







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于评论产品属性情感倾向评估的虚假评论识别研究
[陈燕方1, 2  , 李志宇
, 李志宇1, 2, 3 ]
, 李志宇|
|


作者贡献声明:
陈燕方: 研究方案初步设计, 问卷设计, 论文起草撰写, 论文最终版修订; 李志宇: 研究方案修改, 数据采集, 清洗, 算法设计与实现。
【目的】提出一种基于评论产品属性情感倾向评估模型(Review Attribute of Product-Based Emotion Evaluate, RAPBEE模型), 用于在线商品虚假评论的识别。【方法】针对在线商品虚假评论采用评论产品属性情感倾向离群度量方法, 结合已有评论效用研究对评论结果进行综合排序, 从而得出评论的可信度序列。【结果】基于R语言实现, 在模型试验集上, 通过RAPBEE模型识别处理后的评论序列和当前商品真实情况的符合度为86.2%, 实验结果表明RAPBEE模型有较强的实际应用能力与适应度。【局限】需要依赖于已有属性词典的建模方式, 在大规模的数据运行效率上有待改进。【结论】提供一种新的针对中文商品虚假评论识别处理方法, 具有较强的扩展能力。
随着现代电子商务的高速发展, 在线商品评论已经成为消费者进行网络购物决策的重要参考依据之一, 同时也能够为商家进行服务或商品的改进提供良好的指导依据[ 1]。近年来, 国内外关于在线商品评论的研究重点逐步由观点挖掘转向虚假评论的识别(Review Spam Detection)。其中, 国外较为具有代表性的研究是Jindal等[ 1, 2, 3, 4]的系列文章, 这也使得虚假评论成为社会计算方向下有关情感分析和观点挖掘的重要研究热点之一。相对来说, 国内有关这方面的研究起步较晚, 且研究内容相对国外而言缺乏新颖性和实质性的进步[ 5]。
本文首先对在线商品评论的分类进行重新界定, 并就在线商品“虚假评论”与“垃圾评论”的区别进行了辨析, 然后针对现有虚假评论识别方案存在的问题, 提出了基于评论产品属性情感倾向评估方案(Review Attribute of Product-Based Emotion Evaluate, RAPBEE)的逻辑模型, 并分析了模型实现的两个主要算法及其特点, 进而采用R语言实现。
本文的主要贡献包括:
(1) 提出利用产品评论属性情感倾向的离群度对在线商品可信度进行排序的方法, 以此达到对虚假评论进行有效处理的目的, 为虚假评论的识别提供了一个新的可行方案。
(2) 解决了当前中文虚假评论识别存在的问题, 并取得了良好的实验效果, 为社会计算方向下——观点挖掘与情感分析的扩展提供了一定的思路。
(3) 基于R语言实现, 并公开了全部的词典和数据, 为后续研究增加了可行的实验方案和材料。
在线下市场, 消费者购买商品时的决策依据在很大程度上依赖于现实生活中相互之间的产品口碑传播。随着互联网应用的高速发展, 在线商品评论开始产生, 传统口碑开始向电子口碑过渡, 在线商品评论信息已成为消费者进行网络购物决策时的重要参考依据之一。伴随着在线商品评论的丰富化和多样化, 在线商品虚假评论开始逐步进入人们的视野。
在线商品虚假评论至今并没有一个独立统一的定义, 由于目前对在线商品虚假评论的研究多等同于“垃圾评论”的研究, 因而大部分学者采用Jindal等[ 3]提出的对“垃圾评论”的定义和分类, 即“垃圾评论”分为虚假评论(Untruthful Opinion)、无关评论(Reviews on Brands Only)以及非评论信息(Non-reviews)三种类别。孟美任等[ 6]将“虚”和“假”分开定义, 其中“虚”是指滥发却没有任何价值的评论信息, 事实上这里的“虚”即指Jindal等定义中的第二和第三类垃圾评论。而笔者认为, 国内学者在对Jindal等文章中关于“Review Spam”一词的引用存在误解, 即将它释义为“垃圾评论”是有偏差的。
国内学者在引用“垃圾”一词时, 多源自“垃圾邮件、垃圾链接”之类的计算机专业术语。但从本义上来讲, 这里的“Review Spam”则应被称为“虚假评论”。在Jindal等的研究网站[ 7]中, 关于“Review Spam”列出了三个等价词语: “Fake Review”、“Bogus Review”和“Deceptive Review”, 由此可以看出以前国内学者将这类评论定义为“垃圾评论”是存在误解的, 如果解释为“垃圾”则更加倾向于“无用”之意, 因此笔者将其改称“虚假评论”。然而无论是将虚假评论等同于垃圾评论来研究, 或是将“虚”和“假”分开, 以上学者对在线商品虚假评论的界定都是从行为主体者动机出发。即虚假评论指那些为达到促销自家商品、提升自身信誉或诋毁竞争者商品的目的而发表的不真实的过高或过低的评论, 从而故意误导消费者或是干扰平台意见挖掘系统。这里的行为动机主要来源于商家为提升自身销售量, 实现利益最大化。
笔者认为, 在线商品虚假评论的分类应该从评论最终的作用主体——消费者为起点进行分类, 即从评论信息效用的角度进行分类。分类方式如图1所示:
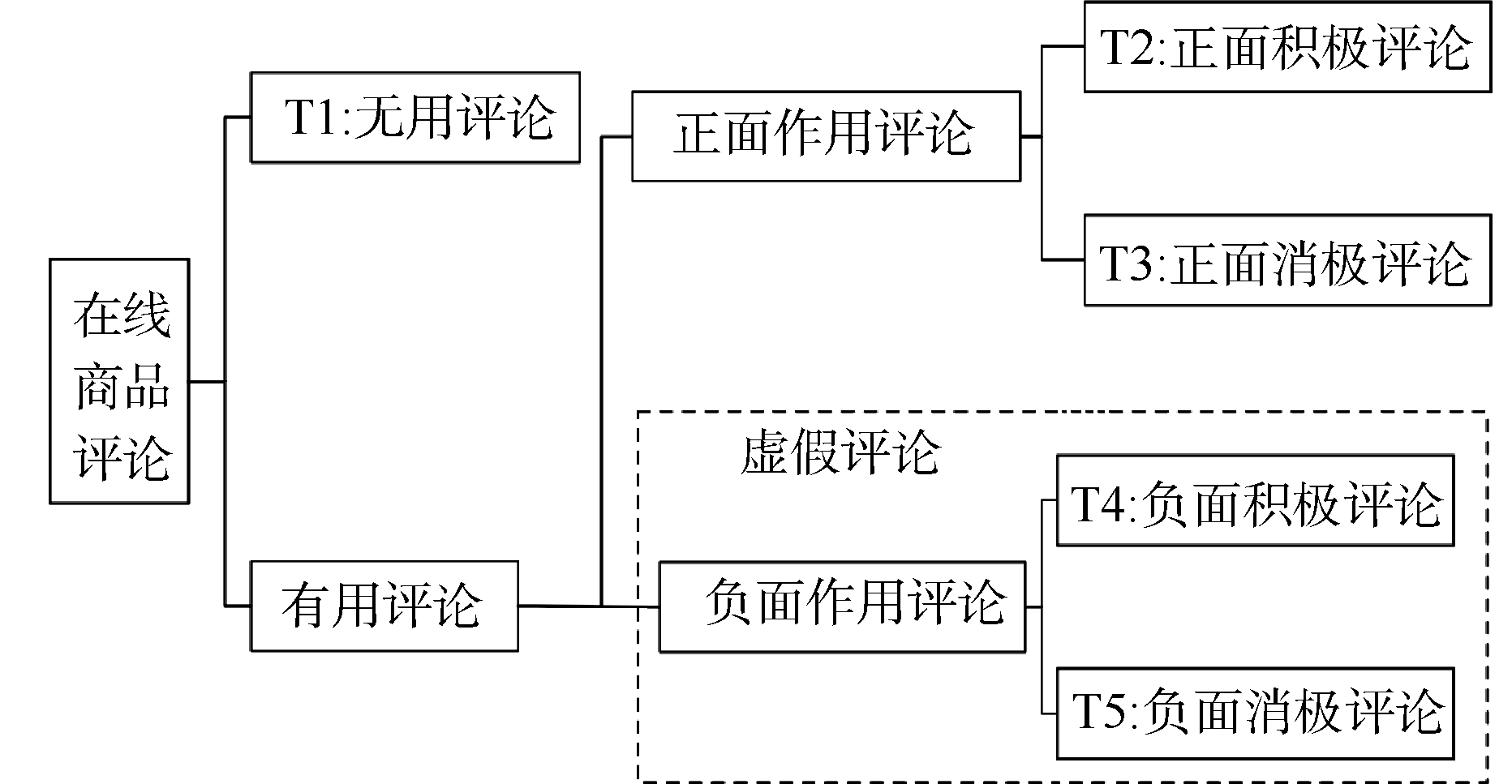 | 图1 在线商品评论的分类 |
在线商品评论从评论信息效用的角度可以分为有用和无用评论。有用评论是指能够对消费者的购物决策产生作用(这种作用既可能是正面的促进, 也有可能是负面的误导)的评论, 而无用则是指类似广告、乱码之类和商品本身无关的信息评论, 无用评论信息往往对于消费者而言极易辨别, 无法误导其购物决策。在有用评论中, 根据其对消费者购物决策的作用类型, 将其分为“正面作用”和“负面作用”。正面作用能够辅助消费者做出正确的购买决策, 包括促使消费者购买到符合心理预期的产品和阻止消费者购买到掺假虚夸的产品; 负面作用评论则是误导消费者进行错误购买决策的相关评论, 包括阻止消费者购买到符合心理预期的产品和诱导消费者购买到掺假虚夸的产品。因此在处理模型中, 最终目的是将可能的负面作用评论识别出来, 即进行可信度排序。
在已有的研究中, 在线商品虚假评论识别主要从三个方面展开:
(1) 元数据特征: 包括评论者元数据(评论者信誉、年龄、方式等)、评论内容元数据(包括评论字数、有用性得票、评论时间等)、产品元数据(包括产品价格、平均得分等)等;
(2) 文本特征: 评论内容的相似度、评论行为(风格)的相似度、评论特征内容(如第一人称、第二人称等)等;
(3) 情感特征: 评论积极、消极词汇比例(数目)、句子的主客观程度等。较为常用的识别模型主要有: 基于元数据特征与虚假评论或评论者的相关性评估模型[ 4, 8, 9], 基于评论文本特征的相似度检测模型[ 3, 10, 11], 基于文本特征内容评价模型[ 12]等。
笔者认为, 虚假评论的识别应以增加用户对评论内容的体验效用为出发点, 展开模型的设计与评价。如众多研究者所述[ 1, 6, 7, 10]: 虚假评论的识别目的是减少虚假评论对消费者的误导, 辅助消费者进行正确的决策。那么虚假评论的识别问题和在线商品效用排序的问题应该是紧密联系的。换句话说, 评论的可信度越低, 则对消费者的效用也就越低。因此, 在RAPBEE模型构建的末尾环节, 在基于评论可信度排序的基础上, 进一步利用评论效用排序算法[ 13]改善评论质量, 从而辅助消费者在可信前提下做出正确的购物决策。模型的实验结果表明, 该模型具备较强的适应性和可扩展性以及较高的消费者辅助决策满意度。
2.1 关键词典定义
RAPBEE模型中的关键词典主要包含三个部分: 通用属性词典、个性化属性词典、情感倾向词典。
定义1: 通用属性词典。通用属性词典是指由用于描述商品或者服务的特征词组成的词典, 主要包括服务评价、产品评价、指导性评价、整体性评价4个方面。通用属性词典是对产品评论的抽象集合, 即消费者有关产品属性的评论内容集中于表1所示的部分, 并且具备很强的相关性。该词典总共包含743个通用特征属性词汇, 由近100万条来自淘宝、京东、当当网等大型网络购物商城的商品评论通过分词、词频统计后分类筛选而来, 具备较强的通用性和代表性, 词典中字段及其释义如表1所示:
| 表1 通用属性词典字段 |
定义2: 个性化属性词典。个性化属性词典是基于特定评论内容以及产品介绍而产生的属性词典。对于特定的商品, 个性化属性词典与通用属性词典关系如图2所示(以某款咖啡为例)。个性化属性词典的产生算法将在2.3节详细展开。个性化属性词典主要用于获取属于该商品特殊属性的相关词语, 在意义上和通用属性词典既有交叉重叠部分, 也有自身的特征, 它的完善与好坏取决于当前商品的评论数量。一般而言, 随着用户评论数量的增多, 商品个性化属性词典越加丰富和完善。
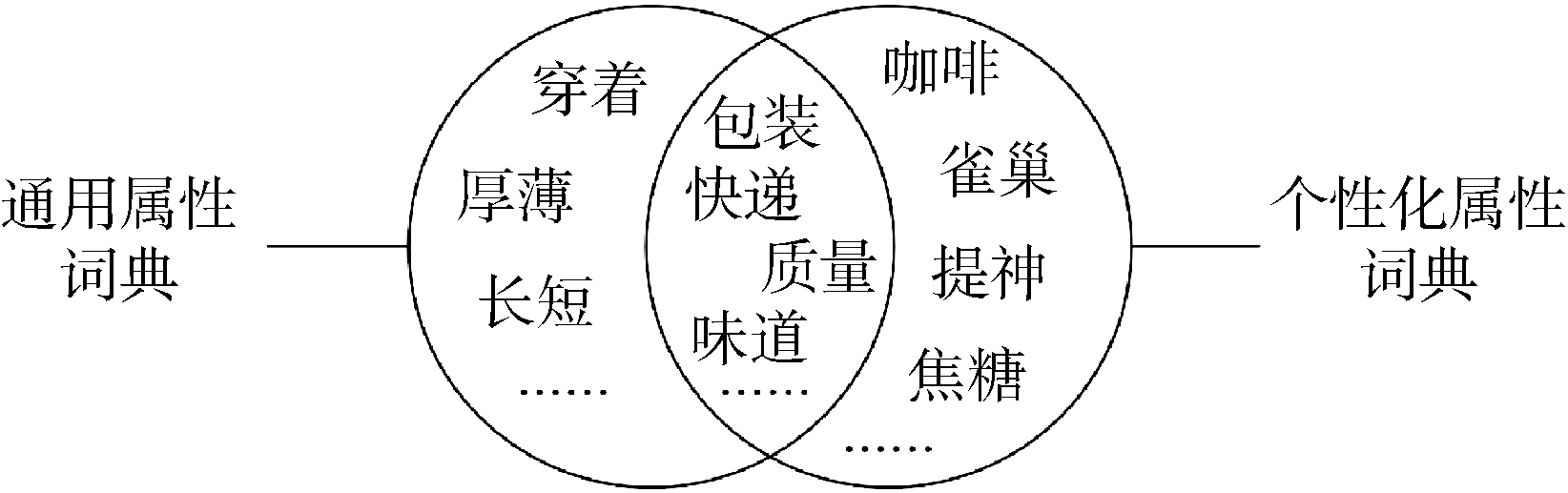 | 图2 通用属性词典和个性化属性词典的关系 |
定义3: 情感倾向词典。情感倾向词典的构建是RAPBEE模型实施的基础, 因此一个较好的情感倾向词典将在一定程度上决定模型的识别效果。目前而言,常用的中文情感词典主要包括知网HowNet情感词库[ 14]、台湾大学的情感极性词典[ 15]以及其他研究人员的情感词典。由于在线商品评论的特殊性, 笔者在上述情感词库的基础上, 结合现有的网络情感词、购物情感词, 筛选出常用的在线商品评论情感词库(总共约2 800个情感倾向词汇), 该词库对算法的运行效率和计算结果都有较好的改善作用。
在已有的研究中, 对于在线商品虚假评论的处理多采用“一次性”方案, 如文献[1]中的评论相似度匹配、文献[6]基于用户行为的识别、文献[16]基于群体用户行为等处理方案。这类方案主要有以下缺点。
(1) 忽视了新增评论对已有评论造成影响的可能性。由于在线商品评论的实时性与动态性, 时刻都可能有新的评论产生, 因此对于特定商品的新评论是否会影响已有评论的有效性和真实性, 这在以往研究中往往被忽略。
(2) 忽视了商家服务或者商品本身发生变化而导致已有评论“失真”的可能性。商家以盈利为基本目的, 因此商家极有可能在得到一定的好评数后降低服务质量, 但由于多数识别处理方案无法处理此类情形, 使得降低质量后的差评无法得到有效的展示而使消费者受害。反之, 同样可能存在商家发现自身服务或者商品存在不足后予以改进, 此时, 以前发表的有关不足的评论将变得“不真实”。
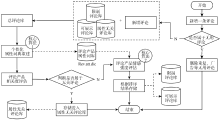
RAPBEE模型在解决上述不足的基础上, 形成了如图3所示的逻辑解决方案。
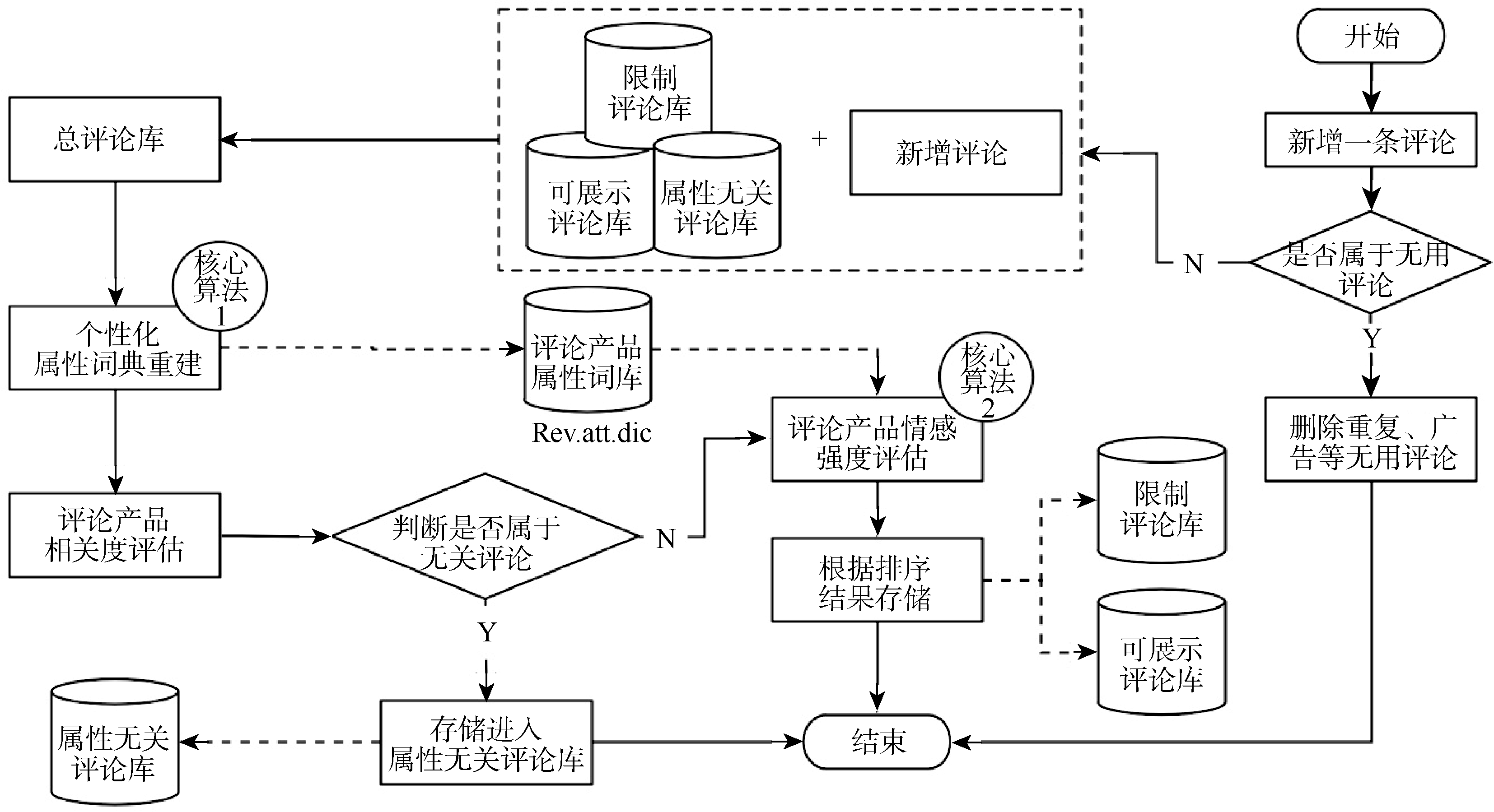 | 图3 RAPBEE模型逻辑结构 |
在该方案中, 对于商品的新增评论, 有两部分需要重新计算和处理:
(1) 个性化评论属性词典的重建。新增评论(非重复和广告等无用评论)产生后将联合已有的评论库(包含限制和非限制)对个性化评论属性词典进行重构;
(2) 属性情感可信度阈值的重建。新增评论的属性情感倾向将对已有评论的属性情感倾向均值造成影响, 因此必须在加入新增评论后, 对评论属性的离群点进行重新的测算和评估。因此任何商家的某些属性服务或者产品的质量变更, 都将反映到消费者的评论内容中, 从而使得所有评论关于该商品各个属性的评分的平均值发生相应的改变。
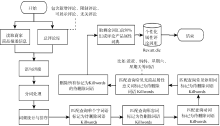
产品评论个性化属性词典的获取需要依赖于初始商品描述信息以及评论内容。初始商品描述信息往往来自于商家本身对商品的描述, 包括和产品服务相关的各类信息(因为这些信息可能在商品评论中被评价), 因此在此基础上构建的个性化属性词典更具有针对性。笔者在获取个性化属性词典时采用的方法较为简单, 主要涉及到文本提取、分词、词频统计排序、去重、去除停用词、形容词、动词、无意义属性词等操作(限于篇幅, 详细流程见模型代码), 其逻辑流程如图4所示:
 | 图4 个性化评论属性词典获取方法 |
2.4 产品属性情感评估算法
产品属性情感评估是RAPBEE模型中最为关键也是最核心的算法, 其中包含的较为重要的子算法是属性情感栈匹配算法, 下面将从算法要素定义展开。
(1) 算法要素定义
定义4: 评论产品属性相关度。产品的属性特征词多表现为名称或者名词性短语, 是对产品或者服务的客观性描述。评论中所包含的产品属性词越多, 那么相对无关评论而言, 其信息含量也就更为丰富和可观, 由此可以降低过强情感倾向带来的不可信度, 同时对消费者的辅助决策作用也越明显。因此, 在RAPBEE模型中, 将会采用评论属性相关度评分对整体情感评价得分项(tot_score)进行辅助修正。其计算方案如下:
其中, N为第
定义5: 基于情感词位置的修正值。情感倾向能够反映消费者对待产品或者服务的态度。然而不同强度的情感词、不同位置的情感词不仅会对消费者情感强度的表达造成影响, 也会对阅读者的情感体验造成影响。因此, 在RAPBEE模型中, 以语句中心为对轴线, 语句两端(开头和结尾)情感词的强度表达要强于中间, 即消费者如果将自身的情感词语放在评论开头或者结尾部分, 那么他所要表达的情感强度将高于中间的某些不重要位置[ 17]。其计算方法如下:
其中,
定义6: 属性情感栈。属性情感栈主要由4个子栈组成, 分别对应特征属性词栈、情感倾向强度栈、否定词栈以及程度副词栈, 属性情感栈是用于匹配产品评论属性情感倾向的重要数据结构, 属性情感栈所执行算法如图5所示。通过图5算法计算完成后, 得到属性情感匹配的结果矩阵如图6所示。
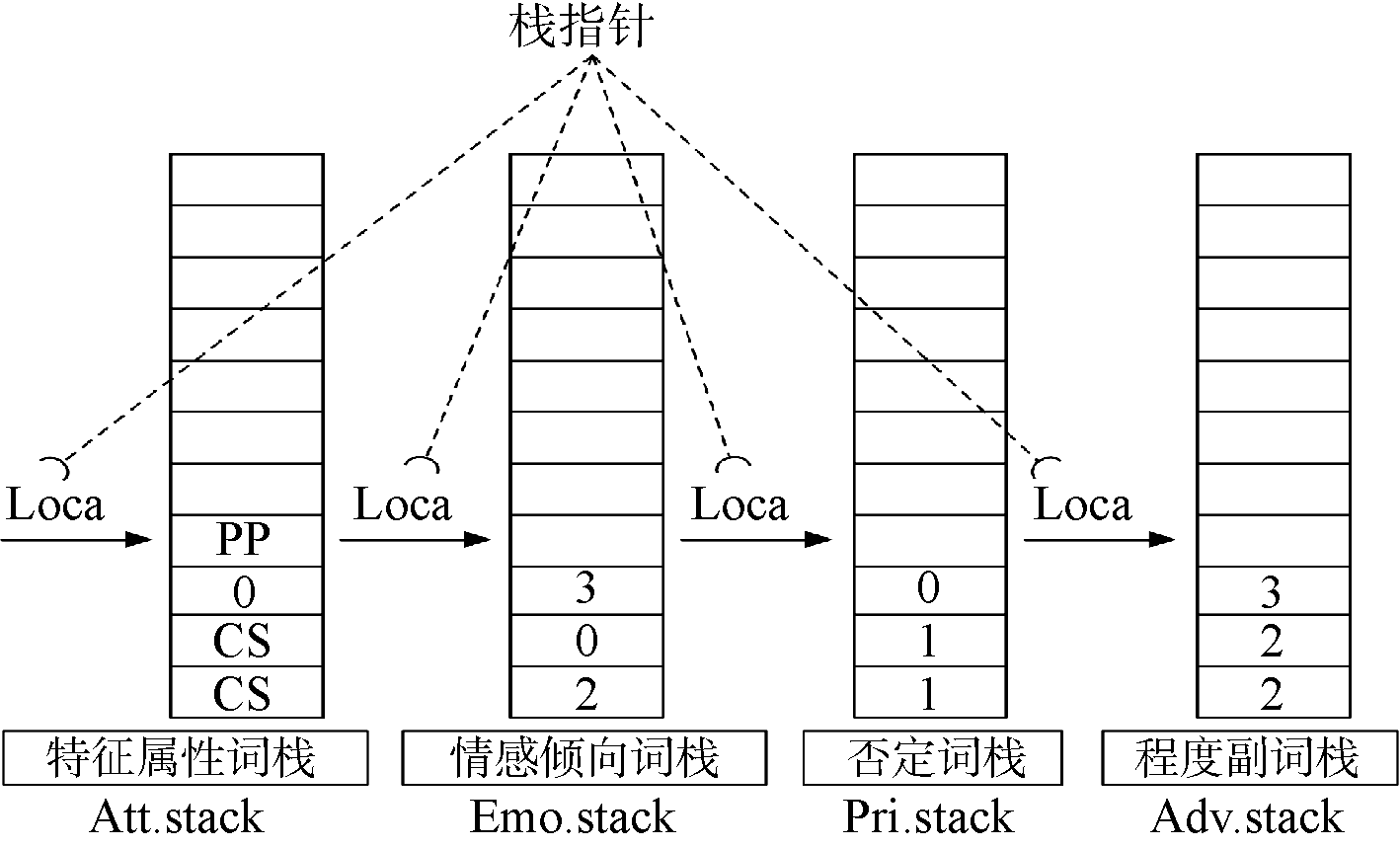 | 图5 属性情感栈 |
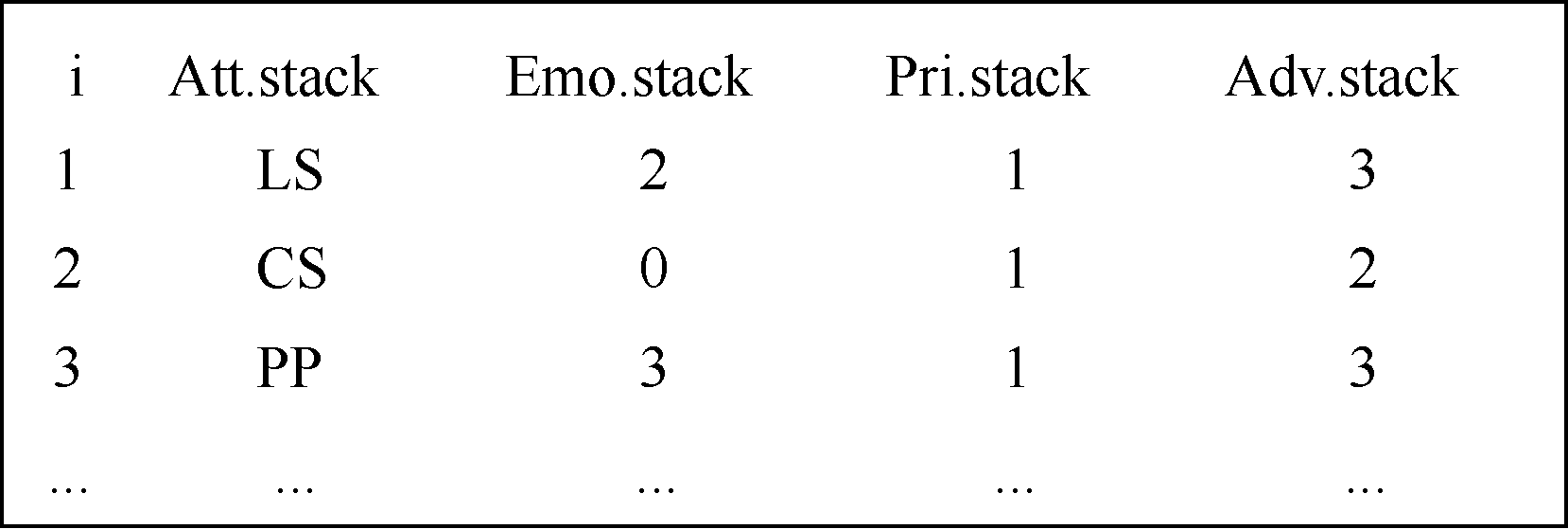 | 图6 属性情感匹配得分矩阵 |
然后再利用定义4和定义5所得的权重进行修饰计算, 最终对应各属性权值得分计算方案如下所示:
其中,
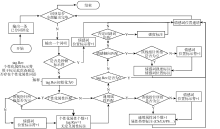
(2) 属性情感栈匹配算法
对已分词序列中的属性对应的情感倾向进行匹配是RAPBEE模型的核心算法, 也是本文的创新点之一。其基本算法流程如图7所示:
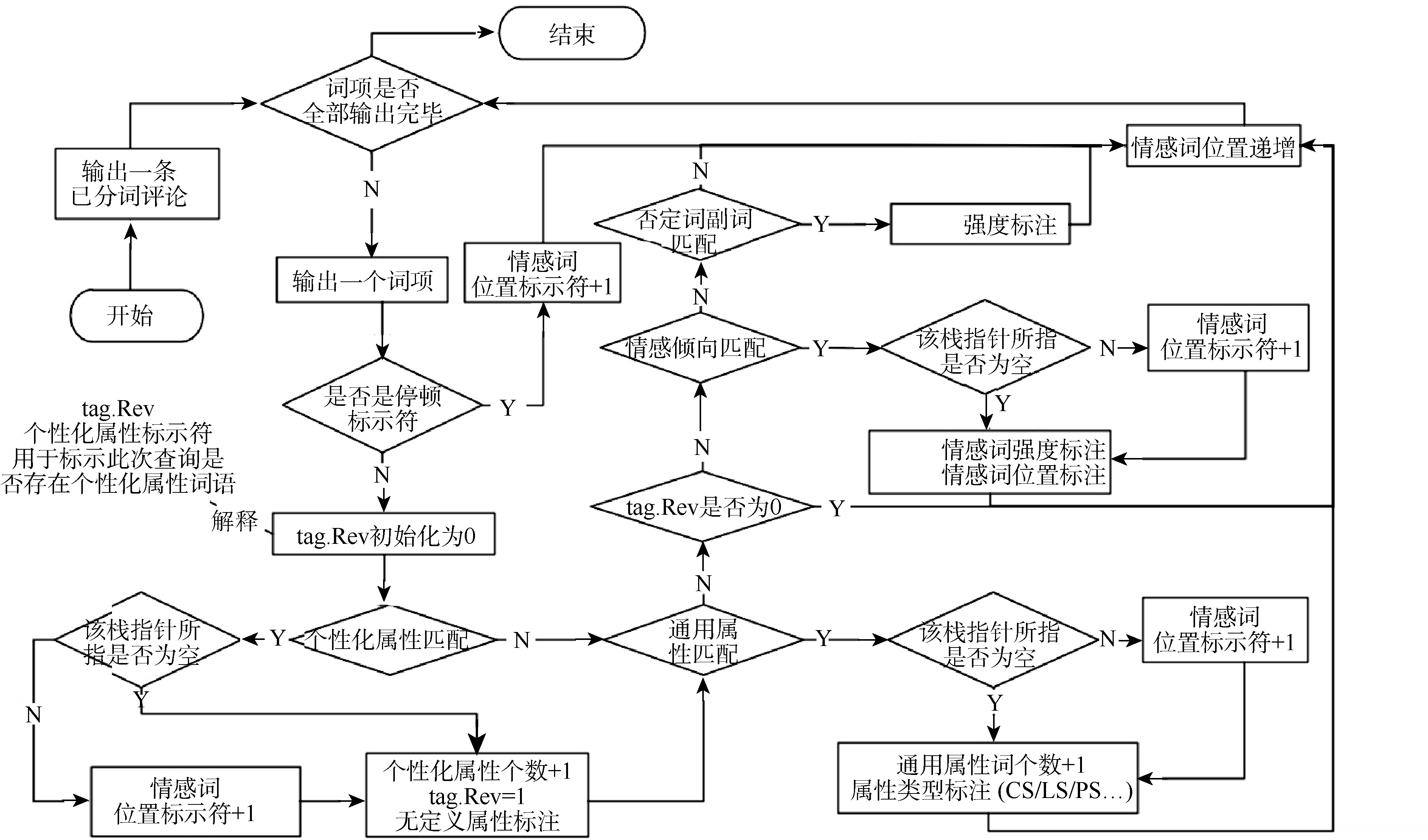 | 图7 属性情感栈匹配算法 |
属性情感栈匹配算法是专门针对在线商品评论短文本的细粒度属性情感倾向的估值算法。假设存在评论: “蛮好的, 价钱实惠, 售后也挺好的, 有一袋破了, 售后很爽快的解决了, 包装有点破损, 以后还会再来的”, 通过算法标注计算后, 结果矩阵以及标注矩阵如图8所示:
 | 图8 属性情感栈匹配计算实例 |
如果将情感栈结果矩阵进行还原将得到如图9所示的表达句。从还原效果来看, 该算法能够对原句子中消费者所要表达的属性评论部分匹配出较高的保真度。
 | 图9 属性情感栈匹配计算还原实例 |
2.5 评论可信度计算
评论可信度计算是在得出属性情感评估结果后的处理节点, 也是RAPBEE模型的关键点之一。在RAPBEE模型可信度的计算中, 将采用基于统计量扩展的多元离群点检测方法, 即通过计算已有属性情感倾向的相对差值的平均值来衡量该条评论关于该属性的离群程度。假设存在如图10所示的评论属性得分矩阵:
 | 图10 评论属性情感结果矩阵 |
第条评论的离群度量计算方法如下:
其中,
进行可信度评估后, 可以得到商品评论的可信度序列即De序列, 进一步对De序列进行归一化处理并从低到高排序后即形成MR序列(通过模型计算得到的可信度序列)。然后采用如下处理方案, 对MR进行分类:
其中, Accept list对应图3中的“可展示评论库”, Refuse list对应“限制评论库”, 两者内部全部按MR值从小到大排列。
在模型的实证研究中, 本文的数据主要来自两方面:
(1) 基于淘宝平台的数据抓取
这部分的实验数据是模型运算的基础, 并且按照时间排序进行获取。获取的主要字段包括: 评论者ID、评论者信誉、评论内容、评论时间、评论字数、评论有效性投票。
(2) 基于现场模拟实验的评分数据
为了能够对实验模型进行有效检测, 笔者采用“体验法”邀请实验人员(20人)进行现场标注实验。具体实验过程为:
① 本文软件代码(R语言)以及相关词典、数据可从https://github.com/zhiyulee-RUC/ReviewSpamDet下载, 供读者实验验证与扩展使用。
①实际购买已抓取评论的对应商品(咖啡[ 20]), 并记录所有购物体验数据, 如购买时间、购买价格、发货时间、物流配送时间、收货时间等。
②实验当天, 现场和实验人员一起拆开包裹, 体验网络购物流程, 品尝咖啡。
③实验人员根据自身购物体验, 对已有评论的可信度、有用性进行标注, 标注方案为离散型打分即1-5星级打分, 分别对应: 1分非常不可信(没用)、2分不可信(没用)、3分普通可信(有用)、4分较为可信(有用)、5分非常可信(有用)。
④实验结束, 对已获得的20份标注数据取各项数据的平均值, 并对平均值进行归一化处理, 得到消费者标注序列CR。
该实验的主要目的是模拟消费者的真实购物流程, 反映目前(抓取评论集时)商品、服务现状, 并由消费者根据自身体验判别评论内容的可信度, 以此辅证RAPBEE模型的识别处理效果。
本实验的商品对象取自淘宝商家的一款咖啡产品[ 20], 一共917条商品评论信息。通过系统运行产生了对应各条评论的可信度数据MR序列(相关评论序列)。基于现场模拟的实验评分数据是对已获取的评论数据的可信度评估的实际值(消费者认可值)进行归一化处理后得到CR序列(相关评论对应的序列), 模型的准确率评估遵循以下算法:
其中,
通过模型运行计算, RAPBEE模型识别处理得到的AC值为0.862, 即通过RAPBEE模型识别处理后的评论序列和当前商品的真实情况的符合度为86.2%, 这在已有模型中已经属于非常不错的结果。此外, 在本实例中, 恰好存在商家商品或服务发生变更的情形, 如图11所示。
图11(a)中数据显示卖家在得到了相应的服务反馈后做出改进, 使得评论内容中关于包装服务评价的得分逐步改善, 因此随着时间的推移, 关于包装属性项目的平均分值上移, 此时以前关于包装属性的负面得分的可信度下降, 正好符合模型的实践意义。而图11(b)中关于物流服务的评价通过Dickey-Fuller检验后P值为0.01<0.05, 即物流服务在整个时间序列中整体状态一直保持不变并趋向于稳定的均值(物流服务取决于物流服务商, 因此物流服务在商品销售期间一直处于稳定状态)。
 | 图11 商家包装、物流服务评价时间序列 |
从在线商品评论属性情感的角度入手, 建立了RAPBEE模型对在线商品评论的可信度进行计算和评估。通过模型的实验和测试发现, 该模型具有较高的准确率和消费者认可度。本文是在目前国内已发表关于中文虚假评论检测的研究中首次采用基于细粒度产品属性情感的离群度来衡量在线商品评论的可信度的研究, 因此具有较高的创新性。
在研究的过程中, 笔者同时发现该模型存在的不足, 主要表现在两个方面: 模型的准确度依赖于两个重要的词典, 即属性词典和情感词典; 模型的运行效率相对较低, 消耗时间较长(运算917条共花费24s)。因此, 后续的研究将主要解决上述问题, 即:
(1) 设计更加高效、精准的属性词典获取算法, 增加模型运行的稳定性。
(2) 尝试进行基于大规模评论数据的R语言虚假评论识别系统的研究, 大大提高算法的运行效率。
目前, 国内外有关在线商品虚假评论识别的相关研究正处于热点时期, 因此不仅仅在英文虚假评论的识别研究上需要突破, 中文评论的处理更是如此。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|