科学院计算技术研究所ICTCLAS分词法对文本进行分词, 建立停用词表, 过滤对类别区分贡献较小的虚词;
②训练集文本表示。统计训练集中每个特征词在各类别及文本中出现的频数, 利用向量空间模型将文本表示为特征空间上的向量;
③特征选择。选择对文本分类贡献较大的特征词作为分类器特征项, 过滤对分类贡献较小的特征词。特征选择的两个关键问题是特征选择方法和特征项维数的选取;
④分类器构造。通过计算每个特征项权重构造特征项权重矩阵, 本文特征项权重计算采用传统TF-IDF算法。
(2) 测试过程
①预处理。包括分词和过滤, 同样采用ICTCLAS分词法对文本进行分词, 建立停用词表, 过滤对类别区分贡献较小的虚词;
②测试集文本表示。对过滤后的测试集文本与特征选择后的训练集文本进行映射, 统计测试集中每个特征词在各类别及文本中出现的频数, 将文本表示为特征空间上的向量, 具体算法如下:
输入: 训练集特征选择后的特征项维数N, 过滤后的测试集文本d
输出: 测试集文本表示矩阵
对测试集文本d, 过滤N中未包含的特征词;
统计测试集文本d中各特征词在各类别中的频数, 形成特征词矩阵。
③文本分类。采用的分类方法包括KNN算法和本文提出的类平均相似度算法;
④结果评价。对分类结果进行评价, 评价指标采用宏平均F1值和微平均F1值。
本文采用的实验数据为复旦和Sogou公开语料库。复旦语料共3 736篇, 其中训练集1 400篇, 测试集2 336篇, 分为艺术、经济、计算机、体育、环境、航空、历史7个类别; Sogou语料共4 476篇, 其中训练集1 400篇, 测试集3 076篇, 分为经济、计算机、军事、体育、医学、旅游、艺术7个类。为验证非平衡语料对本文方法的影响, 另将Sogou语料设置为非平衡语料, 各类别文本分布如表1所示:
| 表1 语料库各类别文本分布 |
评价分类结果有效性的指标主要有查全率、查准率和F1值, 设Ti表示第i类结果中分类正确的文本数, Ci表示分到第i类的文本数, Ni表示第i类实际包含的文本数。
查全率衡量实际属于某一类别的文本中被分到该类别文本的比率, 公式为[ 17]:
| (5) |
查准率衡量被分配到某一类别的文本中分类正确的文本的比率, 公式为[ 17]:
| (6) |
F1值是一种常用的将查全率和查准率综合起来考虑的性能评估方法, 公式为[ 17]:
| (7) |
查全率、查准率和F1值都是针对单类别, 当评估某个分类方法的整体性能时, 需要综合考虑各个类别的结果, 采用宏平均F1(Macro_F1)和微平均F1 (Micro_F1)来评估方法的整体性能, 其计算公式为[ 17]:
| (8) |
| (9) |
| (10) |
| (11) |
| (12) |
| (13) |
其中, M是类别数。
采用ICTCLAS汉语词法分析系统对语料库进行分词, 并去除停用词。
为验证本方法的有效性和优越性, 比较了类平均相似度算法与传统KNN分类算法的分类结果, 并进行了以下三个方面实验:
(1) 实验一: 比较不同特征数目下, 类平均相似度算法与KNN分类算法的实验结果, 特征选择方法采用卡方统计, KNN算法采用动态K值。
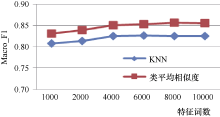
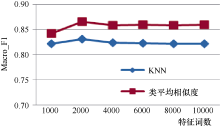
比较特征选择过程中特征数为1 000-10 000时本方法与KNN分类算法的分类效果, 特征选择方法采用卡方统计, 实验采用复旦和Sogou1语料, 实验结果如表2和图2、图3所示:
| 表2 不同特征词数下两种分类算法实验结果对比 |
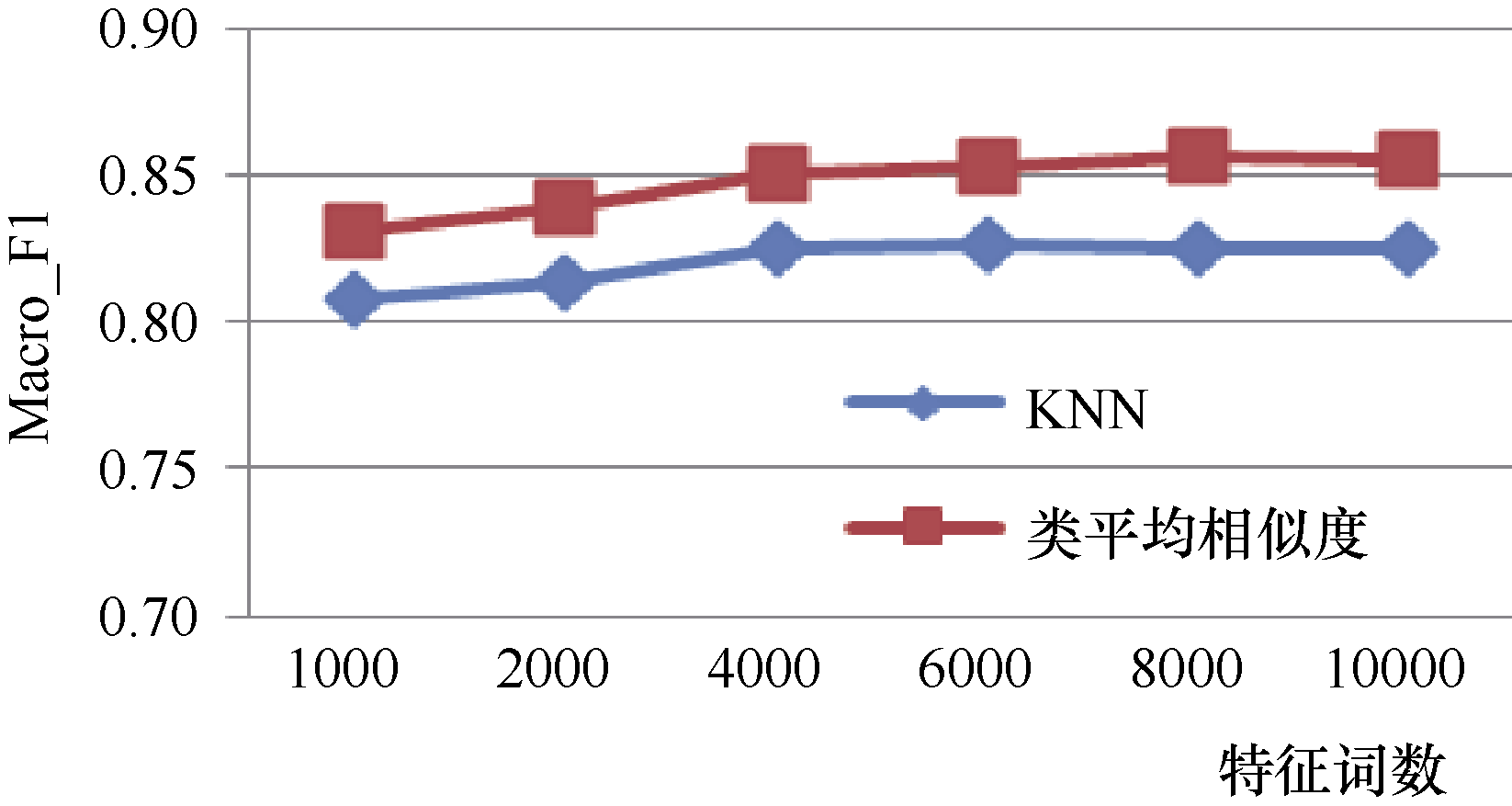 | 图2 Sogou语料不同特征词数下两种分类算法实验结果比较 |
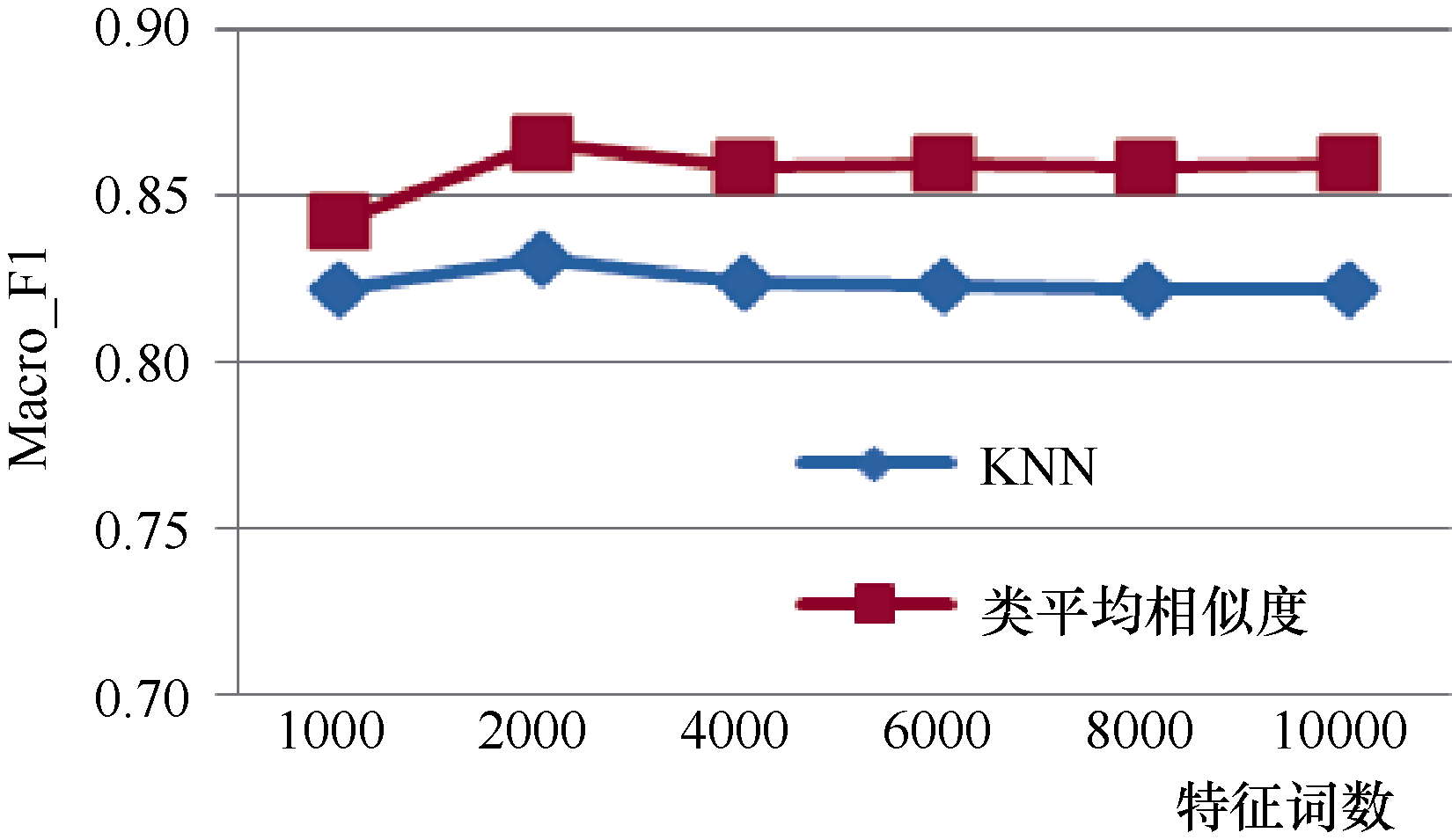 | 图3 复旦语料不同特征词数下两种分类算法实验结果比较 |
由表2和图2、图3可以看出, 对于Sogou、复旦语料库, 结果随着特征词数的增加, 两种分类算法的分类结果先增加, 然后趋于稳定, 分类时间则不断增加; 综合考虑分类结果和分类时间, 对于Sogou语料, 特征词数为4 000时, 分类性能最佳; 对于复旦语料, 特征词数为2 000时, 分类性能最佳。
类平均相似度算法在Sogou、复旦语料上的Macro_F1分别达到85.8%和86.6%, 比KNN算法分别提高3.2%和3.5%, 分类时间约为KNN算法的1/6和1/22。总的来说, 对于Sogou、复旦公开语料库, 类平均相似度算法无论在分类结果还是分类时间上均优于KNN分类算法, 是一种实用的分类算法。
(2) 实验二: 比较不同特征选择方法下, 类平均相似度算法与KNN分类算法的分类结果, 特征数目为实验一的最优结果。
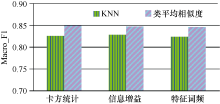
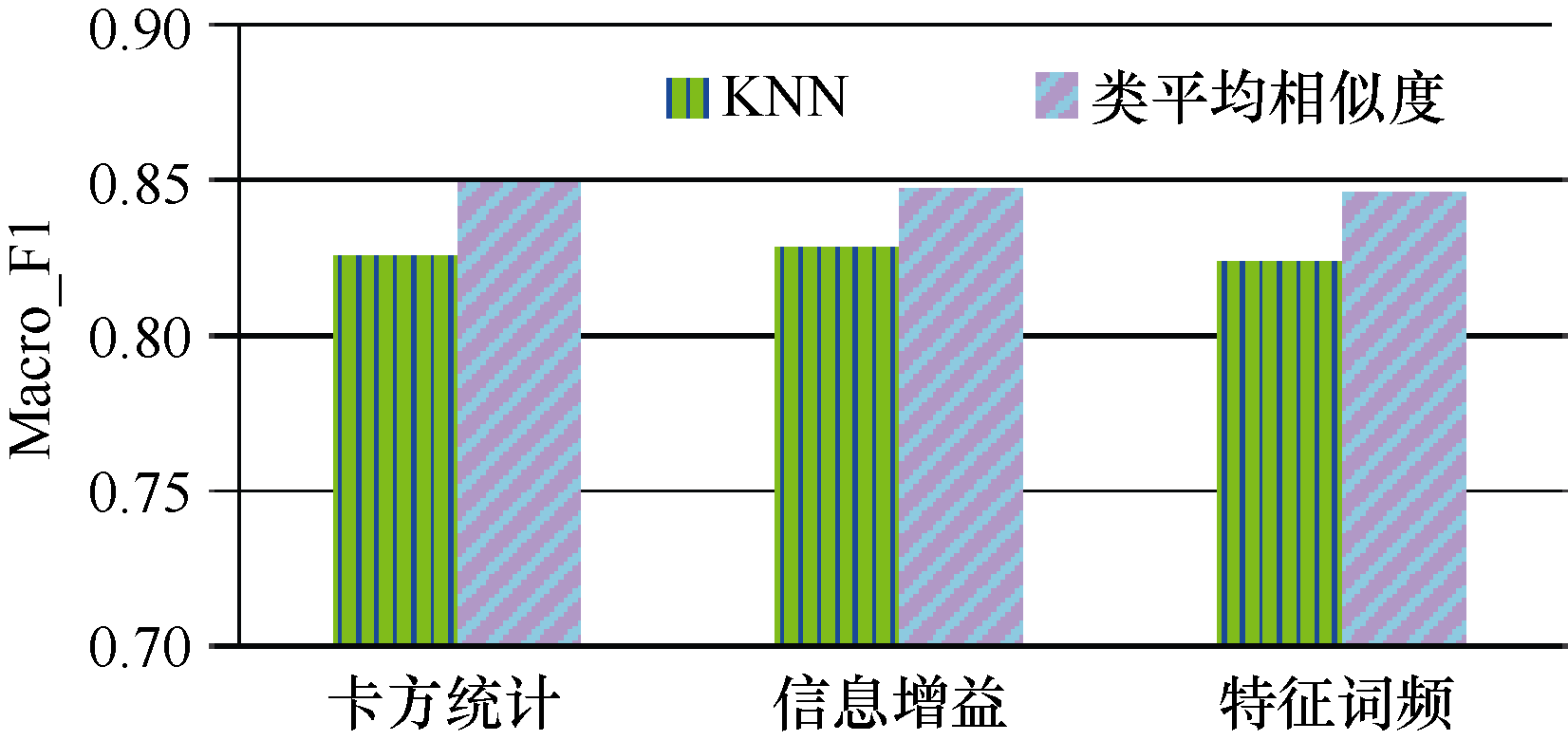
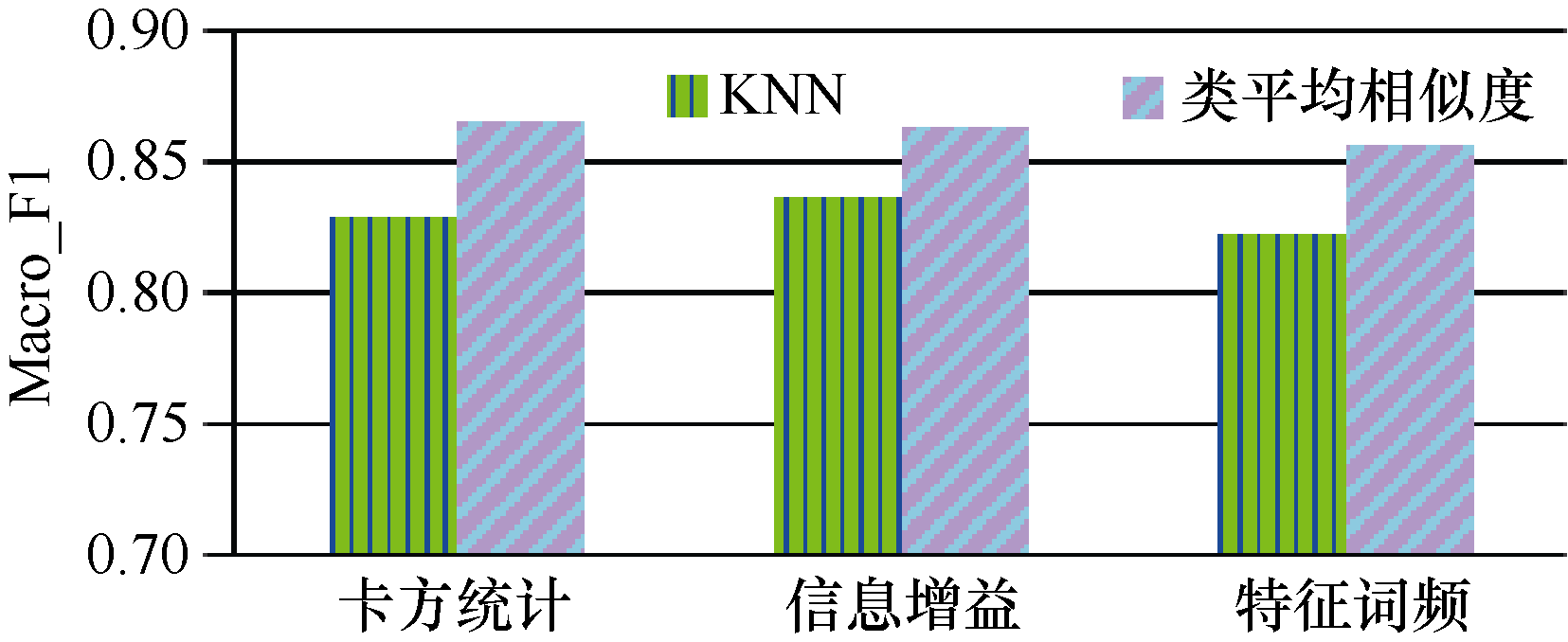
采用卡方统计、信息增益和特征词频三种特征选择方法, 比较本方法与KNN分类算法的分类效果, 两种分类算法中, 复旦语料特征词数为2 000, Sogou语料特征词数为4 000。实验采用复旦和Sogou1语料, 实验结果如表3和图4、图5所示。
| 表3 不同特征选择方法下两种分类算法实验结果对比 |
 | 图4 Sogou语料不同特征选择方法下两种分类算法实验结果比较 |
 | 图5 复旦语料不同特征选择方法下两种分类 算法实验结果比较 |
由表3和图4、图5可以看出, 对于Sogou、复旦语料, KNN算法在信息增益方法上的分类结果略好于卡方统计和特征词频, 类平均相似度算法在三种特征选择方法上的分类结果基本一样; 从分类时间上看, 卡方统计在两种语料、两种分类算法上分类时间最短, 特征词频最长。
类平均相似度算法在卡方统计方法上两种语料的Macro_F1分别达到85.1%和86.6%, 比KNN算法分别提高2.6%和3.5%; 在信息增益方法上分别为84.7%和86.5%, 比KNN算法分别提高1.9%和2.7%; 在特征词频方法上分别达到84.5%和85.7%, 比KNN算法分别提高2.1%和3.3%。综合考虑分类结果和分类时间, 对于本实验中的两种材料和两种分类算法, 卡方统计和信息增益方法略好于特征词频。总体来说, 类平均相似度算法在三种特征选择方法上的分类结果均好于KNN分类算法, 达到了实用水平。
(3) 实验三: 比较非平衡语料下KNN算法与类平均相似度算法的分类结果。
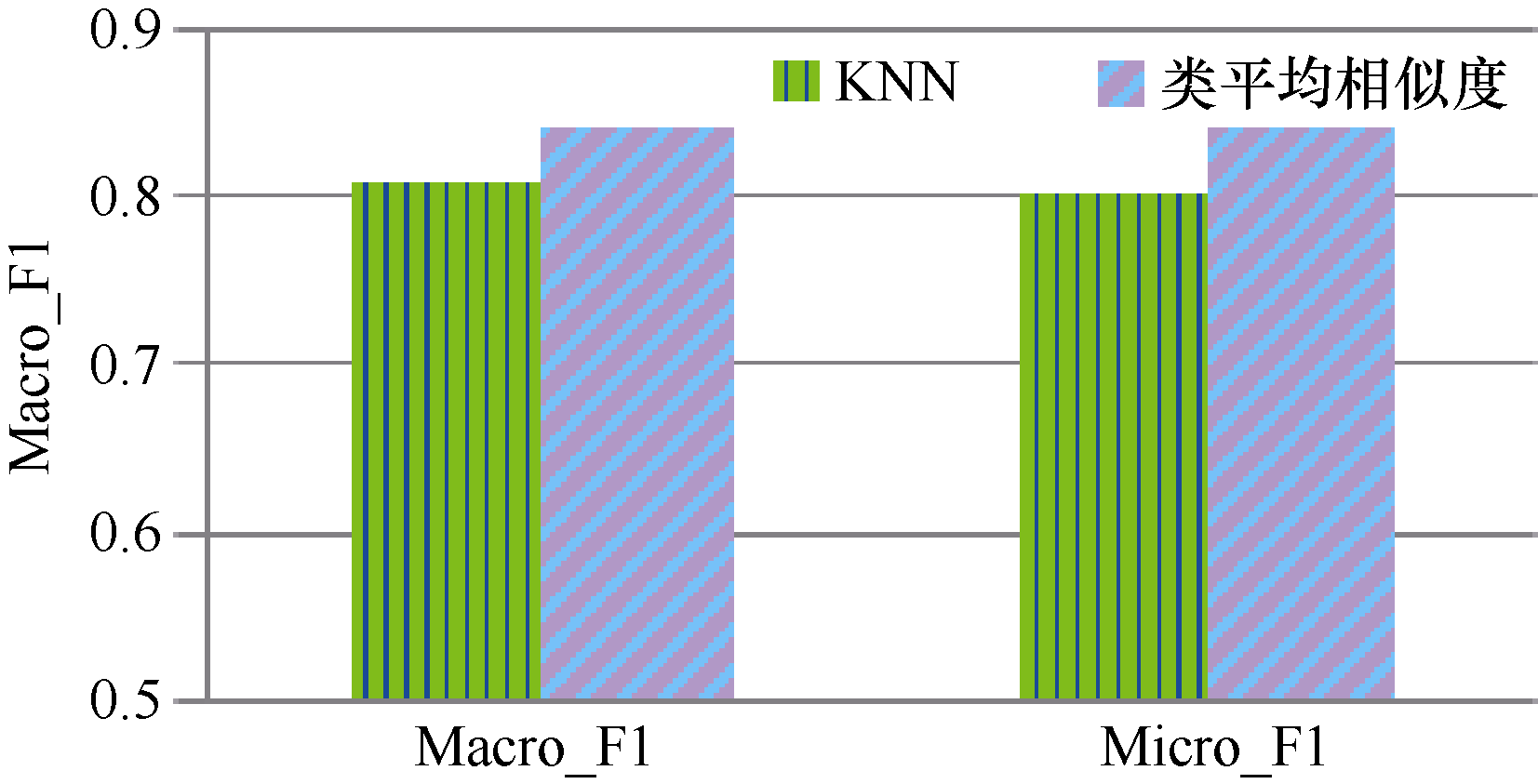
特征选择方法采用卡方统计, 特征词数取4 000, 实验采用Sogou2语料, 实验结果如表4和图6所示:
| 表4 非平衡语料下KNN算法与类平均相似度算法的分类结果比较 |
 | 图6 非平衡语料下KNN与类平均相似度的 分类结果比较 |
由表4和图6可以看出, 类平均相似度算法在Sogou非平衡语料上的Macro_F1达到84%, 比KNN算法提高3.3%, 与实验二中的Sogou1结果相比, KNN算法和类平均相似度分类结果都有所下降, 其中, 类平均相似度下降1.1%, KNN算法下降了1.8%, 这也验证了数据分布不平衡影响文本分类效果、类平均相似度影响比KNN算法小的结论。
以上实验证明, 由于“非作用词”的存在, 特征词数过多反而会影响分类效果; 三种常用特征选择算法的分类效果相差不大, 卡方统计和信息增益略好于特征词频; 对于非平衡语料, 类平均相似度算法的分类结果好于KNN算法, 与平衡语料相比, KNN算法的影响较大; 整体来说, 类平均相似度算法在不同特征选择方法、不同特征词数、非平衡语料下的分类效果都好于KNN算法, 验证了本文方法的有效性和优越性。
在传统向量空间模型的基础上, 针对KNN分类算法存在的速度和精度问题, 本文提出一种基于类平均相似度的分类算法, 并比较了其与KNN算法在不同特征选择算法、不同特征词数条件下的分类效果。实验结果表明, 相比于KNN算法, 类平均相似度在Sogou、复旦公开语料库上有更好的表现, 且分类速度更快。下一步工作包括: 将本文方法应用于更大规模文本分类, 进一步验证本方法对大规模文本分类的优越性; 对现有分类算法做进一步改进, 在提高分类速度的同时, 不断提高分类效果。
OCLC和Elsevier合作改善电子内容的访问
OCLC正在和世界领先的科学、技术、医学信息产品及服务提供商Elsevier进行合作, 研究如何将Elsevier文献检索平台ScienceDirect上的电子书和电子期刊自动更新到WorldCat和图书馆的目录之中。这一自动化过程能确保用户无缝地访问图书馆订阅的内容, 无需图书馆工作人员的干预。
图书馆将能够请求Elsevier向OCLC提供该馆在ScienceDirect上所订阅内容的馆藏数据, 这些数据将会加载到WorldCat知识库, 知识库中包含图书馆电子资源的相关信息, 以及访问资源的链接。馆藏数据将会被自动同步到OCLC目录库中, 无需图书馆工作人员手动干预。
“OCLC和Elsevier的合作将会帮助图书馆员通过自动化程序将ScienceDirect电子书和电子期刊的目录和馆藏信息保持最新。” OCLC业务发展部副总裁Chip Nilges认为: “这样便会大大节省图书馆的时间, 使得用户能够更加快速、简便和可靠地访问这些电子资源。”
Elsevier第三方平台关系主管Alexandra de Lange说: “非常高兴能够和OCLC继续合作。自动化之后的简便过程可以确保读者能够无缝访问内容。这一合作是朝向我们不断改进内容可用性这一目标迈出的重要一步。我们有信心用户会非常高兴参与这项服务, 并且在其管理流程的效率提高方面获益。”
(编译自: http://oclc.org/news/releases/2014/201423dublin.en.html)
(本刊讯)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|