{kind=link}
专利术语抽取的层次过滤方法
[侯婷 , 吕学强, 李卓]
, 吕学强, 李卓]
, 吕学强, 李卓]
|
|


作者贡献声明:
吕学强: 提出研究课题;
侯婷: 设计实验方案, 完成实验并撰写论文;
李卓: 数据处理和分析, 论文最终版本修订。
【目的】专利术语作为专利文献的核心内容和重要组成部分, 其抽取任务是专利研究的基础工作。【方法】提出一种基于层次过滤的方法抽取专利术语。基于后缀数组获取重复字串作为候选词, 根据候选词集合中无效字串的特点将其分为破碎字串、冗余字串和通用词, 通过识别和过滤三类无效字串获得专利术语。分别提出计算独立性算法过滤破碎字串, 相对活跃度计算方法和分词纠错法过滤冗余字串。【结果】实验结果表明, 该方法对中文专利术语抽取有较好的效果, 平均正确率为90.54%, 平均召回率为87.33%。【局限】只针对重复字串, 无法识别文献中出现频次为1的专利术语。【结论】该方法用于专利术语抽取是有效的。
[Objective] As the core content and the important part of patent documents, the extraction task of patent terms is regarded as the basis of research works on the patent.[Methods] A hierarchical filtering method is presented to extract terms. Based on the suffix array, this method takes repeated strings as the candidate words and divides invalid strings into three classes, including the broken string, the redundant string and the common word, according to their features in the candidate set. Besides, by removing the above invalid strings, patent terms are obtained. The authors propose an independence calculation method, a relative activity calculation method and a word segmentation error correction method to filter broken strings and redundant strings respectively.[Results] Experimental results show that the proposed method has a good effect on Chinese patent term extraction. The average precision is 90.54% and the average recall is 87.33%.[Limitations] The method is just suitable for repeated strings and cannot identify the term which frequency number is 1.[Conclusions] The method is effective in patent term extraction.
专利是技术信息的重要来源, 据世界知识产权组织统计, 世界上每年90%-95%的发明创造成果能在专利文献中查到[1]。专利文献具有独特的竞争情报价值, 在科研和专利业务的诸多方面发挥着重要作用。专利术语是深层次理解专利文献内容的基础, 其能否被较好地识别影响着专利检索、专利翻译、专利本体构建[2]等诸多方面的应用性能。因此, 专利术语抽取作为目前重要的研究课题, 越来越受到研究者的关注。
国内外学者对术语抽取进行了大量的研究, 提出了各种术语抽取方法, 主要包括: 语言学规则方法[3]、统计方法[4]和混合方法[5]。其中, 语言学规则方法主要是利用词法、句法信息识别术语, 该方法简单, 抽取准确率高, 但是总体召回率偏低, 规则库构建和维护需要耗费人力资源; 统计方法基于数理统计理论, 利用词的统计特征抽取术语, 该方法具有较好的适应性, 但准确率较低; 混合方法, 即将两种方法结合起来, 取长补短。专利文献是一种法律文本, 为了有效地保护发明创造, 专利申请人在专利文献中往往会使用一些繁复晦涩、意义含混的专用术语, 不能简单地用语言学规则或者统计方法来抽取术语。目前针对中文专利进行术语抽取的研究, 大多采用多策略融合技术。韩红旗等[6]利用构词规则和术语度PC-value计算方法抽取术语。该方法能够有效地抽取长术语, 对低频短术语, 特别是最新术语, 识别精度不高, 需要人工识别。徐川等[7]提出将字符串之间的结合强度与词性过滤法相融合的方法抽取专利术语, 该方法会将一些通用字串误识别为术语。刘豹等[8]使用条件随机场模型进行初步标注识别术语, 然后结合规则库和词表等对错误识别结果进行过滤。岳金媛等[9]利用NC-value算法和条件随机场模型来抽取专利术语。上述两种方法具有较高的准确率和召回率, 但是人工标注术语的工作量较大, 且人工标注的质量决定了术语抽取的质量。谷俊等[10]对传统的TFIDF模型进行了改进, 增加了申请年和申请人的因素来抽取专利技术术语, 针对性比较强, 无法证明其在大规模数据中的通用性。上述专利术语抽取的研究有效地结合了语言学规则方法和统计方法, 提高了抽取术语的准确率, 但是极少考虑到中文专利文献的用词特点。
针对以上方法存在的问题, 本文提出一种基于层次过滤的专利术语抽取方法, 抽取文献中重复字串作为候选术语, 根据候选术语中三类无效字串的结构特点进行逐一过滤。旨在提高专利术语抽取的准确度和召回率, 降低人工成本, 为专利的信息检索、机器翻译、专利分析、专利地图构建等工作提供技术基础。
专利术语承载着专利发明的核心知识, 在专利文献中会被多次提及。因此, 本文抽取文献中的重复字串作为候选术语。而文献中常常包含一些没有实际意义的通用词, 以此作为切分标记对文本进行切分预处理, 可以提高候选术语抽取的效率和准确度。
专利术语构成形式多样, 数词、方位词、介词等均有可能构成术语, 例如“ 四角位移传感器” 、“ 上连杆” 等, 而这些词又存在于常用停用词表中, 同时, 常用停用词表不包含专利常用词, 例如: “ 专利号” 、“ 实施例” 等。因此, 不能直接使用常用停用词表对文献进行切分。本文根据专利文献的用词特点和专利术语的特点, 构建专利切分标记表。
本文构建的专利切分标记表包括显式切分标记和隐式切分标记, 显式切分标记包括标点、数字、西文和非汉字符号; 隐式切分标记包括普通通用词、专利常用词以及出现频率高、构词能力差的单字词。普通通用词是指应用十分广泛、自身并无明确意义、只有将其放入一个完整的句子中才有一定作用的词汇。专利常用词是指与专利相关的经常出现在专利文献中而在其他文献中较少出现的词汇。构词能力差的单字词是指类似于“ 的” 、“ 是” 等的词。
隐式切分标记中的专利常用词和构词能力差的单字词通过人工手动的构建, 普通通用词主要通过选取现代汉语方位词表、代词表、副词表等6个表[11]中的双字以及双字以上的词获得。此外, 本文还收录了单字数词词表和单字量词词表, 将“ 单字数词+单字量词” 的模式, 共同作为一个隐式切分标记。最后, 将获得的全部隐式切分标记按照词长大小顺序, 存储到切分标记表中。专利切分标记表示例如表1所示:
| 表1 专利切分标记词表示例 |
专利文献主要用来描述新发明的领域技术, 所用的专利术语具有丰富的内涵, 一般为多词术语, 单词型术语较少, 因此, 仅将长度大于2的词语作为候选术语。专利术语在文献的多个部分都会重复出现, 如主权项、权利要求书等。同时, 专利术语存在嵌套关系, 例如: “ 连续式葡萄糖传感器” 、“ 连续式葡萄糖” 、“ 葡萄糖传感器” 。因而, 根据术语的分布特点和构成特点, 本文利用后缀数组抽取字符串中重复字串的思想[12], 抽取文本内容中的重复字串作为候选术语。
基本定义如下:
后缀: 从某个位置i开始到整个串末尾结束的一个特殊子串。
最长公共前缀: 一种特殊的公共子串, 即两个字符串从头开始的最长公共子串。 例如: 字符串“ aaaab” 与字符串“ aaab” 的最长公共前缀为“ aaa” 。
算法描述: 首先采用构建的专利切分标记表对专利文献进行切分处理, 获得字串片段, 将这些字串片段的所有后缀按照字典序排列, 将相邻的两个后缀的最长公共前缀以及最长公共前缀从头开始长度大于2的子串作为候选术语加入候选词集合中。
在获取的候选术语中, 存在三种无效字串。第一种无效字串通常在结构上有所缺失, 没有独立存在意义, 例如“ 进电机” 、“ 力传感器” 等, 该类无效字串称为破碎字串。第二种无效字串在结构中存在冗余信息, 字串的一部分不是术语, 例如“ 生物传感器中” 、“ 加壳聚糖溶液” 等, 这类无效字串称为冗余字串。第三种无效字串在结构上完整, 但却不是术语, 例如“ 灵敏度” 、“ 严重性” 等, 此类无效字串称为通用词。将三种无效字串从候选词集合中删除, 即可获得所需的专利术语。
在候选术语的抽取过程中, 会产生一系列的不完整、不能独立出现的条目, 称为破碎字串。同时, 存在一些破碎字串拥有多个相异父串, 且这些父串之间不存在嵌套关系, 称这类破碎字串为公共破碎字串。例如“ 软件系统” 、“ 硬件系统” 中的“ 件系统” 。目前常用子串归并技术[13, 14, 15]处理破碎字串, 但是该技术不能有效地过滤公共破碎字串。因此, 根据子串与其众多父串之间的关系特点, 本文提出一种计算独立性算法, 计算候选字串单独出现的频次。如果一个字串除了在父串中出现之外, 单独出现的频次比较高, 则该字串的独立性比较强, 成为破碎字串的可能性较低。设置阈值, 将单独出现频次小于阈值μ 的候选字串过滤掉。该算法不仅可以准确地过滤同频子串, 也可以有效地将公共破碎字串过滤掉。
假设某候选字串str, 其父串集合为Parset, 则字串str独立出现的频次为:
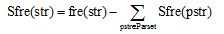 |
其中, Sfre(str)表示字串str独立出现的频次, Sfre(pstr)表示字串pstr独立出现的频次, fre(str)表示字串str在文献中出现的总频次。如果父串集合为空, 则该候选字串的独立频次为其在文献中出现的总频次。
对候选字串中冗余字串的处理, 主要是删除冗余字串中的冗余词。例如: “ 用流量限制膜” , 将冗余词“ 用” 删除。本文从候选字串的相对活跃度、构词规则等方面来处理冗余字串。
(1) 相对活跃度过滤
周浪等[16]提出一种基于左右熵的短语过滤方法, 通过判断候选字串中是否包含活跃度较高的词确定是否为冗余字串。活跃度较高的词为易与其他词汇搭配使用的词, 比如上例中的“ 用” 等。但是有些术语组成部分的词, 活跃度也比较高, 例如“ 控制” 、“ 输出” 等, 包含这类词的字串是专利术语, 并不为冗余字串。据统计, 这类专利术语相比于冗余字串, 在文档中出现的频次平均高出8.5次/文档。因此, 本文对上述方法进行改进, 将字串的频次特征和字串组成词的信息熵特征结合, 提出一种相对活跃度计算方法, 提高冗余字串的识别精度。方法描述如下:
设有词语w, 该词左右两侧的活跃度可按以下公式计算:
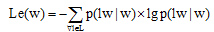 |
 |
其中, L表示词w左侧的词汇的集合; R表示词w右侧的词汇的集合; 
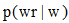
假设某个候选字串中包含n个词语, 即为 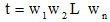
 |
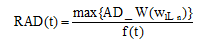 |
其中, RAD(t)表示字串t的相对活跃度, f(t)表示候选字串t的频次, AD_W(wi)表示词汇wi的活跃度。人工设定阈值η , 当RAD(t)大于阈值η 时, 视该字串为冗余字串。设冗余字串中活跃度最高的词为wm, 将wm在t中长度大于2的相邻字串s加入到候选词集中, 同时, 将该字串从候选词集合中删除。
(2) 词性规则过滤
在上述过程中, 将活跃度高的词语的相邻字串加入候选词集中, 会引入一部分噪声。此外, 候选字串中, 存在一些稳定性比较高的非术语字串。从词性规则方面考虑, 将一些明显不符合构词规则的字串从候选词集中删除。但是, 在专利文献中的术语构词具有多样性, 存在一些术语, 并不符合普通的构词规则。因此, 本文将词性过滤规则与字串频次相结合过滤候选字串, 将频次比较低、符合词性过滤规则的字串过滤掉。所用的部分词性过滤规则如表2所示:
| 表2 词性过滤规则 |
(3) 分词纠错法
在以上过滤冗余字串的过程中, 需要用到分词工具。本文采用的分词系统为ICTCLAS[17], 它依赖于上下文, 在某些上下文语境下, 可能会错误地将字串中的几个词切分为一个词, 而且这种粘连现象一般出现在字串的结尾或者开头部分。例如: “ 建模/n 软件/n 模块执行/n” 、“ 理疗/v 装置/n 控制盒/n 上装/n” 等。这类被错误切分的字串属于冗余字串, 且在词性构成上符合术语构词规则, 因此, 不能够被有效识别。
分析发现, 这类冗余字串在候选词集合中一般存在对应的子串, 且为正确术语。如“ 建模/n软件/n 模块/n” 、“ 理疗/v 装置/n 控制盒/n” 均存在于候选词集合中。对其相邻的字串进行分词以及词性标注, 如上例的“ 执行/v” 、“ 上/f 装/v” 等, 可以看出, 单独对其相邻字串进行词性标注时, 标注结果正确。因此, 利用标注结果, 结合术语构词规则, 对分词产生的错误进行分词纠错处理。具体的规则方法描述如下:
设有候选字串S=w1w2L wn, 若候选词集合中存在字串S1=w1w2L wm为字串S的左子串, 字串S2=wm+1L wn为字串S1在字串S中的相邻字串。若字串S1的结尾词词性为名词, 字串S2的结尾词词性为动词、方位词时, 则将候选字串S从候选词集合中删除; 同理, 若候选词集合中存在字串S3=wiL wn, 且i> i, 为字串S的右子串, 字串S4=w1L wn-1为字串S3在字串S中的相邻字串, 若S3结尾词词性为名词时, 对字串S4进行词性标注, 若S4包含助词、方位词(非词首)等不可能构成术语的词性时, 将字串S从候选词集合中删除。
候选字串中存在一些表示性质、程度、数值、位置、形状等的词语, 这类词语并不属于术语范畴。这类词语大都以固定的词缀结尾, 例如“ 残疾人” 、“ 受试者” 、“ 标准值” 、“ 深度” 、“ 严重性” 、“ 双凹形” 等。因此, 本文利用词缀规则过滤候选字串中的通用词。部分词缀规则如表3所示:
| 表3 部分词缀规则 |
(1) 实 验
实验数据采用某专利公司提供的1 102篇有关医疗设备领域的专利文献(摘要、主权项、权利要求书、专利说明书), 大小为18.7MB。根据候选术语抽取算法抽取文献中的重复字串作为候选术语, 通过公式(1)计算候选术语的独立性过滤候选术语中的破碎字串, 利用相对活跃度计算方法、词性规则和分词纠错法过滤冗余字串, 最后采用后缀规则过滤通用词。将三类无效字串过滤后获得专利术语。其中, 过滤破碎字串时阈值μ =1; 识别冗余字串时, 阈值η =0.4。
(2) 评价指标
采用自然语言处理领域中通用的评测指标, 即准确率和召回率。统计每篇文献中包含的术语总数(Sa)、识别的术语总数(St)和正确识别的术语总数(Sr), 计算出单篇准确率(SP)和单篇召回率(SR)。计算所统计文献中包含的术语总数(Ta)、识别的术语总数(Tt)和正确识别的术语总数(Tr), 获得所统计文献的平均准确率(AP)和召回率(AR)。公式如下:
 |
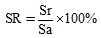 |
 |
 |
随机选取其中15篇专利文献的实验结果进行评价, 如表4所示:
| 表4 专利文献抽取结果评价 |
表4引用的15篇文献, 主题内容、技术背景不同, 文件大小分布各异。专利术语抽取实验在15篇文献中的平均准确率高达90.54%; 召回率和文献大小大体成负相关, 变化较大, 最高达到97.62%, 最低达到78.13%, 对应的文件大小为7KB和58KB。经分析, 文件较大的文献中, 所包含的频次为1的术语较多, 而本文采用的候选术语抽取算法不能将频次为1的专利术语抽取出来。因此, 对于包含较多频次为1的文献, 召回率偏低。而这些频次为1的术语, 在文献中有些作为例子或者另一术语的别名出现, 有些作为技术背景内容被提及, 例如在介绍“ 生理系统” 时, 提及“ 呼吸系统” , 在介绍技术背景时引入其他专利的名称等。
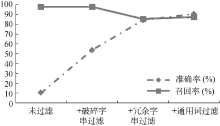
在对三种无效字串过滤的过程中, 分别统计了平均准确率和平均召回率, 其统计结果如图1所示:
 | 图1 逐层过滤的准确率和召回率 |
抽取候选字串过程中, 为了保证召回率, 将最长公共前缀的子串也作为候选词加入候选词集合中, 大大降低了准确率。从图1可以看出, 在未过滤无效字串之前, 准确率仅有10.37%, 而召回率达97.77%。破碎字串过滤将准确率提高到53.77%, 由于过滤阈值较低, 使得提高准确率的同时保持了召回率不变。冗余字串过滤后, 召回率降低到87.33%, 准确率提高到84.22%。通用词过滤后, 召回率保持不变, 主要是因为采用词缀规则过滤一些带有词缀的非术语, 对专利术语没有影响。
从图1可以看出, 候选词集合中破碎字串和冗余字串所占比重较大, 两类字串经过过滤后, 准确率提高幅度较高。在过滤冗余字串时, 召回率下降幅度较大。从字串的活跃度和构词规则等方面逐步过滤冗余字串, 每次过滤都会存在把正确术语过滤掉的情况。根据公式(8)、公式(9)得到平均准确率为90.54%, 平均召回率为87.33%, 表明本文方法对抽取术语具有较好的效果。
以用于专利术语抽取的PC-value方法[6]作对比实验, 抽取15篇文献, 通过观察实验结果, 人为设定PC-value的阈值χ =6。对比实验结果如表5所示:
| 表5 对比实验结果 |
从对比结果中可以看出, 本文方法明显优于PC-value方法。PC-value方法抽取专利技术术语的流程为: 分词和词性标注, 使用语言构词规则获得候选术语列表, 计算候选术语的PC-value值, 领域专家评估确定术语。根据专利术语特点, 存在一些并不符合普通术语构词规则的术语, 该方法不能有效识别该类术语。而本文首先利用重复字串获得候选术语, 从非术语的构词特征出发, 利用统计方法和语言规则法过滤无效字串。PC-value有利于提取高频、长术语, 而对低频的短术语抽取效果不好, 本文方法只对文献中出现频次为1的术语识别效果不好。因此, 本文方法的术语识别效果高于PC-value方法。
根据候选术语中无效字串的特点, 将其分为破碎字串、冗余字串和通用词, 提出一种基于层次过滤的专利术语抽取方法。根据子串与父串的关系特点判断破碎字串并将其过滤; 分别从字串的活跃度和构词规则等方面过滤冗余字串; 采用词缀规则过滤通用词。实验结果表明, 提出的方法能较好地从专利文献中抽取专利术语。本文的候选术语抽取算法只针对重复字串, 对频次为1的低频术语抽取效果不佳。经分析发现, 大多数低频术语出现在文献的背景技术部分, 下一步工作是分析术语在文献中的分布特征, 利用其分布特点改进术语抽取的效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|