



{kind=link}
{kind=link}
{kind=link}
{kind=link}
超球支持向量机文本分类方法改进
[胡吉明 , 陈果]
, 陈果]
, 陈果]
|
|


作者贡献声明:
胡吉明: 提出研究思路, 设计研究方案, 实施研究过程, 撰写和修正研究论文; 陈果: 采集、清洗和分析数据并进行对比实验。
【目的】针对文本分类中类别特征向量改变和重叠等问题, 对超球支持向量机(HS-SVM)分类算法进行改进。【方法】基于增量学习和密度决策函数对原始HS-SVM进行改进, 实现超球类支持向量的动态改变, 准确计算构造超球支持向量机的决策函数, 从而达到提高文本分类效果的目的。【结果】与原始超球支持向量机的文本分类实验对比表明, 本文所提方法在准确率和召回率方面优于其他方案, 建模时间减少且对预测精确度的影响不大。【局限】应进行多种类型数据集上的实验验证, 推广方法改进的适用性; 其次对分类算法的底层改进欠缺, 需继续探索。【结论】本研究有利于提高大规模文本分类的准确性和减少训练时间, 从而提升文本分类效果。
[Objective] In terms of the class features vector changing and overlapping, this paper improves the classification algorithm conducted by super ball supported vector machine.[Methods] Starting from combing the operational mechanism of LDA and HS-SVM, as well as the related studies, this paper constructs a text classification model based on LDA and HS-SVM. The traditional HS-SVM is improved considering incremental learning and intensive degree, and then the dynamic change of hyper-sphere class’ support vector would be achieved and the decision function for constructing hyper-sphere support vector machine would be accurately calculated.[Results] The effect of text classification can be improved from the perspectives of precision rate and recall rate. Comparative experiments are conducted and the results demonstrate that methods in this article are feasible and effective which can effectively improve texts classification. In addition, this method reduces the time of modeling and has little influence on accuracy of predication.[Limitations] Noted that the proposal in this paper is comparatively more complex than the original algorithm that need continuous improvement; and the results needs experiments on more data sets. Meanwhile, the improvement on essence of algorithm is not optimal which is necessary to be further studied.[Conclusions] This study is helpful to improve the accuracy and reduce the training time in large-scale text categorization, and also improve the efficiency and performance of text classification.
文本分类是信息过滤和推荐等系统服务实现的基础; 当前社会网络环境要求更加准确地进行信息资源的分类和关联, 在给定类别的情况下, 根据训练集推导出分类的判别公式和判别规则, 构造文本分类器判定未知文本的类别, 帮助系统和用户发现关联或相似的资源。
(1) 社会网络环境下文本信息的片段化、动态化趋势越来越明显, 结构复杂且语义内容丰富, 传统的基于关键词或主题词的文本向量建模方式已不再适用。而潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)主题模型[ 1]是一种产生式的三层贝叶斯概率主题模型, 将文本内容表示为潜在主题的有限混合, 能够最大程度地表示文本中所蕴含的语义关系; 同时, 具有很好的先验概率假设, 其参数数量不会随着文本数量的增长而线性增长, 泛化能力强, 推理算法便捷高效及展示效果好, 在文本主题提取[ 2]、分类聚类[ 3]、检索[ 4]、演化[ 5]、标注[ 6]等领域得到了广泛应用。
(2) 在大规模样本分类研究上, 超球支持向量机(Hyper-Sphere Support Vector Machine, HS-SVM)作为一种球面结构支持向量机, 采用计算一个能包含某个类全部样本在内的最近超球面的方法, 通过寻找一个最小包围球(Minimum Enclosing Ball, MEB)问题取代SVM的二次规划问题, 明显降低了整体复杂度且提升了分类速度和精度, 能够处理大规模的文本分类且易于扩充, 是一种比SVM更快和效果更好的分类算法[ 7]。如Strack等研究了大规模文本分类中的超球支持向量机算法实现问题[ 8], 结合最小包围球方法、最近点解决算法和概率技术, 在大规模甚至超大规模数据集上的实验发现, 超球支持向量机分类算法在速度和准确性上效果较好。Chau等通过Jarvis March算法寻找不可分割超球点的最佳凸面, 从而提高分类的准确性和速度[ 9]。Yun等指出随着分类训练样本数量的变化, 其超球半径及其分布将会发生变化, 应对其进行动态加权处理, 以保证最终的分类效果[ 10]。艾青等针对多主题分类问题, 基于超球支持向量机和样本与超球的隶属度计算, 判定文本所隶属的主题[ 11]。王德成和林辉通过构建包含少类样本的最小封闭超球体, 通过样本与球心的距离进行欠抽样, 以此实现训练集分类的平衡[ 12]。蒋华和戚玉顺引入主动学习方法, 将球结构支持向量机用于多标签分类, 采用样本近邻方法更新分类器, 实现较少样本的有效分类[ 13, 14]。
超球支持向量机因其在大规模样本分类上的明显优势, 成为研究者进行文本分类及其相关应用的热门分类算法。但是, 在分类过程中文本超球类会随着文本分类数量的增加而不断变化, 需要不断改变超球类的支持向量; 其次, 文本超球类并不是完全独立的, 存在语义或主题上的关联, 虽然针对这一特殊情况无法完全准确划分其类别, 但是可以通过概率决策最大程度地实现文本类别划分的准确性。因此, 本文针对当前文本超球类动态变化和难以划分主题重叠区域内文本的特点, 通过LDA主题模型提高文本建模的准确性, 利用增量学习实现超球类的动态变化以及借助密度决策函数实现文本主题划分的准确性。最后通过实验验证了该方案的有效性。
基于LDA和HS-SVM的分类模型如图1所示:
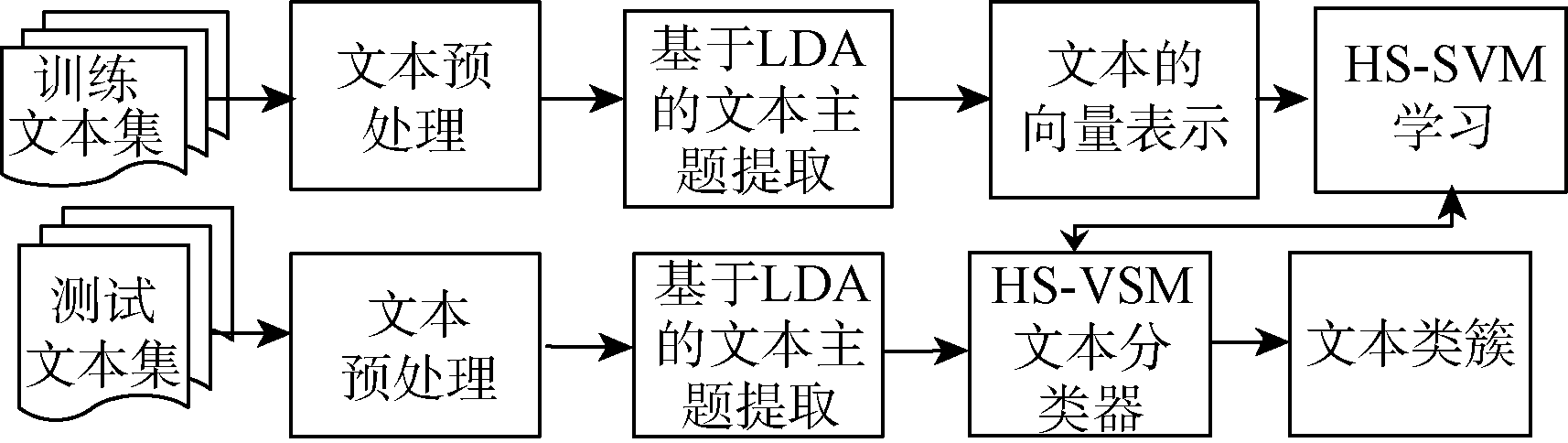 | 图1 基于LDA和HS-SVM的文本分类模型 |
本文基于增量学习动态改变超球类的支持向量, 以适应文本分类中随着文本数量增加文本超球类总体特征向量改变的问题; 其次, 对于初步分类后出现的第三种情况, 即文本被多个超球类包含时, 采取密度决策函数计算比较待分类文本相对于超球类的密度, 将其归入密度最高的超球类, 从而完成最终的准确分类。
超球支持向量机分类的基本思想为: 对某个文本簇在超球半径尽可能小的情况下, 尽可能多地包含该类样本, 达到尽可能高的分类准确率; 当测试文本不处于任何一个文本超球类中时, 通过比较测试文本到各个超球类的距离, 将其归入距离最近的超球类中[ 15]。因此, 文本类簇采用一个最小包围球来界定, 文本簇不同所形成的最小超球也不同。在传统的HS-SVM分类算法中, 实际上每一超球类中边界上的点就是所得到的支持向量, 每个超球类的半径也就被确定下来, 当该类有新文本加入或者新加入的文本被该超球类包围时, 该超球类的支持向量保持不变[ 16]。实际上, 当有新文本加入超球类时, 类别的总体特征发生改变, 即该超球类中的支持向量发生了改变。因此, 本文利用增量学习方法[ 17]实现超球类支持向量的动态改变。
传统的批量学习方法为一种一次性学习过程, 即当得到所有训练样本并学习之后, 学习过程便结束; 但是当有新的数据增加时, 又需重新把所有样本学习一次; 这就带来了时间和空间的大量消耗。而增量学习方法可以渐进式的学习, 无需重新训练原先的样本, 并且可以根据新样本不断调整和修正样本的整体特征; 因此增量学习方法降低了对时间和空间上的要求, 在整体性能上更优[ 18]。基于增量学习的超球支持向量机算法实现的机理描述如下:
给定训练文本集合
因此, 对于待分类样本
①分类样本与超球球心的距离计算。计算
| (1) |
②若存在唯一的
③对于所有的
| (2) |
| (3) |
④若存在两个或两个以上的
| (4) |
⑤分类结束。
HS-SVM文本分类模型假设任意两个超球类是相互独立的, 所有文本都能够被正确分类; 但实际上因文本在语义或主题上是相关的, 存在文本超球类相互重叠的情况, 因此如何准确分类重叠区域的文本是当前研究的一个重要问题。如运用基于子超球支持向量机的分类算法对重叠区域文本进行分类, 对同类错误文本点和异类错误文本点再一次构造子超球以细化分类; 这种方法虽提高了分类精度, 但整个文本分类计算的复杂度大大增加[ 20]。
支持向量机中的决策函数是准确分类重叠区域文本的重要依据; 从密度(密集程度, Intensive Degree)上看, 待分类文本集与超球类之间的密度分布决定了其类别的相似程度, 即密度越大, 说明越有可能属于此超球类; 因此, 本文通过密度计算构造超球支持向量机的决策函数, 以达到对文本精确分类且降低复杂度的目的。
在基于密度决策函数的HS-SVM文本分类算法实现中, 将文本分为三种: 不被任何超球类包含的文本、只被一个超球类包含的文本以及被多个超球类包含的文本, 如图2所示。通过文本类别属性的区分, 将文本分类区分为两种: 前两种直接运用HS-SVM算法分类, 第三种采用基于密度决策函数的HS-SVM分类; 通过比较待分类文本相对于超球类的密度, 将其归入密度最高的超球类。
如图2所示, 两个文本集
 | 图2 超球类的重叠 |
为S1和S2,S1和S2重叠;S1在S2中的部分球面为S'1,S2在S1中的部分球面为S'2。设X0为S'2的一个支持向量,X0∈S'2, 则X0属于类B; 而从分类决策函数计算上看,f1(X0)
| (5) |
其中,
本文根据大多数研究中确立的分类步骤, 基于密度决策函数的HS-SVM文本分类算法训练步骤设定如下[ 8]:
假设文本集中
| (6) |
①对
②将k初始值定为1。
③以
| (7) |
④如果
在计算密度的基础上, 其决策算法步骤为:
①令
②如果
③如果
④分类结束。
本文实验采用中文文本分类语料库-TanCorp-V1.0[ 21], 共包含文本14 150篇, 选择电脑、房产、教育、科技和娱乐5类数据(共7 226篇), 采用ICTCLAS[ 22]预处理后作为实验的基础数据。 将这些文本前60% (4 336篇)作为训练集, 后40% (2 890篇)作为预测集, 如表1所示; 在参数调整确定后, 作为最终实验的依据。
| 表1 实验数据集 |
实验每次只针对5类数据中的一类进行训练, 因此训练超球数为5, 算法的复杂度为O(5)。首先, 对文本进行预处理形成特征空间向量, 通过LDA主题模型得到文本集中词汇在50个潜在主题上的概率分布, 以及潜在主题在每篇文本中的概率分布; 通过向量空间模型(VSM)构建文本向量。然后基于HS-SVM进行文本分类; 根据上述的算法分类过程, 在分类训练中只需要计算待分类文本与每一个超球心的距离就可得知该文本的所属类别; 因此, 该算法较快的分类速度和一个近似的最小类别包围球的最终结果保证了其分类性能。为了检验该HS-SVM的文本分类模型的性能, 本文在其他研究成果基础上, 将主题提取方法(LDA)和文本分类方法(HS-SVM和改进的HS-VSM)组合进行分类实验; 设计了2组对比实验。实验过程中HS-VSM采用LibCVM工具包[ 23], 核函数采用RBF核函数(其适应性和收敛性较好)[ 24], 系统参数
在文本分类评测方法中, 最常用准确率(
其中, a为正确分配给当前类别的文本, b为错误分配给当前类别的文本, c为正确未分配给当前类别的文本。
但是为了从整体上综合评测文本分类性能, 本文在上述基础上采用宏平均作为分类器的评估标准。
宏平均准确率:
宏平均召回率:
宏平均:
| 表2 文本分类实验结果对比 |
 | 图3 分类实验的总体Macro(F1)值对比 |
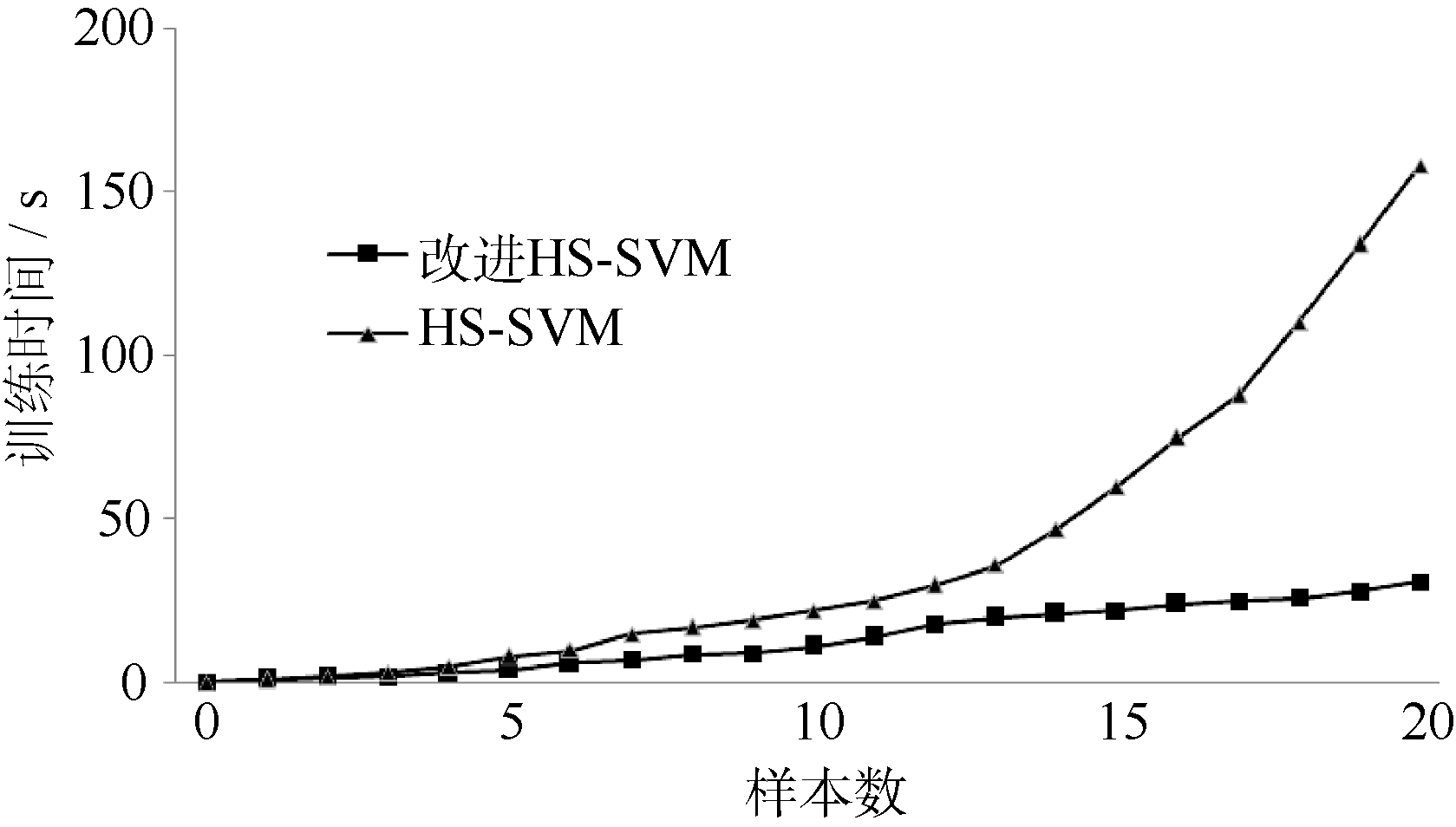 | 图4 训练时间对比 |
| 表3 每个数据集上的预测均方误差 |
如图4所示, 在训练时间上随着新样本的批次加入, 原始的HS-SVM训练方法的训练时间不断增加且较为明显, 而基于增量学习的HS-SVM训练方法的训练时间增加缓慢且较前者具有明显的下降。而且, 两种对比方法在最终建模的预测均方误差上比较接近, 如表3所示, 说明本文提出的方法虽加入了增量学习和决策函数计算, 但建模时间减少且对预测精确度的影响与原始方法差别不大。
根据上述实验结果, 本文提出的基于改进的HS-SVM的文本分类方法, 能够不断适应新文本加入对分类精度的影响, 有效地改善重叠区域文本的分类精度, 总体上性能和效果优于原始方法。
本文研究了文本分类中类别向量动态改变和类别重叠情况下的文本准确分类问题, 提出了基于LDA和改进HS-SVM的文本分类框架, 将增量学习和密度决策函数作为HS-SVM改进的基础, 并通过实验验证了此方案对文本分类的有效性。通过超球类支持向量的动态改变准确划分文本类别, 并降低了复杂度; 根据文本集与超球类之间密度计算, 最大程度地保证了重叠区域文本的类别划分。进一步, 将扩大实验范围和数据集规模, 继续寻找超球支持向量机算法下的最优分类方案。
Ingram和SirsiDynix合作扩大MyiLibrary的应用范围
Ingram内容集团于近日宣布与SirsiDynix公司开始一项合作, 以简化电子内容的发现和传递, 扩大双方产品的应用范围。Ingram将会把其MyiLibrary电子书平台与SirsiDynix的电子资源中心(eResource Central)集成起来, 共同提供对50多万条目的访问。
“将MyiLibrary平台的电子资源和SirsiDynix的电子资源中心集成起来能够帮助双方的图书馆用户更容易地发现更多的内容。”Ingram图书馆服务公司副总裁兼总经理Dan Sheehan说道: “我们很高兴能与SirsiDynix公司合作, 以提高全球图书馆的数字体验。”
SirsiDynix公司为图书馆提供全方位的资源开发工具。SirsiDynix的电子内容管理解决方案——电子资源中心可以通过一个单一的用户界面访问所有的电子书以及来自不同供应商的其他电子资源。此次合作中, 来自Ingram的MyiLibrary内容补充到SirsiDynix的电子资源中心之后, 将会拓宽电子资源中心现有内容的范围, 能够大幅增加图书馆用户及其读者可发现和可借阅的数字内容条目数。这些内容预计于2014年第三季度与读者见面。
对图书馆而言, 电子资源中心能够通过管理许可和访问权限的方式节约成本, 并简化将多个来源、多种格式的内容传递给用户的过程; 能够自动更新图书馆电子资源元数据; 能够将电子资源使用情况整合到流通报告中; 能够管理电子内容的采购和传递。
“很高兴能够与Ingram这样的领先内容提供商合作, 使得全球范围内数以千计的图书馆和图书馆用户能够享受到更多的内容。” SirsiDynix首席执行官Bill Davison指出: “电子资源中心在内容提供者和读者之间架起了一座桥梁, 使得图书馆能够无缝地、经济地管理和传递电子资源。”
(编译自: http://www.ingramcontent.com/PressReleases/Pages/Ingram's-MyiLibrary-Platform-Available-to-More-Libraries-through- SirsiDynix-eResource-Central.aspx)
(本刊讯)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|